March 12, 2026 [systems-programming] #tagged-pointer #fat-pointer #custom-rtti #struct-embedding
Recap
From the previous article, we examined how GNU Emacs represents every Lisp value — integers, symbols, cons cells, strings, buffers — inside a single 64-bit slot called Lisp_Object. Because all heap objects are 8-byte aligned and the lowest 3 bits of any valid pointer are always zero, Emacs reclaims these "free" bits and uses them as a type tag.
The more fundamental question is: when a single variable must hold values of different types at runtime, how do we preserve enough information to use that data correctly?
01. Back to the basics: how to write a polymorphic type
The static typing
Given memory and a struct type, how do we access the data?
Data in memory is represented as bits. To operate on it, we define its shape. If we modify the value of score, we load the data from base + 4 bytes, write a 32-bit value, and store it back.
#include <stdint.h>
struct Person {
uint8_t age; offset 0, size 1
[3 bytes padding] offset 1 (align next field to 4)
uint32_t score; offset 4, size 4
uint64_t id; offset 8, size 8
char name[12]; offset 16, size 12
};
// sizeof(Person) == 28, no trailing padding needed
The compiler remembers the shape of the data so the runtime does not have to.
Dynamic typing
Given a memory address and a set of possible types, how do we access the data?
One approach is to add a field at the beginning of a struct to indicate the active type.
struct TaggedValue {
int type_id; which type is active?
union {
TypeA a; TypeB b; TypeC c; } payload;
};
This allows type checking before casting:
// predicate: is this a TypeA?
bool is_type_a(struct TaggedValue* v) {
return v->type_id == TYPE_A; just an integer comparison
}
// check cast: give me TypeA* or NULL
TypeA* as_type_a(struct TaggedValue* v) {
if (v->type_id == TYPE_A) {
return &v->payload.a; }
return NULL; wrong type
}
Functions can be dispatched according to this tag.
// Each function pointer represents "what to do when you encounter this type".
// A Visitor bundles all these handlers together into one struct.
struct Visitor {
void (*visit_a)(TypeA* a); called when type_id == TYPE_A
void (*visit_b)(TypeB* b); called when type_id == TYPE_B
void (*visit_c)(TypeC* c); called when type_id == TYPE_C
};
// The dispatch function is the bridge between data and behavior.
// It reads the type_id, then hands control to the correct handler.
void visit(struct TaggedValue* v, struct Visitor* visitor) {
switch (v->type_id) {
case TYPE_A: visitor->visit_a(&v->payload.a); break;
case TYPE_B: visitor->visit_b(&v->payload.b); break;
case TYPE_C: visitor->visit_c(&v->payload.c); break;
}
}
Now you have invented C++ std::variant and std::visit that were introduced in C++17, which utilize a "tagged union."
02. Tagged Union (Unboxed): std::variant and std::visit
People claim std::variant and std::visit provide a more "TYPE SAFE" way, but in fact they just provide some checks. It simply ensures that an invalid cast like (TypeA*) type_b_object is caught either at compile time (if the type is not in the variant at all) or at runtime (if the active type does not match), rather than silently producing undefined behavior as the hand-written version would.
There are two things that need attention here:
First, the problem with a tagged union is that the size of the struct is the size of the largest union element. So for the example below, even if most objects are bool or int, the overall size will be 64 bytes, which is very memory inefficient. Therefore, tagged union technique is mostly applied where different sizes of different types are similar, or temporary objects on stack that can be freed after this call.
PS. std::variant is originally designed to handle a closed set of known types in a type-safe manner — similar in spirit to Haskell's Either, where a value is one of several explicitly listed possibilities. The closest C++ analogue to Haskell's Maybe is actually std::optional.
struct TaggedValue {
int type_id;
union {
int a; bool b; char c[64]; } payload;
};
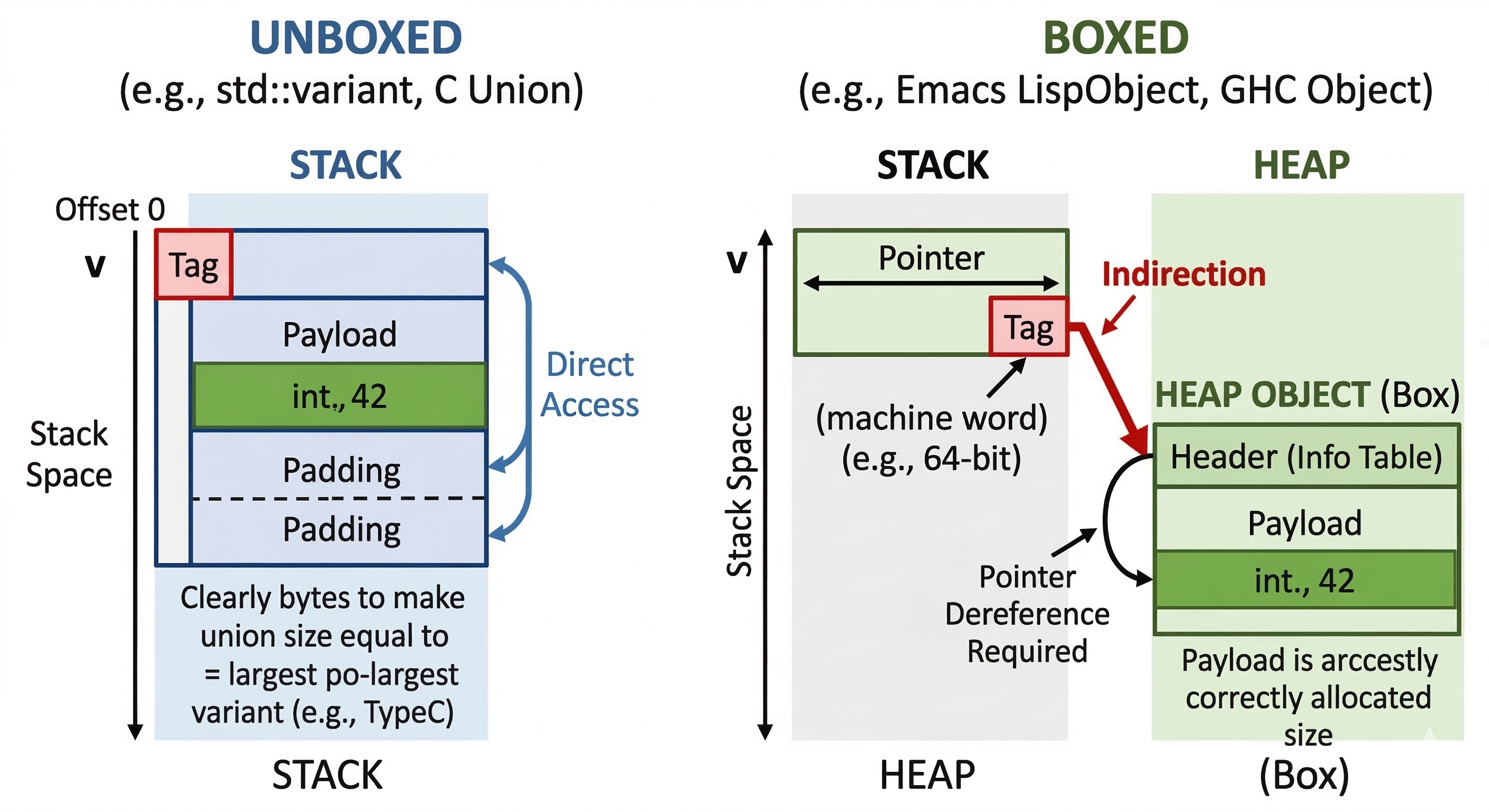
Second, this way of handling data and types is called a "tagged union", or "unboxed".
The naming of boxed and unboxed is a programming language (PL) term that looks very weird to C/C++ programmers. The "unboxed" way looks actually wrapped in a struct box. But the actual meaning in PL theory refers to memory indirection.
- Boxed: The data lives on the heap (inside a "box"). You only hold a reference or pointer to it.
- Unboxed: The raw bits of the data are laid out flat right where they are declared (on the stack, or inline within an array). There are no pointers to follow.
std::variantis unboxed because all the bytes required for the largest possible variant are allocated inline right there.
References on memory representation:
- Simon Marlow - Faster Laziness Using Dynamic Pointer Tagging
- Jane Street - OCaml unboxed types talk
- GHC Commentary
03. Tagged Pointer (Boxed)
A tagged union allocates the maximum required size for every variant. If an Abstract Syntax Tree (AST) contains an integer node requiring 8 bytes and a function definition node requiring 256 bytes, an unboxed tagged union allocates 256 bytes for every integer node. This affects the overall memory footprint and cache usage.
An alternative approach keeps data on the heap (boxed) and uses the lowest 3 bits of the 8-byte aligned pointer as the type tag. This provides $2^3 = 8$ possible types without allocating additional inline bytes. This is called a tagged pointer.
struct tagged_pointer {
void* pointer_and_tag;
}
// sizeof(tagged_pointer) == 8 bytes
What if there are more than 8 types?
One common solution is using fat pointer. Modern languages like Go (interfaces) and Rust (trait objects) use this approach extensively.
Stealing 3 bit is not enough, so, just add a 64-bit space to store the tag information.
struct fat_pointer {
int tag; Could be a type ID, a vtable pointer, or a size/length
void* payload; Pointer to the actual data on the heap
}
// sizeof(fat_pointer) == 16 bytes (doubled)
"Since both Go and Rust think fat pointers are great, why doesn't GNU Emacs just use fat pointers for
Lisp_Object?"
Comparing fat pointers to tagged pointers: A fat pointer is smaller than a tagged union, but it doubles the memory size compared to a 64-bit tagged pointer. This changes the memory footprint and the Garbage Collector (GC) scanning workload. Emacs was designed to keep the Lisp_Object within a single 64-bit word.
PS. It's a crime to waste memory in the 1980s — a typical workstation had around 256 KB of RAM, which is less than the size of a single modern emoji in a Unicode font file. Doubling every Lisp_Object from 8 to 16 bytes wasn't an engineering tradeoff. It was a confession.
04. Emacs: Tagged Pointer + Poor Man's Inheritance
Since GNU Emacs uses the lowest 3 bits for tags, it is strictly limited to 8 fundamental types. If you look at enum Lisp_Type in src/lisp.h, you'll see exactly that:
Lisp_SymbolLisp_Int0Lisp_Int1Lisp_StringLisp_VectorlikeLisp_ConsLisp_Float(plus one unused type)McCarthy's Lisp (1960) abstract math atom eq car cdr cons quote cond │ │ Emacs engineers bridge: │ "statically typed C must represent │ dynamically typed Lisp" ▼ Lisp_Object (src/lisp.h) C layer ┌──────────────────────┬────┐ │ pointer or value │tag │ ← one machine word (64 bits) │ 61 bits │ 3b │ └──────────────────────┴────┘ │ ├─ tag = Cons → struct Lisp_Cons ├─ tag = String → struct Lisp_String ├─ tag = Float → struct Lisp_Float ├─ tag = Int0/1 → EMACS_INT (immediate value, no pointer!) ├─ tag = Symbol → struct Lisp_Symbol └─ tag = Vectorlike │ ▼ union vectorlike_header (The Escape Hatch) │ ├─ PVEC_BUFFER → struct buffer ├─ PVEC_WINDOW → struct window ├─ PVEC_HASH_TABLE → struct Lisp_Hash_Table ├─ PVEC_SYMBOL_WITH_POS → struct Lisp_Symbol_With_Pos └─ ... (over 30+ complex types!)
A basic Lisp interpreter might only need a few primitive types. But Emacs is a text editor designed for performance (?!), so it implements its core objects (like buffers and windows) directly in C. So, 8 types are not enough.
How can we represent more types when the pointer tag is limited to 3 bits?
To expand the type space, Emacs uses a C pattern sometimes called "Poor Man's Inheritance" or struct embedding. By placing a common header as the very first field of a struct, a pointer can be cast to the header type, checked for its sub-type, and then cast to the specific object type.
When Lisp_Object carries the Lisp_Vectorlike tag, it points to a struct starting with union vectorlike_header. Emacs reads this header to find a sub-tag indicating the specific type (pvec_type).
This is how vectorlike_header is embedded:
// Source: lisp.h
struct Lisp_Vector // The generic "Base Data Structure"
{
union vectorlike_header header;
Lisp_Object contents[FLEXIBLE_ARRAY_MEMBER];
} GCALIGNED_STRUCT;
// Derived type Example
struct Lisp_Symbol_With_Pos
{
union vectorlike_header header; <--- The "Base Class" must be the first field!
Lisp_Object sym; A symbol
Lisp_Object pos; A fixnum
} GCALIGNED_STRUCT;
When Emacs identifies a Lisp_Object, it performs two checks:
- Primary Tag Check: Check if the lowest 3 bits are
Lisp_Vectorlike(0b101). - Sub-Tag Check: Cast the pointer to
union vectorlike_header*, read theTYPEfield. If it equalsPVEC_SYMBOL_WITH_POS, cast the pointer tostruct Lisp_Symbol_With_Pos*.
The definition of union vectorlike_header packs the subtype into its size field:
// Source: src/lisp.h
union vectorlike_header
{
The `size' header word, W bits wide, has one of two forms
discriminated by the second-highest bit (PSEUDOVECTOR_FLAG):
1 1 W-2
+---+---+-------------------------------------+
| M | 0 | SIZE | vector
+---+---+-------------------------------------+
1 1 W-32 6 12 12
+---+---+--------+------+----------+----------+
| M | 1 | unused | TYPE | RESTSIZE | LISPSIZE | pseudovector
+---+---+--------+------+----------+----------+
M (ARRAY_MARK_FLAG) holds the GC mark bit.
SIZE is the length (number of slots) of a regular Lisp vector,
and the object layout is struct Lisp_Vector.
TYPE is the pseudovector subtype (enum pvec_type).
LISPSIZE is the number of Lisp_Object fields at the beginning of the
object (after the header). These are always traced by the GC.
RESTSIZE is the number of fields (in word_size units) following.
These are not automatically traced by the GC.
For PVEC_BOOL and statically allocated PVEC_SUBR, RESTSIZE is 0.
(The block size for PVEC_BOOL is computed from its own size
field, to avoid being restricted by the 12-bit RESTSIZE field.)
ptrdiff_t size;
};
And the following contains all the concrete pvec_type sub-types it can represent:
// Source: src/lisp.h
enum pvec_type
{
PVEC_NORMAL_VECTOR, Should be first, for sxhash_obj.
PVEC_FREE,
PVEC_BIGNUM,
PVEC_MARKER,
PVEC_OVERLAY,
PVEC_FINALIZER,
PVEC_SYMBOL_WITH_POS,
PVEC_MISC_PTR,
PVEC_USER_PTR,
PVEC_PROCESS,
PVEC_FRAME,
PVEC_WINDOW,
PVEC_BOOL_VECTOR,
PVEC_BUFFER,
PVEC_HASH_TABLE,
PVEC_OBARRAY,
PVEC_TERMINAL,
PVEC_WINDOW_CONFIGURATION,
PVEC_SUBR,
PVEC_OTHER, Should never be visible to Elisp code.
PVEC_XWIDGET,
PVEC_XWIDGET_VIEW,
PVEC_THREAD,
PVEC_MUTEX,
PVEC_CONDVAR,
PVEC_MODULE_FUNCTION,
PVEC_NATIVE_COMP_UNIT,
PVEC_TS_PARSER,
PVEC_TS_NODE,
PVEC_TS_COMPILED_QUERY,
PVEC_SQLITE,
These should be last, for internal_equal and sxhash_obj.
PVEC_CLOSURE,
PVEC_CHAR_TABLE,
PVEC_SUB_CHAR_TABLE,
PVEC_RECORD,
PVEC_FONT,
PVEC_TAG_MAX = PVEC_FONT Keep this equal to the highest member.
};
This elegant combination of Tagged Pointers (for high-speed, core types and immediate integers without memory allocations) and Poor Man's Inheritance (for an extensible array of complex types) is how Emacs achieves dynamic typing in statically-typed C without sacrificing critical GC performance.
05. The Modern Reincarnation: LLVM's Custom RTTI
The most fascinating part about reading Emacs's 1980s source code is discovering that these techniques are still highly applicable and relevant even in the modern C++ era. The combination of Tagged Pointer + Poor Man's Inheritance is no exception.
By looking at the source code of LLVM, engineers explicitly disable the C++ standard RTTI (-fno-rtti) and dynamic_cast. Instead, LLVM literally reinvents Emacs's "Poor Man's Inheritance" and Tagging system, but wraps it in modern C++ templates. It's called Custom RTTI.
Why LLVM abandons standard RTTI?
Standard C++ RTTI works by embedding a pointer to a type_info object inside every polymorphic class's vtable. A dynamic_cast then traverses a chain of these type_info objects at runtime, comparing strings or pointers until it finds a match or exhausts the hierarchy. For a compiler that performs millions of type checks per second while traversing an AST, this traversal cost is unacceptable.
Instead, LLVM defines a single integer field called SubclassID in its base class to identify concrete types:
// Source: llvm/include/llvm/IR/Value.h
class Value {
private:
A single integer tag — the same idea as Emacs's pvec_type enum.
Private so subclasses cannot corrupt it accidentally.
const unsigned char SubclassID;
public:
unsigned getValueID() const { return SubclassID; }
The base class accepts all Values — this is the identity check.
static bool classof(const Value *) { return true; }
};
// A derived class registers its own ID range and implements classof().
class Argument : public Value {
public:
isa<Argument>(ptr) compiles down to this — a single integer comparison.
No vtable traversal. No string comparison. Just: is the tag == ArgumentVal?
static bool classof(const Value *V) {
return V->getValueID() == ArgumentVal;
}
};
Invoking isa<Argument>(Val) evaluates at compile time to Argument::classof(Val), resulting in an integer comparison on SubclassID.
// How LLVM developers write type dispatch
if (isa<Argument>(Val)) {
Argument *Arg = cast<Argument>(Val);
// Do something with Arg...
}
Both Emacs and LLVM handle dynamic dispatch over a hierarchy of types by embedding tag information directly in the base structures and performing integer comparisons before casting.
06. Other Tagged Pointer Usages
The pattern of storing information in unused bits of pointers or headers is found in other system implementations:
- Linux Kernel Red-Black Trees: Uses the lowest bits of parent pointers to store the node color.
- LuaJIT and V8 (NaN Boxing): Uses the payload space of IEEE 754 "Not-a-Number"
doubles to encode pointers. - PostgreSQL: Encodes transaction visibility metadata in the bit-fields of tuple headers.
- LLVM
PointerIntPair<>: A C++ template utility for packing integers into pointer alignment padding. - ARM64 Top Byte Ignore (TBI): Hardware configuration that allows the top 8 bits of a 64-bit pointer to be used for tags (utilized in iOS/macOS).
Conclusion
This article outlines three ways memory is structured to handle dynamic typing:
- Tagged Union (Unboxed): Allocates inline memory based on the largest variant. (
std::variant) - Fat Pointer: Allocates additional bytes alongside the pointer to store type information. (Go interfaces, Rust traits)
- Tagged Pointer (Boxed): Uses the alignment padding of pointers to store tags, relying on heap allocation for the data. (Emacs
Lisp_Object, V8)
Different memory layouts serve different requirements. Emacs and LLVM utilize Tagged Pointers and struct embedding to manage dynamic typing within their specific memory constraints.
Next step
Looking into the weird Lisp_String object... there is an interval tree in it.
Emacs Internal Series:
- #01: Emacs is a Lisp Runtime in C, Not an Editor
- #02: Data First — Deconstructing Lisp_Object in C
- #03: Tagged Union, Tagged Pointer, and Poor Man's Inheritance
> share on twitter / bluesky / mastodon / facebook / reddit / telegram / email
> related articles:
1) Emacs Internal #02: Data First — Deconstructing Lisp_Object in C