15th December 2025
I wrote about JustHTML yesterday—Emil Stenström’s project to build a new standards compliant HTML5 parser in pure Python code using coding agents running against the comprehensive html5lib-tests testing library. Last night, purely out of curiosity, I decided to try porting JustHTML from Python to JavaScript with the least amount of effort possible, using Codex CLI and GPT-5.2. It worked beyond my expectations.
TL;DR
I built simonw/justjshtml, a dependency-free HTML5 parsing library in JavaScript which passes 9,200 tests from the html5lib-tests suite and imitates the API design of Emil’s JustHTML library.
It took two initial prompts and a few tiny follow-ups. GPT-5.2 running in Codex CLI ran uninterrupted for several hours, burned through 1,464,295 input tokens, 97,122,176 cached input tokens and 625,563 output tokens and ended up producing 9,000 lines of fully tested JavaScript across 43 commits.
Time elapsed from project idea to finished library: about 4 hours, during which I also bought and decorated a Christmas tree with family and watched the latest Knives Out movie.
Some background
One of the most important contributions of the HTML5 specification ten years ago was the way it precisely specified how invalid HTML should be parsed. The world is full of invalid documents and having a specification that covers those means browsers can treat them in the same way—there’s no more “undefined behavior” to worry about when building parsing software.
Unsurprisingly, those invalid parsing rules are pretty complex! The free online book Idiosyncrasies of the HTML parser by Simon Pieters is an excellent deep dive into this topic, in particular Chapter 3. The HTML parser.
The Python html5lib project started the html5lib-tests repository with a set of implementation-independent tests. These have since become the gold standard for interoperability testing of HTML5 parsers, and are used by projects such as Servo which used them to help build html5ever, a “high-performance browser-grade HTML5 parser” written in Rust.
Emil Stenström’s JustHTML project is a pure-Python implementation of an HTML5 parser that passes the full html5lib-tests suite. Emil spent a couple of months working on this as a side project, deliberately picking a problem with a comprehensive existing test suite to see how far he could get with coding agents.
At one point he had the agents rewrite it based on a close inspection of the Rust html5ever library. I don’t know how much of this was direct translation versus inspiration (here’s Emil’s commentary on that)—his project has 1,215 commits total so it appears to have included a huge amount of iteration, not just a straight port.
My project is a straight port. I instructed Codex CLI to build a JavaScript version of Emil’s Python code.
The process in detail
I started with a bit of mise en place. I checked out two repos and created an empty third directory for the new project:
cd ~/dev git clone https://github.com/EmilStenstrom/justhtml git clone https://github.com/html5lib/html5lib-tests mkdir justjshtml cd justjshtml
Then I started Codex CLI for GPT-5.2 like this:
codex --yolo -m gpt-5.2
That --yolo flag is a shortcut for --dangerously-bypass-approvals-and-sandbox, which is every bit as dangerous as it sounds.
My first prompt told Codex to inspect the existing code and use it to build a specification for the new JavaScript library:
We are going to create a JavaScript port of ~/dev/justhtml - an HTML parsing library that passes the full ~/dev/html5lib-tests test suite. It is going to have a similar API to the Python library but in JavaScript. It will have no dependencies other than raw JavaScript, hence it will work great in the browser and node.js and other environments. Start by reading ~/dev/justhtml and designing the user-facing API for the new library - create a spec.md containing your plan.
I reviewed the spec, which included a set of proposed milestones, and told it to add another:
Add an early step to the roadmap that involves an initial version that parses a simple example document that is valid and returns the right results. Then add and commit the spec.md file.
Here’s the resulting spec.md file. My request for that initial version became “Milestone 0.5” which looked like this:
Milestone 0.5 — End-to-end smoke parse (single valid document)
- Implement the smallest end-to-end slice so the public API is real early:
new JustHTML("<html><head></head><body><p>Hello</p></body></html>")returns a tree with the expected tag structure and text nodes.doc.toText()returns"Hello"anddoc.errorsis empty for this valid input.- Add
scripts/smoke.js(no deps) that runs the example and asserts the expected structure/output.- Gate:
node scripts/smoke.jspasses.
Then I told it:
Implement Milestone 0.5
And off it went. The resulting code appeared to work so I said:
Configure GitHub Actions test.yml to run that on every commit, then commit and push
I ran git init and created a private GitHub repository for this project at this point, and set up the local directory to push to that remote.
Here’s that initial push. Then I told it:
OK do the rest, commit and push often
And that was almost it!
I set my laptop to not fall asleep and left it to its devices while we went off to buy a Christmas tree. The “commit and push often” meant I could monitor its progress on my phone by refreshing the commit log on GitHub.
I was running this against my $20/month ChatGPT Plus account, which has a five hour token allowance window for Codex CLI. That ran out at 6:35pm and Codex paused, so I waited until the reset point at 7:14pm and typed:
Keep going
At 9:30pm it declared itself done with the following summary message:
• What’s Done
- html5lib-tests now run in CI and pass: tokenizer 6810/6810, tree 1770/1782
(12 skipped: #script-on), serializer 230/230, encoding 82/83 (1 skipped:
scripted) (.github/workflows/test.yml:1).
- Public API expanded: stream() (src/stream.js:1), CSS selectors query()/
matches() (src/selector.js:1), and toMarkdown() (src/markdown.js:1), all
exported via src/index.js:1.
- Added no-deps unit scripts for selectors/stream/markdown (scripts/run-
selector-tests.js:1, scripts/run-stream-tests.js:1, scripts/run-markdown-
tests.js:1) and wired them into CI.
- Fixed TreeBuilder so <br> no longer closes <p> (src/treebuilder.js:647).
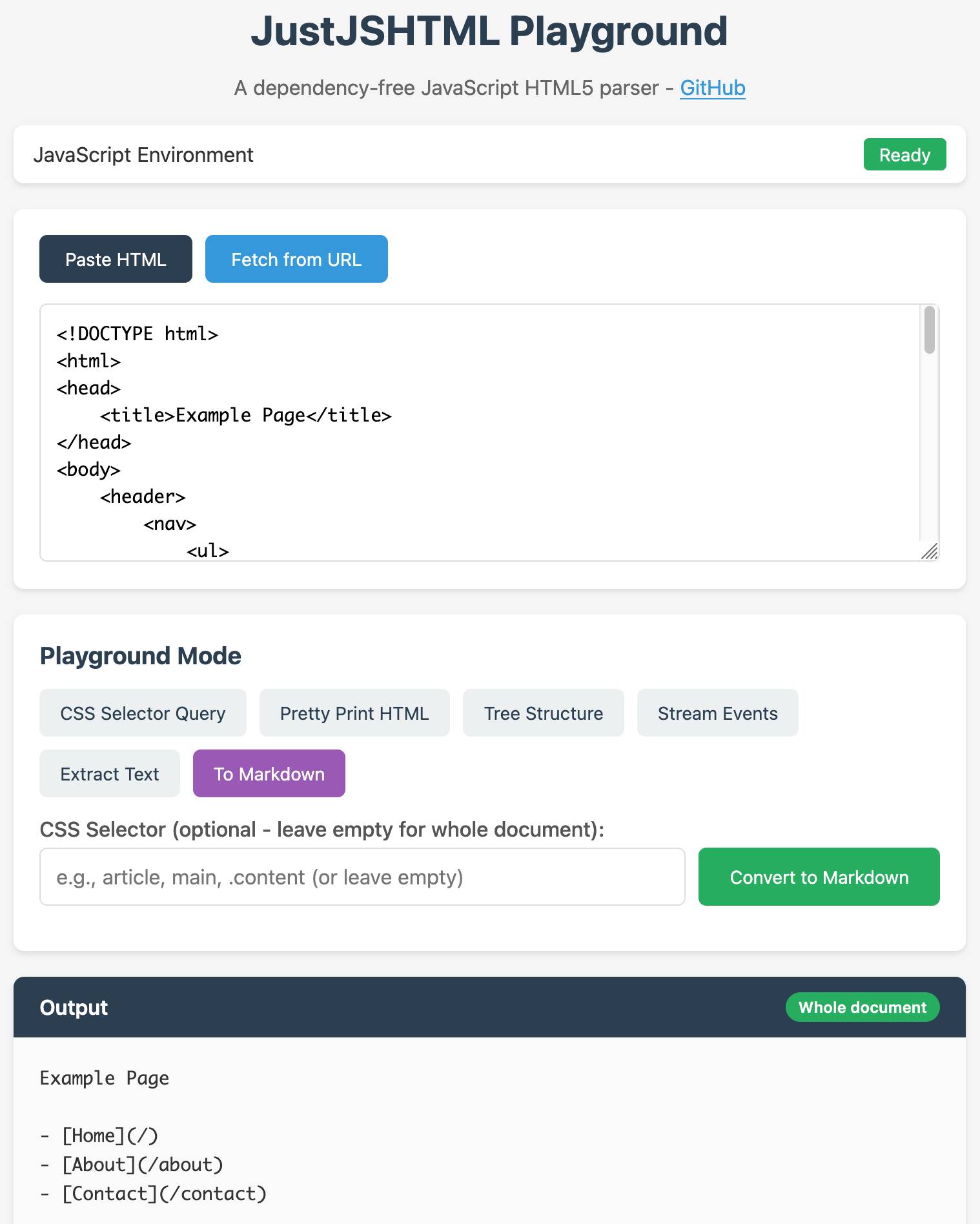
As a finishing touch, I had it add a playground interface so I could try out the new library in my browser. I prompted:
Add a playground.html in the top level folder which loads the necessary ES modules from ./src/... and implements the exact same functionality as seen on https://tools.simonwillison.net/justhtml but using the JavaScript library instead of Pyodide
It fetched my existing JustHTML playground page (described here) using curl and built a new playground.html file that loaded the new JavaScript code instead. This worked perfectly.
I enabled GitHub Pages for my still-private repo which meant I could access the new playground at this URL:
https://simonw.github.io/justjshtml/playground.html