This week I wrote an issue on tldraw's repository about a new contributions policy. Due to an influx of low-quality AI pull requests, we would soon begin automatically closing pull requests from external contributors.
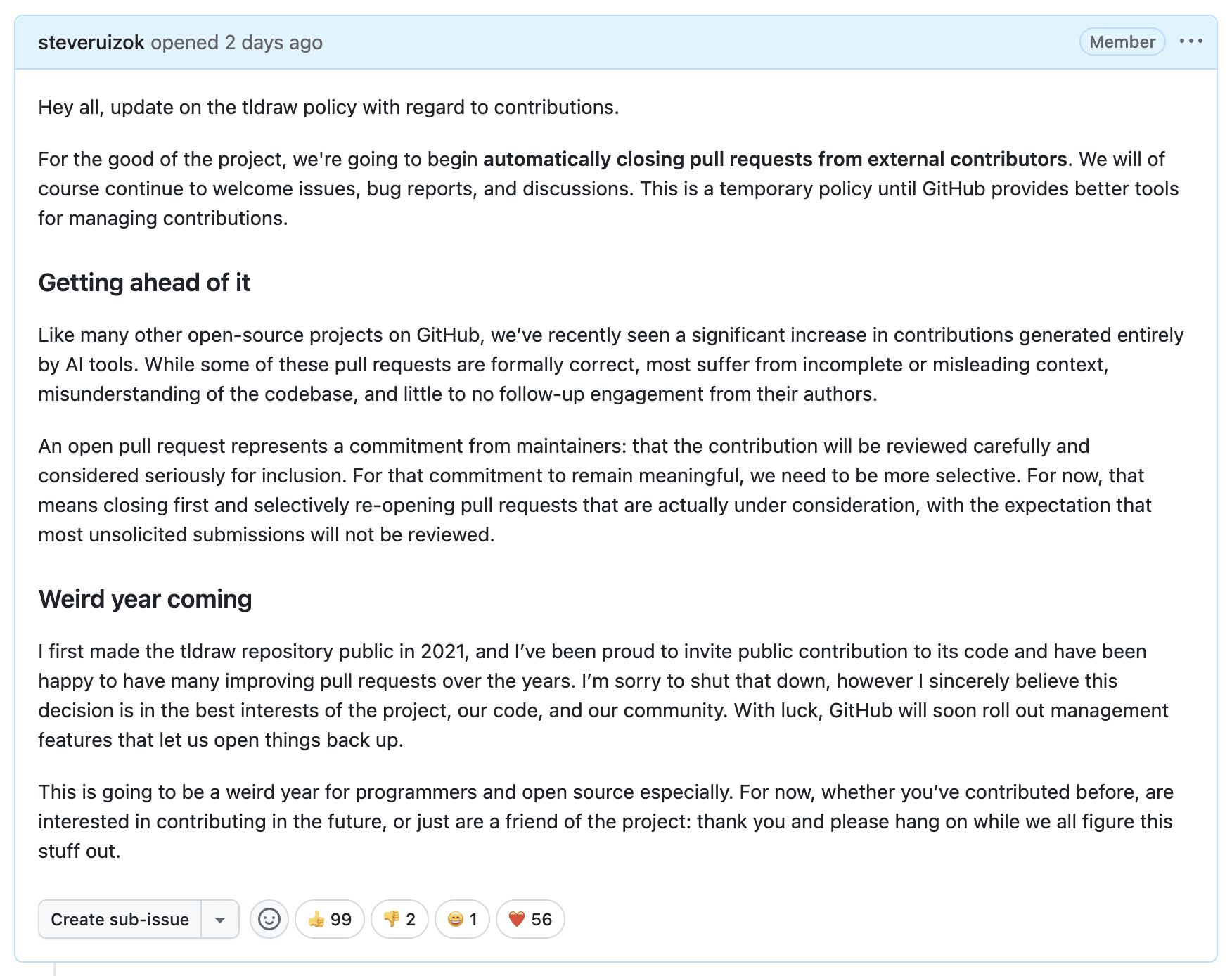
I was expecting to have to defend my decision but the response has been surprisingly positive: the problem is real, tldraw's solution seems reasonable, maybe we should do the same.
The post prompted some good conversation though on Twitter and Hacker News. Much of the discussion focused on recognizing AI code, using AI to evaluate pull requests, and generally preventing people from using AI tools to contribute.
I think this misses the point. We already accept code written with AI. I write code with AI tools. I expect my team to use AI tools too. If you know the codebase and know what you're doing, writing great code has never been easier than with these tools.
The question is more fundamental. In a world of AI coding assistants, is code from external contributors actually valuable at all?
If writing the code is the easy part, why would I want someone else to write it?
Context and contribution
Every repository gets bad pull requests. A few years ago I submitted a full TypeScript rewrite of a text editor because I thought it would be fun. I hope the maintainers didn't read it. Sorry.
One of my first big open source contributions was implementing more arrowheads for Excalidraw. I wrote the code and submitted a PR. The next day, the maintainers kindly pointed me toward their issues-first policy and closed my request.
I stuck with it, though. I was sketching state charts, I wanted the little dots on my arrows, and I cared enough to make it happen. So I stayed engaged and got caught up on the history of the problem. It turned out not to be an implementation question but a design problem. How do we let a user pick the start and end arrowheads? Which components can be adapted, which need to be created? Do we need new icons?
It took a few rounds of constructive iterations, moved along by my research and design work, before we all aligned on a solution. I wrote a new PR, we landed it, and now you can put a little dot or whatever on the end of your Excalidraw arrows.
If this were happening today, what would be different?
We would still need to have discussed the problem and designed a solution. It would have still required the sustained attention of a contributor who cared and wanted to see the change go in. My prototypes would still be useful for research and design but their cost to produce would be lower. I would have made more of them.
Once we had the context we needed and the alignment on what we would do, the final implementation would have been almost ceremonial. Who wants to push the button?
Eternal Sloptember
We'd started getting pull requests that purported to fix reported issues but which were, in retrospect, obvious "fix this issue" one-shots by an author using AI coding tools. Without broader knowledge of the codebase or the purpose of the project, the AI agents were taking the issue at face value and producing a diff. Any problems with the issue were multiplied in the pull request, leading to some of the strangest PRs I'd ever seen.
These pull requests would have been incredible a few months prior. They all looked good. They were formally correct. Tests and checks passed. We'd even started landing some. Then I started to notice unusual patterns. Authors almost always ignored our PR template. Even large PRs would be abandoned, languishing because their authors had neglected to sign our CLA. Commits would be spaced out strangely, with too-brief gaps between each commit. Checking into the authors revealed dozens of PRs across dozens of repositories. And why not?
Many other problematic contributions were more obvious by sheer weirdness. Authors would solve a problem in a way that ignored existing patterns, inlined other parts of the codebase, or went hard into a random direction. Once or twice, I would begin fixing and cleaning up these PRs, often asking my own Claude to make fixes that benefited from my wider knowledge: use this helper, use our existing UI components, etc. All the while thinking that it would have been easier to vibe code this myself.
From the discussions this week, it sounds like this is the default experience of every public repository maintainer right now. I could be describing any repo that takes external contributions. To use Excalidraw as another example: they received more than twice as many PRs in Q4 of 2025 than in Q3. While we have much less contribution, our problem recently got worse in a way that forced my hand.
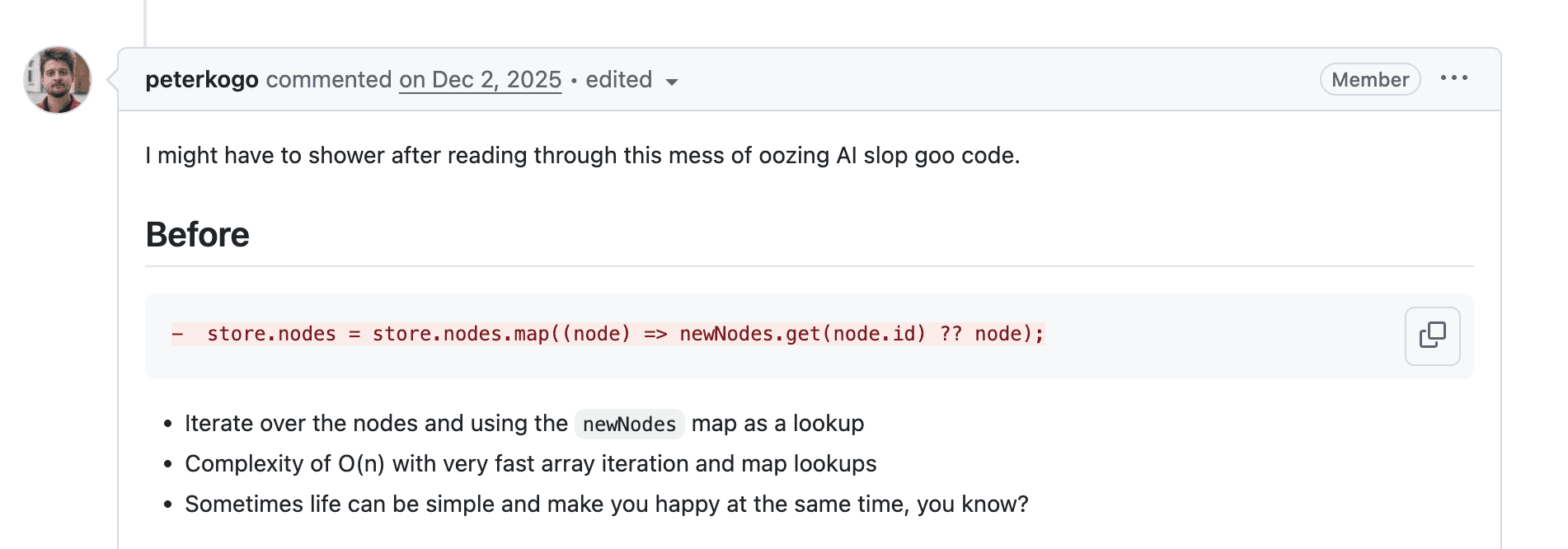
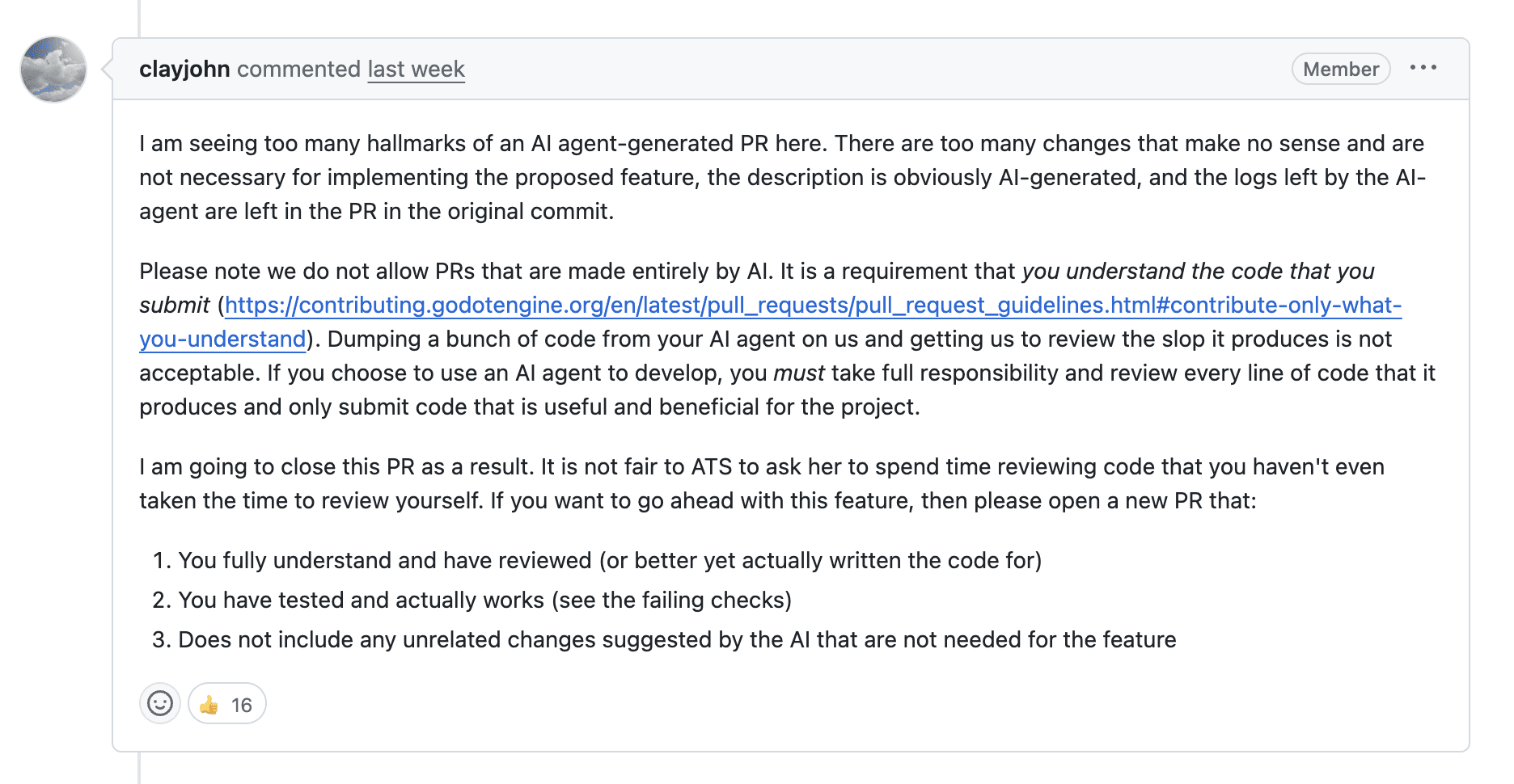
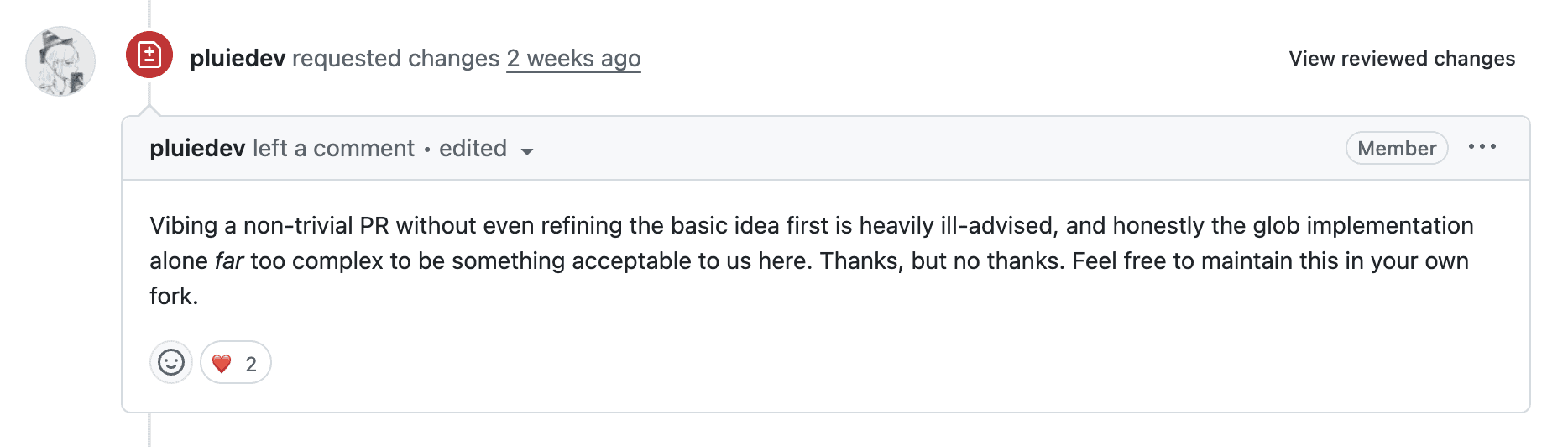
Stay away from my trash!
More recently, we started getting PRs that were better-formed but still so far off-base that I knew something had changed. These were pull requests that claimed to solve a problem we didn't have or fix a bug that didn't exist. Each was claiming to close an issue.
A glance at the linked issue confirmed the problem: one of my own AI scripts, a Claude Code /issue command, was giving bad directions.
As a high-powered tech CEO, I'm constantly running into bugs and small UX nits that I don't have time to fully document but do want to capture for later. Previously, I would fire these into Linear or our issues as empty tickets—"fix bug in sidebar"—then hope I remembered what exactly it was when I came back to it later.
To help with this, I'd created a /issue command that created well-formed issues out of these low-specificity inputs. I would run into a bug and write something quickly like /issue dot menu should stay visible when the menu is open sidebar only desktop, fire off Claude Code to try and figure it out, and continue with my work. I'd get an issue, then a follow-up reply with a root cause analysis for bugs or suggested implementation.
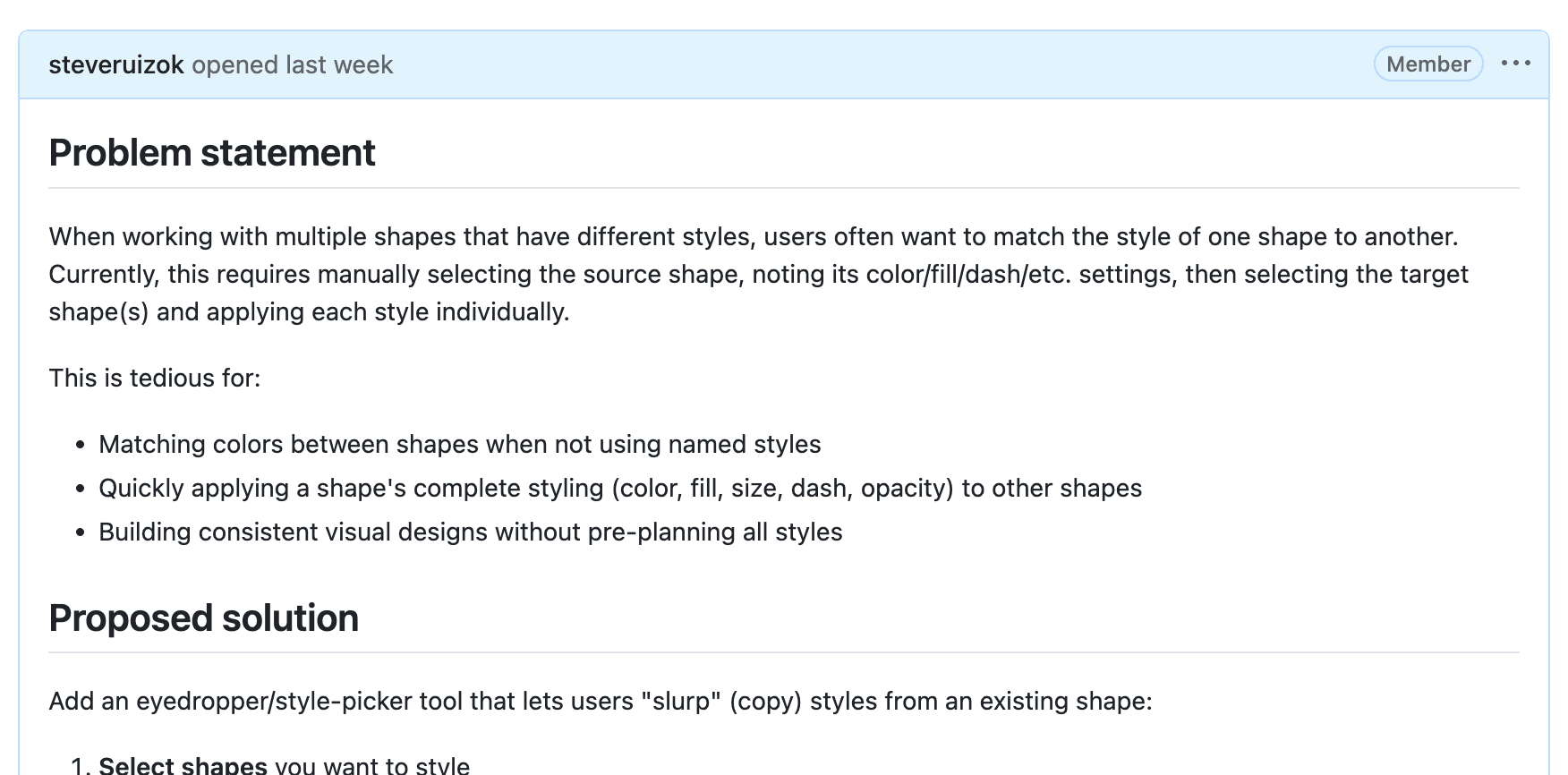
As an example, I'm pretty sure my input for this one was something like /issue you know that paint bucket in google docs i want that for tldraw so that I can copy styles from one shape and paste it to another, if those styles exist in the other shape. i want to like slurp up the styles. It was probably fewer. "Slurp" sounds like me.
When it worked—when the issue was obvious or my input was detailed enough—Claude would go off and make a well-researched issue that was ready to be solved. I'd often follow up with another command to /take the issue and take a shot at implementing it. But if the issue was complex or my input contained too little information (or if I drew an unlucky seed) then the AI would head off in the wrong direction and produce an issue with an imagined bug or junk solution. I'd close the issue, spend more time refining it, or sometimes decide that the idea was wrong to begin with.
In this system, slop is lubrication. My old "fix button" tickets were poor quality but useful. They added entropy and noise to the system but were worth it to capture a certain type of bug or idea. This new system is a similar exchange, introducing noise in exchange for other things. What's different is that this noise is well-formed noise. To an outsider, the result of my fire-and-forget "fix button" might look identical to a professional, well-researched, intellectually serious bug report.
In the past, my awful issues would have been ignored. The issues looked wrong and the effort required to produce a fix would have fallen on the author. The noise was never a problem because no one would have tried to write a high-effort diff based on such a low-effort issue.
AI changed all of that. My low-effort issues were becoming low-effort pull requests, with AI doing both sides of the work. My poor Claude had produced a nonsense issue causing the contributor's poor Claude to produce a nonsense solution.
The thing is, my shitty AI issue was providing value. The contributor's shitty AI solution was not. There was a piece in between—a part of the process I would have done but the contributor could not have done—which was to read the issue and decide whether it made sense. Instead, I'd accidentally put out a call for pointless contribution.
Where this leaves us
This leaves us at a place where the best thing to do for our codebase is to shut down external contributions, at least until GitHub offers better support for controlling who can contribute, when, and where. Assuming the social contract of code contribution remains unchanged, then we need better tools to maintain the peace.
But if you ask me, the bigger threat to GitHub's model comes from the rapid devaluation of someone else's code. When code was hard to write and low-effort work was easy to identify, it was worth the cost to review the good stuff. If code is easy to write and bad work is virtually indistinguishable from good, then the value of external contribution is probably less than zero.
If that's the case, which I'm starting to think it is, then it's better to limit community contribution to the places it still matters: reporting, discussion, perspective, and care. Don't worry about the code, I can push the button myself.