Last October I reported an exposed Algolia admin API key on vuejs.org. The key had full permissions: addObject, deleteObject, deleteIndex, editSettings, the works. Vue acknowledged it, added me to their Security Hall of Fame, and rotated the key.
That should have been the end of it. But it got me thinking: if Vue.js had this problem, how many other DocSearch sites do too?
Turns out, a lot.
How Algolia DocSearch works
Algolia's DocSearch is a free search service for open source docs. They crawl your site, index it, and give you an API key to embed in your frontend. That key is supposed to be search-only, but some ship with full admin permissions.
What I found
Most keys came from frontend scraping. Algolia maintains a public (now archived) repo called docsearch-configs with a config for every site in the DocSearch program, over 3,500 of them. I used that as a starting target list and scraped roughly 15,000 documentation sites for embedded credentials. This catches keys that don't exist in any repo because they're injected at build time and only appear in the deployed site:
APP_RE = re.compile(r'["\']([A-Z0-9]{10})["\']')
KEY_RE = re.compile(r'["\']([\da-f]{32})["\']')
def extract(text, app_ids, api_keys):
if not ALGOLIA_RE.search(text):
return
for a in APP_RE.findall(text):
if valid_app(a):
app_ids.add(a)
api_keys.update(KEY_RE.findall(text))
On top of that I ran GitHub code search to find keys in doc framework configs, then cloned and ran TruffleHog on 500+ documentation site repos to catch keys that had been committed and later removed.
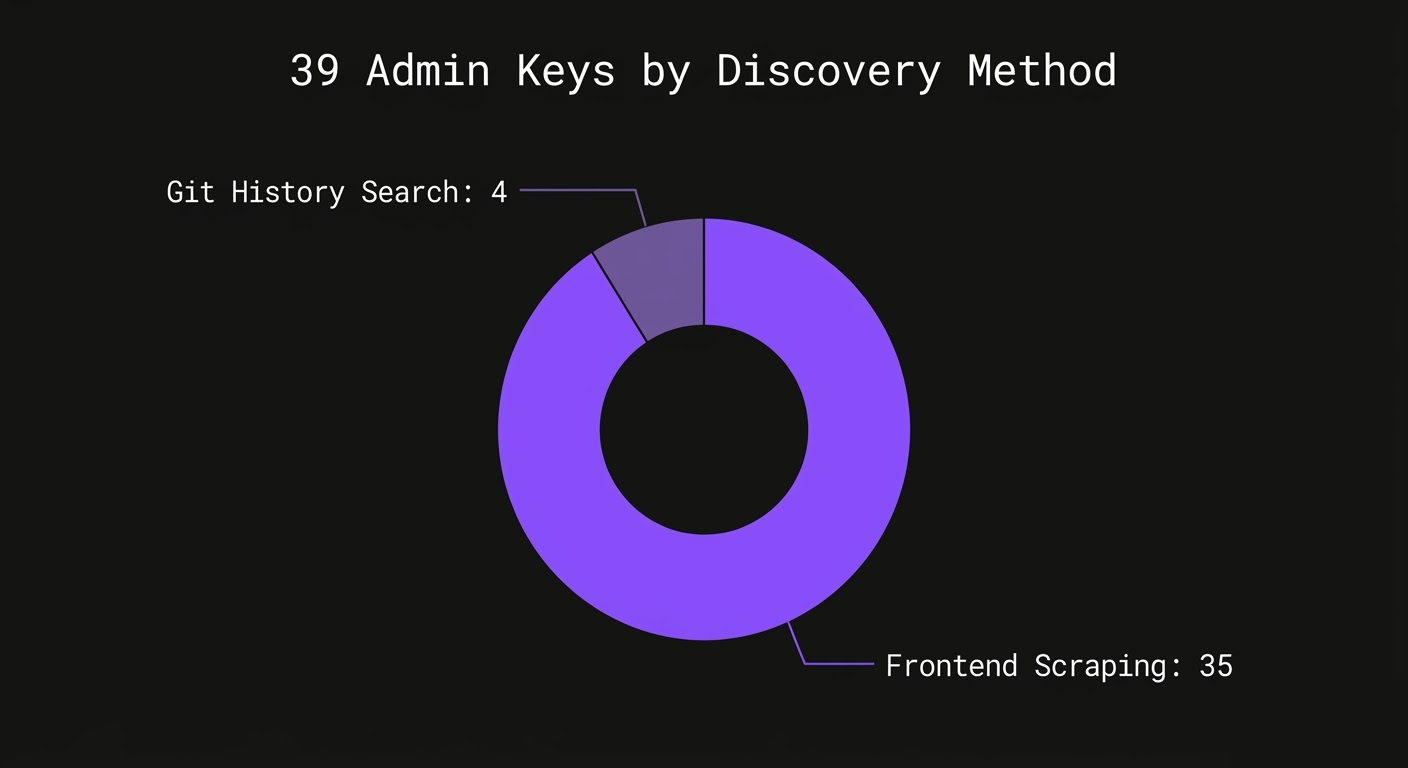
35 of the 39 admin keys came from frontend scraping alone. The remaining 4 were found through git history. Every single one was active at the time of discovery.
The affected projects include some massive open source projects:
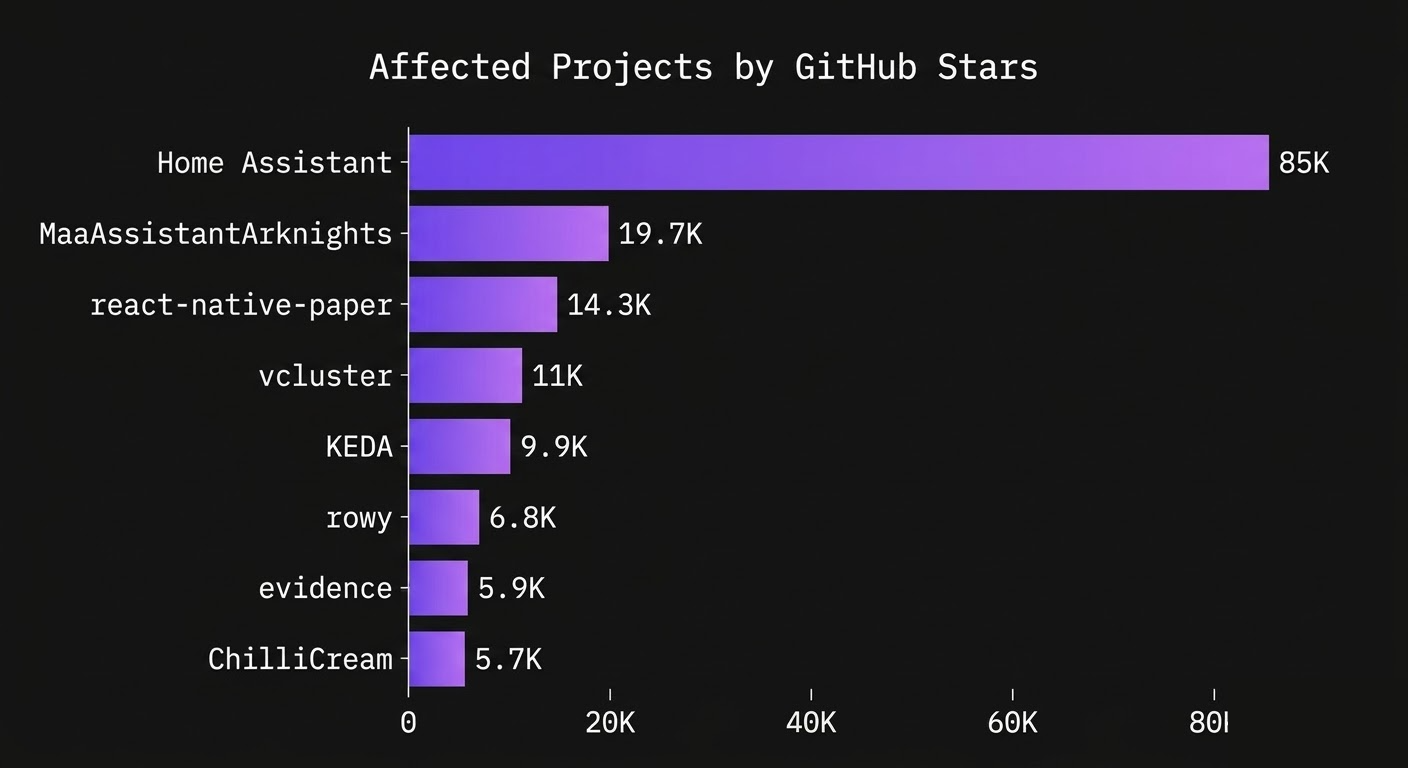
Home Assistant alone has 85,000 GitHub stars and millions of active installations. KEDA is a CNCF project used in production Kubernetes clusters. vcluster, also Kubernetes infrastructure, had the largest search index of any affected site at over 100,000 records.
What these keys can do
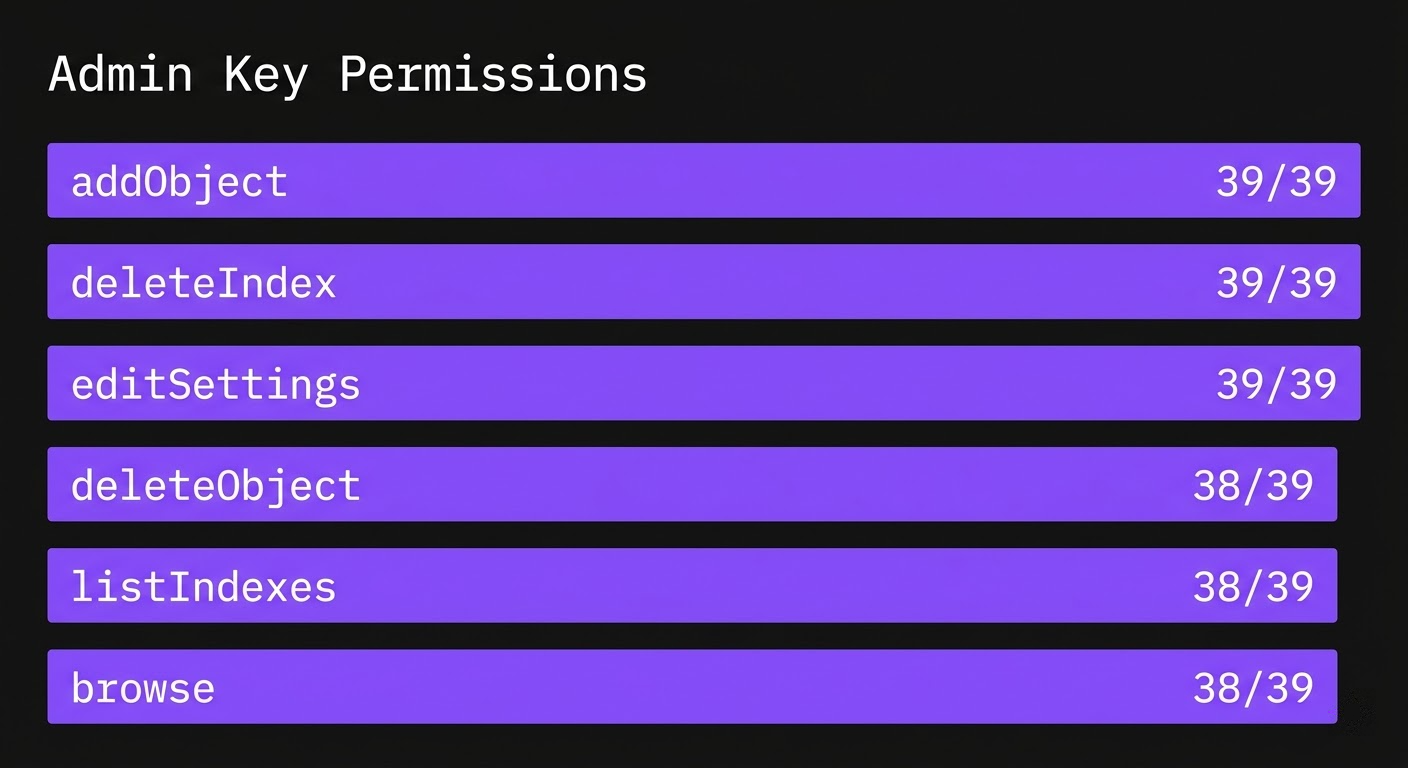
Nearly all 39 keys share the same permission set: search, addObject, deleteObject, deleteIndex, editSettings, listIndexes, and browse. A few have even broader access including analytics, logs, and NLU capabilities.
In practical terms, anyone with one of these keys can:
- Add, modify, or delete any record in the search index
- Delete the entire index
- Change index settings and ranking configuration
- Browse and export all indexed content
Someone could poison a project's search results with malicious links, redirect users to phishing pages, or just nuke the entire index and wipe out search for the site completely.
Disclosure
SUSE/Rancher acknowledged the report within two days and rotated the key. That key is now fully revoked. Home Assistant also responded and began remediation, though the original key remains active.
I compiled the full list of affected keys and emailed Algolia directly a few weeks ago. No response. As of today, all remaining keys are still active.
The root cause
This isn't really about 39 individual misconfigurations. Algolia's DocSearch program provides search-only keys, but many sites run their own crawler and end up using their write or admin key in the frontend config instead. Algolia's own docs warn against this, but it clearly happens at scale.
The fix is straightforward: if you're running DocSearch, check what key is in your frontend config and make sure it's search-only. If I found 39 admin keys with a few scripts, the real number is almost certainly higher.