

Version 2.1.20 of Claude Code shipped a change that replaced every file read and every search pattern with a single, useless summary line.
Where you used to see:
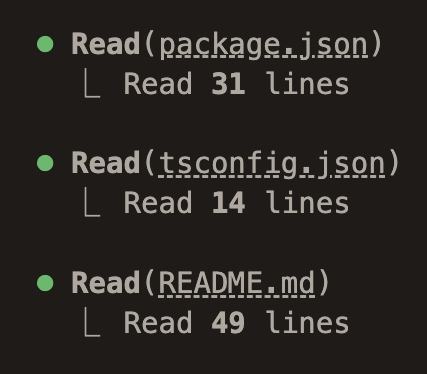
You now get:

That’s it.
“Read 3 files.” Which files? Doesn’t matter.
“Searched for 1 pattern.” What pattern? Who cares.
You’re paying $200 a month for a tool that now hides what it’s doing with your codebase by default.
Across multiple GitHub issues opened for this, all comments are pretty much saying the same thing: give us back the file paths, or at minimum, give us a toggle.
The response from Anthropic:
For the majority of users, this change is a nice simplification that reduces noise.

What majority? The change just shipped and the only response it got is people complaining.
Then when pressed, the fix offered wasn’t to revert or add a toggle. It was: “just use verbose mode.”
Fucking verbose mode.
A big ‘ole dump of thinking traces, hook output, full subagent transcripts, and entire file contents into your terminal. People explained, repeatedly, that they wanted one specific thing: file paths and search patterns inline. Not a firehose of debug output.
The developer’s response to that?
I want to hear folks’ feedback on what’s missing from verbose mode to make it the right approach for your use case.

Read that again. Thirty people say “revert the change or give us a toggle.” The answer is “let me make verbose mode work for you instead.”
As one commenter put it:
If you are going to display something like ‘Searched for 13 patterns, read 2 files’ there is nothing I can do with that information. You might as well not display it at all.
Several versions later, the “fix” is to keep making verbose mode less and less verbose by removing thinking traces and hook output so it becomes a tolerable way to get your file paths back. But verbose mode still dumps full sub-agent output onto your screen, among other things.

Before, when Claude spawned multiple sub-agents you’d see a compact line-by-line stream of what each one was doing, just enough to glance at. Now you get walls of text from multiple agents at once. So what’s the plan? Keep stripping things out of verbose mode one by one until it’s no longer verbose? Where does it end? At some point you’ve just reinvented a config toggle with extra steps.

And the people who were using verbose mode for thinking and hooks now need to press Ctrl+O to get what they had by default. So instead of fixing one problem, you created two.
People are pinning themselves to version 2.1.19 and in the meantime the fix everyone is asking for, a single boolean config flag, would take less effort to implement than all the verbose mode surgery that’s been done instead.
Anthropic during the Super Bowl: we’d never disrespect our users.
Anthropic on GitHub: have you tried verbose mode?