Between August and early September, three infrastructure bugs intermittently degraded Claude's response quality. We've now resolved these issues and want to explain what happened.
In early August, a number of users began reporting degraded responses from Claude. These initial reports were difficult to distinguish from normal variation in user feedback. By late August, the increasing frequency and persistence of these reports prompted us to open an investigation that led us to uncover three separate infrastructure bugs.
To state it plainly: We never reduce model quality due to demand, time of day, or server load. The problems our users reported were due to infrastructure bugs alone.
We recognize users expect consistent quality from Claude, and we maintain an extremely high bar for ensuring infrastructure changes don't affect model outputs. In these recent incidents, we didn't meet that bar. The following postmortem explains what went wrong, why detection and resolution took longer than we would have wanted, and what we're changing to prevent similar future incidents.
We don't typically share this level of technical detail about our infrastructure, but the scope and complexity of these issues justified a more comprehensive explanation.
How we serve Claude at scale
We serve Claude to millions of users via our first-party API, Amazon Bedrock, and Google Cloud's Vertex AI. We deploy Claude across multiple hardware platforms, namely AWS Trainium, NVIDIA GPUs, and Google TPUs. This approach provides the capacity and geographic distribution necessary to serve users worldwide.
Each hardware platform has different characteristics and requires specific optimizations. Despite these variations, we have strict equivalence standards for model implementations. Our aim is that users should get the same quality responses regardless of which platform serves their request. This complexity means that any infrastructure change requires careful validation across all platforms and configurations.
Timeline of events
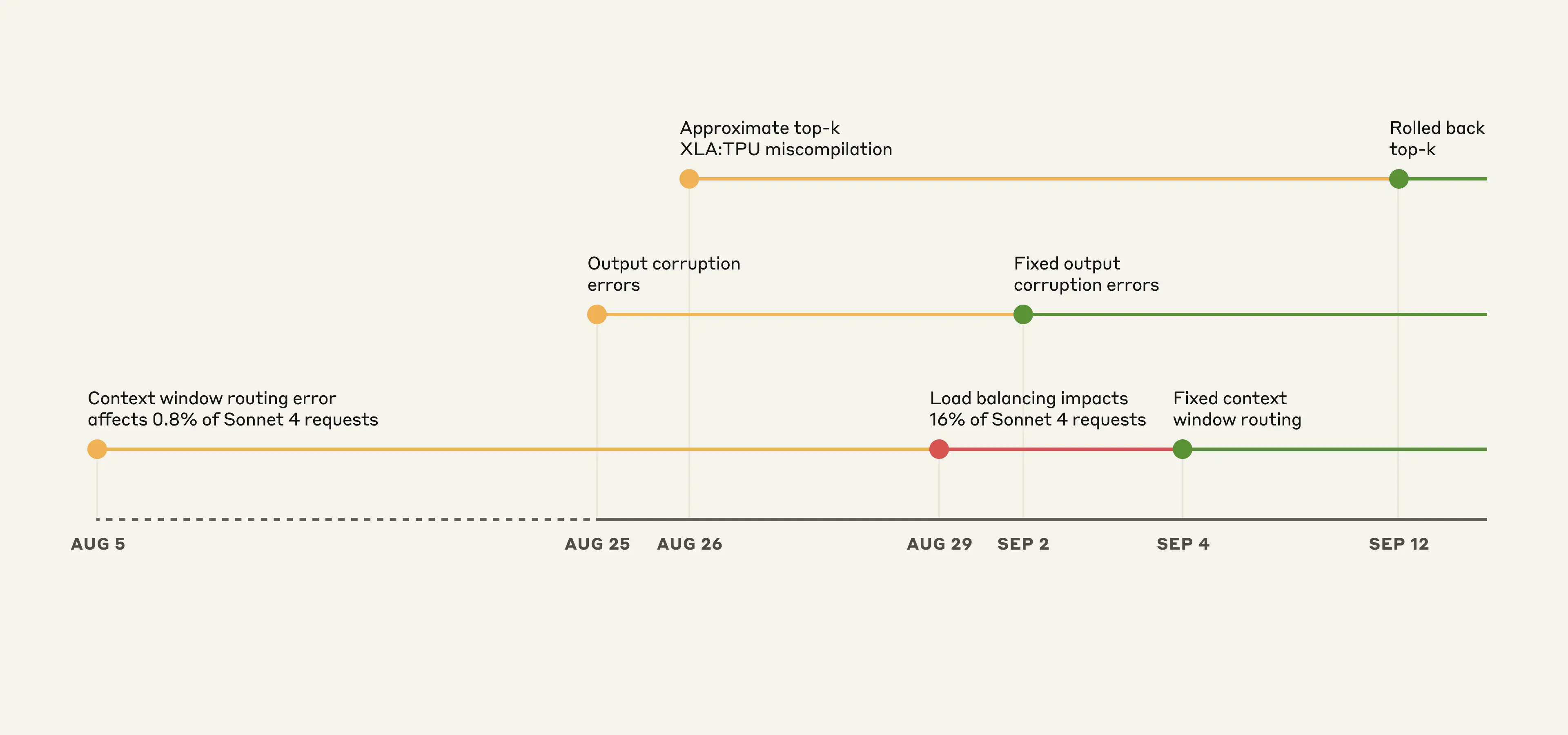
Illustrative timeline of events on the Claude API. Yellow: issue detected, Red: degradation worsened, Green: fix deployed.
The overlapping nature of these bugs made diagnosis particularly challenging. The first bug was introduced on August 5, affecting approximately 0.8% of requests made to Sonnet 4. Two more bugs arose from deployments on August 25 and 26.
Although initial impacts were limited, a load balancing change on August 29 started to increase affected traffic. This caused many more users to experience issues while others continued to see normal performance, creating confusing and contradictory reports.
Three overlapping issues
Below we describe the three bugs that caused the degradation, when they occurred, and how we resolved them:
1. Context window routing error
On August 5, some Sonnet 4 requests were misrouted to servers configured for the upcoming 1M token context window. This bug initially affected 0.8% of requests. On August 29, a routine load balancing change unintentionally increased the number of short-context requests routed to the 1M context servers. At the worst impacted hour on August 31, 16% of Sonnet 4 requests were affected.
Approximately 30% of Claude Code users who made requests during this period had at least one message routed to the wrong server type, resulting in degraded responses. On Amazon Bedrock, misrouted traffic peaked at 0.18% of all Sonnet 4 requests from August 12. Incorrect routing affected less than 0.0004% of requests on Google Cloud's Vertex AI between August 27 and September 16.
However, some users were affected more severely, as our routing is "sticky". This meant that once a request was served by the incorrect server, subsequent follow-ups were likely to be served by the same incorrect server.
Resolution: We fixed the routing logic to ensure short- and long-context requests were directed to the correct server pools. We deployed the fix on September 4. A rollout to our first-party platforms and Google Cloud’s Vertex was completed by September 16. The fix is in the process of being rolled out on Bedrock.
2. Output corruption
On August 25, we deployed a misconfiguration to the Claude API TPU servers that caused an error during token generation. An issue caused by a runtime performance optimization occasionally assigned a high probability to tokens that should rarely be produced given the context, for example producing Thai or Chinese characters in response to English prompts, or producing obvious syntax errors in code. A small subset of users that asked a question in English might have seen "สวัสดี" in the middle of the response, for example.
This corruption affected requests made to Opus 4.1 and Opus 4 on August 25-28, and requests to Sonnet 4 August 25–September 2. Third-party platforms were not affected by this issue.
Resolution: We identified the issue and rolled back the change on September 2. We've added detection tests for unexpected character outputs to our deployment process.
3. Approximate top-k XLA:TPU miscompilation
On August 25, we deployed code to improve how Claude selects tokens during text generation. This change inadvertently triggered a latent bug in the XLA:TPU[1] compiler, which has been confirmed to affect requests to Claude Haiku 3.5.
We also believe this could have impacted a subset of Sonnet 4 and Opus 3 on the Claude API. Third-party platforms were not affected by this issue.
Resolution: We first observed the bug affecting Haiku 3.5 and rolled it back on September 4. We later noticed user reports of problems with Opus 3 that were compatible with this bug, and rolled it back on September 12. After extensive investigation we were unable to reproduce this bug on Sonnet 4 but decided to also roll it back out of an abundance of caution.
Simultaneously, we have (a) been working with the XLA:TPU team on a fix for the compiler bug and (b) rolled out a fix to use exact top-k with enhanced precision. For details, see the deep dive below.
A closer look at the XLA compiler bug
To illustrate the complexity of these issues, here's how the XLA compiler bug manifested and why it proved particularly challenging to diagnose.
When Claude generates text, it calculates probabilities for each possible next word, then randomly chooses a sample from this probability distribution. We use "top-p sampling" to avoid nonsensical outputs—only considering words whose cumulative probability reaches a threshold (typically 0.99 or 0.999). On TPUs, our models run across multiple chips, with probability calculations happening in different locations. To sort these probabilities, we need to coordinate data between chips, which is complex.[2]
In December 2024, we discovered our TPU implementation would occasionally drop the most probable token when temperature was zero. We deployed a workaround to fix this case.

Code snippet of a December 2024 patch to work around the unexpected dropped token bug when temperature = 0.
The root cause involved mixed precision arithmetic. Our models compute next-token probabilities in bf16 (16-bit floating point). However, the vector processor is fp32-native, so the TPU compiler (XLA) can optimize runtime by converting some operations to fp32 (32-bit). This optimization pass is guarded by the xla_allow_excess_precision flag which defaults to true.
This caused a mismatch: operations that should have agreed on the highest probability token were running at different precision levels. The precision mismatch meant they didn't agree on which token had the highest probability. This caused the highest probability token to sometimes disappear from consideration entirely.
On August 26, we deployed a rewrite of our sampling code to fix the precision issues and improve how we handled probabilities at the limit that reach the top-p threshold. But in fixing these problems, we exposed a trickier one.

Code snippet showing a minimized reproducer merged as part of the August 11 change that root-caused the "bug" being worked around in December 2024. In reality, it’s expected behavior of the xla_allow_excess_precision flag.
Our fix removed the December workaround because we believed we'd solved the root cause. This led to a deeper bug in the approximate top-k operation—a performance optimization that quickly finds the highest probability tokens.[3] This approximation sometimes returned completely wrong results, but only for certain batch sizes and model configurations. The December workaround had been inadvertently masking this problem.
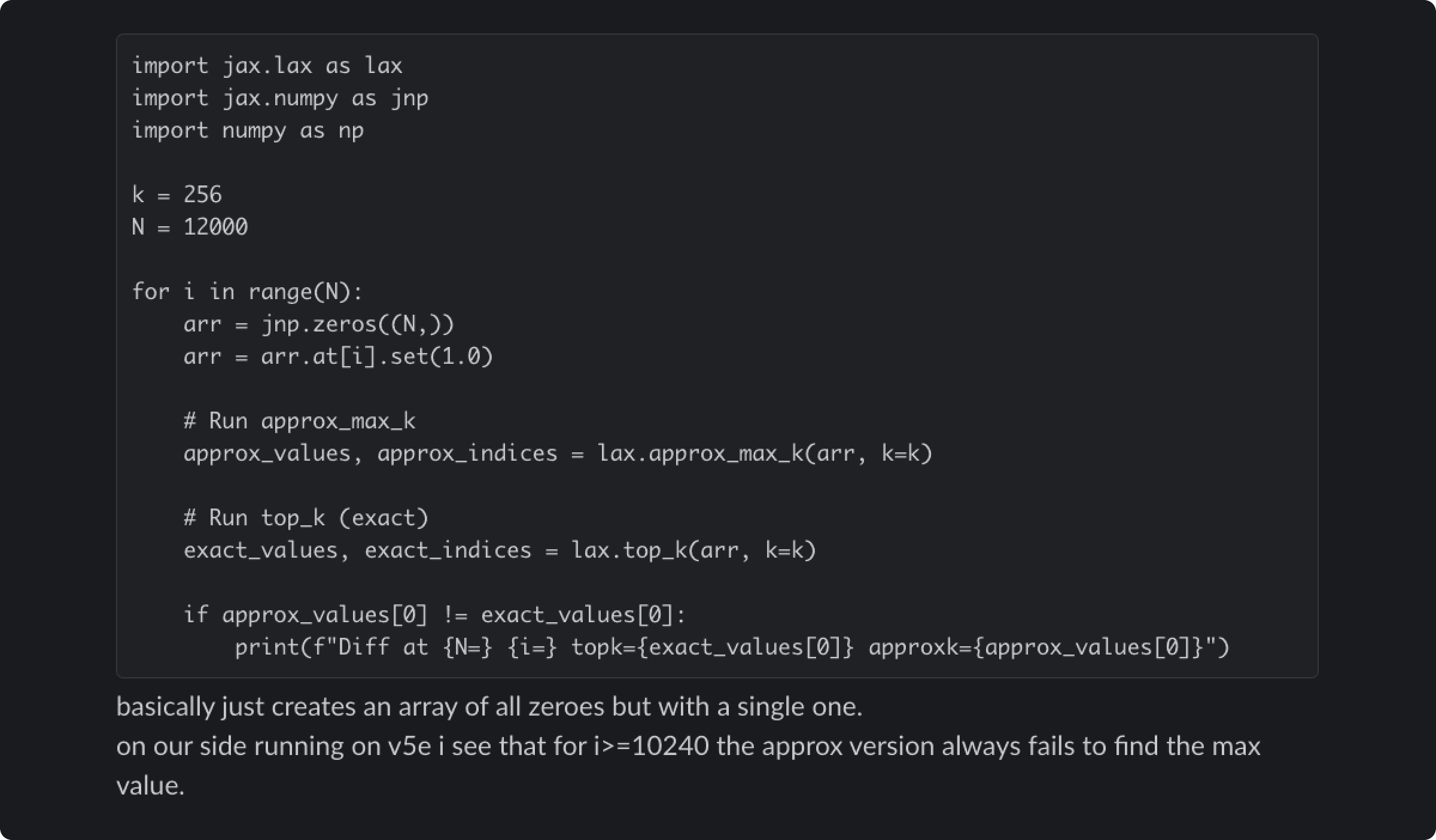
Reproducer of the underlying approximate top-k bug shared with the XLA:TPU engineers who developed the algorithm. The code returns correct results when run on CPUs.
The bug's behavior was frustratingly inconsistent. It changed depending on unrelated factors such as what operations ran before or after it, and whether debugging tools were enabled. The same prompt might work perfectly on one request and fail on the next.
While investigating, we also discovered that the exact top-k operation no longer had the prohibitive performance penalty it once did. We switched from approximate to exact top-k and standardized some additional operations on fp32 precision.[4] Model quality is non-negotiable, so we accepted the minor efficiency impact.
Why detection was difficult
Our validation process ordinarily relies on benchmarks alongside safety evaluations and performance metrics. Engineering teams perform spot checks and deploy to small "canary" groups first.
These issues exposed critical gaps that we should have identified earlier. The evaluations we ran simply didn't capture the degradation users were reporting, in part because Claude often recovers well from isolated mistakes. Our own privacy practices also created challenges in investigating reports. Our internal privacy and security controls limit how and when engineers can access user interactions with Claude, in particular when those interactions are not reported to us as feedback. This protects user privacy but prevents engineers from examining the problematic interactions needed to identify or reproduce bugs.
Each bug produced different symptoms on different platforms at different rates. This created a confusing mix of reports that didn't point to any single cause. It looked like random, inconsistent degradation.
More fundamentally, we relied too heavily on noisy evaluations. Although we were aware of an increase in reports online, we lacked a clear way to connect these to each of our recent changes. When negative reports spiked on August 29, we didn't immediately make the connection to an otherwise standard load balancing change.
What we're changing
As we continue to improve our infrastructure, we're also improving the way we evaluate and prevent bugs like those discussed above across all platforms where we serve Claude. Here's what we're changing:
- More sensitive evaluations: To help discover the root cause of any given issue, we’ve developed evaluations that can more reliably differentiate between working and broken implementations. We’ll keep improving these evaluations to keep a closer eye on model quality.
- Quality evaluations in more places: Although we run regular evaluations on our systems, we will run them continuously on true production systems to catch issues such as the context window load balancing error.
- Faster debugging tooling: We'll develop infrastructure and tooling to better debug community-sourced feedback without sacrificing user privacy. Additionally, some bespoke tools developed here will be used to reduce the remediation time in future similar incidents, if those should occur.
Evals and monitoring are important. But these incidents have shown that we also need continuous signal from users when responses from Claude aren't up to the usual standard. Reports of specific changes observed, examples of unexpected behavior encountered, and patterns across different use cases all helped us isolate the issues.
It remains particularly helpful for users to continue to send us their feedback directly. You can use the /bug command in Claude Code or you can use the "thumbs down" button in the Claude apps to do so. Developers and researchers often create new and interesting ways to evaluate model quality that complement our internal testing. If you'd like to share yours, reach out to feedback@anthropic.com.
We remain grateful to our community for these contributions.
[1] XLA:TPU is the optimizing compiler that translates XLA High Level Optimizing language—often written using JAX—to TPU machine instructions.
[2] Our models are too large for single chips and are partitioned across tens of chips or more, making our sorting operation a distributed sort. TPUs (just like GPUs and Trainium) also have different performance characteristics than CPUs, requiring different implementation techniques using vectorized operations instead of serial algorithms.
[3] We had been using this approximate operation because it yielded substantial performance improvements. The approximation works by accepting potential inaccuracies in the lowest probability tokens, which shouldn't affect quality—except when the bug caused it to drop the highest probability token instead.
[4] Note that the now-correct top-k implementation may result in slight differences in the inclusion of tokens near the top-p threshold, and in rare cases users may benefit from re-tuning their choice of top-p.