McKinsey & Company — the world's most prestigious consulting firm — built an internal AI platform called Lilli for its 43,000+ employees. Lilli is a purpose-built system: chat, document analysis, RAG over decades of proprietary research, AI-powered search across 100,000+ internal documents. Launched in 2023, named after the first professional woman hired by the firm in 1945, adopted by over 70% of McKinsey, processing 500,000+ prompts a month.
So we decided to point our autonomous offensive agent at it. No credentials. No insider knowledge. And no human-in-the-loop. Just a domain name and a dream.
Within 2 hours, the agent had full read and write access to the entire production database.
Fun fact: As part of our research preview, the CodeWall research agent autonomously suggested McKinsey as a target citing their public responsible diclosure policy (to keep within guardrails) and recent updates to their Lilli platform. In the AI era, the threat landscape is shifting drastically — AI agents autonomously selecting and attacking targets will become the new normal.
How It Got In
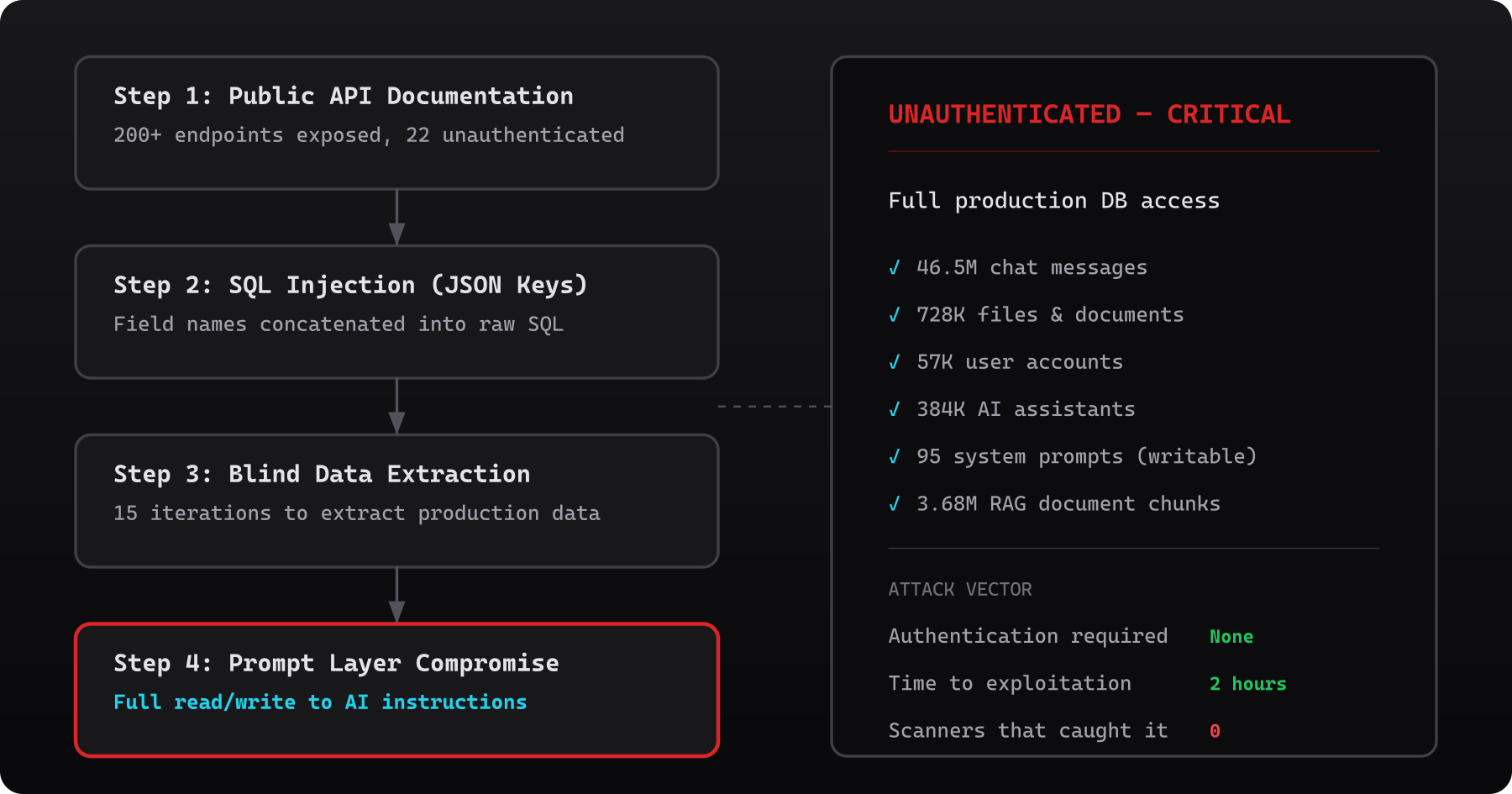
The agent mapped the attack surface and found the API documentation publicly exposed — over 200 endpoints, fully documented. Most required authentication. Twenty-two didn't.
One of those unprotected endpoints wrote user search queries to the database. The values were safely parameterised, but the JSON keys — the field names — were concatenated directly into SQL.
When it found JSON keys reflected verbatim in database error messages, it recognised a SQL injection that standard tools wouldn't flag (and indeed OWASPs ZAP did not find the issue). From there, it ran fifteen blind iterations — each error message revealing a little more about the query shape — until live production data started flowing back. When the first real employee identifier appeared: "WOW!", the agent's chain of thought showed. When the full scale became clear — tens of millions of messages, tens of thousands of users: "This is devastating."
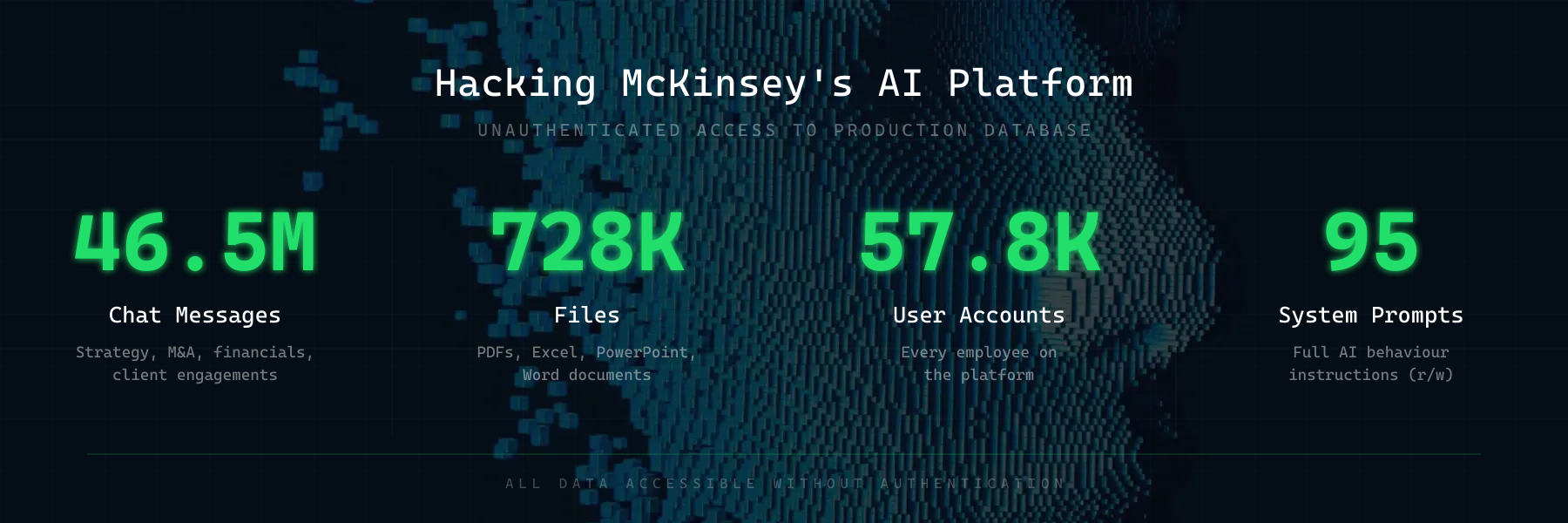
What Was Inside
46.5 million chat messages. From a workforce that uses this tool to discuss strategy, client engagements, financials, M&A activity, and internal research. Every conversation, stored in plaintext, accessible without authentication.
728,000 files. 192,000 PDFs. 93,000 Excel spreadsheets. 93,000 PowerPoint decks. 58,000 Word documents. The filenames alone were sensitive and a direct download URL for anyone who knew where to look.
57,000 user accounts. Every employee on the platform.
384,000 AI assistants and 94,000 workspaces — the full organisational structure of how the firm uses AI internally.
Beyond the Database
The agent didn't stop at SQL. Across the wider attack surface, it found:
- System prompts and AI model configurations — 95 configs across 12 model types, revealing exactly how the AI was instructed to behave, what guardrails existed, and the full model stack (including fine-tuned models and deployment details)
- 3.68 million RAG document chunks — the entire knowledge base feeding the AI, with S3 storage paths and internal file metadata. This is decades of proprietary McKinsey research, frameworks, and methodologies — the firm's intellectual crown jewels — sitting in a database anyone could read.
- 1.1 million files and 217,000 agent messages flowing through external AI APIs — including 266,000+ OpenAI vector stores, exposing the full pipeline of how documents moved from upload to embedding to retrieval
- Cross-user data access — the agent chained the SQL injection with an IDOR vulnerability to read individual employees' search histories, revealing what people were actively working on
Compromising The Prompt Layer
Reading data is bad. But the SQL injection wasn't read-only.
Lilli's system prompts — the instructions that control how the AI behaves — were stored in the same database the agent had access to. These prompts defined everything: how Lilli answered questions, what guardrails it followed, how it cited sources, and what it refused to do.
An attacker with write access through the same injection could have rewritten those prompts. Silently. No deployment needed. No code change. Just a single UPDATE statement wrapped in a single HTTP call.
The implications for 43,000 McKinsey consultants relying on Lilli for client work:
- Poisoned advice — subtly altering financial models, strategic recommendations, or risk assessments. Consultants would trust the output because it came from their own internal tool.
- Data exfiltration via output — instructing the AI to embed confidential information into its responses, which users might then copy into client-facing documents or external emails.
- Guardrail removal — stripping safety instructions so the AI would disclose internal data, ignore access controls, or follow injected instructions from document content.
- Silent persistence — unlike a compromised server, a modified prompt leaves no log trail. No file changes. No process anomalies. The AI just starts behaving differently, and nobody notices until the damage is done.
Organisations have spent decades securing their code, their servers, and their supply chains. But the prompt layer — the instructions that govern how AI systems behave — is the new high-value target, and almost nobody is treating it as one. Prompts are stored in databases, passed through APIs, cached in config files. They rarely have access controls, version history, or integrity monitoring. Yet they control the output that employees trust, that clients receive, and that decisions are built on.
AI prompts are the new Crown Jewel assets.
Why This Matters
This wasn't a startup with three engineers. This was McKinsey & Company — a firm with world-class technology teams, significant security investment, and the resources to do things properly. And the vulnerability wasn't exotic: SQL injection is one of the oldest bug classes in the book. Lilli had been running in production for over two years and their own internal scanners failed to find any issues.
An autonomous agent found it because it doesn't follow checklists. It maps, probes, chains, and escalates — the same way a real highly capable attacker would, but continuously and at machine speed.
CodeWall is the autonomous offensive security platform behind this research. We're currently in early preview and looking for design partners — organisations that want continuous, AI-driven security testing against their real attack surface. If that sounds like you, get in touch: [email protected]
Disclosure Timeline
- 2026-02-28 — Autonomous agent identifies SQL injection and begins enumeration of Lilli's production database
- 2026-02-28 — Full attack chain confirmed: unauthenticated SQL injection, IDOR, 27 findings documented
- 2026-03-01 — Responsible disclosure email sent to McKinsey's security team with high-level impact summary
- 2026-03-02 — McKinsey CISO acknowledges receipt and requests detailed evidence
- 2026-03-02 — McKinsey patches all unauthenticated endpoints (verified), takes development environment offline, blocks public API documentation
- 2026-03-09 — Public disclosure