WeakC4, or Distilling an Emergent Object
2swap

[
View the solution to Connect 4 here
](https://2swap.github.io/WeakC4/)
WeakC4 is a search-free, low-knowledge solution to 7x6 Connect 4, constructed by identifying a language which describes perfect play for a small subset of nodes, and then identifying a small opening tree which contains only those nodes as leaves.
This website provides a formal strategy for optimal first-player Connect Four play, which is fundamentally different from existing strong and weak solutions such as Fhourstones:
- It depends on so little information that it fits in about 150 kilobytes as shown, even before de-duplicating symmetric pairs.
- It uses no search during runtime, running at O(wh) time complexity to select a move.
- It can be visualized in its entirety and rendered in realtime.
- It visually illustrates and confirms the existence of particularly challenging openings, lines, and variations already known to connect 4 players.
Weak and Strong Solutions
This website shows a weak solution to the game of Connect Four. In short, this means that it provides sufficient information to guarantee a win for the first player if the first player plays in accordance with the weak solution's suggestions, but makes no comment on arbitrary positions. (If it did, that would make it a strong solution).
As a motivating example: player 1 (hereafter dubbed "Red") can win by playing in the center column on the first move and then following the weak solution's suggestions, but would not be guaranteed to win if the first disc is played elsewhere. The weak solution contains no information about what would happen in the other columns- As far as Red cares, it would be redundant to learn those branches, since they are not good.
A strong solution would contain a game-theoretic value for every position, whereas this weak solution only contains sufficient information to guarantee a win for Red, not including any other positions.
In graph-theoretic terms, we can think of these solution types as graphs, where the strong solution is the entire game tree, and a weak solution is a subgraph which is closed under a few important per-node constraints which will be discussed later.
Connect 4 is already strongly solved, and at first glance that seems to render discussion of weak solutions moot. In reality, I think the opposite is more generally true. A weak solution has a lot of advantages over a strong solution, such as:
- Smaller data footprint. You need to "memorize" less information to be able to play perfectly.
- Revealing underlying structure. A weak solution depends on, and exposes, a structural understanding of the game.
- Visualization. A weak solution can be visualized in a way that a strong solution (14tb uncompressed, 350gb compressed) cannot.
A strong solution is a general, naive approach to solving any game which does not demand structural understanding. A weak solution, up to the selection of which winning branches to include and which to omit, leaves room for creative choice and can be used to express structural insights of the game in question.
A "Good" Weak Solution
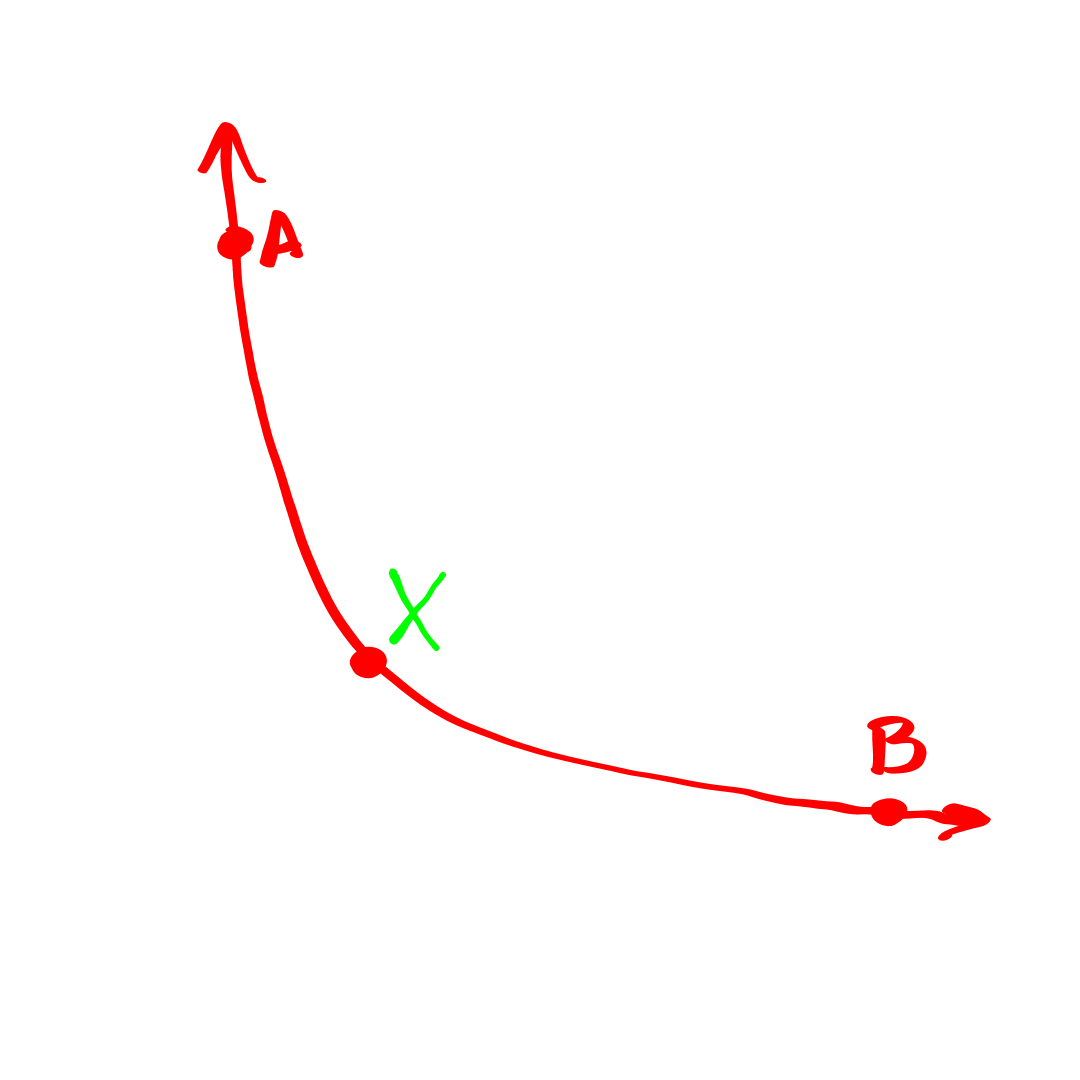
Imagine your goal is to go to a Chess tournament and play perfectly. One option, strategy A, would be to arrive without any preparation and read through every possible variation of play while seated. Another option, strategy B, would be to show up to the tournament already having memorized the game-theoretical value of each position, which would allow you to play perfectly without any search at all.
In some sense, these two approaches are opposites of each other. The first over-relies on computation with no dependence on knowledge, while the second over-relies on knowledge with no dependence on computation.
However, in another sense, they are very similar- in both cases, we can consider the 'data product' of the two strategies to be identical- regardless of when the value of a position is computed, before the tournament or during it, the player is required in the moment to arrive at the same quantity of information- the same tree, the same 'data product'. Both players would effectively construct the tree which results from alpha-beta-pruning, one would do so during the competition and one would do so before.
A more intelligent player would instead choose a strategy X which balances the two approaches. Insofar as the amount of knowledge required to memorize up to a certain depth increases exponentially, and the amount of computation required to read out an endgame increases exponentially as well, we can minimize both quantities via a strategy which involves memorizing halfway through the game, and relying on computation for the remainder. In other words, this player would reduce the total amount of data processed by optimizing the balance between memorization and compute.
A Great Weak Solution
So far, we have been treating the game tree, or 'data product' as a sort of infinitely entropic object which is only approachable formally through naive search. In reality, there is plenty of room for the application of human intuition and heuristic analysis, which is evidence that this game tree is informationally redundant- it has some sort of structure to it, and thus it can be compressed. This should not come as a surprise- insofar as it was generated in correspondence with a consistent set of rules, (the rules of the game itself), it should be expected to exhibit some degree of self-similarity.
It was a design goal of this project to not rely on realtime compute whatsoever because I hoped to visualize a solution in full. The existence of a compute step implicitly hides information which exists within our solution, and therefore we would not be faithfully visualizing the entire game tree.
If we're clever, we can eliminate the compute step entirely.
Nothing in life comes free. In simple terms, what this meant was a need for a much deeper upfront computation to intelligently choose what branches to suggest for memorization, because it turns out that some sparse branches in this enormous game tree yield entirely regular and patterned continuations- continuations which have a "simple trick" demanding neither computation nor memorization.
Here's a motivating puzzle to demonstrate the technical challenge underlying this upfront computation:
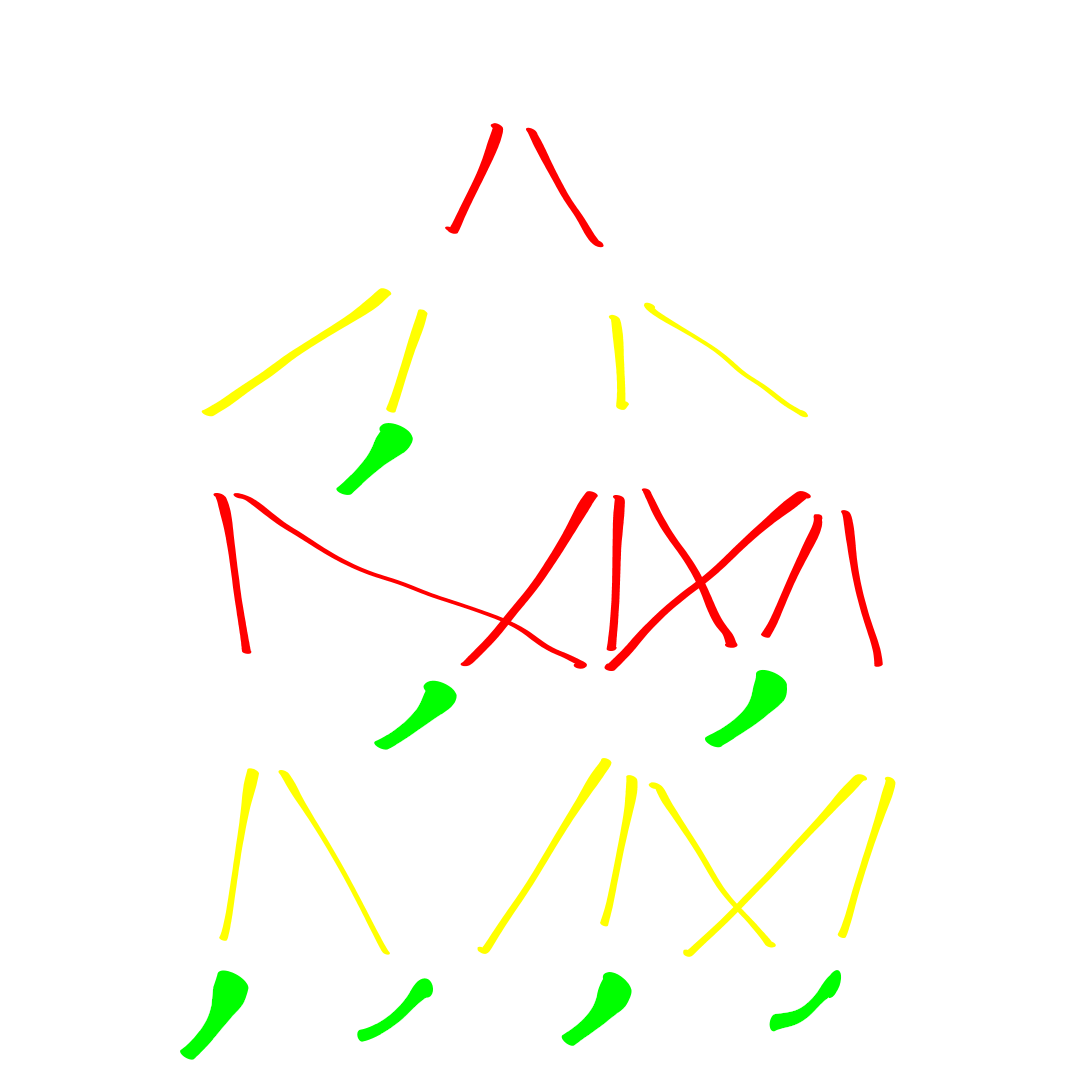
This is a directed game tree, where Red's moves are shown in Red, and Yellow's are shown in Yellow. Nodes which have a "simple trick" are crossed with green, and have been drawn as leaf nodes.
Try to identify the smallest possible subtree which serves as a weak solution on behalf of Red for this game. In other words, your job is to remove Red edges so that every remaining red-to-move node maintains exactly one outgoing red edge, without trimming any yellow edges. Click on the image to reveal the answer.
The fundamental challenge of this project was then twofold:
- To find a language which expresses "simple tricks" for a sufficiently large critical-mass of nodes in the game tree, and
- To find an "opening book" tree for memorization, whose leaf nodes all have such "simple tricks".
I think it is worth reflecting on the fact that this approach isn't merely a "strategy" for perfect connect 4 play, but more importantly an exercise in actually understanding the shape of the game tree of this complex patterned structure which emerges from the rules of Connect 4. How could you identify clever tricks, or languages to describe them, or a small tree whose leaves all contain those clever tricks, without having an understanding of the game's intrinsic form? More on this in the "Reflections" section.
Minimum Weak Solutions
There is a subtlety here which needs to be addressed. The puzzle above requests a minimum weak solution. However, this project does not search for a minimum-size graph but rather a graph which requires less information to be expressed. In the same way that a repetitive text file can be compressed, we abuse the fact that the game tree involves informational redundancy to reduce the size of the graph and come up with a solution which is not graph-theoretically small, but rather information-theoretically small.
Claimeven
Before I define the entire language for expressing these "simple tricks", let me provide a motivating connect 4 position. It's Yellow's turn, but Red already has a simple trick in mind. Can you find it?

The trick is for Red to merely play call-and-response with Yellow, playing in the same column as Yellow's last move. If Red does this, Red will win in the center column after a few dozen turns. We can visualize the final game board, regardless of how Yellow continues:

Notice how the puzzle's position only had a single column with an odd number of empty spaces remaining, and that was the row that Red needed to win on. All of the other columns had an even number of remaining spaces. This is important to notice, because if several columns had an odd number of spaces, then Yellow could intentionally fill one of them up, and Red would be forced to make a move, breaking the call-and-response pattern.
As this strategy involves Red filling rows 2, 4, and 6, this strategy was dubbed Claimeven by Victor Allis in his paper A Knowledge-based Approach of Connect-Four.
Unfortunately, there are not sufficiently many positions in Connect 4 which can be solved with pure Claimeven alone, so we need to generalize a bit further.
Steady-State Language
The language I chose to express these "simple tricks" uses a "Steady State Diagram", which looks like this:

This should be thought of as a "cheat sheet" which tells Red how to continue playing until winning, for the position drawn in the picture. The diagram features annotations on top of the grid squares which are to be used by Red to determine what to do next. As Red plays, the diagram does not change.
To determine what Red should do, we look at all of the legal moves which Red can make right now. We completely disregard "floating" annotations.
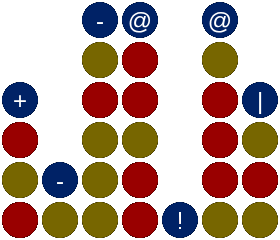
Red's chosen move is selected by following this list of ordered priorities:
- Make a winning move, if available.
- Block an opponent winning move, if available.
- Play on an ! (pronounced as 'urgent'), if available.
- Play on a @ (pronounced as 'miai'), only if there is exactly one available.
- Play on a | (pronounced as 'claimodd') only if it is on an odd row (otherwise ignore it), or a blank-space cell (pronounced 'claimeven') only if it is on an even row. Note that claimeven is represented with a blank space because it shows up a lot, so it is good to think of claimeven as a sort of 'default behavior'.
- Play on a +, if available.
- Play on an =, if available.
- Play on a -.
In creation of these diagrams, I provide the guarantee that there is always precisely one unique move suggested by this priority list. In other words, among the diagrams featured on my site, you will never find one where two urgents are available. This corresponds to the earlier qualification that a red-to-move node has exactly one outgoing edge.
I won't discuss all the design decisions that guided me to use this specific language. To gain some intuition, I suggest you view the graph and explore some steady state diagrams yourself.
I also don't make the claim that it is perfect, or optimal, or anything of the like. I converged on this design primarily through lots of trial and error. There are also a bunch of positions considered simple by Connect 4 experts which do not have a Steady State Diagram- chiefly among them positions which use the "triple-odds" strategy. Triple-odds requires a bit of global knowledge, which my Steady State language is too simple to express. I suspect the graph could be shrunk by a factor of 4 or so if a language was found which can simply express triple-odds.
Take a moment to consider that there is a trade between complexity and expressiveness of the Steady State language and graph size. I chose the best balance I could manage. If you have a better idea, I encourage you to try it :)
Technical Approach
Briefly, here's a description of the rest of the technical approach which permitted me to generate the graph:
- A genetic algorithm was used to quickly predict candidate Steady States for a given graph, later verified by brute force. [Code]
- I used all sorts of methods to select the best branches which are trimmed as much as possible. This involved a lot of search and backtracking, but realistically I wasn't able to search for minimal branches at a depth any higher than about 8 [Code]. Finding the best branches in the opening involved lots of trial and error, some of my own intuition as a Connect 4 player, and soliciting suggestions for node-pruning from other players. Of course, I do not guarantee optimality of this graph. I expect it can probably be compressed by another 25 percent or so, without any modification to the Steady State language.
- Force-directed graph spreading was used to generate the graph visualization, appropriately spread-out in 3d-space. [Code]. Mirror forces were applied to guide the graph to reflect the mirror structure of the game.
Results
We have developed a search-free, low-knowledge solution to connect 4 by identifying a language which describes perfect play for a small subset of nodes, and then selecting a small opening tree which contains only those nodes as leaves.
The resulting solution has the following properties:
- It uses no search during runtime, running at O(wh) time complexity to select a move at any valid position.
- It has been reduced to a total of under 10,000 nodes (subject to further reduction, see the graph page for a live count.) About two-thirds of these nodes are leaves representing steady states.
- It depends on so little information that it fits in about 150 kilobytes, even including mirrored positions.
- This level of compression can be compared to Allis (1988), who found an opening book of 500,000 nodes which permitted real-time play, but still invoked search.
- Traversing this tree and confirming its validity runs slightly faster on my machine than solving the game directly with Fhourstones, in some sense implying that this is the fastest "proof-by-compute" of the claim that connect 4 is a player-1-to-win game. This is even the case without any clever proof-of-correctness of steady-states which I have yet to implement- we are just brute-force checking them.
- Both of these metrics could further be reduced by about half, as they included search and storage of mirror positions.
- Sooner or later, I will make an Anki opening deck using the discovered branches, so that humans who wish to attempt memorization can do so.
- It can be visualized in its entirety and rendered in realtime.
- It visually illustrates and confirms the existence of particularly challenging openings, lines, and variations already known to connect 4 players.
All other connect 4 solutions currently available have a sort of "queryable" interface, where the user prompts the solver with a position, and the solver returns a game-theoretical value. Instead, by distilling our solution into a small data structure, we can map out the game in space for intuitive visual exploration.
An Anki deck was made from the non-leaf trunk of the graph, for the sake of human opening memorization!
Reflections
The game tree of Connect 4 is an emergent object which arises from a set of simple rules. This is similar to a lot of other structures which we interface with. Physics is likely of the same nature, in which a rather simple set of equations at the quantum level yield a myriad of unexpected macroscopic phenomena such as doorknobs and opposable thumbs. Through the iteration of computational rules, different phenomena come to life at different resolutions of observation.
And I think that's kind of an important point- resolutions. These structures usually have a "stack" of phenomena which emerge at different levels of resolution. In physics, we see organisms composed of cells composed of molecules composed of atoms, each behaving in a way best described by its associated field of study. Compare this to our minimal expression of Connect 4's winning strategy, exhibiting different form at different levels. In the endgame, there are these simple tricks which depend on a patterned, regular structure of the continuation tree, but abstracted further back towards the opening, emergent macrostructures grow into recognizable variations and named, known openings. Of course, this was by design, but I suspect it is a necessary design choice to achieve the desired result of expressing the object's form in as little data as possible.
A pessimistic physicist with a reductionist attitude might say that reality is merely composed of particulate phenomena, and that the segmentable, nameable macroscopic world is an illusion, or a construction of human invention. However, this physicist falls into the same philosophical trap of the Chess competitors following naive strategies A and B, dismissive of a knowledge-based mode of understanding via pattern recognition, instead deferring to raw mechanics.
Connect 4 is in a rather magical place in terms of complexity. It is ripe with emergent objects, and yet it is simple enough to visualize and formally reason about computationally. I am unaware of any other attempts to make a low-information weak solution to Connect 4 which forego search, so my sample size is one, but it seems to me that this sort of compression depends on a multi-resolutional approach, effectively contradicting the philosophy of the reductionist physicist as a viable means of approaching arbitrary emergent objects.
I hope the reader can appreciate this endeavor not merely as a strategy for the game of Connect 4, but more importantly as a formal exercise in extracting understanding from an emergent object- a problem neglected by traditional computational approaches to solving board games.
Credits
Both Fhourstones by John Tromp and Pascal Pons's online Strong Connect 4 Solver were used for positional analysis in constructing the graph, the former for search algorithms and the latter for human analysis. Creating this would have been much more painful without those tools.
If you find a branch that you think is inefficient, let me know! Here are some people who have already suggested branches resulting in a reduction of nodes in the graph:
- CTL560 is a monster at finding steady states by hand.
- Radiant
- Nod
- IAMHER0BRINE
- Fireball