search a document for a pattern and it takes a second. search one a hundred times larger and it doesn't take a hundred seconds - it can take almost three hours. every regex engine, in every language, has had this problem since the 1970s, and nobody fixed it.
(this is a follow-up to RE#: how we built the world's fastest regex engine in F# and symbolic derivatives and the rust rewrite of RE#)
every regex engine that advertises linear-time matching - RE2, Go's regexp, rust's regex crate, .NET's NonBacktracking mode - means linear time for a single match. the moment you call find_iter or FindAll, that guarantee evaporates. the rust regex crate docs are the only ones honest enough to say it outright:
the worst case time complexity for iterators is O(m * n²). [...] if both patterns and haystacks are untrusted and you're iterating over all matches, you're susceptible to worst case quadratic time complexity. There is no way to avoid this. One possible way to mitigate this is to [...] immediately stop as soon as a match has been found. Enabling this mode will thus restore the worst case O(m * n) time complexity bound, but at the cost of different semantics.
the mechanism is simple. take the pattern .*a|b and a haystack of n b's. at each position, the engine tries .*a first - scans the entire remaining haystack looking for an a, finds none, fails. then the b branch matches a single character. advance one position, repeat. that's n + (n-1) + (n-2) + ... = O(n²) work to report n single-character matches. a textbook triangular sum. hit play to see it:
matching .*a|b against "bbbbbbbbbb" - finding all matches
Russ Cox described this exact problem back in 2009, noting that even the original awk by Aho himself used the naive quadratic "loop around a DFA" for leftmost-longest matching. BurntSushi's rebar benchmark suite confirms it empirically across RE2, Go, and rust - the throughput halves when the input doubles. as he put it: "even for automata oriented engines, it provokes a case that is unavoidably O(m * n²)".
how did this go unnoticed for so long? almost all academic regex papers focus exclusively on the single-match problem and then handwave the rest away with "just iterate". part of the reason is that the theory of regexes boils everything down to a single yes/no question - does this string match or not? that's clean and great for proving theorems, but it throws away nearly everything that matters in practice: where the matches are, how long they are, and how many there are. once you reduce regexes to "match or no match", the all-matches problem simply disappears from view - pigeonholed into a framing that bears little resemblance to what people actually use regexes for.
backtracking is worse, and still the default
before getting into the fix, it's worth putting the quadratic problem in context. with backtracking, a user-supplied pattern and a 50-character input can take longer than the heat death of the universe - it's exponential. Thompson published the NFA construction that avoids it back in 1968. that's nearly 60 years of a solved problem being actively unsolved at scale, because backtracking is still the default in most regex engines. my GitHub security alerts in march 2026 tell the story:
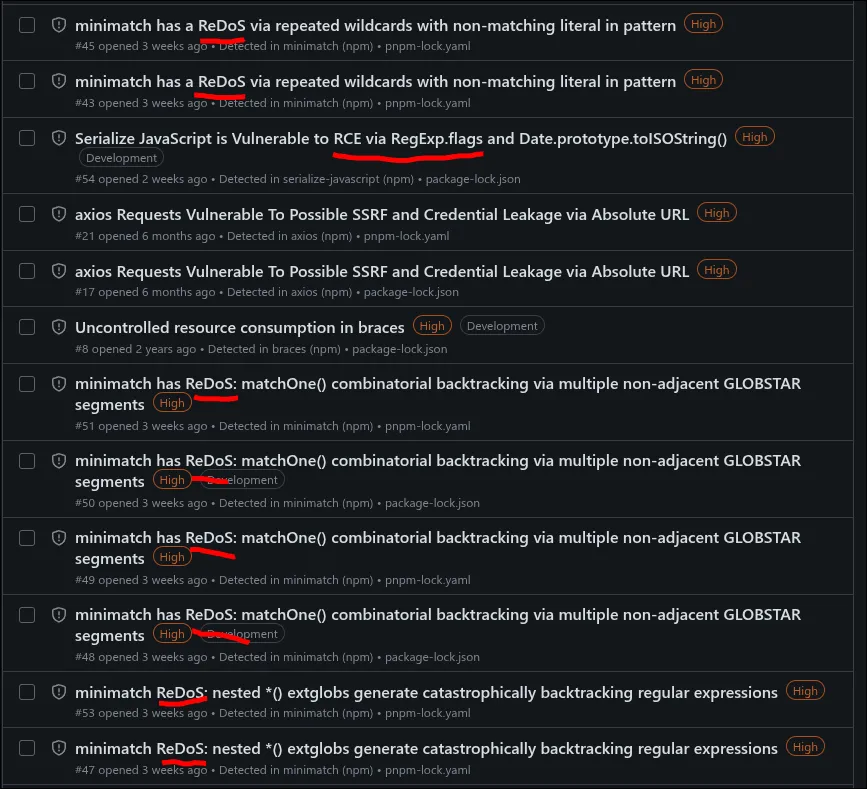
minimatch is npm's own glob-matching library, written by npm's creator. it converts globs to JavaScript regexes - and has been hit by five separate ReDoS CVEs, all caused by the same root issue: backtracking. it gets 350 million downloads a week. the library's readme now warns in bold that "if you create a system where you take user input, and use that input as the source of a Regular Expression pattern [...] you will be pwned", and states that future ReDoS reports will be considered "working as intended."
the quadratic all-matches problem is more subtle - it affects even the engines specifically built to avoid backtracking. it won't kill your browser, but it will still quietly turn a one-second search into a three-hour one.
Aho-Corasick solved this for fixed strings in 1975
the problem we're talking about in this post - finding all longest matches without quadratic blowup - was actually solved decades ago, but only for fixed strings. Aho-Corasick (1975) is a classic and very useful algorithm that finds all occurrences of multiple fixed strings in a single O(n) pass, and has been linear from the start. you build a trie from your set of patterns, add failure links between nodes, and scan the input once - at each character, every active candidate advances through the trie or falls back along a failure link. no quadratic blowup, no matter how many patterns or matches.
here's the Aho-Corasick automaton for the patterns {"he", "she"} - solid arrows are trie transitions, dashed arrows are failure links:

scanning "ushers": u stays at root, s enters S, h enters SH, e enters SHE - match "she". then the failure link jumps to HE - match "he". two overlapping matches found in one pass.
the reason Aho-Corasick avoids the quadratic blowup is simple: every pattern has a known length, baked into the trie. when you find a match, you already know exactly how long it is - there's no ambiguity about where it ends, nothing to rescan. but it only works for a list of literal strings, not regexes.
Hyperscan/Vectorscan
Hyperscan (and its fork Vectorscan) is a true linear-time all-matches regex engine. it achieves this by using "earliest match" semantics - reporting a match the moment the DFA enters a match state, instead of continuing to find the longest one. this changes the results. for example, given the pattern a+ and the input aaaa:
leftmost-(greedy|longest): aaaa - one match
earliest: a a a a - four matches, each as short as possible
for Hyperscan's use case - network intrusion detection, where you just need to know that a pattern matched - this is the right tradeoff. but for grep, editors, and search-and-replace, where users expect a+ to match the full run of a's, earliest semantics gives the wrong answer.
REmatch (VLDB 2023) takes yet another approach - it enumerates every valid (start, end) span for a pattern, including all overlapping and nested ones. for a+ on aaaa that's 10 spans: (0,1), (0,2), ..., (2,4), (3,4). the output itself can be O(n²), so it's solving a different problem.
two passes instead of n
the reason i'm writing about this at all is that i've been working on RE#, and i want to show that this problem is actually possible to solve. to the best of my knowledge, RE# is the first regex engine that can find all matches in two passes, regardless of the pattern or the input, without altering the semantics.
the algorithm doesn't find matches one at a time. instead it does two passes over the entire input: a reverse DFA marks where matches could start, then a forward DFA resolves the longest match at each marked position. by the time we confirm a match, both directions have already been scanned - matches are reported retroactively rather than by restarting from each position. the llmatch algorithm section in the first post walks through this in detail.
one match or ten thousand, it's the same two passes. same example as before:
matching .*a|b against "bbbbbbbbbb" - finding all matches
traditional (find, advance, repeat):
resharp (two passes):
on patterns that produce many matches - log parsing, data extraction, search-and-replace across large files - the difference between O(n) and O(n²) is the difference between "instant" and "why is this taking so long".
the matches are still leftmost-longest (POSIX) - a|ab and ab|a give the same results, boolean algebra works, and you can refactor patterns without changing the output.
hardened mode
two passes eliminate the n restarts, but the forward pass itself still resolves one match at a time. pathological patterns with ambiguous match boundaries can cause quadratic work within that pass. i wanted a mode that guarantees linear time even on adversarial input, no exceptions - so i added a hardened mode to the engine.
hardened mode replaces the forward pass with an O(n * S) scan (where S is the number of simultaneously active DFA states) that resolves all match endings in a single pass, returning exactly the same leftmost-longest matches with no semantic tradeoff. on pathological input (.*a|b against a haystack of b's), the difference is dramatic:
| input size | normal | hardened | speedup w/ hardened |
|---|---|---|---|
| 1,000 | 0.7ms | 28us | 25x |
| 5,000 | 18ms | 146us | 123x |
| 10,000 | 73ms | 303us | 241x |
| 50,000 | 1.8s | 1.6ms | 1,125x |
normal mode goes quadratic; hardened stays linear. so why not make hardened the default? i went back and forth on this.
the quadratic blowup requires a pathological pattern and a structured input that's long enough to cause a problem - you need both halves. take a pattern like [A-Z][a-z]+ - every match starts at an uppercase letter and ends the moment the engine sees something that isn't lowercase. there's no ambiguity about where a match ends, so the engine never rescans the same input. for this pattern, the quadratic case is actually impossible. most real-world patterns share this property.
so imposing a 3-20x constant-factor slowdown on every query to protect against a case you're unlikely to hit by accident felt wrong.
but if patterns are user-supplied, the calculus changes completely - the attacker controls one half of the equation and the compile time as well. "you probably won't hit it" is exactly the kind of reasoning that leads to production incidents. in the end i kept the fast path as the default, mostly because the slowdown is real and measurable on every single query, while the pathological case requires a genuinely hostile combination.
there's also a practical reality: i'm trying to show that RE# is the fastest regex engine for common workloads. if the default path is 20% slower on common benchmarks, that's what people see - not the quadratic fix. i won't have it.
hardened mode is there for when you're accepting patterns from the internet and can't trust what you're getting - an explicit opt-in rather than a silent tax on everyone.
let re = Regex::with_options(
pattern,
EngineOptions::default().hardened(true)
)?;
the cost on normal text:
| pattern | normal | hardened | ratio |
|---|---|---|---|
[A-Z][a-z]+ |
2.2ms | 6.5ms | 3.0x slower |
[A-Za-z]{8,13} |
1.7ms | 7.6ms | 4.4x slower |
\w{3,8} |
2.6ms | 22ms | 8.7x slower |
\d+ |
1.3ms | 5.2ms | 3.9x slower |
[A-Z]{2,} |
0.7ms | 4.7ms | 6.7x slower |
patterns with lookarounds are currently rejected in hardened mode - there's no theoretical barrier, but the implementation needs some work.
vs Aho-Corasick
RE#'s hardened mode extends Aho-Corasick's approach to full regexes, where match lengths aren't known in advance. instead of a trie it holds a set of active match candidates, advancing all of them on each input character using derivatives. new candidates are only added at positions already confirmed as valid match beginnings by the reverse pass, so the engine never wastes work on positions that can't start a match. the result is the same property Aho-Corasick has always had, linear-time all-matches, but for regexes.
so how does RE#'s normal mode compare to Aho-Corasick on its home turf? here's a benchmark with a dictionary of 2663 words as a word1|word2|...|wordN alternation, matched against ~900KB of english prose - exactly the kind of workload Aho-Corasick was designed for. RE# just compiles it as a regular regex:
| benchmark | resharp | resharp (hardened) | rust/regex | aho-corasick |
|---|---|---|---|---|
| dictionary 2663 words (~15 matches) | 627 MiB/s | 163 MiB/s (3.85x) | 535 MiB/s (1.17x) | 155 MiB/s (4.05x) |
how is this possible when RE# is doing more work - two passes instead of one? it comes down to cache behavior. Aho-Corasick builds the full automaton upfront - for 2663 words that's a large DFA with many states and unpredictable jumps between them, leading to cache misses and branch mispredictions. rust regex uses a single lazily-compiled DFA, which helps, but the state space for a large alternation is still substantial. RE#'s derivative-based DFAs are lazily built and more compact - the two automata (forward and reverse) each have far fewer states than the equivalent full trie or NFA-based DFA, so transitions hit warm cache lines more often.
RE# hardened is doing unnecessary work here - as with [A-Z][a-z]+ above, this pattern has unambiguous match boundaries, so hardening adds nothing. this loss isn't inevitable - we can infer at compile time that hardening isn't needed for patterns like these, but there are higher priorities right now.
to be clear, for a smaller set of strings and a fully built automaton that fits comfortably in L1 cache, Aho-Corasick would be the right choice - it only needs one pass while RE# scans twice. the result above is specific to large patterns where cache pressure tips the balance.
skip acceleration
speaking of higher priorities - in the previous post i described how skip acceleration works and where RE# was losing to regex on literal-heavy patterns. since then i've been closing those gaps with hand-written AVX2 and NEON implementations - rare byte search, teddy multi-position matching, and range-based character class scanning.
these used to be significant losses - closing them was one of the more satisfying things to get working. i was also eager to see how RE# performs on rebar, BurntSushi's benchmark suite for regex engines:
| benchmark | resharp | rust/regex |
|---|---|---|
| literal, english | 34.8 GB/s | 33.7 GB/s |
| literal, case-insensitive english | 17.1 GB/s | 9.7 GB/s |
| literal, russian | 40.2 GB/s | 33.5 GB/s |
| literal, case-insensitive russian | 10.3 GB/s | 7.7 GB/s |
| literal, chinese | 22.4 GB/s | 44.0 GB/s |
| literal alternation, english | 12.2 GB/s | 12.5 GB/s |
| literal alternation, case-insensitive english | 4.9 GB/s | 2.5 GB/s |
| literal alternation, russian | 3.3 GB/s | 5.9 GB/s |
RE# does very well here now - most numbers are within noise threshold of regex. the few differences here and there come down to byte frequency tables and algorithmic choices in the skip loop. for context, a DFA by itself gets you somewhere near 1 GB/s - CPU vector intrinsics can opportunistically push that to 40+ on patterns where most of the input can be skipped.
streaming
"does RE# support streaming?" is a question i get asked a lot, and it's a good one. the short answer is:
- any pattern + leftmost-longest semantics = no. this isn't an engine limitation - it's inherent to the semantics. if you ask for the longest match on an infinite stream, the answer might be "keep going forever." you might think leftmost-greedy avoids this since it works left-to-right, but it doesn't -
.*a|bon a stream ofb's has the same problem, the.*abranch keeps scanning forward looking for the lastathat may never come. - pattern with an unambiguous end boundary = yes. some patterns already have unambiguous boundaries and work fine as-is. for the ones that don't, in RE# you can intersect with a boundary -
^.*$for lines,~(_*\n\n_*)for paragraphs (where~(...)is complement and_*matches any string), or any delimiter you want - and now the pattern is compatible with streaming. in the previous post i showed how you can intersect a regex with "valid utf-8", here, you can intersect with "up to the next newline" or "up to the end of the section", even if the original pattern is user-supplied and does not have this property. it is a nice and general technique. - any pattern + earliest semantics = yes. report a match the moment the DFA enters a match state, no need to scan further. this is what Hyperscan does - it works on streams because it never needs to look ahead.
the API doesn't expose a streaming interface yet - find_all takes &[u8] - but chunked streaming is on the list.
what RE# doesn't do
worth being upfront about the limitations:
no capture groups - RE# returns match boundaries only, not sub-group captures. this isn't impossible - captures are a post-match operation that can be layered on top. the reason is we haven't found the right way to do it yet. with intersection and complement, every subexpression would naively become a capture group -
(a.*&.*b)has two implicit groups, and complement creates more. in traditional regex,(?:...)exists to opt out of capturing, but the more i think about it the more?:feels like a historical mistake - it makes the default behavior (capturing) the one that opts you into a much slower algorithm, even when you don't need it. i'd rather get the design right than ship something awkward.in the meantime, you can use another engine to extract captures post-match - with
\Aanchors on the already-known match boundaries, the overhead isn't that bad.no lazy quantifiers -
.*?isn't supported. RE# uses leftmost-longest (POSIX) semantics, which is the mathematically unambiguous interpretation. lazy quantifiers are a backtracking concept that doesn't translate to this model.
capture groups may come eventually, but lazy quantifiers are a deliberate architectural choice. if you need captures today, use regex. if you need the properties RE# offers (boolean operators, lookarounds, true-linear all-matches, POSIX semantics), these limitations are unlikely to matter.
re
as a side note - to put RE#'s boolean operators to practical use, i built a grep tool called re. the main thing it adds over (rip)?grep is multi-term boolean search with scoping - require multiple patterns to co-occur on the same line, paragraph, or within N lines of each other:
# unsafe code with unwrap co-located within 5 lines
re --near 5 -a unsafe -a unwrap src/
# list all files both containing serde and async
re --scope file -a serde -a async -l src/
you can also use full RE# patterns - re '([0-9a-f]+)&(_*[0-9]_*)&(_*[a-f]_*)' src/ finds hex strings containing both a digit and a letter. you could do this with a pipeline of greps, but it's one pass with all the context information preserved.
wrapping up
i think i'll rest for a bit after this. i can only do 80-hour weeks for so long, and even though i have a lot more to share, it'll have to wait. there's also a paper that's been conditionally accepted at PLDI - i'll write about it properly once it's out. the rust RE# itself isn't quite ready for a formal 1.0 announcement yet, but we're getting closer.