TL;DR: In this work, we introduce DFlash, a method utilizing a lightweight block diffusion model for drafting in speculative decoding. This enables efficient and high-quality parallel drafting, pushing the limits of speculative decoding. DFlash achieves up to 6.17×\mathbf{6.17\times} lossless acceleration for Qwen3-8B, nearly 2.5×\mathbf{2.5\times} faster than the state-of-the-art speculative decoding method EAGLE-3, as shown in Figure 1.
Huggingface Models: [Qwen3-4B-DFlash-b16] [Qwen3-8B-DFlash-b16] [Qwen3-Coder-30B-A3B-DFlash]
Your browser does not support the video tag.
Demo video of DFlash. DFlash achieves fast decoding with lossless generation, significantly outperforming EAGLE-3 in speed. We use JetLM/SDAR-8B-Chat-b16 with confidence-threshold sampling (0.9) for standalone block diffusion, and RedHatAI/Qwen3-8B-speculator.eagle3 with a speculation length of 7 for EAGLE-3.
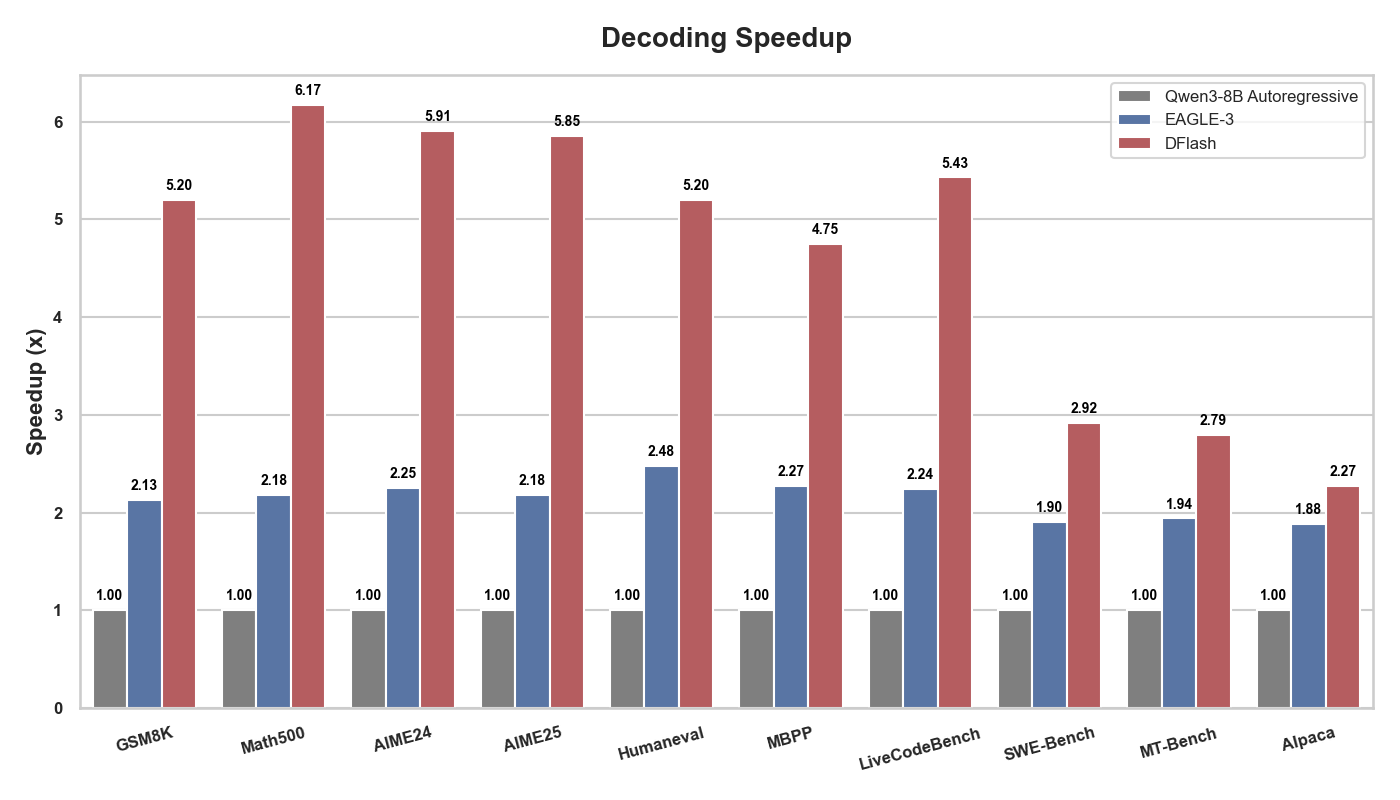
Figure 1. Speedup comparison between DFlash, EAGLE-3 against Autoregressive Decoding. Overall, DFlash achieves more than 2.5× higher speedup than EAGLE-3.
Note. Due to the lack of official EAGLE-3 checkpoints for Qwen3-4B and Qwen3-8B, we compare against RedHatAI/Qwen3-8B-speculator.eagle3 in this blog. This checkpoint is trained using the open-source speculators framework.
Quick Start
🚀 Serving with SGLang
DFlash is now supported on SGLang, enabling high-throughput speculative decoding in a production-grade serving stack.
vLLM integration is currently in progress.
Installation
uv pip install "git+https://github.com/sgl-project/sglang.git@refs/pull/16818/head#subdirectory=python"
Serving
python -m sglang.launch_server \
--model-path Qwen/Qwen3-Coder-30B-A3B-Instruct \
--speculative-algorithm DFLASH \
--speculative-draft-model-path z-lab/Qwen3-Coder-30B-A3B-DFlash \
--tp-size 1 \
--dtype bfloat16 \
--attention-backend fa3 \
--mem-fraction-static 0.75 \
--trust-remote-code
Transformers
pip install transformers==4.57.3 torch==2.9.1 accelerate
from transformers import AutoModel, AutoModelForCausalLM, AutoTokenizer
# 1. Load the DFlash Draft Model
model = AutoModel.from_pretrained(
"z-lab/Qwen3-8B-DFlash-b16",
trust_remote_code=True,
dtype="auto",
device_map="cuda:0"
).eval()
# 2. Load the Target Model
target = AutoModelForCausalLM.from_pretrained(
"Qwen/Qwen3-8B",
dtype="auto",
device_map="cuda:0"
).eval()
# 3. Load Tokenizer and Prepare Input
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
prompt = "How many positive whole-number divisors does 196 have?"
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 4. Run Speculative Decoding
generate_ids = model.spec_generate(
input_ids=model_inputs["input_ids"],
max_new_tokens=2048,
temperature=0.0,
target=target,
stop_token_ids=[tokenizer.eos_token_id]
)
print(tokenizer.decode(generate_ids[0], skip_special_tokens=True))
Why DFlash?
Autoregressive Large Language Models (LLMs) have transformed the AI landscape, but their sequential nature creates a bottleneck: inference is slow, and GPU compute is often under-utilized.
Speculative decoding addresses this bottleneck by using a small draft model to generate tokens that the target LLM verifies in parallel. While effective, state-of-the-art methods like EAGLE-3 still rely on autoregressive drafting. This serial drafting process is inefficient and prone to error accumulation, effectively capping speedups at roughly 2–3×\times for popular models like the Qwen3 series.
Diffusion LLMs (dLLMs) offer parallel text generation and bidirectional context modeling, presenting a promising alternative to autoregressive LLMs. However, current dLLMs still suffer from performance degradation compared to their autoregressive counterparts. Furthermore, their requirement for a large number of denoising steps to maintain generation quality limits their raw inference speed [1].
This presents a clear trade-off: AR models are performant but slow, while dLLMs allow for fast, parallel generation but often suffer from lower accuracy. Can we combine the strengths of both while avoiding their respective weaknesses? The natural solution is to utilize diffusion for drafting, taking advantage of parallelism, while relying on the AR model for verification.
How DFlash Works
However, using diffusion for drafting is non-trivial:
- Existing Diffusion Speculators are Impractical: Methods like DiffuSpec[2] and SpecDiff-2[3] rely on massive 7B-parameter draft models. This high memory footprint makes them prohibitively expensive for real-world serving and limits speedups to ~3-4×\times.
- Small Diffusion Models Don’t Work: Simply shrinking the diffusion drafter fails. We trained a lightweight 5-layer block diffusion model (block size 16) from scratch on data generated by Qwen3-4B and perform speculative decoding for Qwen3-4B on some math tasks. As shown in the table below, without additional help, the small model lacks the reasoning capability to align with the target, resulting in limited speedup.
| Temp | GSM8K
Speedup / τ\tau | Math500
Speedup / τ\tau | AIME24
Speedup / τ\tau | AIME25
Speedup / τ\tau | | --- | --- | --- | --- | --- | | 0 | 2.83 / 3.38 | 3.73 / 4.61 | 3.43 / 4.12 | 3.35 / 4.07 | | 1 | 2.76 / 3.29 | 3.31 / 4.12 | 2.66 / 3.23 | 2.65 / 3.24 |
Is there no free lunch? Can we build a drafter that is both small (fast) and accurate (high acceptance)?
The Key Insight: The Target Knows Best
We demonstrate that a free lunch does exist. Our key insight is that the large AR target model’s hidden features implicitly contain information about future tokens, a phenomenon also observed by [4].
Instead of asking a tiny diffusion model to reason from scratch, DFlash conditions the draft model on context features extracted from the target model. This fuses the deep reasoning capabilities of the large model with the parallel generation speed of the small diffusion drafter.
Design
Figure 2 illustrate the system design of DFlash.
- Feature Fusion: After the prefill or verification steps, we extract and fuse the hidden features from the target model.
- Conditioning: These features are fed directly into the Key/Value (K,V) projections of the draft model layers and stored in the draft model’s KV cache.
- Parallel Drafting: Conditioned on this rich context (and the last verified token), the drafter predicts the next block of tokens in parallel using diffusion.
To minimize overhead, the draft model reuses the embedding and LM head layers from the target model, and only the intermediate layers are trained. We set the number of draft layers to 5, striking a balance between draft quality and speed.
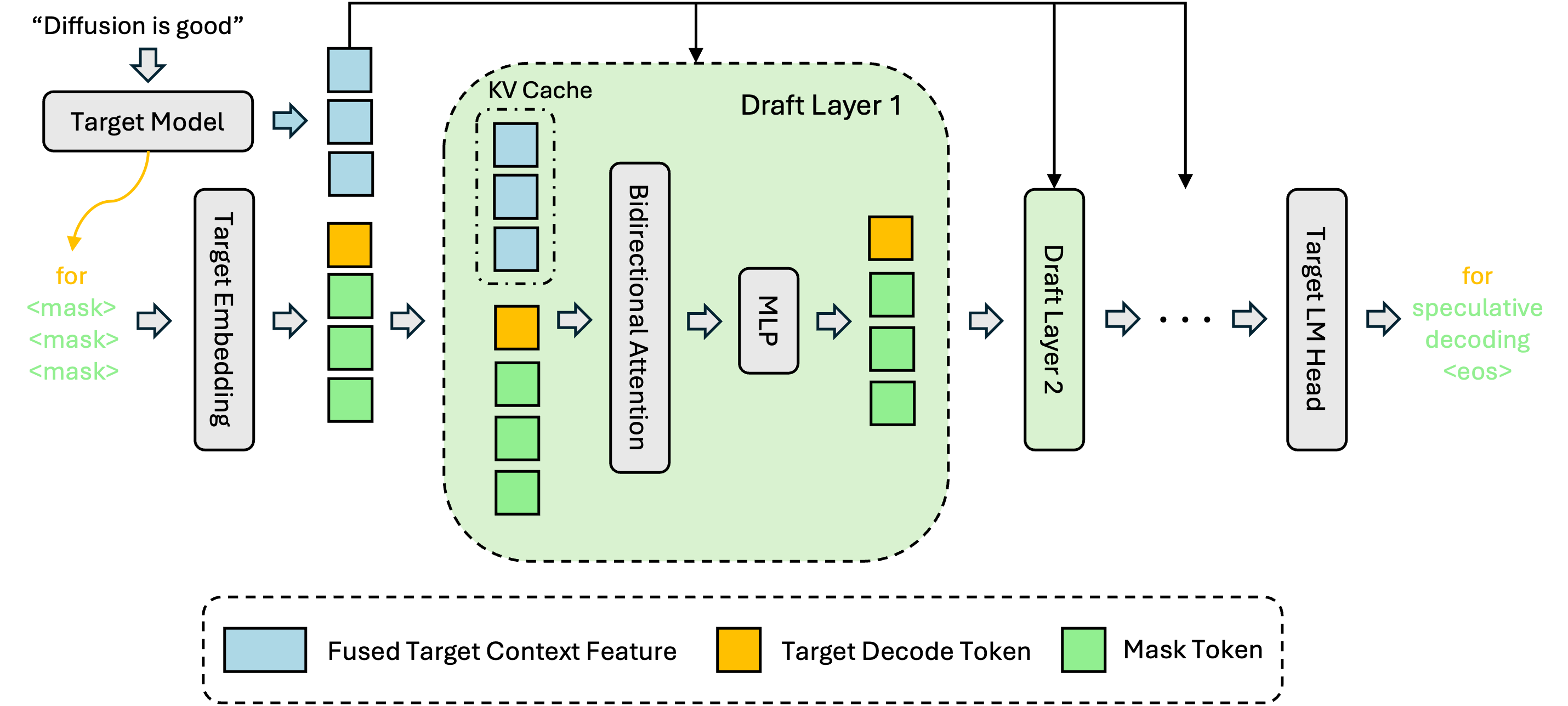
Figure 2. The overall design of DFlash. We extract and fuse the hidden context features from the target model, feeding these features into each draft layer to perform conditional speculation.
Benchmark Results
We evaluate DFlash against the state-of-the-art speculative decoding method, EAGLE-3. The tables below compare the decoding speedup and acceptance length across various benchmarks. For DFlash, the drafting block size is 16, and the number of denoising steps is 1. For EAGLE-3, we use the pretrained model RedHatAI/Qwen3-8B-speculator.eagle3 for all experiments, with a speculation length of 7.
We set the maximum generation length to 2048 for each task. All tests disable the “thinking” mode of the Qwen3 models. Acceptance is determined using direct token matching between the draft and target sampled tokens. Check out our GitHub repository to see how to reproduce the results.
Math Benchmarks
| Method | Temp | GSM8K
Speedup / τ\tau | Math500
Speedup / τ\tau | AIME24
Speedup / τ\tau | AIME25
Speedup / τ\tau | Average
Speedup / τ\tau | | --- | --- | --- | --- | --- | --- | --- | | Qwen3-8B-speculator.eagle3 | 0 | 2.13x / 2.89 | 2.18x / 2.94 | 2.25x / 3.04 | 2.18x / 2.93 | 2.19x / 2.95 | | Qwen3-4B-DFlash-b16 | 0 | 5.17x / 6.50 | 6.19x / 7.84 | 6.00x / 7.47 | 5.79x / 7.28 | 5.79x / 7.27 | | Qwen3-8B-DFlash-b16 | 0 | 5.20x / 6.55 | 6.17x / 7.87 | 5.91x / 7.48 | 5.85x / 7.31 | 5.78x / 7.30 | | | | | | | | | | Qwen3-8B-speculator.eagle3 | 1 | 2.07x / 2.79 | 2.03x / 2.75 | 1.88x / 2.54 | 1.81x / 2.44 | 1.95x / 2.63 | | Qwen3-4B-DFlash-b16 | 1 | 4.73x / 5.98 | 5.14x / 6.67 | 3.84x / 4.97 | 3.89x / 5.01 | 4.40x / 5.66 | | Qwen3-8B-DFlash-b16 | 1 | 4.78x / 6.04 | 5.02x / 6.57 | 3.87x / 5.06 | 3.84x / 5.03 | 4.38x / 5.68 |
Code Benchmarks
| Method | Temp | Humaneval
Speedup / τ\tau | MBPP
Speedup / τ\tau | LiveCodeBench
Speedup / τ\tau | SWE-Bench
Speedup / τ\tau | Average
Speedup / τ\tau | | --- | --- | --- | --- | --- | --- | --- | | Qwen3-8B-speculator.eagle3 | 0 | 2.48x / 3.36 | 2.27x / 3.08 | 2.24x / 3.16 | 1.90x / 2.55 | 2.22x / 3.04 | | Qwen3-4B-DFlash-b16 | 0 | 5.26x / 6.63 | 4.87x / 6.19 | 5.41x / 6.97 | 2.97x / 3.70 | 4.63x / 5.87 | | Qwen3-8B-DFlash-b16 | 0 | 5.20x / 6.55 | 4.75x / 6.00 | 5.43x / 7.12 | 2.92x / 3.69 | 4.58x / 5.84 | | | | | | | | | | Qwen3-8B-speculator.eagle3 | 1 | 2.30x / 3.11 | 2.15x / 2.92 | 2.17x / 3.00 | 1.66x / 2.21 | 2.07x / 2.81 | | Qwen3-4B-DFlash-b16 | 1 | 4.80x / 6.05 | 4.35x / 5.55 | 5.00x / 6.60 | 2.51x / 3.09 | 4.17x / 5.32 | | Qwen3-8B-DFlash-b16 | 1 | 4.35x / 5.40 | 4.07x / 5.17 | 5.15x / 6.79 | 2.30x / 2.82 | 3.97x / 5.05 |
Chat Benchmarks
| Method | Temp | MT-Bench
Speedup / τ\tau | Alpaca
Speedup / τ\tau | Average
Speedup / τ\tau | | --- | --- | --- | --- | --- | | Qwen3-8B-speculator.eagle3 | 0 | 1.94x / 2.72 | 1.88x / 2.68 | 1.91x / 2.70 | | Qwen3-4B-DFlash-b16 | 0 | 2.87x / 4.35 | 2.23x / 3.10 | 2.55x / 3.73 | | Qwen3-8B-DFlash-b16 | 0 | 2.79x / 4.25 | 2.27x / 3.16 | 2.53x / 3.71 | | | | | | | | Qwen3-8B-speculator.eagle3 | 1 | 1.81x / 2.55 | 1.79x / 2.56 | 1.80x / 2.56 | | Qwen3-4B-DFlash-b16 | 1 | 2.63x / 4.03 | 2.16x / 2.99 | 2.40x / 3.51 | | Qwen3-8B-DFlash-b16 | 1 | 2.50x / 3.74 | 2.11x / 2.88 | 2.31x / 3.31 |
Conclusion
DFlash demonstrates the promise of applying diffusion during the drafting stage of speculative decoding, pushing the speed limits of autoregressive LLMs. While dLLMs offer parallel generation, they often suffer from quality degradation compared to state-of-the-art autoregressive models. DFlash shows that by utilizing dLLMs strictly for drafting, we can fully leverage their parallel efficiency without sacrificing output quality. Crucially, by conditioning the drafter on context features from the capable target LLM, DFlash maintains high acceptance rates.
DFlash establishes a new direction for the development of diffusion LLMs. Rather than struggling to train dLLMs to match the accuracy of autoregressive models, we can instead deploy them as specialized drafters. This approach allows us to safely reduce the number of denoising steps, fully utilizing parallel generation, while relying on verification to prevent quality loss. Furthermore, training a lightweight dLLM for drafting requires significantly less compute than training a large, standalone dLLM.
We are currently working on integrating DFlash into popular serving frameworks. We also plan to support a wider range of models, including large MoE models. DFlash is compatible with various inference-time acceleration techniques for dLLMs, such as those introduced in DiffuSpec [2] and SpecDiff-2 [3], which can further improve speedups; we plan to support these integrations soon. The current results are based purely on block diffusion with a block size of 16.
Reference
[1] Qian Y-Y, Su J, Hu L, Zhang P, Deng Z, Zhao P, Zhang H. d3LLM: Ultra-Fast Diffusion LLM using Pseudo-Trajectory Distillation[J]. arXiv preprint, 2025.
[2] Li G, Fu Z, Fang M, et al. Diffuspec: Unlocking diffusion language models for speculative decoding[J]. arXiv preprint arXiv:2510.02358, 2025.
[3] Sandler J, Christopher J K, Hartvigsen T, et al. SpecDiff-2: Scaling Diffusion Drafter Alignment For Faster Speculative Decoding[J]. arXiv preprint arXiv:2511.00606, 2025.
[4] Samragh M, Kundu A, Harrison D, et al. Your llm knows the future: Uncovering its multi-token prediction potential[J]. arXiv preprint arXiv:2507.11851, 2025.
Citation
If you find DFlash useful for your research or applications, please cite our paper.
@misc{chen2026dflash,
title = {DFlash: Block Diffusion for Flash Speculative Decoding},
author = {Chen, Jian and Liang, Yesheng and Liu, Zhijian},
year = {2026},
eprint = {2602.06036},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
url = {https://arxiv.org/abs/2602.06036}
}