Is security spending more tokens than your attacker?
Last week we learned about Anthropic’s Mythos, a new LLM so “strikingly capable at computer security tasks” that Anthropic didn’t release it publicly. Instead, only critical software makers have been granted access, providing them time to harden their systems.
We quickly blew through our standard stages of processing big AI claims: shock, existential fear, hype, skepticism, criticism, and (finally) moving onto the next thing. I encouraged people to take a wait-and-see approach, as security capabilities are tailor-made for impressive demos. Finding exploits is a clearly defined, verifiable search problem. You’re not building a complex system, but poking at one that exists. A problem well suited to throwing millions of tokens at.
Yesterday, the first 3rd party analysis landed, from the AI Security Institute (AISI), largely supporting Anthropic’s claims. Mythos is really good, “a step up over previous frontier models in a landscape where cyber performance was already rapidly improving.”
The entire report is worth reading, but I want to focus on the following chart, detailing the ability of different models to successfully complete a simulated, complex corporate network attack:
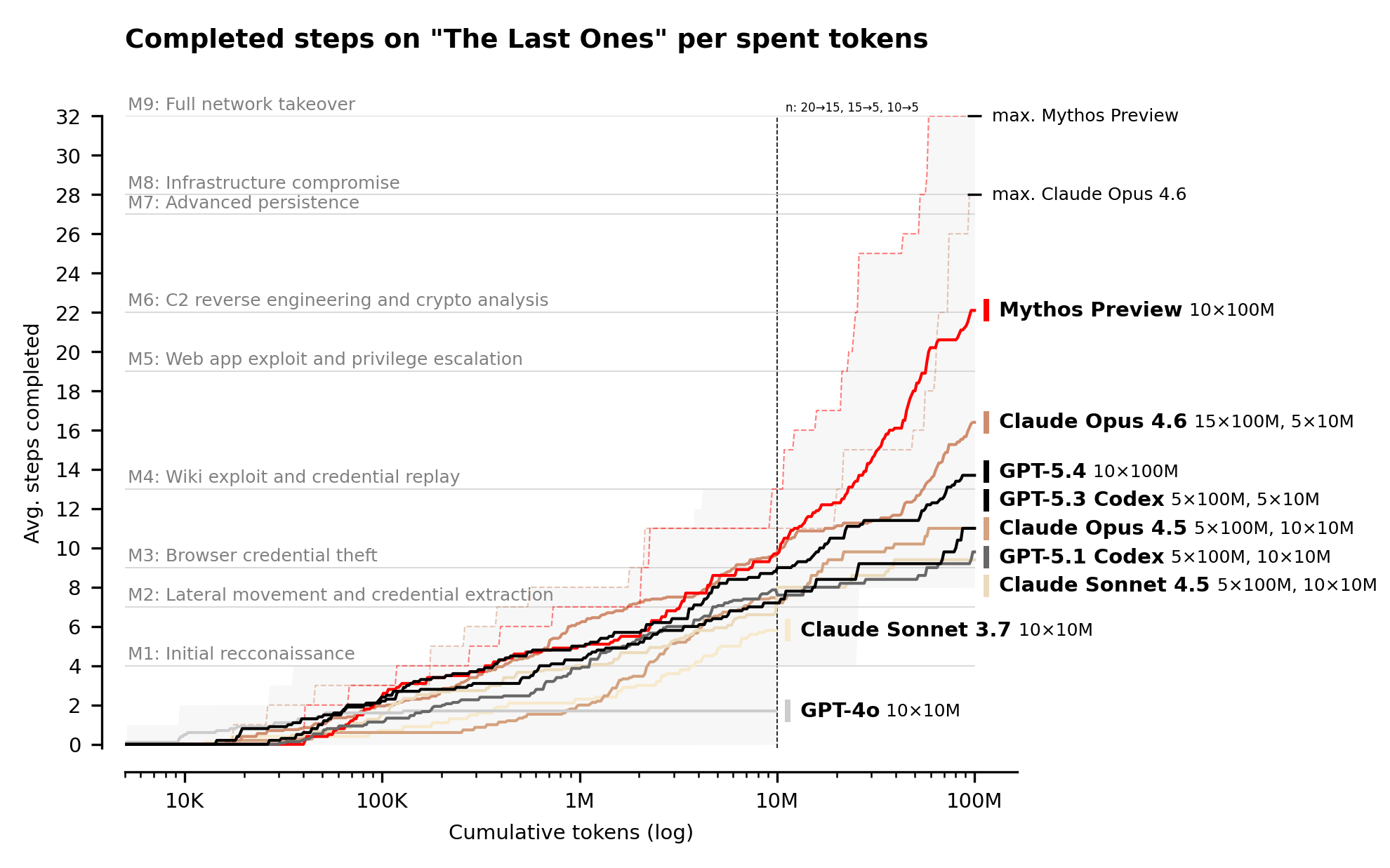
“The Last Ones” is, “a 32-step corporate network attack simulation spanning initial reconnaissance through to full network takeover, which AISI estimates to require humans 20 hours to complete.” The lines are the average performance across multiple runs (10 runs for Mythos, Opus 4.6, and GPT-5.4), with the “max” lines representing the best of each batch. Mythos was the only model to complete the task, in 3 out of its 10 attempts.
This chart suggests an interesting security economy: to harden a system we need to spend more tokens discovering exploits than attackers spend exploiting them.
AISI budgeted 100M tokens for each attempt. That’s $12,500 per Mythos attempt, $125k for all ten runs. Worryingly, none of the models given a 100M budget showed signs of diminishing returns. “Models continue making progress with increased token budgets across the token budgets tested,” AISI notes.
If Mythos continues to find exploits so long as you keep throwing money at it, security is reduced to a brutally simple equation: to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them.
You don’t get points for being clever. You win by paying more. It is a system that echoes cryptocurrency’s proof of work system, where success is tied to raw computational work. It’s a low temperature lottery: buy the tokens, maybe you find an exploit. Hopefully you keep trying longer than your attackers.
This calculus has a few immediate takeaways:
First, open source software remains critically important.
For those of you who aren’t exposed to AI maximalists, this statement feels absurd. But lately, after the LiteLLM and Axios supply chain scares, many have argued for reimplementing dependency functionality using coding agents.
Here’s Karpathy, just a few weeks ago:
Classical software engineering would have you believe that dependencies are good (we’re building pyramids from bricks), but imo this has to be re-evaluated, and it’s why I’ve been so growingly averse to them, preferring to use LLMs to “yoink” functionality when it’s simple enough and possible.
If security is purely a matter of throwing tokens at a system, Linus’s law that, “given enough eyeballs, all bugs are shallow,” expands to include tokens. If corporations that rely on OSS libraries spend to secure them with tokens, it’s likely going to be more secure than your budget allows. Certainly, this has complexities: cracking a widely used OSS package is inherently more valuable than hacking a one-off implementation, which incentivizes attackers to spend more on OSS targets.
Second, hardening will be an additional phase for agentic coders.
We’ve already been seeing developers break their process into two steps, development and code review, often using different models for each phase. As this matures, we’re seeing purpose-built tooling meeting this pattern. Anthropic launched a code review product that costs $15-20 per review.
If the above Mythos claims hold, I suspect we’ll see a three phase cycle: development, review, and hardening.
- Development: Implement features, iterate quickly, guided by human intuition and user feedback.
- Review: Document, refactor, and other gardening tasks, async, applying best practices with each PR.
- Hardening: Identify exploits, autonomously, until the budget runs out.
Critically, human input is the limiter for the first phase and money is the limiter for the last. This quality inherently makes them separate stages (why spend to harden before you have something?). Previously, security audits were rare, discrete, and inconsistent. Now we can apply them constantly, within an optimal (we hope!) budget.
Code remains cheap, unless it needs to be secure. Even if costs go down as inference optimizations, unless models reach the point of diminishing security returns, you still need to buy more tokens than attackers do. The cost is fixed by the market value of an exploit.