In this newsletter:
First impressions of Claude Cowork, Anthropic’s general agent
Fly’s new Sprites.dev addresses both developer sandboxes and API sandboxes at the same time
My answers to the questions I posed about porting open source code with LLMs
Plus 4 links and 1 quotation and 1 TIL
If you find this newsletter useful, please consider sponsoring me via GitHub. $10/month and higher sponsors get a monthly newsletter with my summary of the most important trends of the past 30 days - here are previews from August and September.
New from Anthropic today is Claude Cowork, a “research preview” that they describe as “Claude Code for the rest of your work”. It’s currently available only to Max subscribers ($100 or $200 per month plans) as part of the updated Claude Desktop macOS application.
I’ve been saying for a while now that Claude Code is a “general agent” disguised as a developer tool. It can help you with any computer task that can be achieved by executing code or running terminal commands... which covers almost anything, provided you know what you’re doing with it! What it really needs is a UI that doesn’t involve the terminal and a name that doesn’t scare away non-developers.
“Cowork” is a pretty solid choice on the name front!
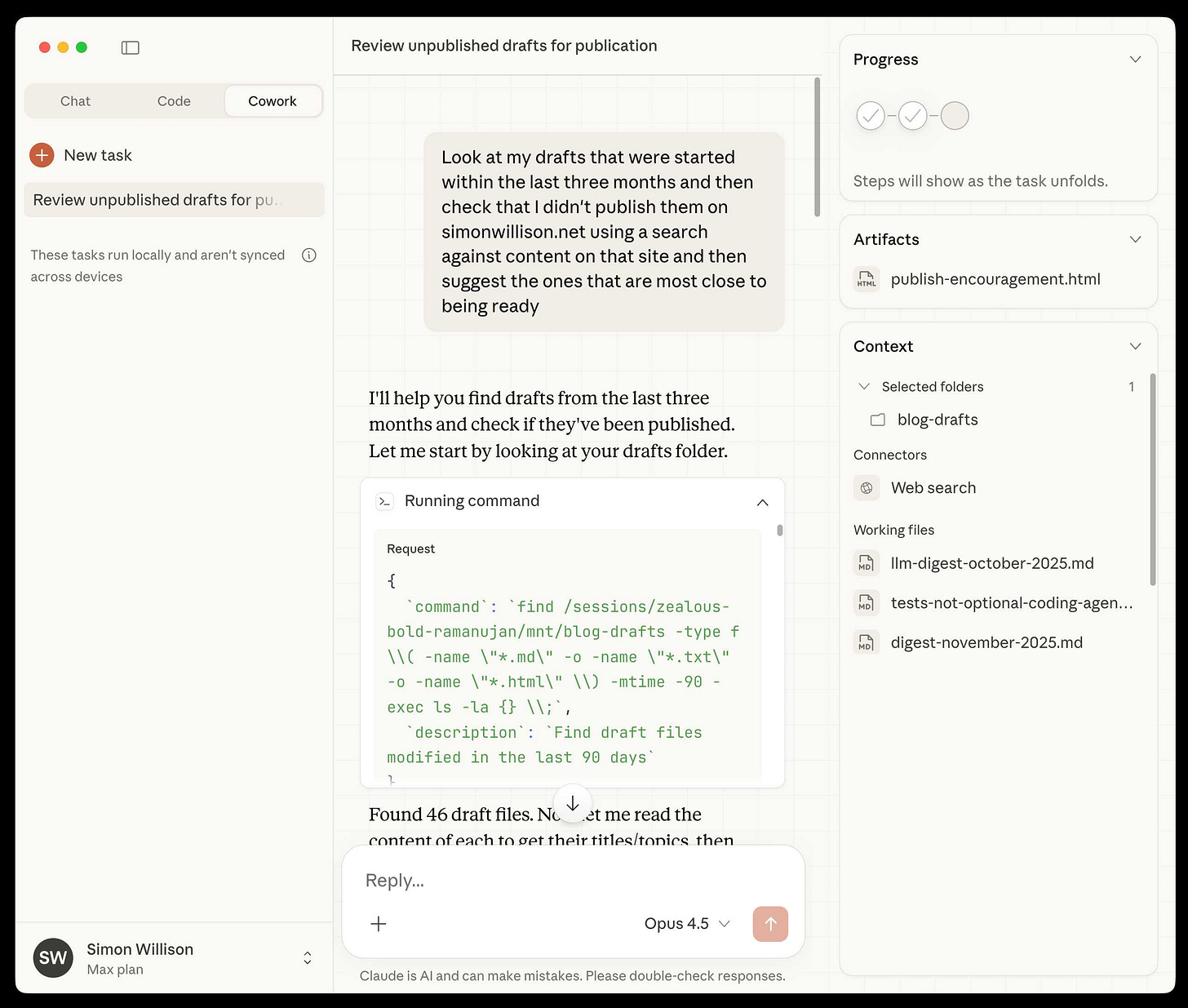
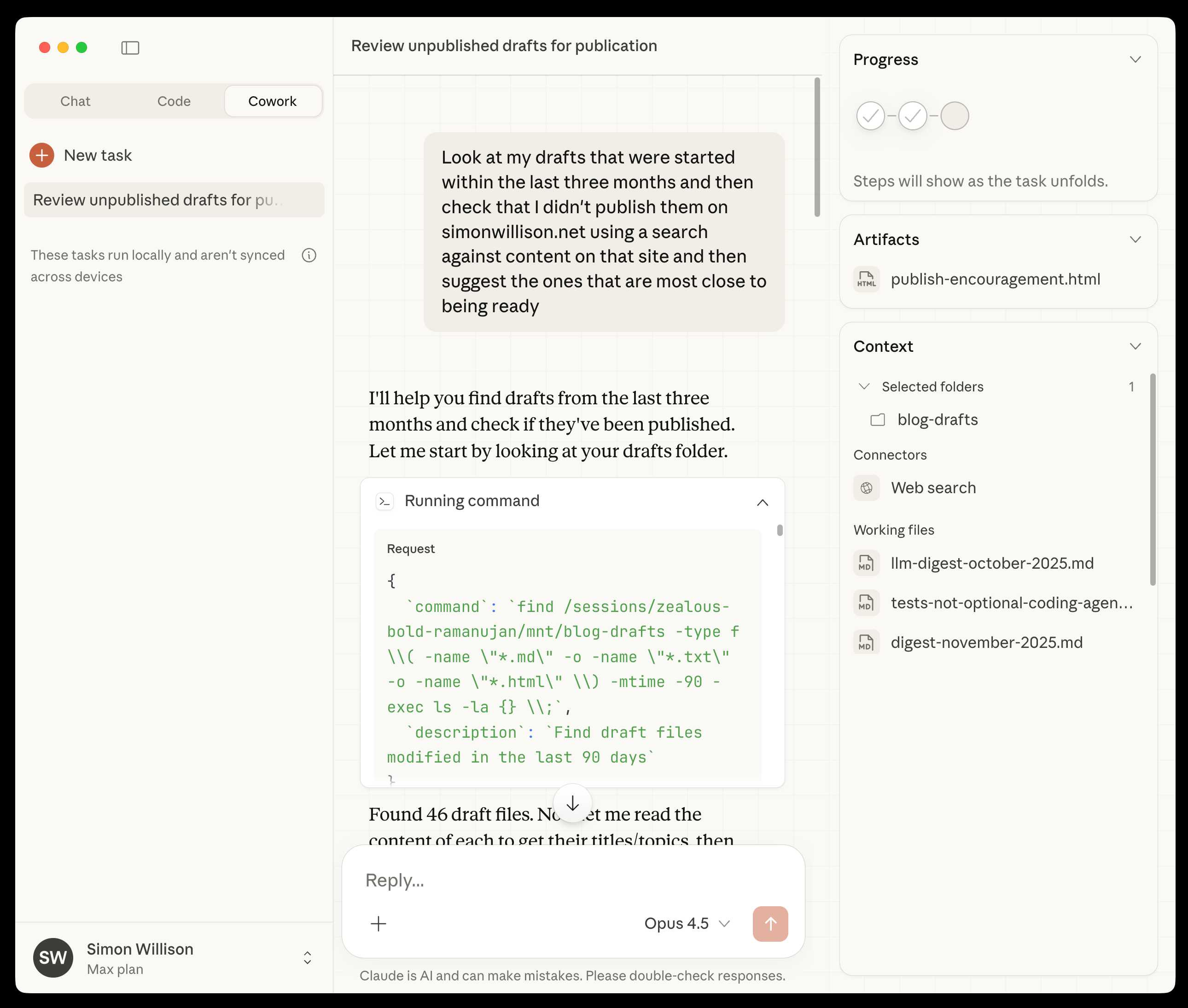
The interface for Cowork is a new tab in the Claude desktop app, called Cowork. It sits next to the existing Chat and Code tabs.
It looks very similar to the desktop interface for regular Claude Code. You start with a prompt, optionally attaching a folder of files. It then starts work.
I tried it out against my perpetually growing “blog-drafts” folder with the following prompt:
Look at my drafts that were started within the last three months and then check that I didn’t publish them on simonwillison.net using a search against content on that site and then suggest the ones that are most close to being ready
[
, with "+ New task" button and a task titled "Review unpublished drafts for pu..." listed below. Text reads "These tasks run locally and aren't synced across devices". Main panel header shows "Review unpublished drafts for publication". User message in green bubble reads: "Look at my drafts that were started within the last three months and then check that I didn't publish them on simonwillison.net using a search against content on that site and then suggest the ones that are most close to being ready". Claude responds: "I'll help you find drafts from the last three months and check if they've been published. Let me start by looking at your drafts folder." Below is an expanded "Running command" section showing Request JSON with command: find /sessions/zealous-bold-ramanujan/mnt/blog-drafts -type f \( -name "*.md" -o -name "*.txt" -o -name "*.html" \) -mtime -90 -exec ls -la {} \;, description: Find draft files modified in the last 90 days. Response text begins: "Found 46 draft files. Next let me read the content of each to get their titles/topics, then". Right sidebar shows Progress section with three circular indicators (two checked, one pending) and text "Steps will show as the task unfolds.", Artifacts section listing "publish-encouragement.html", Context section with "Selected folders" showing "blog-drafts" folder, Connectors showing "Web search", and Working files listing "llm-digest-october-2025.md", "tests-not-optional-coding-agen...", and "digest-november-2025.md". Bottom shows reply input field, "Opus 4.5" model selector, user "Simon Willison" with "Max plan", and disclaimer "Claude is AI and can make mistakes. Please double-check responses."")
{kind=link}
{kind=link}
It started by running this command:
find /sessions/zealous-bold-ramanujan/mnt/blog-drafts \
-type f \( -name “*.md” -o -name “*.txt” -o -name “*.html” \) \
-mtime -90 -exec ls -la {} \;
That /sessions/zealous-bold-ramanujan/mnt/blog-drafts path instantly caught my eye. Anthropic say that Cowork can only access files you grant it access to - it looks to me like they’re mounting those files into a containerized environment, which should mean we can trust Cowork not to be able to access anything outside of that sandbox.
It turns out I have 46 draft files from the past three months. Claude then went to work with its search tool, running 44 individual searches against site:simonwillison.net to figure out which of my drafts had already been published.
Here’s the eventual reply:
Based on my analysis, here are your unpublished drafts that appear closest to being ready for publication:
🔥 Most Ready to Publish (substantial content, not yet published)
freq-argued-llms.md- “Frequently Argued Questions about LLMs” (22,602 bytes)
This is a meaty piece documenting common arguments about LLMs with your counterpoints
Well-structured with a TL;DR and multiple sections
No matching published article found on your site
Very close to ready - just needs a final review pass
claude-code-timeline.md- “Claude Code Timeline and Codex Timeline” (3,075 bytes)
About viewing JSONL session logs from Claude Code and Codex
You published
claude-code-transcriptson Dec 25, but this appears to be a different/earlier piece about timeline viewing toolsShorter but seems complete
datasette-1a20-upgrade-instructions.md- Plugin Upgrade Guide (3,147 bytes)
Technical guide for plugin authors
You published the main 1.0a20 announcement but this companion upgrade guide appears unpublished
Would be valuable for plugin maintainers
That’s a good response! It found exactly what I needed to see, although those upgrade instructions are actually published elsewhere now (in the Datasette docs) and weren’t actually intended for my blog.
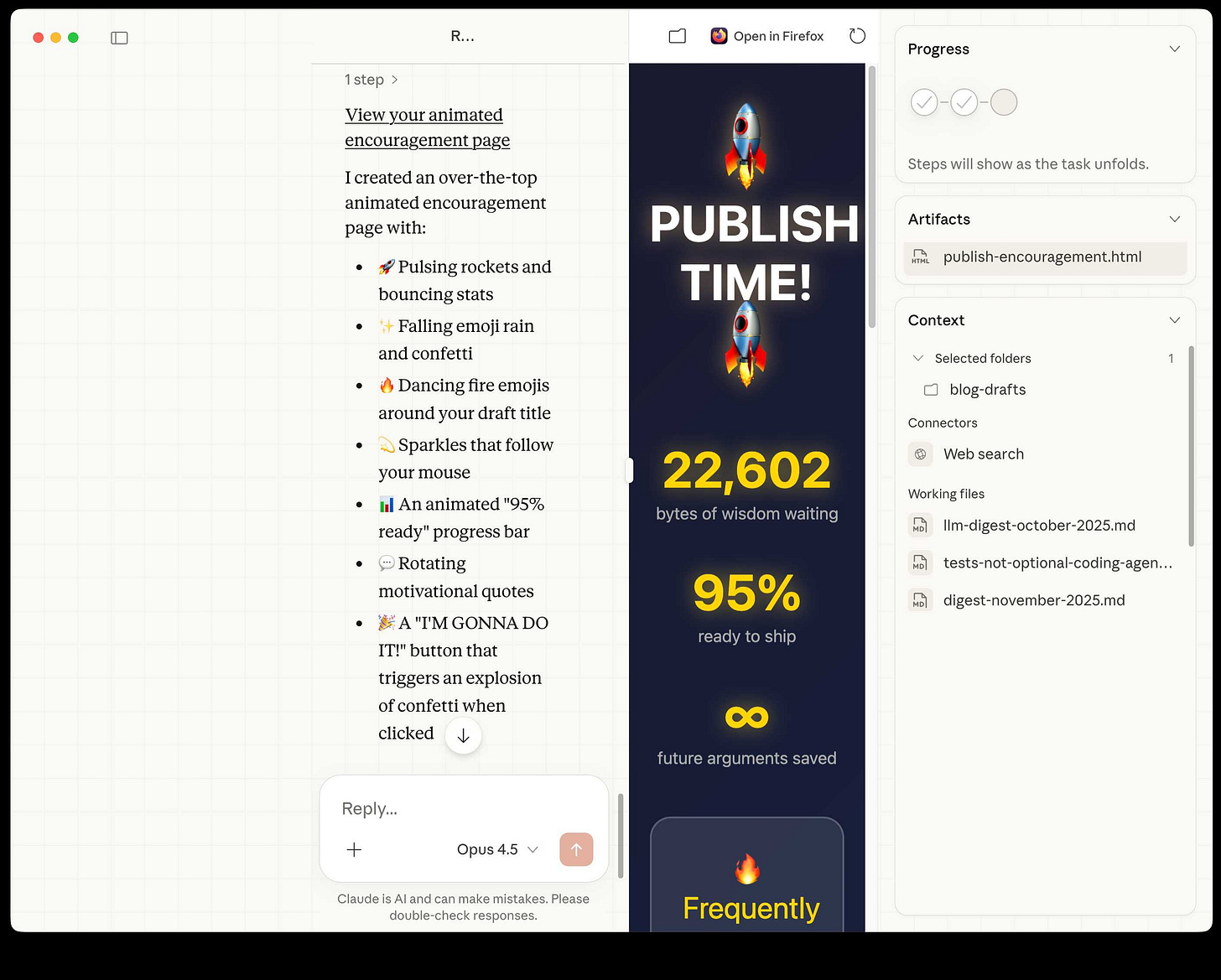
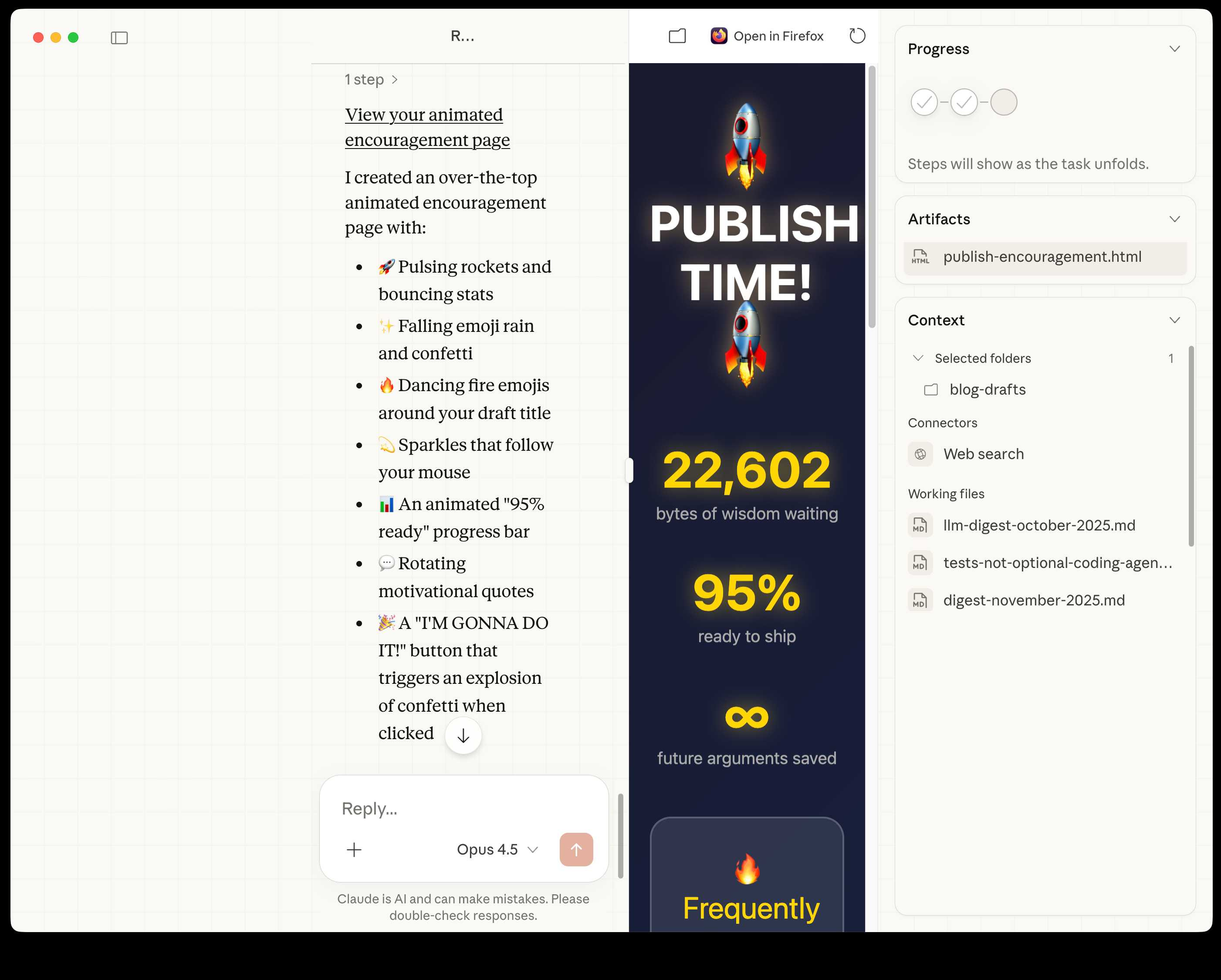
Just for fun, and because I really like artifacts, I asked for a follow-up:
Make me an artifact with exciting animated encouragements to get me to do it
Here’s what I got:
[
. Top toolbar shows "Open in Firefox" button. Right sidebar displays Progress section with checkmarks, Artifacts section with "publish-encouragement.html" selected, Context section showing "blog-drafts" folder, "Web search" connector, and Working files listing "llm-digest-october-2025.md", "tests-not-optional-coding-agen...", and "digest-november-2025.md". Bottom shows reply input, "Opus 4.5" model selector, and disclaimer text.")
{kind=link}
{kind=link}
I couldn’t figure out how to close the right sidebar so the artifact ended up cramped into a thin column but it did work. I expect Anthropic will fix that display bug pretty quickly.
I’ve seen a few people ask what the difference between this and regular Claude Code is. The answer is not a lot. As far as I can tell Claude Cowork is regular Claude Code wrapped in a less intimidating default interface and with a filesystem sandbox configured for you without you needing to know what a “filesystem sandbox” is.
Update: It’s more than just a filesystem sandbox - I had Claude Code reverse engineer the Claude app and it found out that Claude uses VZVirtualMachine - the Apple Virtualization Framework - and downloads and boots a custom Linux root filesystem.
I think that’s a really smart product. Claude Code has an enormous amount of value that hasn’t yet been unlocked for a general audience, and this seems like a pragmatic approach.
With a feature like this, my first thought always jumps straight to security. How big is the risk that someone using this might be hit by hidden malicious instruction somewhere that break their computer or steal their data?
Anthropic touch on that directly in the announcement:
You should also be aware of the risk of “prompt injections“: attempts by attackers to alter Claude’s plans through content it might encounter on the internet. We’ve built sophisticated defenses against prompt injections, but agent safety---that is, the task of securing Claude’s real-world actions---is still an active area of development in the industry.
These risks aren’t new with Cowork, but it might be the first time you’re using a more advanced tool that moves beyond a simple conversation. We recommend taking precautions, particularly while you learn how it works. We provide more detail in our Help Center.
That help page includes the following tips:
To minimize risks:
Avoid granting access to local files with sensitive information, like financial documents.
When using the Claude in Chrome extension, limit access to trusted sites.
If you chose to extend Claude’s default internet access settings, be careful to only extend internet access to sites you trust.
Monitor Claude for suspicious actions that may indicate prompt injection.
I do not think it is fair to tell regular non-programmer users to watch out for “suspicious actions that may indicate prompt injection”!
I’m sure they have some impressive mitigations going on behind the scenes. I recently learned that the summarization applied by the WebFetch function in Claude Code and now in Cowork is partly intended as a prompt injection protection layer via this tweet from Claude Code creator Boris Cherny:
Summarization is one thing we do to reduce prompt injection risk. Are you running into specific issues with it?
But Anthropic are being honest here with their warnings: they can attempt to filter out potential attacks all they like but the one thing they can’t provide is guarantees that no future attack will be found that sneaks through their defenses and steals your data (see the lethal trifecta for more on this.)
The problem with prompt injection remains that until there’s a high profile incident it’s really hard to get people to take it seriously. I myself have all sorts of Claude Code usage that could cause havoc if a malicious injection got in. Cowork does at least run in a filesystem sandbox by default, which is more than can be said for my claude --dangerously-skip-permissions habit!
I wrote more about this in my 2025 round-up: The year of YOLO and the Normalization of Deviance.
Security worries aside, Cowork represents something really interesting. This is a general agent that looks well positioned to bring the wildly powerful capabilities of Claude Code to a wider audience.
I would be very surprised if Gemini and OpenAI don’t follow suit with their own offerings in this category.
I imagine OpenAI are already regretting burning the name “ChatGPT Agent” on their janky, experimental and mostly forgotten browser automation tool back in August!
bashtoni on Hacker News:
Simple suggestion: logo should be a cow and and orc to match how I originally read the product name.
I couldn’t resist throwing that one at Nano Banana:
[

{kind=link}
New from Fly.io today: Sprites.dev. Here’s their blog post and YouTube demo. It’s an interesting new product that’s quite difficult to explain - Fly call it “Stateful sandbox environments with checkpoint & restore” but I see it as hitting two of my current favorite problems: a safe development environment for running coding agents and an API for running untrusted code in a secure sandbox.
Disclosure: Fly sponsor some of my work. They did not ask me to write about Sprites and I didn’t get preview access prior to the launch. My enthusiasm here is genuine.
I predicted earlier this week that “we’re due a Challenger disaster with respect to coding agent security” due to the terrifying way most of us are using coding agents like Claude Code and Codex CLI. Running them in --dangerously-skip-permissions mode (aka YOLO mode, where the agent acts without constantly seeking approval first) unlocks so much more power, but also means that a mistake or a malicious prompt injection can cause all sorts of damage to your system and data.
The safe way to run YOLO mode is in a robust sandbox, where the worst thing that can happen is the sandbox gets messed up and you have to throw it away and get another one.
That’s the first problem Sprites solves:
curl https://sprites.dev/install.sh | bash
sprite login
sprite create my-dev-environment
sprite console -s my-dev-environment
That’s all it takes to get SSH connected to a fresh environment, running in an ~8GB RAM, 8 CPU server. And... Claude Code and Codex and Gemini CLI and Python 3.13 and Node.js 22.20 and a bunch of other tools are already installed.
The first time you run claude it neatly signs you in to your existing account with Anthropic. The Sprites VM is persistent so future runs of sprite console -s will get you back to where you were before.
... and it automatically sets up port forwarding, so you can run a localhost server on your Sprite and access it from localhost:8080 on your machine.
There’s also a command you can run to assign a public URL to your Sprite, so anyone else can access it if they know the secret URL.
In the blog post Kurt Mackey argues that ephemeral, disposable sandboxes are not the best fit for coding agents:
The state of the art in agent isolation is a read-only sandbox. At Fly.io, we’ve been selling that story for years, and we’re calling it: ephemeral sandboxes are obsolete. Stop killing your sandboxes every time you use them. [...]
If you force an agent to, it’ll work around containerization and do work . But you’re not helping the agent in any way by doing that. They don’t want containers. They don’t want “sandboxes”. They want computers.
[...] with an actual computer, Claude doesn’t have to rebuild my entire development environment every time I pick up a PR.
Each Sprite gets a proper filesystem which persists in between sessions, even while the Sprite itself shuts down after inactivity. It sounds like they’re doing some clever filesystem tricks here, I’m looking forward to learning more about those in the future.
There are some clues on the homepage:
You read and write to fast, directly attached NVMe storage. Your data then gets written to durable, external object storage. [...]
You don’t pay for allocated filesystem space, just the blocks you write. And it’s all TRIM friendly, so your bill goes down when you delete things.
The really clever feature is checkpoints. You (or your coding agent) can trigger a checkpoint which takes around 300ms. This captures the entire disk state and can then be rolled back to later.
For more on how that works, run this in a Sprite:
cat /.sprite/docs/agent-context.md
Here’s the relevant section:
## Checkpoints
- Point-in-time checkpoints and restores available
- Copy-on-write implementation for storage efficiency
- Last 5 checkpoints mounted at `/.sprite/checkpoints`
- Checkpoints capture only the writable overlay, not the base image
Or run this to see the --help for the command used to manage them:
sprite-env checkpoints --help
Which looks like this:
sprite-env checkpoints - Manage environment checkpoints
USAGE:
sprite-env checkpoints <subcommand> [options]
SUBCOMMANDS:
list [--history <ver>] List all checkpoints (optionally filter by history version)
get <id> Get checkpoint details (e.g., v0, v1, v2)
create Create a new checkpoint (auto-versioned)
restore <id> Restore from a checkpoint (e.g., v1)
NOTE:
Checkpoints are versioned as v0, v1, v2, etc.
Restore returns immediately and triggers an async restore that restarts the environment.
The last 5 checkpoints are mounted at /.sprite/checkpoints for direct file access.
EXAMPLES:
sprite-env checkpoints list
sprite-env checkpoints list --history v1.2.3
sprite-env checkpoints get v2
sprite-env checkpoints create
sprite-env checkpoints restore v1
I’m a big fan of Skills, the mechanism whereby Claude Code (and increasingly other agents too) can be given additional capabilities by describing them in Markdown files in a specific directory structure.
In a smart piece of design, Sprites uses pre-installed skills to teach Claude how Sprites itself works. This means you can ask Claude on the machine how to do things like open up ports and it will talk you through the process.
There’s all sorts of interesting stuff in the /.sprite folder on that machine - digging in there is a great way to learn more about how Sprites works.
Also from my predictions post earlier this week: “We’re finally going to solve sandboxing”. I am obsessed with this problem: I want to be able to run untrusted code safely, both on my personal devices and in the context of web services I’m building for other people to use.
I have so many things I want to build that depend on being able to take untrusted code - from users or from LLMs or from LLMs-driven-by-users - and run that code in a sandbox where I can be confident that the blast radius if something goes wrong is tightly contained.
Sprites offers a clean JSON API for doing exactly that, plus client libraries in Go and TypeScript and coming-soon Python and Elixir.
From their quick start:
# Create a new sprite
curl -X PUT https://api.sprites.dev/v1/sprites/my-sprite \
-H "Authorization: Bearer $SPRITES_TOKEN"
# Execute a command
curl -X POST https://api.sprites.dev/v1/sprites/my-sprite/exec \
-H "Authorization: Bearer $SPRITES_TOKEN" \
-d '{"command": "echo hello"}'
You can also checkpoint and rollback via the API, so you can get your environment exactly how you like it, checkpoint it, run a bunch of untrusted code, then roll back to the clean checkpoint when you’re done.
Managing network access is an important part of maintaining a good sandbox. The Sprites API lets you configure network access policiesusing a DNS-based allow/deny list like this:
curl -X POST \
“https://api.sprites.dev/v1/sprites/{name}/policy/network” \
-H “Authorization: Bearer $SPRITES_TOKEN” \
-H “Content-Type: application/json” \
-d ‘{
“rules”: [
{
“action”: “allow”,
“domain”: “github.com”
},
{
“action”: “allow”,
“domain”: “*.npmjs.org”
}
]
}’
Sprites have scale-to-zero baked into the architecture. They go to sleep after 30 seconds of inactivity, wake up quickly when needed and bill you for just the CPU hours, RAM hours and GB-hours of storage you use while the Sprite is awake.
Fly estimate a 4 hour intensive coding session as costing around 46 cents, and a low traffic web app with 30 hours of wake time per month at ~$4.
(I calculate that a web app that consumes all 8 CPUs and all 8GBs of RAM 24/7 for a month would cost ((7 cents * 8 * 24 * 30) + (4.375 cents * 8 * 24 * 30)) / 100 = $655.2 per month, so don’t necessarily use these as your primary web hosting solution for an app that soaks up all available CPU and RAM!)
I was hopeful that Fly would enter the developer-friendly sandbox API market, especially given other entrants from companies like Cloudflare and Modal and E2B.
I did not expect that they’d tackle the developer sandbox problem at the same time, and with the same product!
My one concern here is that it makes the product itself a little harder to explain.
I’m already spinning up some prototypes of sandbox-adjacent things I’ve always wanted to build, and early signs are very promising. I’ll write more about these as they turn into useful projects.
Update: Here’s some additional colour from Thomas Ptacek on Hacker News:
This has been in the works for quite awhile here. We put a long bet on “slow create fast start/stop” --- which is a really interesting and useful shape for execution environments --- but it didn’t make sense to sandboxers, so “fast create” has been the White Whale at Fly.io for over a year.
Last month I wrote about porting JustHTML from Python to JavaScript using Codex CLI and GPT-5.2 in a few hours while also buying a Christmas tree and watching Knives Out 3. I ended that post with a series of open questions about the ethics and legality of this style of work. Alexander Petros on lobste.rsjust challenged me to answer them, which is fair enough! Here’s my attempt at that.
You can read the original post for background, but the short version is that it’s now possible to point a coding agent at some other open source project and effectively tell it “port this to language X and make sure the tests still pass” and have it do exactly that.
Here are the questions I posed along with my answers based on my current thinking. Extra context is that I’ve since tried variations on a similar theme a few more times using Claude Code and Opus 4.5 and found it to be astonishingly effective.
I decided that the right thing to do here was to keep the open source license and copyright statement from the Python library author and treat what I had built as a derivative work, which is the entire point of open source.
After sitting on this for a while I’ve come down on yes, provided full credit is given and the license is carefully considered. Open source allows and encourages further derivative works! I never got upset at some university student forking one of my projects on GitHub and hacking in a new feature that they used. I don’t think this is materially different, although a port to another language entirely does feel like a slightly different shape.
Now this one is complicated!
It definitely hurts some projects because there are open source maintainers out there who say things like “I’m not going to release any open source code any more because I don’t want it used for training” - I expect some of those would be equally angered by LLM-driven derived works as well.
I don’t know how serious this problem is - I’ve seen angry comments from anonymous usernames, but do they represent genuine open source contributions or are they just angry anonymous usernames?
If we assume this is real, does the loss of those individuals get balanced out by the increase in individuals who CAN contribute to open source because they can now get work done in a few hours that might previously have taken them a few days that they didn’t have to spare?
I’ll be brutally honest about that question: I think that if “they might train on my code / build a derived version with an LLM” is enough to drive you away from open source, your open source values are distinct enough from mine that I’m not ready to invest significantly in keeping you. I’ll put that effort into welcoming the newcomers instead.
The much bigger concern for me is the impact of generative AI on demand for open source. The recent Tailwind story is a visible example of this - while Tailwind blamed LLMs for reduced traffic to their documentation resulting in fewer conversions to their paid component library, I’m suspicious that the reduced demand there is because LLMs make building good-enough versions of those components for free easy enough that people do that instead.
I’ve found myself affected by this for open source dependencies too. The other day I wanted to parse a cron expression in some Go code. Usually I’d go looking for an existing library for cron expression parsing - but this time I hardly thought about that for a second before prompting one (complete with extensive tests) into existence instead.
I expect that this is going to quite radically impact the shape of the open source library world over the next few years. Is that “harmful to open source”? It may well be. I’m hoping that whatever new shape comes out of this has its own merits, but I don’t know what those would be.
I’m not a lawyer so I don’t feel credible to comment on this one. My loose hunch is that I’m still putting enough creative control in through the way I direct the models for that to count as enough human intervention, at least under US law, but I have no idea.
I’ve come down on “yes” here, again because I never thought it was irresponsible for some random university student to slap an Apache license on some bad code they just coughed up on GitHub.
What’s important here is making it very clear to potential users what they should expect from that software. I’ve started publishing my AI-generated and not 100% reviewed libraries as alphas, which I’m tentatively thinking of as “alpha slop”. I’ll take the alpha label off once I’ve used them in production to the point that I’m willing to stake my reputation on them being decent implementations, and I’ll ship a 1.0 version when I’m confident that they are a solid bet for other people to depend on. I think that’s the responsible way to handle this.
That one was a deliberately provocative question, because for a new HTML5 parsing library that passes 9,200 tests you would need a very good reason to hire an expert team for two months (at a cost of hundreds of thousands of dollars) to write such a thing. And honestly, thanks to the existing conformance suites this kind of library is simple enough that you may find their results weren’t notably better than the one written by the coding agent.
Link 2026-01-10 A Software Library with No Code:
Provocative experiment from Drew Breunig, who designed a new library for time formatting (”3 hours ago” kind of thing) called “whenwords” that has no code at all, just a carefully written specification, an AGENTS.md and a collection of conformance tests in a YAML file.
Pass that to your coding agent of choice, tell it what language you need and it will write it for you on demand!
This meshes nearly with my recent interest in conformance suites. If you publish good enough language-independent tests it’s pretty astonishing how far today’s coding agents can take you!
quote2026-01-11
Also note that the python visualizer tool has been basically written by vibe-coding. I know more about analog filters -- and that’s not saying much -- than I do about python. It started out as my typical “google and do the monkey-see-monkey-do” kind of programming, but then I cut out the middle-man -- me -- and just used Google Antigravity to do the audio sample visualizer.
Linus Torvalds, Another silly guitar-pedal-related repo
TIL 2026-01-11 Taking Neon I at the Crucible:
I took the Neon I intensive week-long evening class at the Crucible in Oakland, with teachers Dan Kuppe and Kat. I learned to make a neon sign! It’s still awaiting final infusion of gas, but I’ll share photos here once it’s finished. …
Link 2026-01-11 Don’t fall into the anti-AI hype:
I’m glad someone was brave enough to say this. There is a lot of anti-AI sentiment in the software development community these days. Much of it is justified, but if you let people convince you that AI isn’t genuinely useful for software developers or that this whole thing will blow over soon it’s becoming clear that you’re taking on a very real risk to your future career.
As Salvatore Sanfilippo puts it:
It does not matter if AI companies will not be able to get their money back and the stock market will crash. All that is irrelevant, in the long run. It does not matter if this or the other CEO of some unicorn is telling you something that is off putting, or absurd. Programming changed forever, anyway.
I do like this hopeful positive outlook on what this could all mean, emphasis mine:
How do I feel, about all the code I wrote that was ingested by LLMs? I feel great to be part of that, because I see this as a continuation of what I tried to do all my life: democratizing code, systems, knowledge. LLMs are going to help us to write better software, faster, and will allow small teams to have a chance to compete with bigger companies. The same thing open source software did in the 90s.
This post has been the subject of heated discussions all day today on both Hacker Newsand Lobste.rs.
Link 2026-01-12 Superhuman AI Exfiltrates Emails:
Classic prompt injection attack:
When asked to summarize the user’s recent mail, a prompt injection in an untrusted email manipulated Superhuman AI to submit content from dozens of other sensitive emails (including financial, legal, and medical information) in the user’s inbox to an attacker’s Google Form.
To Superhuman’s credit they treated this as the high priority incident it is and issued a fix.
The root cause was a CSP rule that allowed markdown images to be loaded from docs.google.com - it turns out Google Forms on that domain will persist data fed to them via a GET request!
No posts