{kind=link}
{kind=link}
Fans of vibecoding and agentic tools say they are 2x as productive, 10x as productive – maybe 100x as productive! Someone built an entire web browser from scratch. Amazing!
So, skeptics reasonably ask, where are all the apps? If AI users are becoming (let’s be conservative) merely 2x more productive, then where do we look to see 2x more software being produced? Such questions all start from the assumption that the world wants more software, so that if software has gotten cheaper to make then people will make more of it. So if you agree with that assumption, then where is the new software surplus, what we might call the “AI effect”?
We’ll look at PyPI, the central repository for Python packages. It’s large, public, and consistently measured, so we should expect to see some AI effect there.
Counting packages
There it is, see it? The release of ChatGPT. Does it look like an epochal revolution of software productivity on the upper chart? No.
There are a few spikes in the lower chart showing new packages/month, in what you might call the “AI era” of 2020 onward. But those reflect spam and malware floods, not genuine package creation.1
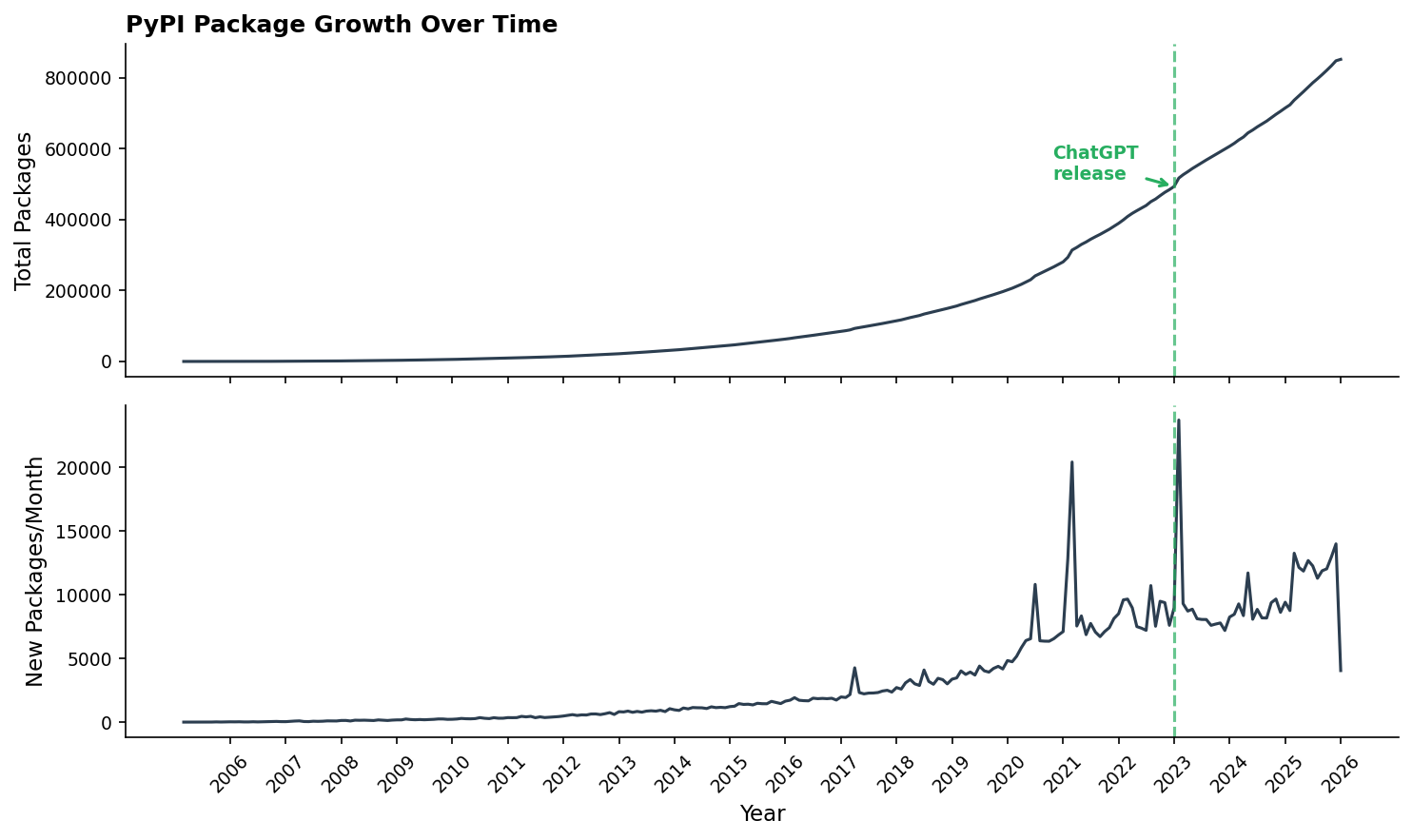
Two-panel chart showing PyPI total packages growing exponentially to 800k and new packages per month fluctuating around 5-15k, with ChatGPT release marked showing no obvious inflection point
This is curious. If AI is making software engineers more productive, why aren’t they producing more software?
Counting updates
But, you might say, package creation is not the right measure. Anyone can create and upload a “package” which is nothing but a hello world demo. This is always easier than creating something durable which people actually use. We want to look at “real” packages, packages which are actually downloaded, used, and maintained over time.
Okay, so let’s consider a different chart. We start by gathering the 15,000 most downloaded Python packages on PyPI in December 2025.2 Then we split the packages into cohorts based on their birth-year, and for each cohort we plot their median release frequency over time.3 This seems like a reasonable proxy measure of the production of real, actively-used software.
To show one cohort’s release frequency over time, we draw a line. So in the chart below, every line starts with a point showing the number of update releases within the first 12 months of the life of a package born in that year. The line proceeds as the package ages.
So what do we see? Do packages get updated more frequently after the advent of ChatGPT?
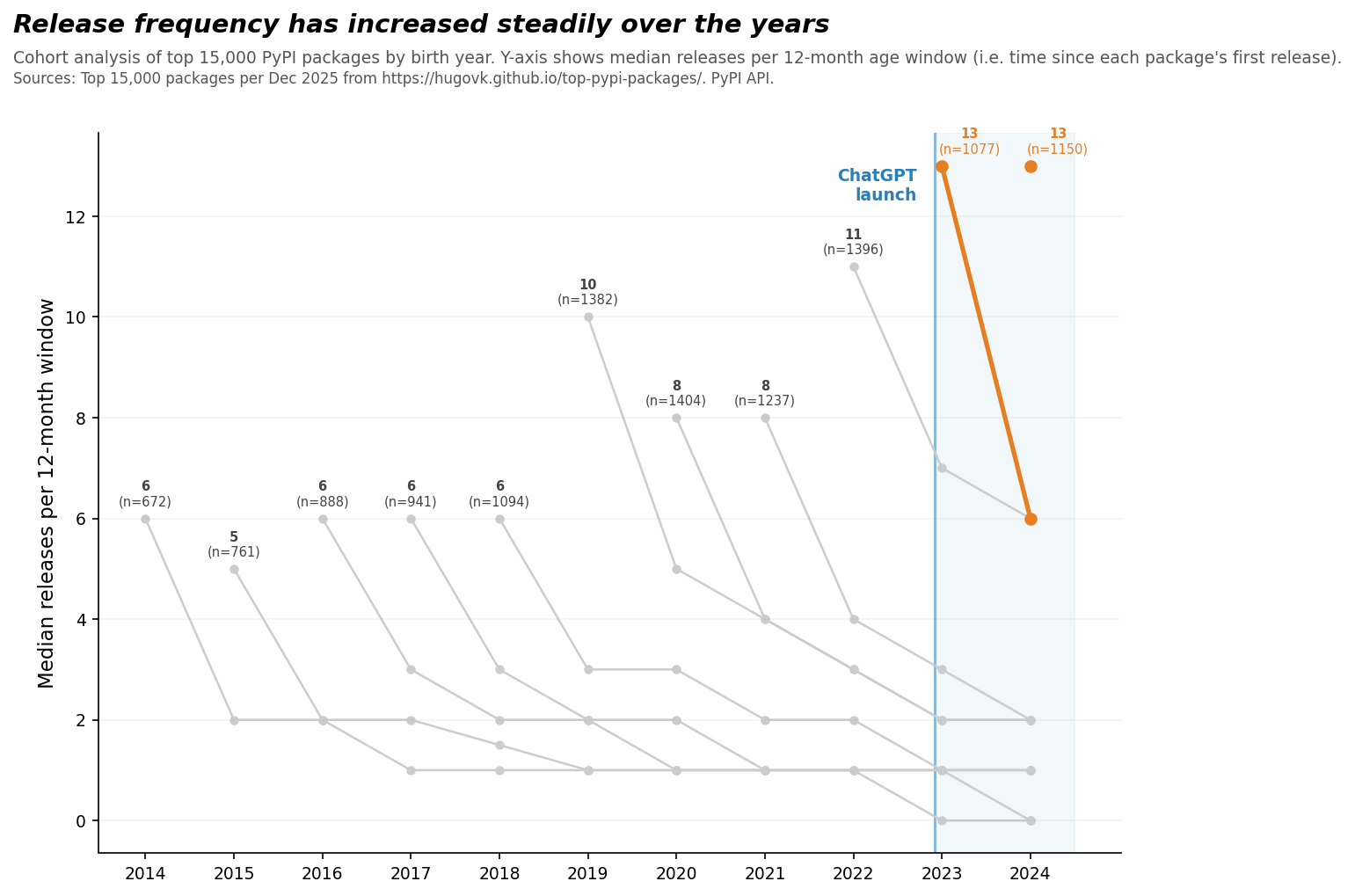
Well … sort of?
We clearly see that packages born after ChatGPT were updated more frequently within their first year (13 releases/year) than packages born back in 2014 (6 releases/year). This is seen in the fact that the cohort life lines start higher over time.
But this looks like it’s continuing a trend which starts too early to be attributed to an AI productivity boost. First-year release frequency started increasing in 2019 (at 10 releases/year), well before modern AI coding tools appeared. This seems just as likely to be due to growing adoption of continuous integration tools like GitHub Actions, which have been around longer.
Another reason to doubt this increase is entirely due to AI is the other effect visible in this chart, which is that packages are released less frequently as they get older. This is seen in the fact that all of the cohort life lines decrease over time. That has not changed. In other words, people are not using AI in a way that leads them to update a package more frequently as it ages.
It’s about AI
But surely some of that increase in initial release frequency is due to an AI boost? Let’s look deeper.
Let’s split packages by whether they’re about AI or not, by classifying based on the package’s description.4 There can we see an AI effect?
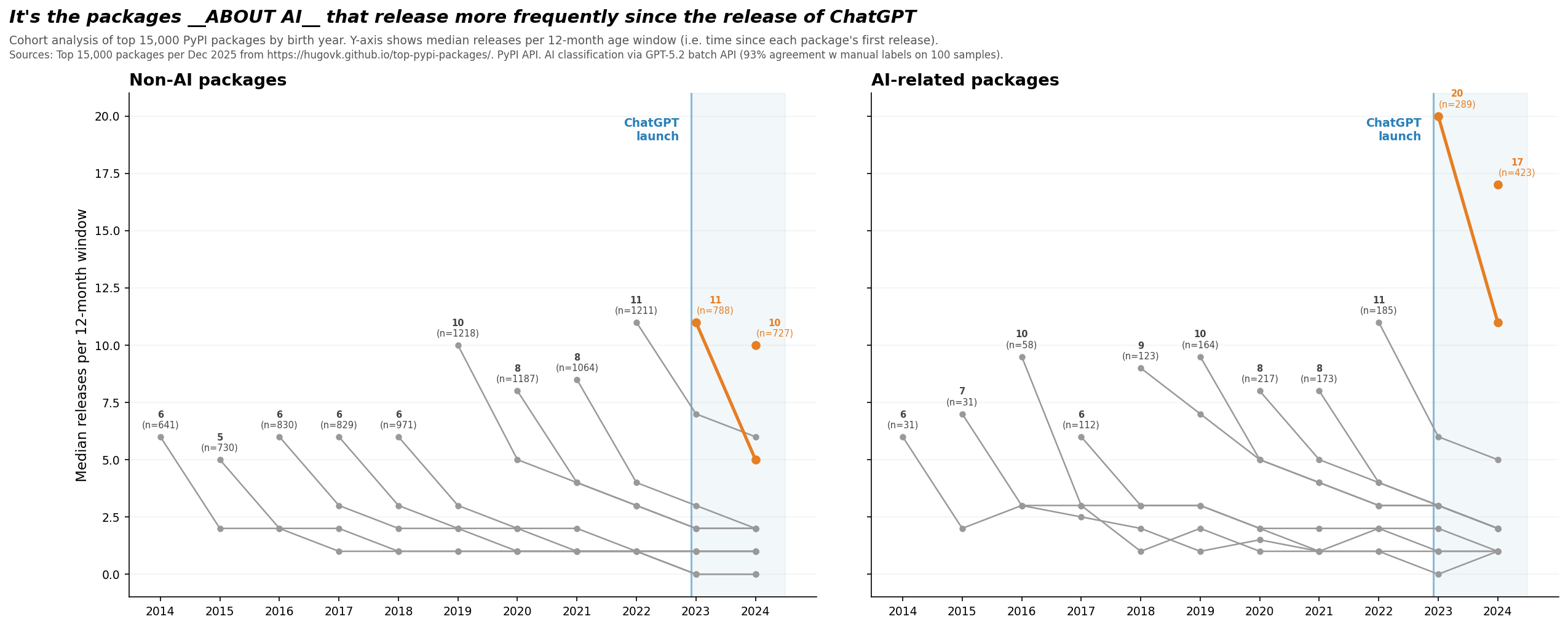
There it is! Or at least, there’s something!
Packages which are not about AI look much more like their pre-ChatGPT era cohorts, in that they show the same modest secular trend of increasing releases per year.
But in contrast, the packages which are about AI show a dramatic increase in release frequency. For example, the packages first-released in 2023 about AI reached a median of 20 releases in their first 12 months. Almost 2x their non-AI counterparts in the same year.
In short, for some reason, newly created packages about AI are being updated much more frequently.
Or is it about popularity?
Of course, AI is very popular right now. When we see that packages about AI are updated more frequently, are we merely observing that popular packages are updated more frequently?
To address that question, let’s do one more split. Let’s take our initial group of the top 15,000 packages by download in December 2025, and split it into two groups, the more popular 7,500 and the less popular 7,500.
Was our observation regarding packages “about AI” merely an observation regarding popularity?
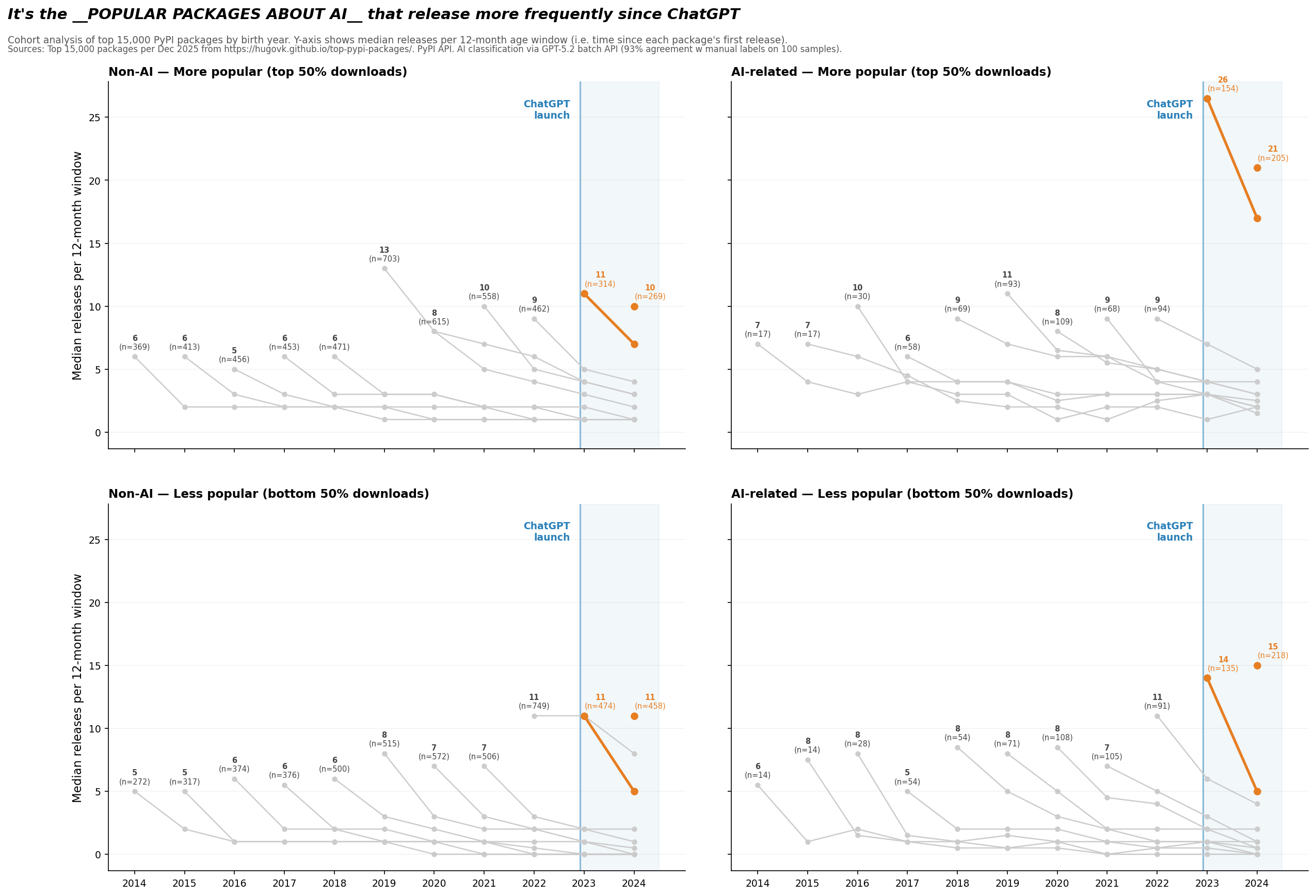
No. The top-right quadrant jumps out: popular AI packages jumped to 21-26 median releases per year post ChatGPT, more than double the ~10 that popular non-AI packages have held steady at (and also significantly more than the less popular AI packages).
So we do see a >2x effect in release frequency, and it’s concentrated in the most popular packages about AI specifically.
But of course the interesting question is, why?
So what?
Before considering what’s causing this, let’s recap the evidence:
There is no obvious increase in the rate of package creation as a whole, post-ChatGPT, and only a marginal increase in the rate of package updates as a whole.
There is a small, steady increase in update frequency over the years, but this trend predates ChatGPT.
There is a large (>2x) increase in update frequency for popular AI packages, and a smaller bump for less popular AI packages.
If we ask why we see this pattern of evidence, we discover that it’s actually adequate to let us conclude that some things are not happening, and to suggest some plausible interpretations for what is going on.5
Is AI massively boosting developer productivity across the board?
No. We are not seeing indications that developers as a whole are 100x or even 10x more productive. The bumper crop of new packages, or new package updates, just does not exist!
Relax. You are not missing a party that literally everyone else was invited to.
Are some developers building much faster, by using AI?
Perhaps? But the visible aggregate effect is still so modest, that if some devs are getting this big boost, there certainly aren’t many of them. Or else the purported boost is not really that big. What we see in aggregate is hardly any uptick in package update frequency.
However, we do see a boost in newly-created popular packages about AI.
Are people building an enormous amount of software for using AI?
Yes, yes they are. The jump in update frequency for recent packages about AI is really the headline effect here. The narrowness of this effect is the puzzle that needs to be explained.
So, let’s ask again, why? Why is this jump concentrated in software about AI? We do have two hypotheses:
AI “skill issue”. Maybe people building AI tools are also the ones most likely to know how to use AI effectively. This would produce a bigger productivity boost for AI packages. But if skill alone explained the jump, we’d expect it across all AI packages. Instead, the 2x2 chart shows it’s concentrated in the most popular ones, which suggests something else is also at play.
Money and hype 🤑💰. An enormous amount of funding and enthusiasm has flowed into AI, and it is being converted into (amongst other things) PyPI packages. Maybe it’s not that developers working on these packages have gotten more productive. It’s just that they work more, because there is more money to pay for that work. The cohort sizes in figure 3 illustrate this: the 2021 cohort has a non-AI to AI ratio of over 6:1 (1211 to 185). While the 2024 cohort ratio is under 2:1 (727 to 423)! On this view, it’s not so much that AI is making developers superhuman, but that supercharged interest in AI is paying for a higher rate of creation and iteration of packages about AI.
Alas, the data do not tell us which of these effects is larger.
But what we can say is that the main measurable impact of the generative AI revolution, so far, at least on the PyPI ecosystem, is not a Cambrian explosion in all software. But a sharp and concentrated burst in the updating of packages that are themselves part of the AI ecosystem.
Footnotes
See the official pypi blog: Inbound Malware Volume Report↩︎
This data was downloaded from hugovk’s monthly dump of 15,000 top-pypi-packages January 19th 2026.↩︎
We count releases in 12-month windows from each package’s first upload, not calendar years. This avoids having to annualize partial first-year figures. Non-final versions (alpha, beta, rc, dev, post) are excluded.↩︎
We used GPT5.2 to classify packages as “AI-related” or not based on their PyPI description. We agreed on 93% after labeling 100 packages ourselves. The classifications are imperfect but directionally useful.↩︎
All analysis code and data is available at https://github.com/AnswerDotAI/pypi-analysis.↩︎
{kind=link}