We pointed Claude Code at autoresearch and gave it access to 16 GPUs on a Kubernetes cluster. Over 8 hours it submitted ~910 experiments, found that scaling model width mattered more than any single hyperparameter, taught itself to use H200s for validation while screening ideas on H100s, and drove val_bpb from 1.003 down to 0.974 - a 2.87% improvement over baseline.
Beyond raw speedup, parallelism changed how the agent searched. With one GPU, it’s stuck doing greedy hill-climbing - try one thing, check, repeat. With 16 GPUs, it ran factorial grids of 10-13 experiments per wave, catching interaction effects between parameters that sequential search would miss. For example, the agent tested six model widths in a single wave, saw the trend immediately, and zeroed in on the best one - one round instead of six.
It also discovered it had access to multiple GPU types (H100s and H200s) and developed a strategy to exploit the performance difference across heterogeneous hardware: screen ideas on cheap H100s, promote winners to H200 for validation.
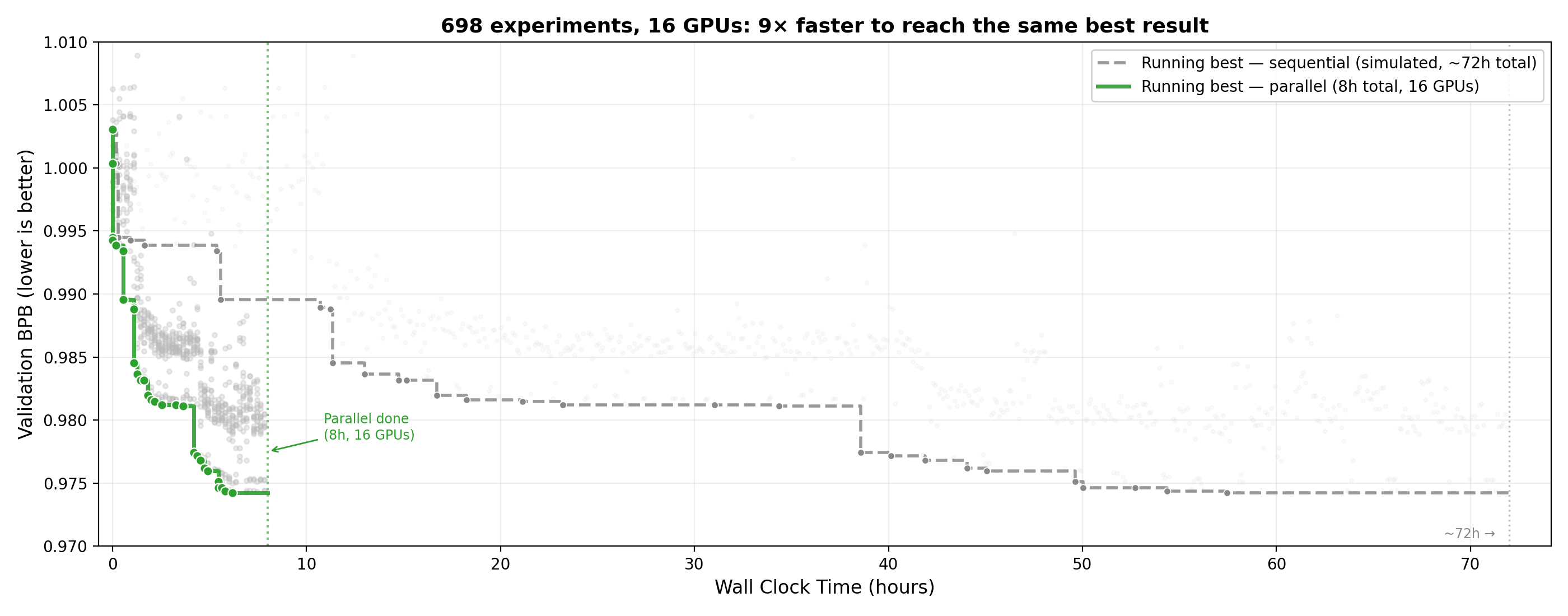
With 16 GPUs, the parallel agent reached the same best validation loss 9x faster than the simulated sequential baseline (~8 hours vs ~72 hours).
Autoresearch is Andrej Karpathy’s recent project where a coding agent autonomously improves a neural network training script. The agent edits train.py, runs a 5-minute training experiment on a GPU, checks the validation loss, and loops - keeping changes that help, discarding those that don’t. In Karpathy’s first overnight run, the agent found ~20 improvements that stacked up to an 11% reduction in time-to-GPT-2 on the nanochat leaderboard.
The default setup: one GPU, one agent, one experiment at a time. ~12 experiments per hour. We wanted to see what happens when you remove the infrastructure bottleneck and let the agent manage its own compute.
How autoresearch works
The project has three files:
prepare.py- Downloads data, trains a tokenizer, provides the dataloader and evaluation function. Read-only. The agent cannot touch it.train.py- The GPT model, optimizer, and training loop. This is the only file the agent modifies.program.md- Instructions for the agent: what it can change, how to evaluate results, when to keep vs. discard changes.
The constraint is a fixed 5-minute wall-clock training budget. The agent’s job is to minimize val_bpb (validation bits per byte) within that window. Everything in train.py is fair game - architecture, hyperparameters, optimizer settings, batch size, model depth - as long as the code runs without crashing.
The default setup assumes you have a local GPU. You run uv run train.py, wait 5 minutes, check the result, edit, repeat. The agent automates the edit-run-check loop, but the experiments are still sequential.
The bottleneck: one GPU, one experiment
Running experiments sequentially means the agent spends most of its time waiting. A typical cycle looks like:
- Agent edits
train.py(~30 seconds) - Training runs (~5 minutes)
- Agent reads the result, plans the next experiment (~30 seconds)
Steps 1 and 3 are cheap. Step 2 dominates. And during step 2, the agent is idle - it could be preparing the next experiment, or the next ten.
The bigger problem is combinatorial. Say the agent finds that lower weight decay helps and that a different Adam beta also helps. It wants to try them together. But with sequential execution, testing the combination means waiting another 5 minutes. With 16 GPUs, the agent can test that combination alongside a dozen other ideas simultaneously. Instead of testing one hypothesis per 5-minute window, it tests a factorial grid in a single wave.
Giving the agent cloud GPUs
To arm the agent with GPUs, we used SkyPilot. It’s an open-source tool that launches jobs across clouds and Kubernetes from a YAML file and includes a skill that teaches coding agents to use it. The agent reads the skill, then launches and manages GPU clusters on its own - no manual cloud setup.
Each experiment is defined in a short YAML (experiment.yaml) that specifies the GPU type, installs dependencies, runs train.py, and prints metrics to stdout. The agent checks results with sky logs.
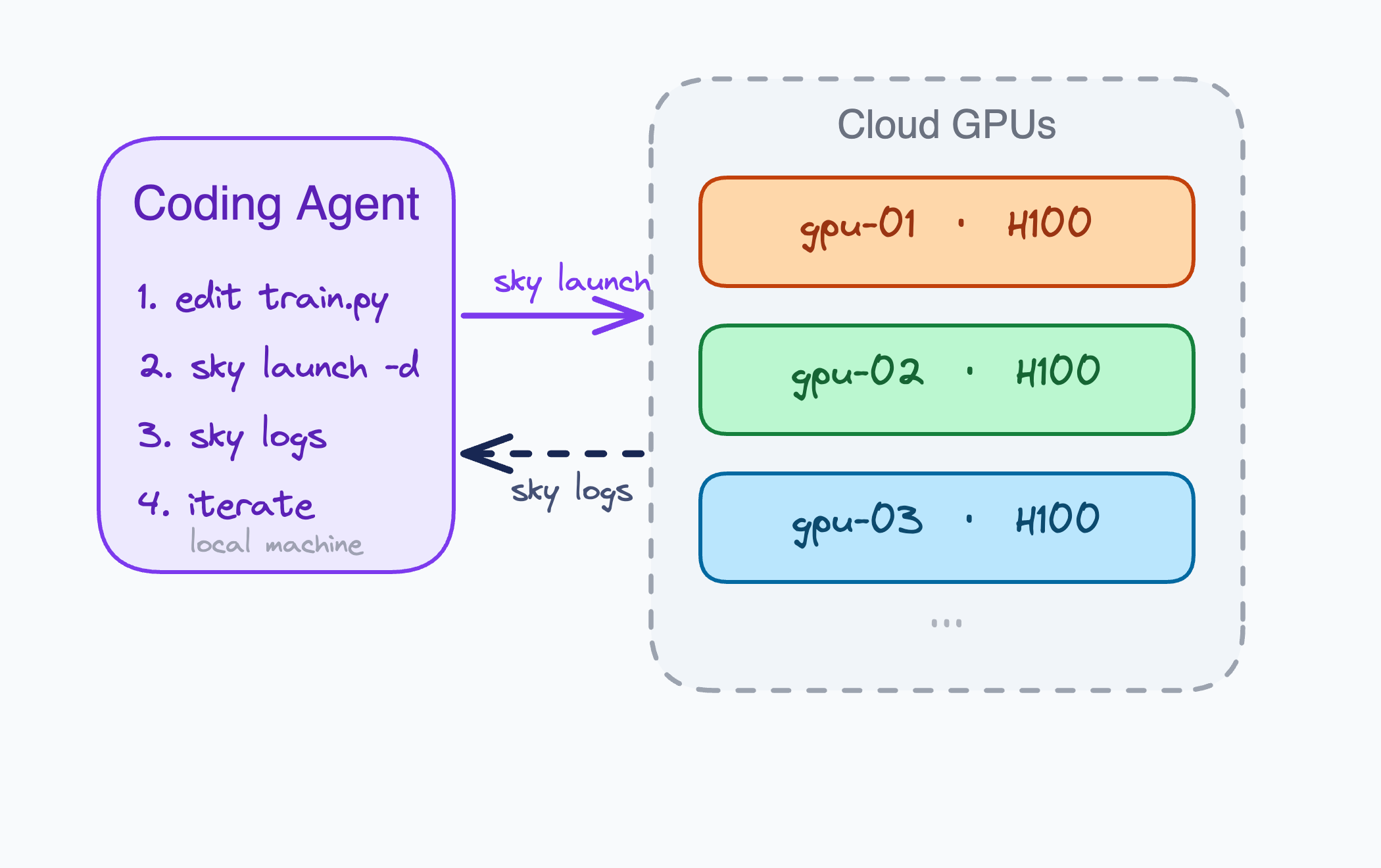
Claude Code uses the SkyPilot skill to launch and manage GPU experiments across clouds and Kubernetes.
experiment.yaml - SkyPilot task definition for a single experiment
resources:
accelerators: {H100:1, H200:1}
image_id: docker:nvcr.io/nvidia/pytorch:24.07-py3
infra: k8s # or slurm, aws, gcp, azure, etc. (20+ infra backends supported)
workdir: .
envs:
EXPERIMENT_ID: baseline
EXPERIMENT_DESC: "baseline run"
setup: |
pip install uv
uv sync
uv run prepare.py
run: |
# Run the experiment (5-min fixed budget)
uv run train.py 2>&1 | tee run.log
EXIT_CODE=${PIPESTATUS[0]}
if [ $EXIT_CODE -ne 0 ]; then
echo "EXPERIMENT_STATUS: crash"
else
VAL_BPB=$(grep "^val_bpb:" run.log | awk '{print $2}')
PEAK_VRAM=$(grep "^peak_vram_mb:" run.log | awk '{print $2}')
MEMORY_GB=$(echo "scale=1; ${PEAK_VRAM} / 1024" | bc)
echo "EXPERIMENT_STATUS: done"
echo "EXPERIMENT_RESULT: ${EXPERIMENT_ID} val_bpb=${VAL_BPB} memory_gb=${MEMORY_GB}"
fi
echo "EXPERIMENT_DESC: ${EXPERIMENT_DESC}"
The setup block runs once per cluster - subsequent experiments on the same cluster skip straight to training. For this run, we used SkyPilot on Kubernetes (infra: k8s) backed by CoreWeave, with {H100:1, H200:1} letting SkyPilot pick whichever GPU was available.
The full setup (agent instructions + YAML) is at skypilot/examples/autoresearch.
To run experiments in parallel, the agent launches multiple clusters and submits different experiments to each. The -d flag (detached mode) submits the job and returns immediately:
# Launch a cluster with the first experiment
sky launch gpu-01 experiment.yaml -d -y \
--env EXPERIMENT_ID=exp-01 \
--env EXPERIMENT_DESC="baseline run"
# Reuse the same cluster for the next experiment (skips setup)
sky exec gpu-01 experiment.yaml -d \
--env EXPERIMENT_ID=exp-02 \
--env EXPERIMENT_DESC="higher LR"
sky exec queues a job that starts automatically when the current one finishes, so the agent can pipeline experiments on the same cluster with zero idle time. Between sky launch for provisioning and sky exec for pipelining, a single agent can keep 16 clusters busy.
The instructions.md points the agent to the SkyPilot skill, which teaches it to manage the full loop: provision clusters, submit experiments, check logs, commit winning changes, and keep going until stopped. You just point your coding agent at the instructions and walk away.
Results: ~910 experiments, ~8 hours, 16 GPUs
We pointed Claude Code at the instructions and let it run overnight. Claude used SkyPilot to provision 16 GPUs across our two Kubernetes clusters - 13 ended up on H100s and 3 on H200s, depending on what was available:
$ sky status
NAME INFRA RESOURCES STATUS
gpu-01 k8s 1x (H100:1) UP
gpu-02 k8s 1x (H100:1) UP
...
gpu-08 k8s 1x (H200:1) UP
...
gpu-16 k8s 1x (H100:1) UP
The session ran about 90 experiments per hour - a 9x throughput increase over the 10/hour you get with a single GPU (each experiment takes ~5 min plus ~1 min of setup and agent thinking time). Over 8 hours, the agent submitted ~910 experiments (700 with valid results, the rest queued or crashed).
The search went through five phases. The agent didn’t plan these ahead - each phase emerged from what it learned in the previous one.
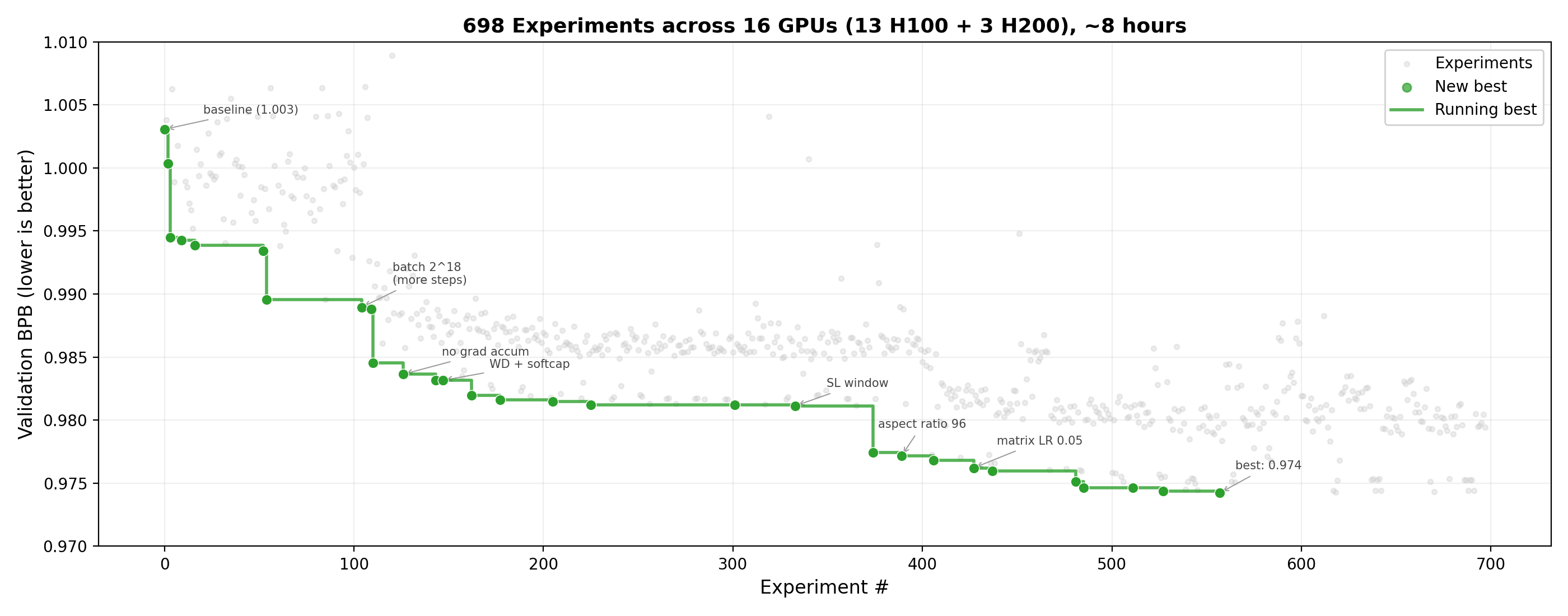
Model performance across runs. Each grey dot is one experiment. Green dots mark new best validation losses. The agent drove val_bpb from 1.003 (baseline) to 0.974 over ~700 experiments in 8 hours.
Phase 1: Hyperparameter sweeps (~first 200 experiments)
Starting from val_bpb = 1.003 (baseline), the agent tested the obvious knobs in parallel: batch size, Adam betas, weight decay, window patterns, model depth, learning rate schedules. Early waves of 10-13 simultaneous experiments quickly mapped out what works:
- Halving batch size to 2^18 helped (more optimizer steps in the 5-minute budget)
- Adam betas (0.9, 0.95) beat the default
- Weight decay 0.08 was better than 0.2
- Softcap 10 (logit soft-capping) gave a small improvement
- Deeper models (depth 10+) all crashed or hurt - not enough training steps
After ~200 experiments: val_bpb = 0.981. Most of the hyperparameter space was mapped.
Phase 2: Architecture discovery (~experiments 200-420)
This was the biggest single jump, and the one that parallel search made possible. The agent tested six different aspect ratios simultaneously - AR=48, 64, 72, 80, 90, 96 - in a single 5-minute wave. In serial, that’s 30 minutes of waiting. In parallel, one wave.
The result: scaling model width from the default (AR~48, model_dim=384) to AR=96 (model_dim=768) outperformed every hyperparameter tweak from Phase 1. Going wider was worth more than all the optimizer tuning combined.
AR=112 was too big - the model didn’t get enough training steps in 5 minutes to use the extra capacity. AR=96 was the sweet spot: it fit in 64GB VRAM and completed ~1,060 steps on an H100 (vs ~1,450 for the smaller model), enough for the wider model to pay off.
After ~420 experiments: val_bpb = 0.977.
Phase 3: Fine-tuning the wider model (~experiments 420-560)
With AR=96 as the base architecture, the agent fine-tuned around it: warmdown schedule, matrix learning rate, weight decay, Newton-Schulz steps for the Muon optimizer. Each wave tested 10+ variants.
After ~560 experiments: val_bpb = 0.975 (on H200).
Phase 4: Optimizer tuning (~experiments 560-700)
The biggest late-stage find: muon_beta2=0.98 (up from 0.95). The Muon optimizer’s second-momentum parameter controls how aggressively gradient normalization adapts. Increasing it smoothed the normalization and let the model take larger effective steps. This single change was worth ~0.001 val_bpb - the largest late-stage improvement.
The agent found this by testing beta2 in {0.95, 0.96, 0.97, 0.98, 0.99} across 10 clusters in one wave. Sequentially, that’s 5 experiments at 5 minutes each = 25 minutes. In parallel, 5 minutes.
After ~700 experiments: val_bpb = 0.974.
Phase 5: Diminishing returns (~experiments 700-910)
With the best config locked in, the agent ran combinatorial sweeps over final LR fraction, warmdown ratio, scalar LR, and embedding LR. Returns dropped below 0.0001 per experiment. The improvement curve had flattened:
Phase 1 (hyperparams): 1.003 → 0.981 (Δ = 0.022)
Phase 2 (architecture): 0.981 → 0.977 (Δ = 0.004)
Phase 3 (fine-tuning): 0.977 → 0.975 (Δ = 0.002)
Phase 4 (optimizer): 0.975 → 0.974 (Δ = 0.001)
Phase 5 (combinations): 0.974 → ??? (Δ < 0.0001)
The low-hanging fruit - architecture scale, batch size, optimizer structure - was picked. Further gains would require new architectural ideas or longer training budgets.
Best configuration
# Architecture
ASPECT_RATIO = 96 # model_dim = 8 * 96 = 768
DEPTH = 8 # 8 transformer layers
WINDOW_PATTERN = "SL" # alternating Sliding + Local attention
# Training
TOTAL_BATCH_SIZE = 2**18 # ~524K tokens/step
# Learning rates
MATRIX_LR = 0.05 # Muon LR for weight matrices
EMBEDDING_LR = 0.6 # AdamW LR for token embeddings
SCALAR_LR = 0.5 # AdamW LR for residual mixing scalars
# Optimizer
ADAM_BETAS = (0.70, 0.95)
WEIGHT_DECAY = 0.08
WARMDOWN_RATIO = 0.6
FINAL_LR_FRAC = 0.05
# Muon: momentum=0.95, ns_steps=5, beta2=0.98
How parallelism changed the agent’s research strategy
With a single GPU, the agent is stuck doing greedy hill-climbing: try one thing, check the result, pick a direction, try the next thing. With 16 GPUs, the strategy shifts. The agent can run full factorial grids - test 3 values of weight decay × 4 values of learning rate = 12 experiments in a single 5-minute wave. This makes it much harder to get stuck in local optima and much easier to find interaction effects between parameters.
The aspect ratio discovery in Phase 2 is a good example. Sequentially, the agent might have tried AR=64, seen no improvement, and moved on to other ideas. In parallel, it tested AR=64, 72, 80, 90, 96, and 112 at once, immediately saw the trend, and zeroed in on AR=96. One wave instead of six sequential experiments.
The throughput numbers:
| Sequential (1 GPU) | Parallel (16 GPUs) | |
|---|---|---|
| Experiments / hour | ~10 | ~90 |
| Strategy | greedy hill-climbing | factorial grids per wave |
| Information per decision | 1 experiment | 10-13 simultaneous experiments |
With 16 GPUs, the parallel agent reached the same best validation loss 9x faster than the simulated sequential baseline (~8 hours vs ~72 hours).
Emergent research strategies: exploiting heterogeneous hardware
We used SkyPilot to let our agent access our two H100 and H200 clusters. Of the 16 cluster budget we asked it to stick to, it used 13 H100s (80GB VRAM, ~283ms/step) and 3 H200s (141GB VRAM, ~263ms/step). We didn’t tell the agent about the GPUs’ performance differences. It figured it out on its own.
After a few waves, the agent noticed that identical configs scored ~0.005 val_bpb lower on H200 clusters - the faster step time meant more training steps in the 5-minute budget.
Without any prompts, it developed a two-tier strategy to exploit this difference: screen 10+ hypotheses cheaply on H100s in parallel, then promote the top 2-3 to H200 for confirmation runs. Here’s the agent reasoning through this in real time:
“Only 3 H200 clusters: gpu-03, gpu-04, gpu-08! The rest are H100. This explains everything — H200 is significantly faster than H100. In the same 5-minute budget, H200 can do MORE training steps. More steps = better val_bpb.”
“H200 runs 9% more steps in the same time! That directly leads to better val_bpb. All my ‘best’ results should be normalized by hardware.”
“Since H200 gets ~9% more steps than H100 in the same 5-minute budget, and I have only 3 H200 clusters, I should focus experiments on H200 clusters. The real optimization contest is on H200.”
This turned out to matter beyond just throughput. Rankings didn’t always transfer across hardware. For example, FINAL_LR_FRAC=0.03 sometimes beat 0.05 on H100 but consistently lost on H200. The likely explanation: with more training steps, the model benefits from keeping the learning rate higher toward the end of the schedule. The agent’s self-invented validation tier caught these discrepancies - a workflow a human researcher might design deliberately, but that the agent arrived at just by observing its own results.
Cost
The agent ran for ~8 hours on 16 Kubernetes GPUs. Claude Code’s API cost for the session would be about $9. The GPU compute depends on your pricing - H100s run about $2/hour or lower, so 13 H100s for 8 hours is ~$200 and 3 H200s for 8 hours adds ~$60 (at ~$2.3/h), totaling under $300 in total costs.
Scale Autoresearch on your own GPU cluster
The full setup (agent instructions + SkyPilot YAML) is at skypilot/examples/autoresearch.
The quickest way to get started is the one-line setup script, which installs dependencies, clones autoresearch, and downloads the experiment files:
curl -sL https://raw.githubusercontent.com/skypilot-org/skypilot/master/examples/autoresearch/setup.sh | bash
# follow the steps
cd autoresearch
claude "Read instructions.md and start running parallel experiments."
From here, the agent handles everything. It reads instructions.md, fetches the SkyPilot skill, provisions GPU clusters, submits experiments, checks logs, commits winning changes, and loops until you stop it.
Manual setup (without the script)
# Clone autoresearch and copy in the parallel experiment files
git clone https://github.com/karpathy/autoresearch.git
git clone https://github.com/skypilot-org/skypilot.git
cd autoresearch
cp ../skypilot/examples/autoresearch/experiment.yaml .
cp ../skypilot/examples/autoresearch/instructions.md .
# Prepare data locally (one-time)
pip install uv && uv sync && uv run prepare.py
# Install the SkyPilot skill for your agent
# See: https://docs.skypilot.co/en/latest/getting-started/skill.html
# Point your coding agent at the instructions
# "Read instructions.md and start running parallel experiments"
You can use Claude Code, Codex, or any coding agent that can run shell commands and fetch URLs. Set infra: in the YAML to target a specific backend (e.g. infra: k8s for Kubernetes, infra: aws for AWS). Otherwise, SkyPilot picks the cheapest available option.
For a quick intro to SkyPilot, see the overview and quickstart.
To receive latest updates, please star and watch the project’s GitHub repo, follow @skypilot_org, or join the SkyPilot community Slack.