Hacker news discussion trended on #9 with excellent feedback and comments here.
Modern agentic architectures rely heavily on chaining LLM calls. A typical pattern looks like:
Use an LLM to decide which tool to invoke
Call the tool (e.g. search, calculator, API)
Use another LLM call to interpret the result and generate a final response
This structure is easy to reason about, simple to prototype, and generalizes well.
But it scales poorly.
Each LLM call incurs latency, cost, and token overhead. More subtly, it compounds context: every step includes not only the original query, but intermediate outputs and scratchpad logic from earlier prompts. This creates a growing burden on both inference and model performance.
The consequence is that most agent stacks are paying GPT-4 to do what amounts to classical control flow — tool selection — with no reuse, no abstraction, and no efficiency gains at scale.
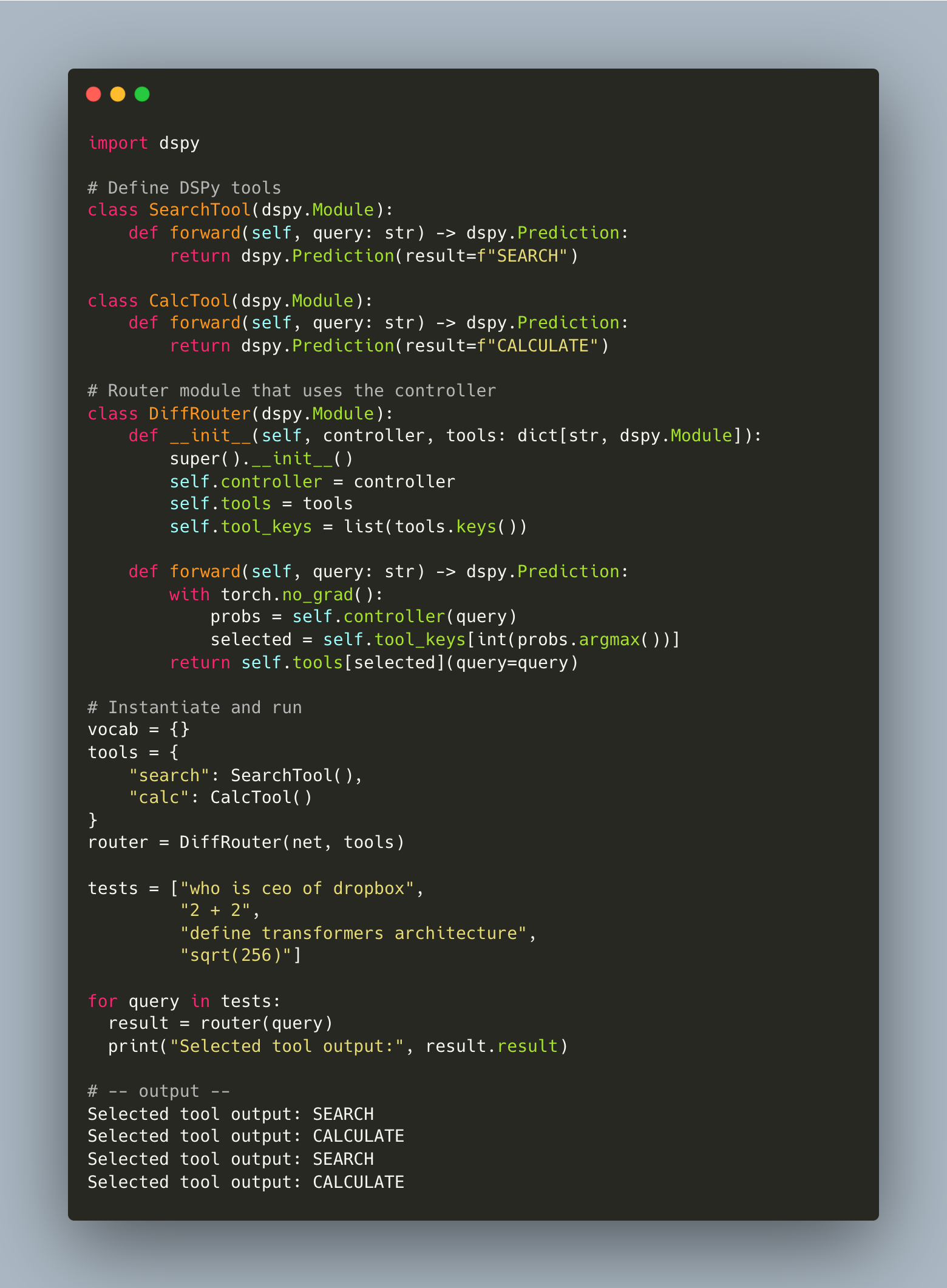
Instead of using an LLM to route between tools, we can model the decision as a trainable function. A differentiable controller learns tool selection from data — typically via reinforcement or supervised fine-tuning — and runs entirely outside the LLM.
The benefits are architectural:
Local execution — avoids external API calls
Determinism — removes stochastic sampling from routing
Composability — integrates natively with PyTorch / DSPy pipelines
Control — tool choice is explainable and debuggable
A minimal example looks like this 1 (PyTorch):

This is a simple 4-layer network: input is tokenized text; output is a softmax distribution over tools. Because it’s differentiable, you can backpropagate from downstream task reward and improve the router over time.

We can either get data from existing logs, or use GPT to create a synthetic dataset. (Our costs will be one time per tool controller, vs LLM calls for them in production).

We use a simple Adam optimizer to train this simple controller.

And finally, the demo!
For completeness, this is how we’d do it via an LLM directly.

And as a bonus, here’s how you would integrate it into a DSPy Pipeline.
Prompt-based planners incur a hidden penalty: context inflation.
Each new prompt must reintroduce the full conversation history, prior decisions, and any scratch output. The result is exponential growth in irrelevant tokens, particularly in multi-hop workflows.
This leads to:
Token tax — redundant tokens sent repeatedly
Truncation risk — long contexts hit model limits earlier
Attention dilution — more tokens competing for limited compute
Leakage — planner logic unintentionally affects final output
By contrast, a differentiable router operates entirely out-of-band. The only input to the final LLM call is the original query and the selected tool’s result. Context length is constant regardless of tool depth.

This architectural separation restores clarity to the final model call — reducing hallucinations, improving determinism, and reclaiming inference capacity for core reasoning.
The shift to differentiable routing mirrors a broader trend:
Separating declarative control logic from generative inference.
Current agentic systems blur this line. Tool selection is handled in the same modality — and often the same model — as natural language generation. This creates coupling where there should be composition.
Differentiable programming is one way to decouple the two:
LLMs focus on generation and synthesis
Lightweight neural modules handle routing, orchestration, and control
The result is a more modular, inspectable, and scalable architecture — one that avoids paying transformer inference costs for classical programming constructs.
To drive this home, lets consider a planner that routes queries between a search API and a calculator tool. Each query invokes:
One LLM call to plan
One LLM call to interpret the tool’s result
One LLM call to generate the final answer
At GPT-4.1 prices (75 input / 75 output tokens per call), this costs:

A 3× reduction in cost per run — with larger savings as tool chains grow in complexity.
In early-stage workflows, LLM routing is fast to implement and flexible to extend. But at scale, it’s structurally inefficient — economically and architecturally.
Differentiable controllers offer an excellent alternative. They reduce cost, improve performance, and clarify model behavior. They mark a step toward LLM systems that look less like prompt chains — and more like programs.
No posts