Feb 12, 2026
Our most specialized reasoning mode is now updated to solve modern science, research and engineering challenges.
The Deep Think team
General summary
Gemini 3 Deep Think has a major upgrade to help solve science, research and engineering challenges. Google AI Ultra subscribers can now access the updated Deep Think in the Gemini app. Researchers, engineers and enterprises can express interest in early access to test Deep Think via the Gemini API.
Summaries were generated by Google AI. Generative AI is experimental.

Your browser does not support the audio element.
Listen to article
This content is generated by Google AI. Generative AI is experimental
[[duration]] minutes
Today, we’re releasing a major upgrade to Gemini 3 Deep Think, our specialized reasoning mode, built to push the frontier of intelligence and solve modern challenges across science, research, and engineering.
We updated Gemini 3 Deep Think in close partnership with scientists and researchers to tackle tough research challenges — where problems often lack clear guardrails or a single correct solution and data is often messy or incomplete. By blending deep scientific knowledge with everyday engineering utility, Deep Think moves beyond abstract theory to drive practical applications.
The new Deep Think is now available in the Gemini app for Google AI Ultra subscribers and, for the first time, we’re also making Deep Think available via the Gemini API to select researchers, engineers and enterprises. Express interest in early access here.
Here is how our early testers are already using the latest Deep Think:
Lisa Carbone, a mathematician at Rutgers University, works on the mathematical structures required by the high-energy physics community to bridge the gap between Einstein’s theory of gravity and quantum mechanics. In a field with very little existing training data, she used Deep Think to review a highly technical mathematics paper. Deep Think successfully identified a subtle logical flaw that had previously passed through human peer review unnoticed.
At Duke University, the Wang Lab utilized Deep Think to optimize fabrication methods for complex crystal growth for the potential discovery of semiconductor materials. Deep Think successfully designed a recipe for growing thin films larger than 100 μm, meeting a precise target that previous methods had challenges to hit.
Anupam Pathak, an R&D lead in Google’s Platforms and Devices division and former CEO of Liftware, tested the new Deep Think to accelerate the design of physical components.
Elevating reasoning with mathematical and algorithmic rigor
Last year, we showed that specialized versions of Deep Think could successfully navigate some of the toughest challenges in reasoning, achieving gold-medal standards at math and programming world championships. More recently, Deep Think has enabled specialized agents to conduct research-level mathematics exploration.
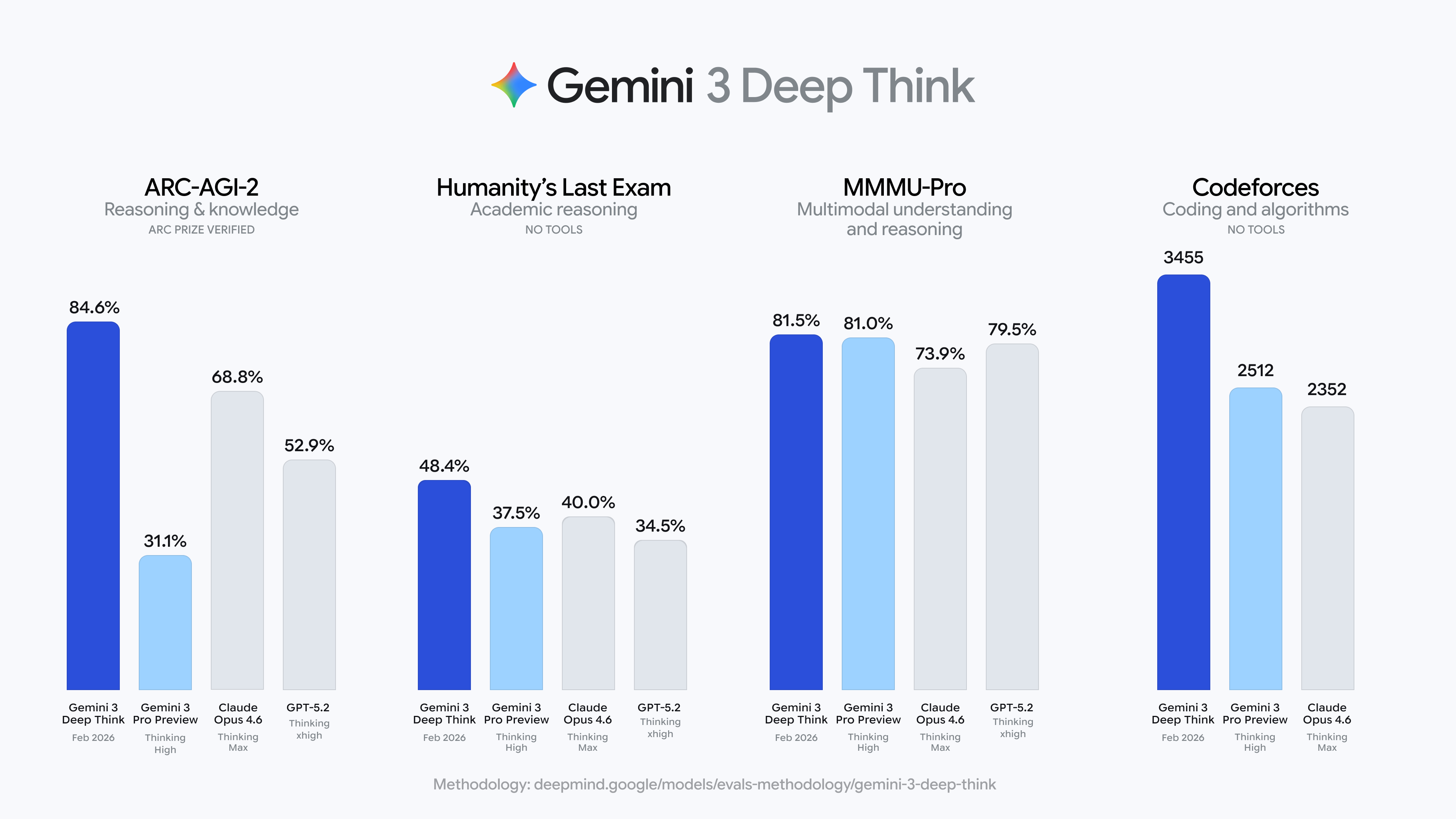
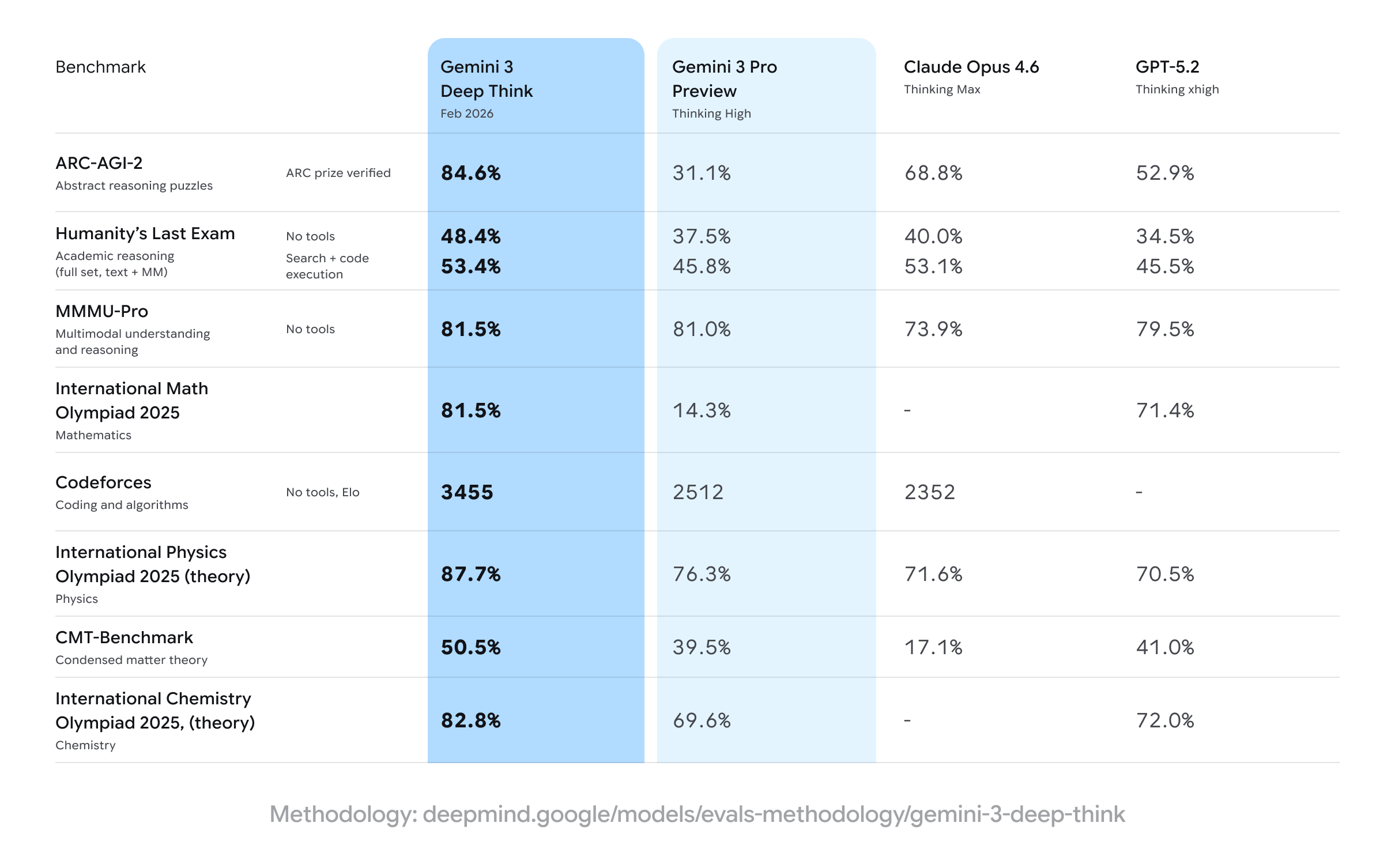
The updated Deep Think mode continues to push the frontiers of intelligence, reaching new heights across the most rigorous academic benchmarks, including:
- Setting a new standard (48.4%, without tools) on Humanity’s Last Exam, a benchmark designed to test the limits of modern frontier models
- Achieving an unprecedented 84.6% on ARC-AGI-2, verified by the ARC Prize Foundation
- Attaining a staggering Elo of 3455 on Codeforces, a benchmark consisting of competitive programming challenges
- Reaching gold-medal level performance on the International Math Olympiad 2025
Navigating complex scientific domains
Beyond mathematics and competitive coding, Gemini 3 Deep Think now also excels across broad scientific domains such as chemistry and physics. Our updated Deep Think mode demonstrates gold medal-level results on the written sections of the 2025 International Physics Olympiad and Chemistry Olympiad. It also demonstrates proficiency in advanced theoretical physics, achieving a score of 50.5% on CMT-Benchmark.
Accelerating real-world engineering
In addition to its state-of-the-art performance, Deep Think is built to drive practical applications, enabling researchers to interpret complex data, and engineers to model physical systems through code. Most importantly, we are working to bring Deep Think to researchers and practitioners where they need it most — beginning with surfaces such as the Gemini API.
With the updated Deep Think, you can turn a sketch into a 3D-printable reality. Deep Think analyzes the drawing, models the complex shape and generates a file to create the physical object with 3D printing.
Available to Google AI Ultra Subscribers and the Gemini API via our Early Access Program
Google AI Ultra subscribers will be able to access the updated Deep Think mode starting today in the Gemini app. Scientists, engineers and enterprises can also now express interest in our early access program to test Deep Think via the Gemini API.
We can’t wait to see what you discover.
Related stories
.