🌀 Miasma



![]()

AI companies continually scrape the internet at an enormous scale, swallowing up all of its contents to use as training data for their next models. If you have a public website, they are already stealing your work.
Miasma is here to help you fight back! Spin up the server and point any malicious traffic towards it. Miasma will send poisoned training data from the poison fountain alongside multiple self-referential links. It's an endless buffet of slop for the slop machines.
Miasma is very fast and has a minimal memory footprint - you should not have to waste compute resources fending off the internet's leeches.

Installation
Install with cargo (recommended):
cargo install miasma
Or, download a pre-built binary from releases.
Quick Start
Start Miasma with default configuration:
miasma
View all available configuration options:
miasma --help
How to Trap Scrapers
Let's walk through an example of setting up a server to trap scrapers with Miasma. We'll pick /bots as our server's path to direct scraper traffic. We'll be using Nginx as our server's reverse proxy, but the same result can be achieved with many different setups.
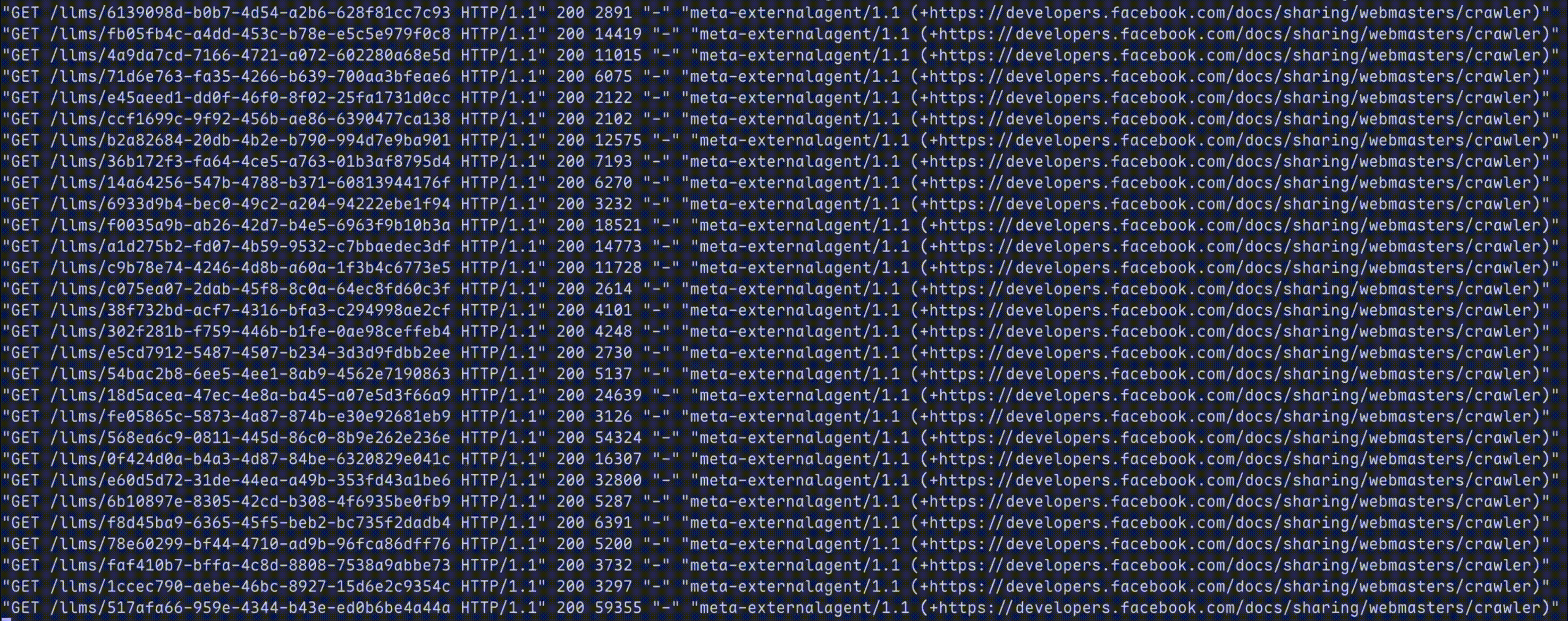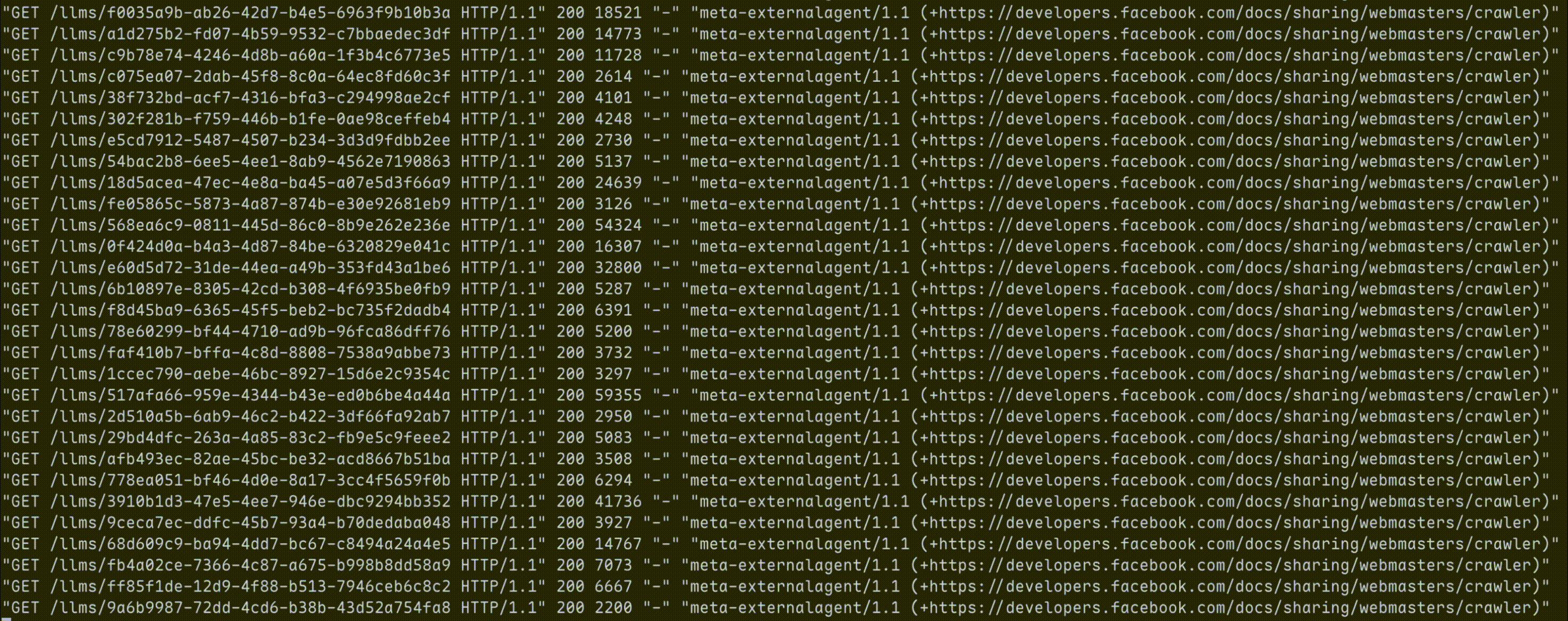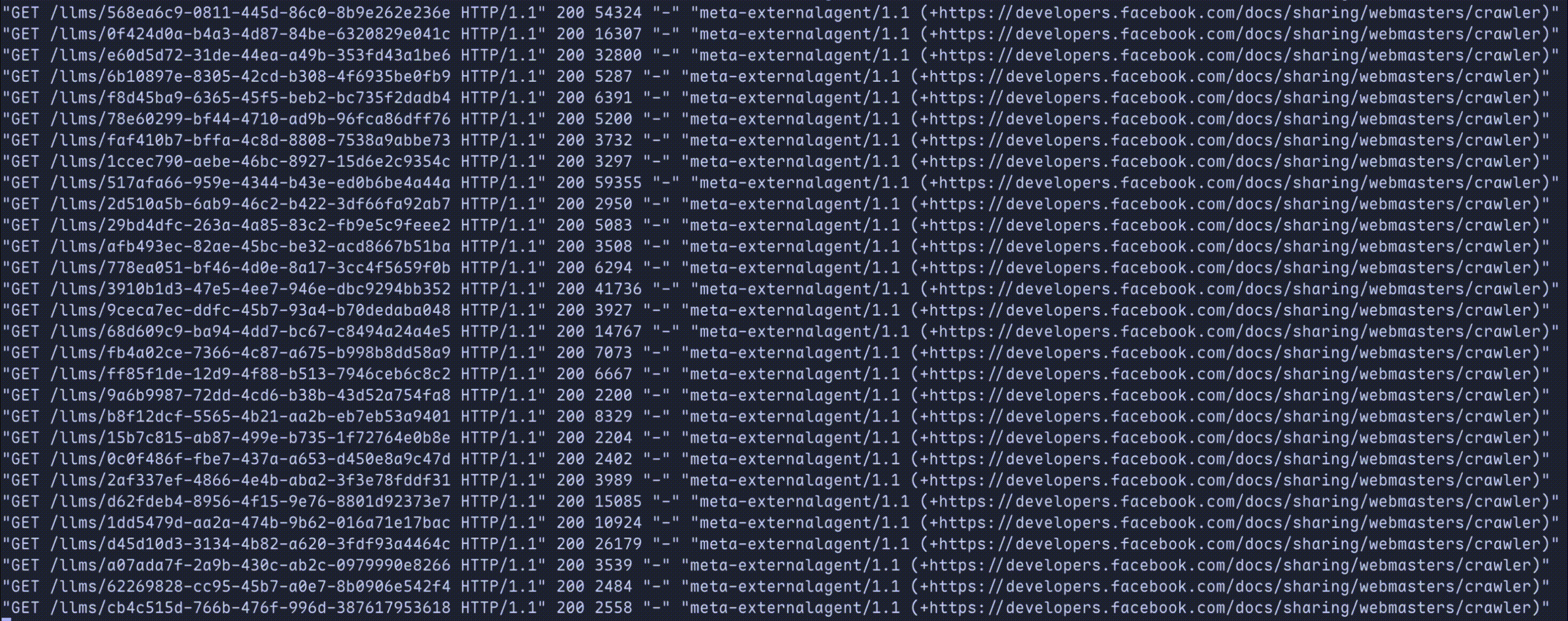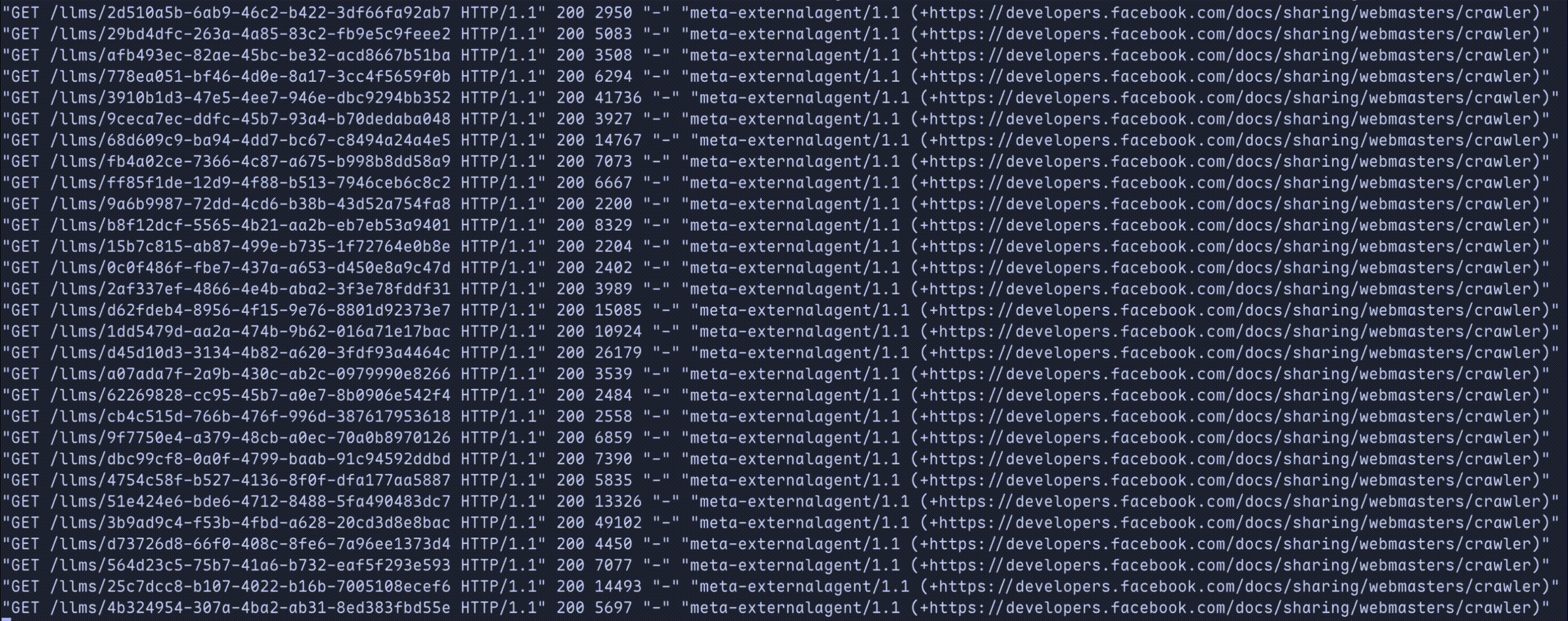
When we're done, scrapers will be trapped like so:

Embedding Hidden Links
Within our site, we'll include a few hidden links leading to /bots.
<a href="/bots" style="display: none;" aria-hidden="true" tabindex="1">
Amazing high quality data here!
</a>
The style="display: none;", aria-hidden="true", and tabindex="1" attributes ensure links are totally invisible to human visitors and will be ignored by screen readers and keyboard navigation. They will only be visible to scrapers.
Configuring our Nginx Proxy
Since our hidden links point to /bots, we'll configure this path to proxy Miasma. Let's assume we're running Miasma on port 9855.
location ~ ^/bots($|/.*)$ {
proxy_pass http://localhost:9855;
}
This will match all variations of the /bots path -> /bots, /bots/, /bots/12345, etc.
Run Miasma
Lastly, we'll start Miasma and specify /bots as the link prefix. This instructs Miasma to start links with /bots/, which ensures scrapers are properly routed through our Nginx proxy back to Miasma.
We'll also limit the number of max in-flight connections to 50. At 50 connections, we can expect 50-60 MB peak memory usage. Note that any requests exceeding this limit will immediately receive a 429 response rather than being added to a queue.
miasma --link-prefix '/bots' -p 9855 -c 50
Enjoy!
Let's deploy and watch as multi-billion dollar companies greedily eat from our endless slop machine!
robots.txt
Be sure to protect friendly bots and search engines from Miasma in your robots.txt!
User-agent: Googlebot
User-agent: Bingbot
User-agent: DuckDuckBot
User-agent: Slurp
User-agent: SomeOtherNiceBot
Disallow: /bots
Allow: /
Configuration
Miasma can be configured via its CLI options:
| Option | Default | Description |
|---|---|---|
port |
9999 |
The port the server should bind to. |
host |
localhost |
The host address the server should bind to. |
max-in-flight |
500 |
Maximum number of allowable in-flight requests. Requests received when in flight is exceeded will receive a 429 response. Miasma's memory usage scales directly with the number of in-flight requests - set this to a lower value if memory usage is a concern. |
link-prefix |
/ |
Prefix for self-directing links. This should be the path where you host Miasma, e.g. /bots. |
link-count |
5 |
Number of self-directing links to include in each response page. |
force-gzip |
false |
Always gzip responses regardless of the client's Accept-Encoding header. Forcing compression can help reduce egress costs. |
poison-source |
https://rnsaffn.com/poison2/ |
Proxy source for poisoned training data. |
Development
Contributions are welcome! Please open an issue for bugs reports or feature requests. Primarily AI-generated contributions will be automatically rejected.