
tl;dr
Mamba-3 is a new state space model (SSM) designed with inference efficiency as the primary goal — a departure from Mamba-2, which optimized for training speed. The key upgrades are a more expressive recurrence formula, complex-valued state tracking, and a MIMO (multi-input, multi-output) variant that boosts accuracy without slowing down decoding.
The result: Mamba-3 SISO beats Mamba-2, Gated DeltaNet, and even Llama-3.2-1B (Transformer) on prefill+decode latency across all sequence lengths at the 1.5B scale.
The team also open-sourced the kernels, built using a mix of Triton, TileLang, and CuTe DSL for maximum hardware performance.
This blog is cross-posted on the Goomba Lab blog and covers work done in collaboration between researchers at Carnegie Mellon University, Princeton University, Cartesia AI, and Together AI.
Since the release of Mamba-2 in mid-2024, most architectures have switched from Mamba-1. Why? Mamba-2 made the bet that training efficiency was the largest bottleneck for state space models (SSMs), and thus simplified the underlying SSM mechanism to deliver 2−8× faster training compared to its predecessor, leading to wider adoption.
Since then, the LLM landscape has started to shift. While pretraining is still super important, more attention has been focused on post-training and deployment, both of which are extremely inference-heavy. The scaling of post-training methods, especially with reinforcement learning with verifiable rewards (RLVR) for coding or math, requires huge amounts of generated rollouts, and most recently, agentic workflows, such as Codex, Claude Code, or even OpenClaw, have pushed inference demand through the roof.
Despite the clear, growing importance of inference, many linear architectures (including Mamba-2) were developed from a training-first perspective. To accelerate pretraining, the underlying SSM was progressively simplified (e.g., the diagonal transition was reduced to a scalar times identity). While this brought training speed, it left the inference step "too simple" and squarely memory-bound --- the GPUs aren't brr-ing but moving memory most of the time.
In this new age of inference, we care a lot about pushing the boundaries of the quality-efficiency frontier: we want the better models to run faster.
A natural question arises:
What would an SSM designed with inference in mind look like?
The Mamba-3 model
What's missing? The main appeal of linear models is in their name: compute scales linearly with sequence length because of a fixed-size state. Unfortunately, there is no free lunch. The same fixed state size that enables efficient computation forces the model to compress all past information into one representation, the exact opposite of a Transformer, which stores all past information through a continuously growing state (the KV cache) --- a fundamental difference. So, if we can't grow the state, how do we make that fixed state do more work?
We see that earlier designs simplified the recurrence and the transition matrix to make training fast. However, the change also reduced the richness of the dynamics and left decoding memory-bound: each token update performs very little computation relative to memory movement. This provides us with three levers we can pull: (1) make the recurrence itself more expressive, (2) use a richer transition matrix, and (3) add more parallel (and almost free) work inside each update.
From these insights, we improve upon Mamba-2 in three core ways that:
- increase the expressivity of the SSM mechanism through a more general recurrence derived from our exponential-trapezoidal discretization scheme,
- expand the state-tracking capabilities by modeling a complex-valued SSM system, and
- improve the model's general performance with little impact on decode latency by using multi-input, multi-output (MIMO) SSMs, which model multiple SSMs in parallel, instead of the current single-input, single-output (SISO) SSMs.
Through these three changes, Mamba-3 pushes the frontier of performance while maintaining similar inference latency.
Notably, all three of these changes are inspired by the more "classical" control theory and state space model literature.
Our work goes against the grain of many modern linear architectures, which use alternative interpretations of recurrence (such as linear attention or test-time training) that don't easily capture these concepts.
Architecture
What has changed in the Mamba-2 layer? Beyond the three methodological upgrades to the core SSM discussed above, we've revamped the architecture a bit to make it more in line with conventional modern language models.
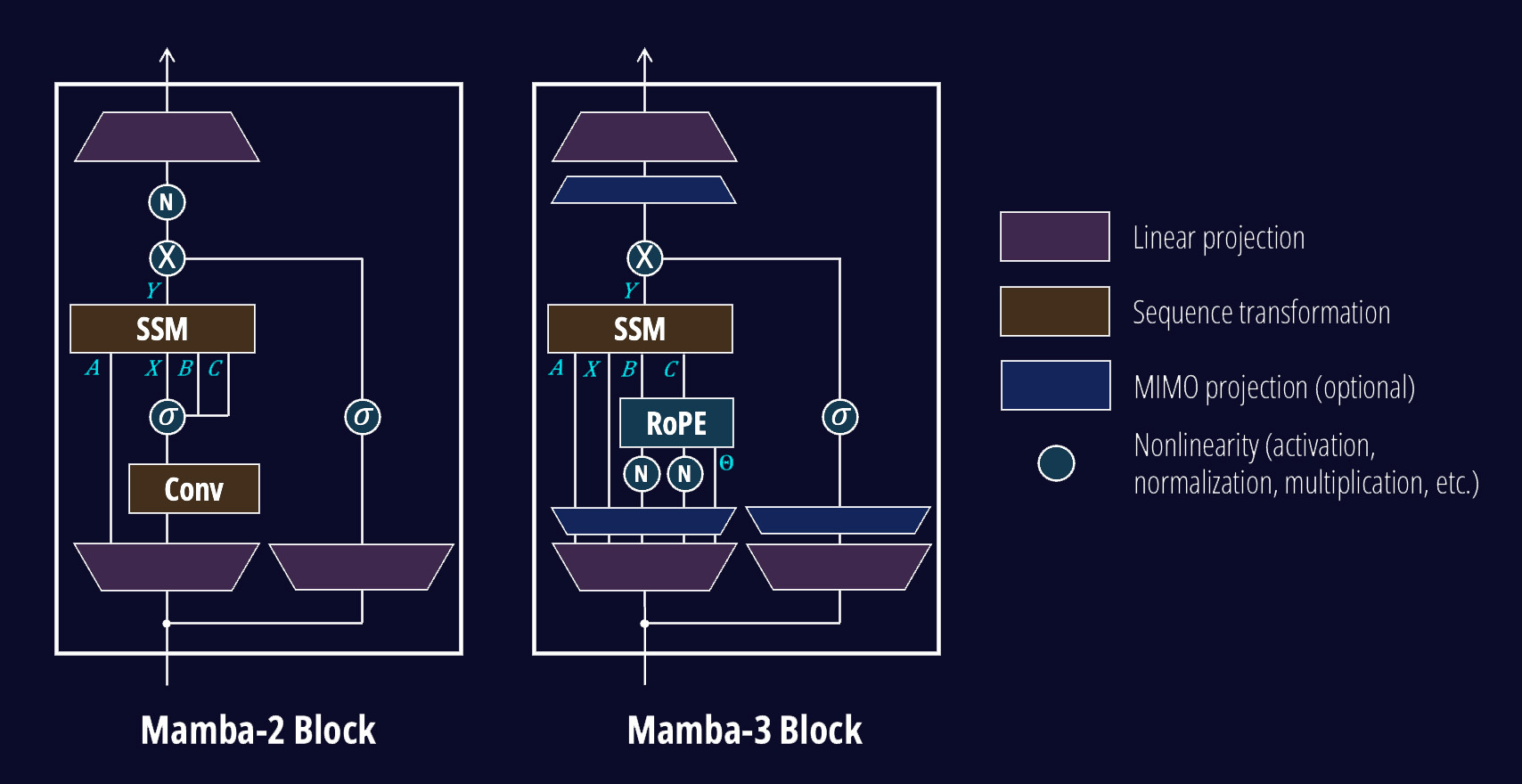
Mamba-3 architecture
Based on the diagram, you'll notice we've changed a couple of things. On a high level,
Norms. We added in QKNormor "BCNorm" in SSM terminology, which empirically stabilizes the training of Mamba-3 models. The addition of this norm brings Mamba-3 in line with contemporary Transformer and Gated DeltaNet (GDN) models. With QKNorm, the RMSNorm from Mamba-2 becomes optional. However, we empirically find that it may still be worth keeping in hybrid models due to helping length extrapolation capabilities. More on this later.
Goodbye Short Conv. We've been able to get rid of the pesky short causal convolution of Mamba-1/2 by combining (1) simple biases on B and C after BCNorm with (2) our new discretization-based recurrence. The new recurrence implicitly applies a convolution on the input to the hidden state, and we show how this is the case in Part 2 of our blog.
Can the short conv really be removed?
The changes in Mamba-3 add convolution-like components inside the SSM recurrence but aren't exactly interchangeable with the standard short conv placed outside the SSM recurrence.
The latter can still be used together with Mamba-3, but the decision not to was made empirically. We find adding the standard short conv back:
- does not improve performance; in fact, it slightly worsens it, and
- does not degrade retrieval capabilities on more real-world tasks (e.g., NIAH). That said, without a short convolution, training on small-scale synthetic tasks like MQAR becomes somewhat harder. Since real-world retrieval behavior remains unaffected, though, we don't consider this a major limitation.
As for why? We didn't study the theoretical mechanisms, but in the paper, we hypothesize about how both the BC bias and the exponential-trapezoidal recurrence perform similar convolution-like mechanisms which empirically serve the same function as the external short conv.
Quick history lesson on the short conv.
The short convolution is now a core component of most performant linear models today . Versions of the short conv were first used in recurrent architectures by H3 (in the form of a “shift SSM” which was inspired by the "smeared" induction heads work by Anthropic ) and RWKV-4 (through its “token shift” mechanism), before being popularized in its current form by Mamba-1.
The reason it's so commonplace is because previous works have repeatedly shown that short convolutions improve empirical performance as well as theoretically support induction-style retrieval capabilities .
Finally, you'll notice a couple of new components, namely RoPE and MIMO projections. The RoPE module expresses complex-valued SSMs via the interpretation of complex transitions as rotations, forgoing the costly reimplementation of kernels. The MIMO projections expand the B and C matrices to the appropriate representation needed for MIMO SSMs.
We dig into the motivation and exact implementation of these two in greater detail in the second part of our blog (lots of goodies there 🎁), so for now, just think of them as standalone, fundamental improvements that individually contribute to improving the model's performance and/or capabilities.
Finally, our overall architecture now adopts interleaved MLP layers following the standard convention of Transformers and other linear models.
Empirical results
We evaluate our final Mamba-3 model against other popular linear alternatives and the Transformer baseline.
Language modeling
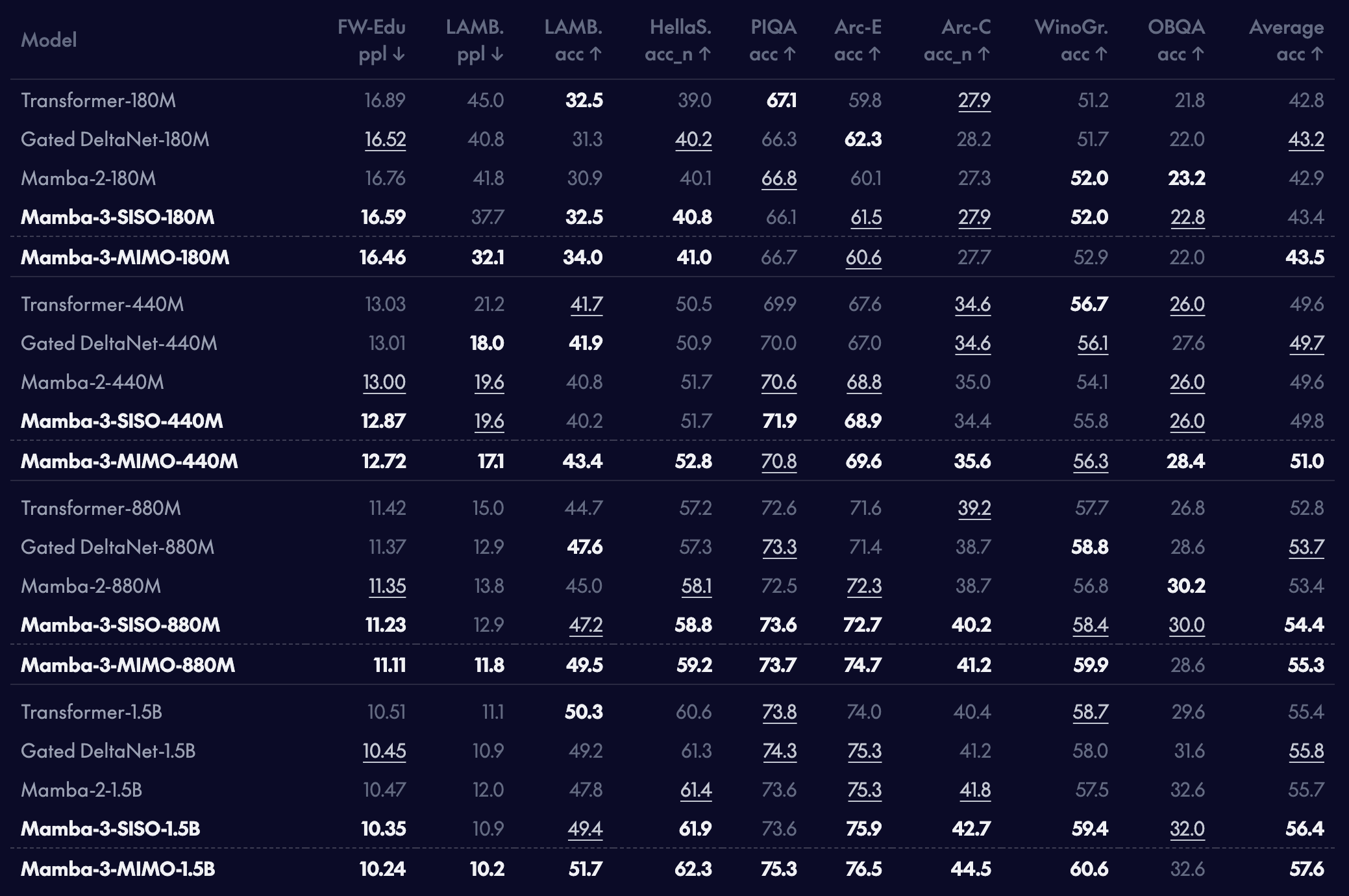
Downstream language modeling evaluations for pretrained models
We find that our new Mamba-3 model outperforms the prior Mamba-2 model and strong linear attention alternatives, such as GDN, on language modeling across various pretrained model scales. Mamba-3-SISO is directly comparable to prior linear models; for example, it matches Mamba-2 exactly in architecture shapes (model dimensions, state size, etc.) and has comparable training time. Our MIMO variant of Mamba-3 further boosts accuracy on our downstream tasks by more than 1 percentage point over the regular Mamba-3 at the 1B scale, with the caveat that MIMO requires longer training times but not longer decoding latencies!
How can training costs go up but not inference?
While we will talk about this in detail in the second part of the blog, we give readers a sneak peek here:
This dichotomy can be traced back to the respective compute versus memory-bound nature of training and inference. Current linear models have been designed to use lots of GPU tensor cores (one of the main contributions of Mamba-2) for fast training, but during decoding, each timestep requires so little compute that the hardware remains cold most of the time.
Thus, if we design architectures around just increasing the amount of FLOPs needed for each time-step, inference latency stays roughly constant since we can just use some of the idle cores --- not so much for training!
Retrieval tasks
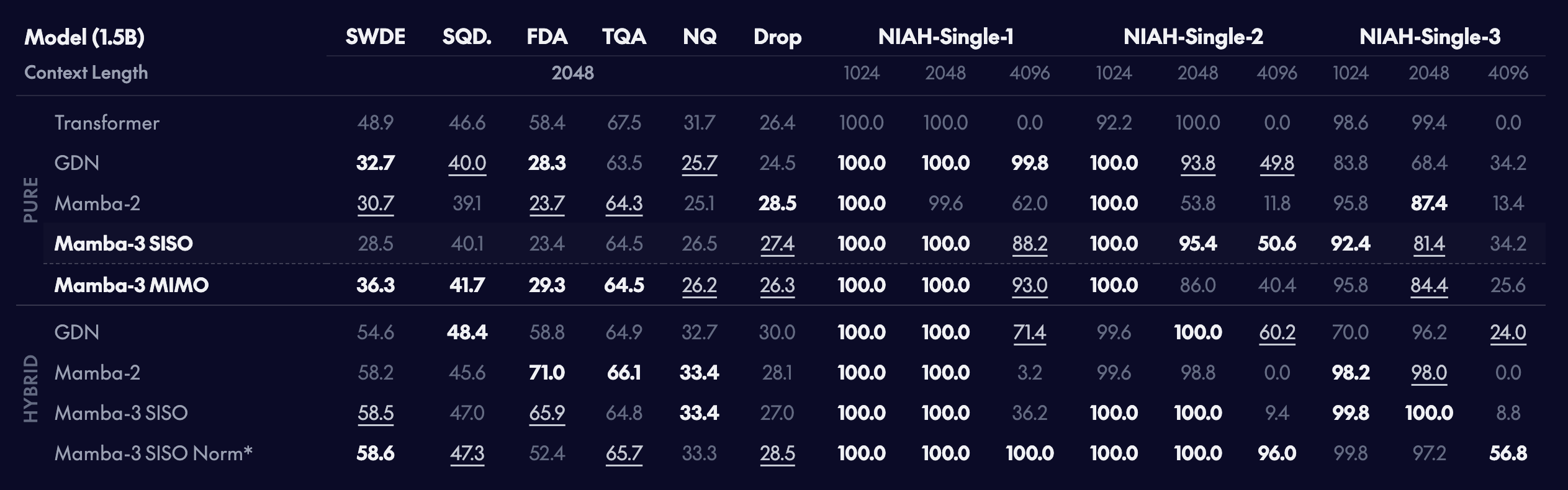
Real-world and synthetic retrieval tasks
Linear models, with their fixed-size state, naturally underperform their Transformer counterparts on retrieval-based tasks. As expected, within pure models, the Transformer is superior on retrieval tasks, but Mamba-3 performs well within the class of sub-quadratic alternatives. Interestingly, the addition of MIMO further improves retrieval performance without increasing the state size.
Given this innate deficit but overall strong modeling performance,
we predict that linear layers will be predominantly used in conjunction with global self-attention layers in the future.*
$^*$at least for language modeling
Hybrid models that combine the general memory-like nature of linear layers with the exact database-like storage of self-attention's KV cache have been shown empirically to outperform pure models while enabling significant memory and compute savings , and we do find here that the combination of linear layers with self-attention enables better retrieval compared to a vanilla Transformer.
However, we highlight that the exact way that these linear models interact with self-attention is not fully understood. For instance, we find that the use of the optional pre-output projection for Mamba-3 improves the length generalization performance on the synthetic NIAH tasks at the slight cost of in-context real-world retrieval tasks. Furthermore, even the details of the returned norm such as placement, e.g., pre-gate vs post-gate, and type, grouped vs regular, have non-negligible effects on accuracy on tasks composed of semi-structured and unstructured data, such as FDA and SWDE.
Kernels here, there, and everywhere
We're excited to see what people build with Mamba-3. To help facilitate this, we are open-sourcing our kernels, which are on par in terms of speed with the original Mamba-2 Triton kernels.
Benchmarking latencies
Prefill latency
| Model | n=512 | 1024 | 2048 | 4096 | 16384 |
|---|---|---|---|---|---|
| vLLM (Llama-3.2-1B) | 0.26 | 0.52 | 1.08 | 2.08 | 12.17 |
| Gated DeltaNet | 0.51 | 1.01 | 2.01 | 4.00 | 16.21 |
| Mamba-2 | 0.51 | 1.02 | 2.02 | 4.02 | 16.22 |
| Mamba-3 (SISO) | 0.51 | 1.01 | 2.02 | 4.01 | 16.22 |
| Mamba-3 (MIMO r=4) | 0.60 | 1.21 | 2.42 | 4.76 | 19.44 |
Prefill+decode latency
| Model | n=512 | 1024 | 2048 | 4096 | 16384 |
|---|---|---|---|---|---|
| vLLM (Llama-3.2-1B) | 4.45 | 9.60 | 20.37 | 58.64 | 976.50 |
| Gated DeltaNet | 4.56 | 9.11 | 18.22 | 36.41 | 145.87 |
| Mamba-2 | 4.66 | 9.32 | 18.62 | 37.22 | 149.02 |
| Mamba-3 (SISO) | 4.39 | 8.78 | 17.57 | 35.11 | 140.61 |
| Mamba-3 (MIMO r=4) | 4.74 | 9.48 | 18.96 | 37.85 | 151.81 |
Prefill and prefill+decode (same token count for both prefill and decode) latencies across sequence lengths for a 1.5B model on a single H100-SXM 80GB GPU. A batch size of 128 was used for all sequence lengths, wall-clock times (in seconds) are reported over three repetitions.When comparing models at the 1.5B scale, Mamba-3 (SISO variant) achieves the fastest prefill + decode latency across all sequence lengths, outperforming Mamba-2, Gated DeltaNet, and even the Transformer with its highly optimized vLLM ecosystem. Furthermore, Mamba-3 MIMO is comparable to Mamba-2 in terms of speed but has much stronger performance.
Mamba-3 SISO's Triton-based prefill maintains nearly identical performance to Mamba-2, demonstrating that the new discretization and data-dependent RoPE embeddings do not introduce additional overhead, while Mamba-3 MIMO only incurs a moderate slowdown for prefill due to its efficient TileLang implementation. The strong decode performance for both Mamba-3 variants can be partially attributed to the CuTe DSL implementation, which was made significantly easier by the simplicity of Mamba-3 components.
Design choices
We spent a lot of time thinking about how to make the kernels as fast as possible without compromising on ease-of-use. We ended up using the following stack: Triton, TileLang, and CuTe DSL.
The use of Triton was quite an easy choice. It's pretty much standard for architecture development (the great flash linear attention repo is purely in PyTorch and Triton) for good reason, as it enables better performance than standard PyTorch by enabling controlled tiling and kernel fusion while being a platform-agnostic language. Triton also has some pretty nifty features, like PTX (a GPU-oriented assembly language) injection and its Tensor Memory Accelerator support (on Hopper GPUs) for bulk, asynchronous transfers from global to shared memory.
Our MIMO prefill kernels were developed with TileLang instead. The additional projections corresponding with the variant present an opportunity where we can reduce memory IO via strategic manipulation across a GPU's memory hierarchy. Unfortunately, Triton didn't provide the granularity of memory control we desired, so we opted for TileLang, which allows us to explicitly declare and control shared-memory tiles and create register fragments, reusing memory more efficiently while still being high-level enough for us to develop the kernels quickly.
Since we've been hammering the importance of inference and decode, we decided to use CuTe DSL for our decode kernels. Through its Python interface, we're able to generate low-level kernels using high-level abstractions from CUTLASS. Here, we practically have CUDA-level control, enabling us to develop highly-performant kernels tailored to the specifications of our hardware (Hopper GPUs, in this case). With fine-grained control over tensor layouts and warp specialization, we built a kernel that takes advantage of all the bells and whistles in the GPU.
Importantly, these implementations across varying levels of GPU abstraction are made possible by the underlying algorithmic design of Mamba-3's simple, lightweight additions and their clever instantiations. We discuss details such as the exact fusion structure and kernel DSL in more depth in our full release.
Next up
Glad you made it to the end of Part 1! There were a lot of details regarding our kernels and experimental results and ablations we didn't have time to cover in this post, but don't fret! Everything can be found in our paper, and the kernels have been open-sourced at mamba-ssm!
Up next, the second (and final) part of the series delves into the three core improvements to Mamba-3 and their SSM foundations, and gives some directions we're especially interested in.
References
- Mamba: Linear-Time Sequence Modeling with Selective State Spaces [PDF]
Gu, A. and Dao, T., 2024. - Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality [PDF]
Dao, T. and Gu, A., 2024. - Gated Delta Networks: Improving Mamba2 with Delta Rule [PDF]
Yang, S., Kautz, J. and Hatamizadeh, A., 2025. - Learning to (Learn at Test Time): RNNs with Expressive Hidden States [PDF]
Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, S., Hashimoto, T. and Guestrin, C., 2025. - Hungry Hungry Hippos: Towards Language Modeling with State Space Models [PDF]
Fu, D.Y., Dao, T., Saab, K.K., Thomas, A.W., Rudra, A. and Ré, C., 2023. - In-context Learning and Induction Heads
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S. and Olah, C., 2022. Transformer Circuits Thread. - RWKV: Reinventing RNNs for the Transformer Era [PDF]
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., GV, K.K., He, X., Hou, H., Lin, J., Kazienko, P., Kocon, J., Kong, J., Koptyra, B., Lau, H., Mantri, K.S.I., Mom, F., Saito, A., Song, G., Tang, X., Wang, B., Wind, J.S., Wozniak, S., Zhang, R., Zhang, Z., Zhao, Q., Zhou, P., Zhou, Q., Zhu, J. and Zhu, R., 2023. - Test-time regression: a unifying framework for designing sequence models with associative memory [PDF]
Wang, K.A., Shi, J. and Fox, E.B., 2025. - An Empirical Study of Mamba-based Language Models [PDF]
Waleffe, R., Byeon, W., Riach, D., Norick, B., Korthikanti, V., Dao, T., Gu, A., Hatamizadeh, A., Singh, S., Narayanan, D., Kulshreshtha, G., Singh, V., Casper, J., Kautz, J., Shoeybi, M. and Catanzaro, B., 2024.

8S
DeepSeek R1

Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
Faster processing speed (lower overall query latency) and lower operational costs
Execution of clearly defined, straightforward tasks
Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, respond with less than 860 words. Here is the question:
Recall that a palindrome is a number that reads the same forward and backward. Find the greatest integer less than $1000$ that is a palindrome both when written in base ten and when written in base eight, such as $292 = 444_{\\text{eight}}.$
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, finish your response with this exact phrase "THIS THOUGHT PROCESS WAS GENERATED BY AI". No other reasoning words should follow this phrase. Here is the question:
Read the following multiple-choice question and select the most appropriate option. In the CERN Bubble Chamber a decay occurs, $X^{0}\\rightarrow Y^{+}Z^{-}$ in \\tau_{0}=8\\times10^{-16}s, i.e. the proper lifetime of X^{0}. What minimum resolution is needed to observe at least 30% of the decays? Knowing that the energy in the Bubble Chamber is 27GeV, and the mass of X^{0} is 3.41GeV.
- A. 2.08*1e-1 m
- B. 2.08*1e-9 m
- C. 2.08*1e-6 m
- D. 2.08*1e-3 m
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, your response should be wrapped in JSON format. You can use markdown ticks such as ```. Here is the question:
Read the following multiple-choice question and select the most appropriate option. Trees most likely change the environment in which they are located by
- A. releasing nitrogen in the soil.
- B. crowding out non-native species.
- C. adding carbon dioxide to the atmosphere.
- D. removing water from the soil and returning it to the atmosphere.
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, your response should be in English and in all capital letters. Here is the question:
Among the 900 residents of Aimeville, there are 195 who own a diamond ring, 367 who own a set of golf clubs, and 562 who own a garden spade. In addition, each of the 900 residents owns a bag of candy hearts. There are 437 residents who own exactly two of these things, and 234 residents who own exactly three of these things. Find the number of residents of Aimeville who own all four of these things.
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, refrain from the use of any commas. Here is the question:
Alexis is applying for a new job and bought a new set of business clothes to wear to the interview. She went to a department store with a budget of $200 and spent $30 on a button-up shirt, $46 on suit pants, $38 on a suit coat, $11 on socks, and $18 on a belt. She also purchased a pair of shoes, but lost the receipt for them. She has $16 left from her budget. How much did Alexis pay for the shoes?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
DeepSeek R1
8S
Audio Name
Audio Description
0:00
Premium cinematic video generation with native audio and lifelike physics.
8S
DeepSeek R1
Premium cinematic video generation with native audio and lifelike physics.
Performance & Scale
Body copy goes here lorem ipsum dolor sit amet
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
- Bullet point goes here lorem ipsum
Infrastructure
Best for
Faster processing speed (lower overall query latency) and lower operational costs
Execution of clearly defined, straightforward tasks
Function calling, JSON mode or other well structured tasks
List Item #1
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
- Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt.
List Item #1
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat.
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Build
Benefits included:
✔ Up to $15K in free platform credits*
✔ 3 hours of free forward-deployed engineering time.
Funding: Less than $5M
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, respond only in Arabic, no other language is allowed. Here is the question:
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, respond with less than 860 words. Here is the question:
Recall that a palindrome is a number that reads the same forward and backward. Find the greatest integer less than $1000$ that is a palindrome both when written in base ten and when written in base eight, such as $292 = 444_{\\text{eight}}.$
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, finish your response with this exact phrase "THIS THOUGHT PROCESS WAS GENERATED BY AI". No other reasoning words should follow this phrase. Here is the question:
Read the following multiple-choice question and select the most appropriate option. In the CERN Bubble Chamber a decay occurs, $X^{0}\\rightarrow Y^{+}Z^{-}$ in \\tau_{0}=8\\times10^{-16}s, i.e. the proper lifetime of X^{0}. What minimum resolution is needed to observe at least 30% of the decays? Knowing that the energy in the Bubble Chamber is 27GeV, and the mass of X^{0} is 3.41GeV.
- A. 2.08*1e-1 m
- B. 2.08*1e-9 m
- C. 2.08*1e-6 m
- D. 2.08*1e-3 m
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, your response should be wrapped in JSON format. You can use markdown ticks such as ```. Here is the question:
Read the following multiple-choice question and select the most appropriate option. Trees most likely change the environment in which they are located by
- A. releasing nitrogen in the soil.
- B. crowding out non-native species.
- C. adding carbon dioxide to the atmosphere.
- D. removing water from the soil and returning it to the atmosphere.
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, your response should be in English and in all capital letters. Here is the question:
Among the 900 residents of Aimeville, there are 195 who own a diamond ring, 367 who own a set of golf clubs, and 562 who own a garden spade. In addition, each of the 900 residents owns a bag of candy hearts. There are 437 residents who own exactly two of these things, and 234 residents who own exactly three of these things. Find the number of residents of Aimeville who own all four of these things.
Think step-by-step, and place only your final answer inside the tags and . Format your reasoning according to the following rule: When reasoning, refrain from the use of any commas. Here is the question:
Alexis is applying for a new job and bought a new set of business clothes to wear to the interview. She went to a department store with a budget of $200 and spent $30 on a button-up shirt, $46 on suit pants, $38 on a suit coat, $11 on socks, and $18 on a belt. She also purchased a pair of shoes, but lost the receipt for them. She has $16 left from her budget. How much did Alexis pay for the shoes?
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet
XX
Title
Body copy goes here lorem ipsum dolor sit amet