I recently had to design a new reference data system for the manufacturing domain. During the initial design stages we brought up the idea of using the Clojure programming language. Even if at first I was skeptical on deviating from the standard development stack, I gradually realized the value of taking advantage of the multpile opportunities offered by this language.
This blog post is a high level take on the use of the Clojure programming language and its introduction into my development stack. I will present here the points that guided the decision to use it over more conventional languages like Java.
First, What-is Clojure ?
Clojure is a dynamic functional programming language that runs on the Java Virtual Machine and which is a member of the Lisp family ( yes you heard it right, the very old one )

As a result, Clojure not only benefits all the well-known advantages of functional programming languages such as immutable data structures ( which I will not describe in this article ) but it also provides all the advantages related to its Lisp nature, such as code-as-data semantic.
In addition, the Clojure ecosystem provides a wide range of powerfull libraries and tools for manipulating data which makes it very convenient for prototyping complex data validation and transformation programs.
Clojure language is not a newcomer, it was created in 2007, but has been considered for many years as a "hobbyist" language used in very specific cases only, although it was intially designed with the objective of being multi-purpose and stable for business usage.
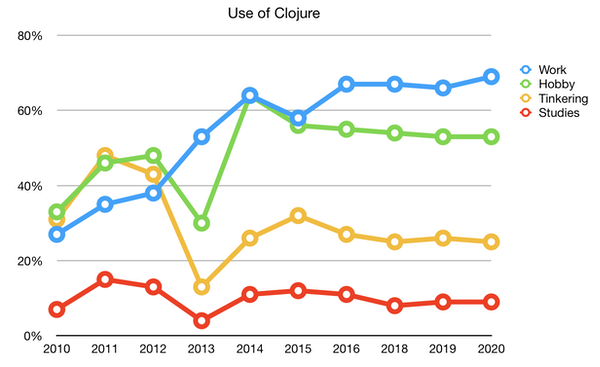
However reports tend to show a significant increase in the use of Clojure in enterprise in the recent years. I can mention the fact ThoughtWorks radar passed Clojure language to "adopted" since 2014, meaning Clojure position is an enterprise ready technology for quite a long time.
So why did I go for Clojure ?
A first element of decision lied in the fact that our product used a great number of data structures and business management rules which aim to evolve very frequently and be adapted to new business contexts over time.
So the idea came to use text descriptors a.k.a DSL ( Domain Specific Language ) to specify business logic instead of "hard-coded" pieces of code.
Thereby the use of conventional object oriented programming languages did not seem appropriate, while Clojure provided all the necessary features by design or using powerful libraries such as malli or specter.
On the other hand, I had to evaluate the complexity of some business-cases and demonstrate feasibility in the early stages of development. The Clojure-toolbox provided ways to ease data exploration, and allowed us to develop prototypes in a very short time while the use of alternative languages would have required a lot of boilerplate code.
Code as Data
The very first advantage of Clojure was bought by its nature of Lisp. Clojure uses a superset of EDN (Extensible Notation Format) which allows code declaration in a readfullness notation format.
(defn person-name
[person]
{:pre [(s/valid? :acct/person person)]
:post [(s/valid? string? %)]}
(str (:acct/first-name person) " " (:acct/last-name person)))
Thus, Clojure is well suited to creating rich DSLs that integrate seamlessly into the language. You may have heard Lisps boasting about code being data and data being code.
Many of the features of Lisp have made it into other languages, but Lisp's approach to code-as-data and its macro system still set it apart.
The software product I was working on required to implement a lighweight language to express business logic in a declarative way, like a rules-engine. This use-case has been achieved using a single Clojure variable.
(def business-logic
[:ruleset-group
[:ruleset1
[:when [:condition1][:condition2]]
[:then [:and [:action1][:action2][:action3]]]
[:ruleset2
[:when [:condition3] [:or [:condition4][:condition5]]]
[:then [:and [:action4][:action5][:action6]]]]]])
The ambition here was just to use a simple and concise data structures that can be easilly modified by non-developers and persisted in database. But Clojure provides features to implement way more complex DSLs using its macros system.
REPL (Read Eval Print Loop)
Another key feature that made me go for Clojure is its REPL environment (standing for Read-Eval-Print Loop) which enables the programmer to interact with a running program and modify it, by evaluating one code expression at a time.
REPL is a secret weapon for Lisp programmers and it is a tool that enables you to interactively contact with the program you write and evolve it rapidly. Discourses of REPL Driven Development never end in Clojure community and it has become quite popular. The reason for this is that you can productively and quickly write your code. The progresses such as finding a bug or adding/removing a feature can be easily carried out through quick feedbacks.
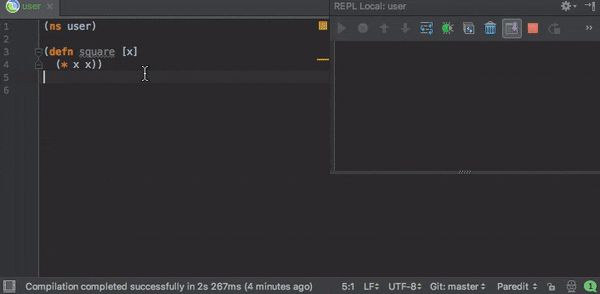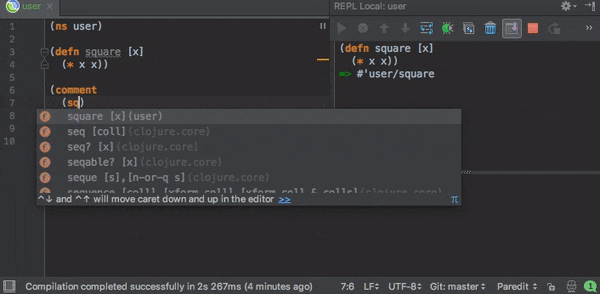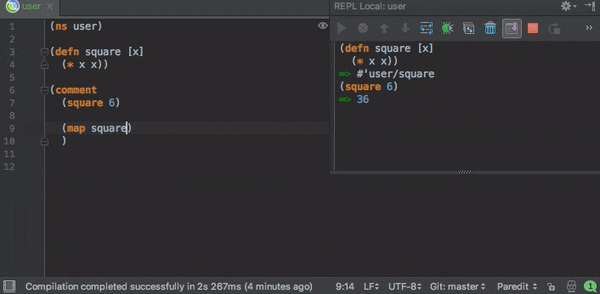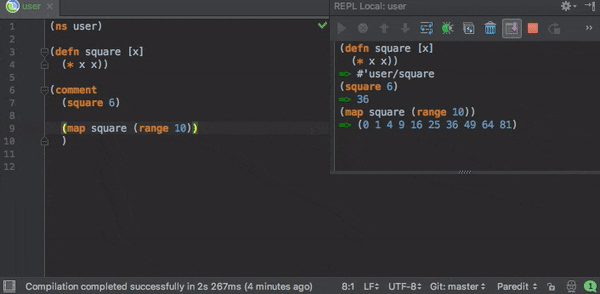
The ability to develop and test quickly in an iterative approach helped a lot during the initial exploration phase. Developers had the possibility to instantly experiment new code snippets during workshop sessions, and therefore to incredibly increase efficiency. As the Clojure docs says very well :
Many Clojure programmers consider the REPL, and the tight feedback loop it provides, to be the most compelling reason to use Clojure. This does not mean that the language features of Clojure, such as immutable data structures, are not valuable: the Clojure REPL gets most of its leverage because of these features, in particular because Clojure was designed with interactive development in mind.
In addition, the integration of REPL in IDEs plugins such as cursive or calva pushes this interactivity a step further, and allows on-demand execution of small portions of code or even single expressions.
Java Interoperability
As it was written on the JVM, Clojure gives access to all available Java libraries and their frameworks. So you can call Java code from Clojure code, or vice versa.
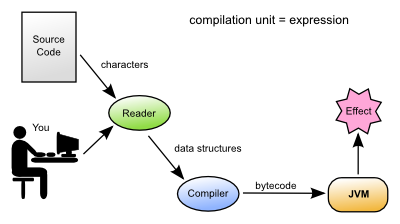
In my context this was a huge advantage, as it helped to integrate seamlessly Clojure with our standard development stack: Java/SpringBoot.
Nevertheless, despite the fact that the interop feature reduced the difficulty for us to on-board the Clojure world, a crucial decision to be made was the depth of use.
Several options were put on the table, knowing that the more complex features were used, the more the required level of experience grew. The challenge for me was therefore to find a good balance between short-term productivity, and mid-term risks around the management of the skill matrix of our development team.
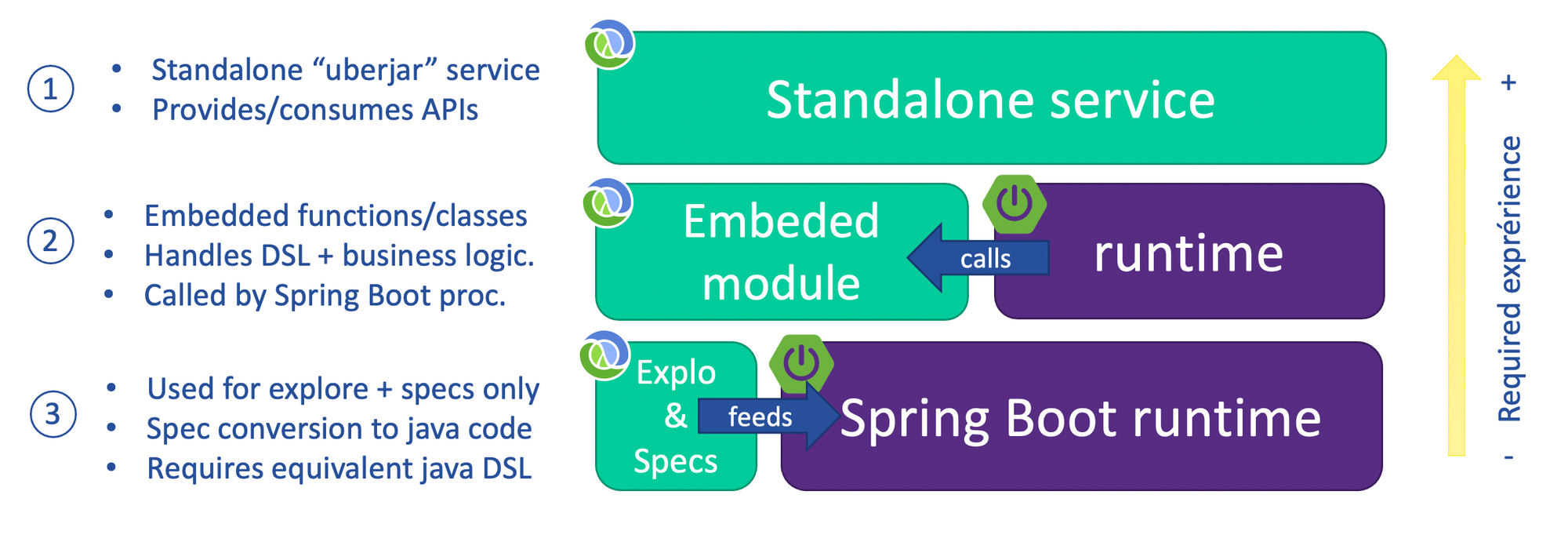
I finally decided to learn by walking, by first limiting use-cases to prototyping purposes, and then gradually integrating functions and modules into our product code.
In this way, we added with success several features directly taking advantage of code-as-data sematic and REPL, while limiting the overall complexity of our technical solution. Moreover this allowed the dev team to improve their knowledge of the Clojure programming language over time.
Other benefits to consider
See below a list of extra features that I considered for the future steps.
Macro system: allows the compiler to be extended by user code. Macros can be used to define syntactic constructs which would require primitives or built-in support in other languages. It fits well our custom DSL engine writing challenge.
ClojureScript: ClojureScript is a compiler for clojure that targets JavaScript. It generates code that can be executed on browser side. Thus, it allows to reduce the technological frontier between frontend and backend
Data-friendly Libraries: Clojure ecosystem provides a wide range of libraires such as ClojureSpec, Schema or Malli that would be interesting in our context.
Learning-Curve
When deciding how deep to go with Clojure, it is important to take staffing into consideration. Clojure's functional and data-oriented approach is antagonistic to a lot of more traditional programming wisdom. For teams with experience in object-oriented development only, the learning curve can be steep. The number of experienced Clojure developers on the market also is relatively small.
It will therefore be better to consider a very progressive rampup on this technology in order to gradually leverage the nice features listed above, one after another.
The man who removes a mountain begins by carrying away small stones.
In my personal case, this method turned out to be worth-it because it allowed my team to be effective from the very first moments of project lifecycle, and then to deepen technical use cases as they went along.
To date, I'm constantly re-evaluating the opportunities for exploiting Clojure in other parts of my software architecture, while taking care to improve and maintain a high level of competence in my development team.
Conclusion
To summarize, here is a synthesis of arguments that made Clojure a go-to option.
- It is a functional language, convenient to handle data and transformations.
- It is a LISP, well suited to write DSL by nature.
- It provides REPL for short-loop developement and testing.
- It has lots of powerfull data-driven schema libraries.
- It provides java interop to integrate seamlessly in enterprise standards.
That being said, one may serously considers to give it a try for new projects requiring rapid data-driven development.