If you're evaluating JSON as JavaScript, you also need to make sure none of the objects have a key named "__proto__", or else you can end up with some strange results.
(This is related to the 'prototype pollution' attack, although searching that phrase will mostly give you information about the more-dangerous variant where two objects are being merged together with some JS library. If __proto__ is just part of a literal, the behavior is not as dangerous, but still surprising.)
Wait can someone explain why a script tag inside a comment inside a script tag needs to be closed, while a script tag inside a script tag without a comment does not? They explained why comments inside script tags are a thing, but nothing further than that.
I would say avoid trying to understand arcane nuances better than the adversary. Assume they've simultaneously got more time on their hands and sat on the relevant standards committees. Adopt a strategy that's robust to having missed a small nuance in the standard or in the particular implementation by this or that browser. (That doesn't mean there isn't value in a blog post enumerating the edge cases, of course.)
Kaminsky described a very simple and nearly-universal technique to deal with escaping/injection issues. Encode the embedded data as base64 and decode it on the client side. This projects arbitrary data into a fixed, known domain (generally `[a-zA-Z0-9+/]*`) which you can ensure is free from control characters. (You may need to use a particular variant to achieve this, eg for URLs the last characters used are generally `-_` because both + and / are significant in that context.)
That ship sailed several paragraphs ago, when <script> got special treatment by the HTML parser. Too bad we couldn't all agree to parse <![CDATA[...]]> consistently, or, you know, just &-escape the text like we do /everywhere else/ in HTML.
Discussing why parsing HTML SCRIPT elements is so complicated, the history of why it became the way it is, and how to safely and securely embed JSON content inside of a SCRIPT element today.
Everything until the tag closer </script> is inside
the script element.
And:
In fact, script tags can contain any language (not
necessarily JavaScript) or even arbitrary data. In order to
support this behavior, script tags have special parsing
rules. For the most part, the browser accepts whatever is
inside the script tag until it finds the script close tag
</script>.
Note the sentence fragment "even arbitrary data." This explains the second part of your question as to why nested script tags without HTML comments do not require matching closing tags. Similar compatibility hacks exist for other closing tags (search for Chrome closing tags being optional for a fun ride down a rabbit hole).
As to:
why a script tag inside a comment inside a script tag needs
to be closed ...
Well, this again is due to maximizing backward compatibility in order to support broken browsers (thanks IE4, you bastard!). As the article states:
When JavaScript was first introduced, many browsers did not
support it. So they would render the content of the script
tag – the JavaScript code itself. The normal way to get
around that was to put the script into a comment ...
This was my first submission, and the above comment was what I added to the text box. It wasn’t clear to me what the purpose was, but it seemed like it would want an excerpt. I only discovered after submitting that it created this comment.
I guess people just generally don’t add those?
Still, to help me out, could someone clarify why this was down-voted? I don’t want to mess up again if I did, but I don't understand what that was.
The other comment explains this, but I think it can also be viewed differently.
It’s helpful to recognize that the inner script tags are not actual script tags. Yes, once entering a script element, the browser switches parsers and wants to skip everything until a closing script tag appears. The STYLE element, TITLE, TEXTAREA, and a few others do this. Once they chop up the HTML like this they send the contents to the separate inner parser (in this case, the JS engine). SCRIPT is unique due to the legacy behavior^1.
HTML5 specifies these “inner” tags as transitions into escape modes. The entire goal is to allow JavaScript to contain the string “</script>” without it leaking to the outer parser. The early pattern of hiding inside an HTML comment is what determined the escaping mechanism rather than making some special syntax (which today does exist as noted in the post).
The opening script tag inside the comment is actually what triggers the escaping mode, and so it’s less an HTML tag and more some kind of pseudo JS syntax. The inner closing tag is therefore the escaped string value and simultaneously closes the escaped mode.
Consider the use of double quotes inside a string. We have to close the outer quote, but if the inner quote is escaped like `\”` then we don’t have to close it — it’s merely data and not syntax.
There is only one level of nesting, and eight opening tags would still be “closed” by the single closing tag.
^1: (edit) This is one reason HTML and XML (XHTML) are incompatible. The content of SCRIPT and STYLE elements are essentially just bytes. In XML they must be well-formed markup. XML parsers cannot parse HTML.
type
This attribute indicates the type of script represented. The value of this attribute will be one of the following:
[...]
Any other value
The embedded content is treated as a data block, and won't be processed by the browser. Developers must use a valid MIME type that is not a JavaScript MIME type to denote data blocks. All of the other attributes will be ignored, including the src attribute.
Although 'importmap' has specific functionality, as does 'speculationrules', although they operate similarly. My favorite is type="module" which competes with the higher level attribute nomodule="true". Anyways it looks like <script> has taken a lot of abuse over the years:
So did these older browsers also check for the presence of a comment before turning on double-escaping mode?
Or did they always have two levels of script tag escaping but that behavior only got preserved when inside an HTML comment?
No other JavaScript behavior is different inside an HTML comment, and I’m still missing the connection between the HTML comment and the embedded </script> not closing the tag besides that they were two things that older browsers might have done.
> Leave url blank to submit a question for discussion. If there is no url, text will appear at the top of the thread. If there is a url, text is optional.
Most people will opt for text to be optional with a link - unless they're showing their own product (Show HN). Because there is an expectation that you will attempt to read an article, before conversing about it.
I think its just because as a comment it looks pretty random and somewhat off topic since its a summary of the article instead of an opinion on it.
I think most of the time people dont add a comment to submissions, but if they do its more of the form: I found X interesting because of [insert non obvious reason why X is interesting] or some additional non-obvious context needed.
In any case, i don't think there is any reason to worry too much. There was no ill intent and at the end of the day its all just fake internet points.
As per the 'special parsing rules for script tags', browsers don't actually treat it as what you'd expect it means.
<script>console.log("<![CDATA[Hello, this string content in a CDATA section!]]>");</script>
Results in this being output to the console:
<![CDATA[Hello, this string content in a CDATA section!]]>
Browsers don't do what you intend if you wrap the whole script in CDATA, either. They treat the "<![CDATA[" sequence as literally part of the script! Which of course throws a syntax error.
I tend to use them anyway, as sort of a HTML/XHTML polyglot thing, because deep in my heart I still think HTML should be valid XML:
<script>/* <![CDATA[ */
// my script here, and you *still* need to be careful not
// to include close-script or close-cdata sequences
/* ]]> */</script>
In summary, the 'special parsing rules for script tags' add a great amount of complexity not just to the parsing code, but for anybody who has to emit markup, especially if different parsers disagree on what kind of escaping rules are active within a given section. Yes, the HTML5 spec codified the neurotypical "I would rather make you guess what I mean than just use the proper words to say it clearly" behavior, so at least browsers agree on it, but it's a mess and a pain to deal with because now you have to remember 1000 exceptions to what would have been simple rules.
Huh, it’s still confusing to me why they would have this double-escaping behavior only inside an HTML comment. Why not have it always behave one way or the other? At what point did the parsing behavior inside and outside HTML comments split and why?
Whoever the idiot was who came up with piling inline CSS and JS into the already heavy SGML syntax of HTML should've considered his career choices. It would've be perfectly adequate to require script and CSS to be put into external "resources" linked via src/href, especially since the spec proposals operated under the assumption there would be multiple script and styling languages going forward (like, hey, if we have one markup and styling language, why not have two or multiple?). When in fact the rules were quite simple: in SGML, text rendered to the reader goes into content, everything else, including formatting properties, goes into atttibutes. The reason for introducing this inlining misfeature was probably the desire to avoid network roundtrip, which would've later been made bogusly obsolete by Google's withdrawn HTTP/2 push spec, but also the bizarre idea anyone except webdev bloggers would be editing HTML+CSS by hand. To think there was a committee overviewing such blunders as "W3C recommendations" - actually, they screwed up again with CSS when they allowed unencoded inline data URLs such as used for SVG backgrounds and the like. The alarm bells should've been ringing at the latest the moment they seriously considered storing markup within CSS like with the abovementioned misfeature but also with the "content:" CSS property. You know, as in "recommendation" which is how W3C final stage specs were called.
> My favorite is type="module" which competes with the higher level attribute nomodule="true". Anyways it looks like <script> has taken a lot of abuse over the years:
It "conflicts" in the same way noscript[1] and script "conflict" no? They're basically related features, but can't really be made exclusive because the mere act of trying to do so wouldn't work: as the link indicates, executing code in a !module browser reserves the type (requires a specific set of types) so you can't use that as a way to opt in !module browsers.
[1] an other fun element with wonky parsing rules besides
At some point I think I read a more complete justification, but I can’t find it now. There is evidence that it came about as a byproduct of the interaction of the HTML parser and JS parsers in early browsers.
In this link we can see the expectation that the HTML comment surrounds a call to document.write() which inserts a new SCRIPT element. The tags are balanced.
In this HTML 4.01 spec, it’s noted to use HTML comments to hide the script contents from render, which is where we start to get the notion of using these to hide markup from display.
My guess is that at some point the parsers looked for balanced tags, as evidenced in the note in the last link above, but then practical issues with improperly-generated scripts led to the idea that a single SCRIPT closing tag ends the escaping. Maybe people were attempting to concatenate script contents wrong and getting stacks of opening tags that were never closed. I don’t know, but I suppose it’s recorded somewhere.
Many things in today’s HTML arose because of widespread issues with how people generated the content. The same is true of XML and XHTML by the way. Early XML mailing lists were full of people parsing XML with naive PERL regular expressions and suggesting that when someone wants to “fix” broken markup, that they do it with string-based find-and-replace.
The main difference is that the HTML spec went in the direction of saying, _if we can agree how to handle these errors then in the face of some errors we can display some content_ and we can all do it in the same way. XML is worse in some regards: certain kinds of errors are still ambiguous and up to the parser to determine how to handle, whether they are non-recoverable or recoverable. For those non-recoverable, the presence of a single error destroys the entire document, like being refused a withdrawal at the bank because you didn’t cross a 7.
At least with HTML5, it’s agreed upon what to do when errors are present and all parsers can produce the same output document; XML parsers routinely handle malformed content and do so in different ways (though most at least provide or default to a strict mode). It’s better than the early web, but not that much better.
Yeah, that's fair, and I did forget about `=`/padding when I discussed base64. This instance is a solved problem with a simple solution, blessed by the standards body.
The advantage of the base64 technique is that it provides fewer degrees of freedom, and so is more robust to unforseen vectors of attack. It's defensive programming. But it comes at a cost of memory/bandwidth.
> It would've be perfectly adequate to require script and CSS to be put into external "resources" linked via src/href
Bullshit - Navigator and IE didn't have HTTP/2. I'm guessing you didn't use dialup where your external CSS or JavaScript regularly failed to load. You didn't add extra dependencies because IE would only had two concurrent connections to load files.
It's easy to criticize past mistakes from your armchair: but I suggest you try and be a little more fair towards the people that made decisions especially when overall HTML has been a resounding success.
Which is a little weird. At the very least I'd expect the type="module" documentation to say that `charset`, `defer` and `nomodule` attributes have no effect.
Not just his convenience. Man-millenia of convenience, if you will ;) I too love the fact that many things can be single index.html's, no need of a zip file then. It's double-click to view. One of the best things about the web platform.
Edit: and "effort", please. The spec has a simple and clear note:
> The easiest and safest way to avoid the rather strange restrictions described in this section is to always escape an ASCII case-insensitive match for "<!--" as "\x3C!--", "<script" as "\x3Cscript", and "</script" as "\x3C/script" when these sequences appear in literals in scripts (e.g. in strings, regular expressions, or comments), and to avoid writing code that uses such constructs in expressions. Doing so avoids the pitfalls that the restrictions in this section are prone to triggering.
Backwards compatibility is easily and completely worth this small amount of effort. It's a one-liner in most languages.
The easiest and safest way to avoid the rather strange restrictions described is to not make use of inline script in a way that makes those restrictions neccessary, though. And a "recommendation" should reflect that (from back when HTML recommendations were actually published rather than random Google shills writing whatever on github). The suggested workaround is also not without criticism (eg [1]).
MDN does a pretty good job anyways. Perhaps I feel that it would be in keeping with that spirit to have this condition documented. This is partly because MDN is far easier to read for the purposes of _reference_ than the spec which is easier to read for the purposes of _implementing_. It's also easier to search and to share links to, as the link you presented earlier was both wrong and confusing, and there was no natural way to link to the part of the document you intended.
Perhaps the spec isn't the right tool for every job? That's why, for me, at least.
Submit a change, then. MDN isn't written by some secret cabal. It's written by all of us.
Listen to this article (with local TTS)
<script> tags follow unintuitive parsing rules that can break a webpage in surprising ways. Fortunately, it’s relatively straightforward to escape JSON for script tags.
Just do this
Replace < with \x3C or \u003C in JSON strings.
In PHP, use json_encode($data, JSON_HEX_TAG | JSON_UNESCAPED_SLASHES) for safe JSON in <script> tags.
In WordPress, use [wp_json_encode](https://developer.wordpress.org/reference/functions/wp_json_encode/) with the same flags.
The easiest and safest … is to always escape an ASCII case-insensitive match for “<!--” as “\x3C!--“, “<script” as “\x3Cscript“, and “</script” as “\x3C/script“…
This post will dive deep into the exotic script tag parsing rules in order to understand how they work and why this is the appropriate way to escape JSON.
What’s so gnarly about a script tag?
Script tags are used to embed other languages in HTML. The most common example is JavaScript:
This is great, JavaScript can be embedded directly. Imagine if script tags required HTML escaping:
In fact, script tags can contain any language (not necessarily JavaScript) or even arbitrary data. In order to support this behavior, script tags have special parsing rules. For the most part, the browser accepts whatever is inside the script tag until it finds the script close tag </script>1.
So, what happens when we embed this perfectly valid JavaScript that contains a script close tag?
Oops! We can see that </script> was part of a JavaScript string, but the browser is just parsing the HTML. This script element closes prematurely, resulting in the following tree:
├─SCRIPT
│ └─#text console.log('
└─#text ')
Ok, let’s use json_encode() and we should be all set:
Now we’ve got this HTML:
</script> has become <\/script>. The JavaScript string value is preserved and the script element does not close prematurely. Perfect, right?
Not so fast, things are about to get messy
Let’s expand with a more complex example. Here’s some data used by an imaginary HTML library. We’ll escape the JSON again with json_encode2:
Our HTML page includes the following, with a safely escaped script close tag:
Lovely. We’re good at this. Let’s just ship that 🚀
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
Great. Production is now a blank page and we need to write a post-mortem. What happened? The HTML looks just fine. Let’s inspect the document tree:
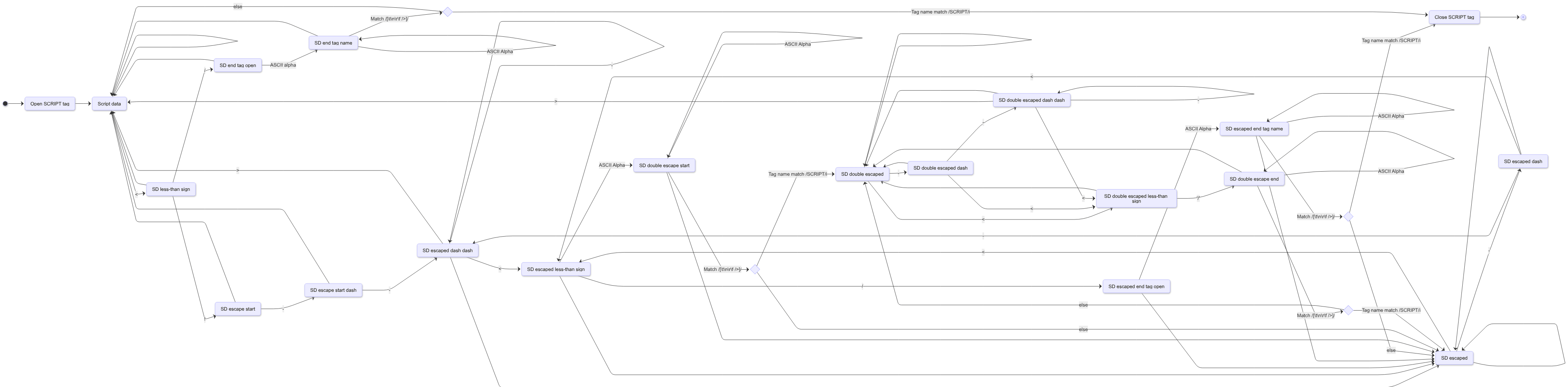
If you’re not steeped in HTML arcana, fear not, this handy chart should clarify things 🙃
This is a real and mostly accurate diagram of how script tag tokenization works. I’ve taken some liberties with things like end-of-file tokens and null bytes that aren’t relevant to the discussion.
When JavaScript was first introduced, many browsers did not support it. So they would render the content of the script tag – the JavaScript code itself. The normal way to get around that was to put the script into a comment — things like
This kind of practice was commonplace on the web. As the web evolved, browsers continued to support the behavior so they wouldn’t break existing pages. Then, HTML5 came along and standardized the behavior so folks knew what to expect, even if it’s surprising. We can see other remnants of this practice in the HTML scripting specification:
for related historical reasons, the string “<!–” in classic scripts is actually treated as a line comment start, just like “//”.
Back to our script data double escaped state. We can simplify the diagram above to collapse some states and focus on the interesting transitions:
This diagram names some transitions <script and </script. This is true, but the tag name only matches when the name script is followed by a byte that terminates a tag name — Space, Tab, “/”, “>”, or a newline (\n, \f, \r). For example, <script-o-rama or </scripty do not transition.
To understand the problem with our example above, locate the three transitions for </script:
script data → close
script data escaped → close
‼️ script data double escaped → script data escaped ‼️
</script> does not close a script element from the script data double escaped state.
The complexity of script tag parsing and escaping comes from the escaped states. Avoid the script data double escaped state and script tags become simple. Everything until the tag closer </script> is inside the script element.
How can we avoid the double escaped state? Script tag parsing always starts in the script data state and there’s a pattern in its transitions:
</script: script data → close
<!--: script data → script data escaped
Both require “<” as their first character Everything will be handled predictably if < never appears inside of the script tag. Remember what the HTML standard on scripting said? It recommends escaping < in specific places:
[Escape] “<!--” as “\x3C!--“, “<script” as “\x3Cscript“, and “</script” as “\x3C/script” [in literals.]
PHP has the [JSON_HEX_TAG](https://www.php.net/manual/en/json.constants.php#constant.json-hex-tag) flag that will escape all < as \u003C and >\u003E. This will escape much more than is strictly necessary, but it’s sufficient and is provided by the language. Perfect!
How to escape JSON escaping in PHP
For JSON that will be printed in a script tag, use the following flags:
[JSON_HEX_TAG](https://www.php.net/manual/en/json.constants.php#constant.json-hex-tag) All < and > are converted to \u003C and \u003E.
If everything is UTF-8 (both the data and the charset of the page) you can add these flags for cleaner and shorter JSON:
[JSON_UNESCAPED_UNICODE](https://www.php.net/manual/en/json.constants.php#constant.json-unescaped-unicode) Encode multibyte Unicode characters literally (default is to escape as \uXXXX).
[JSON_UNESCAPED_LINE_TERMINATORS](https://www.php.net/manual/en/json.constants.php#constant.json-unescaped-line-terminators) The line terminators are kept unescaped when [JSON_UNESCAPED_UNICODE](https://www.php.net/manual/en/json.constants.php#constant.json-unescaped-unicode) is supplied. It uses the same behaviour as it was before PHP 7.1 without this constant. Available as of PHP 7.1.0.
JSON_UNESCAPED_LINE_TERMINATORS is a fun one. Before ES2019, JavaScript strings did not accept two characters U+2028 (LINE SEPARATOR) and U+2029 (PARAGRAPH SEPARATOR) that JSON strings do allow. Some valid JSON was invalid JavaScript. Since the JavaScript is a superset of JSON proposal landed in ES2019, that’s no longer the case and those characters no longer require escaping. Phew! Browser support today is very good.
JSON escaping in action
Here’s the problematic example again, now with the recommended flags:
Let’s see the printed HTML and its resulting tree:
“Success! 🎉” is displayed and the tree structure is exactly what we expected.
What about JavaScript?
The problems with JSON seem to be solved. But what about JavaScript source text? Or what if we decide to embed XML, Python, or Haskell in a script tag? All of those are permitted but bring different challenges.
Given what we learned here, see if you can find a general solution for escaping JavaScript safely. Remember that script data double escaped state is dangerous and should be avoided. We also can’t allow the script tag to close prematurely with </script>. The path from our entry state to double-escaped looks like this:
Script data state: “<!--” transition to
Script data escaped state: “<script>” transition to
Script data double escaped state: ‼️
The diagrams in this post were generated with Mermaid and Graphviz. Their source is available in this gist. Thanks to Dennis Snell for an improved version of the reduced state graph.
It’s easiest to talk about </script> as the script close tag. Technically, it’s not strictly </script>, but a sequence of characters that looks like a script tag closer. For example </SCRIPT/> closes a script element but </script-no> does not. ↩︎
Several examples include [JSON_PRETTY_PRINT](https://www.php.net/manual/en/json.constants.php#constant.json-pretty-print) in the output for legibility. This flag is omitted from the example code. ↩︎