
Brooklyn, New York. March 2026.
I decided to move to Brooklyn for a coding retreat.
There were some personal reasons that brought me back to the US. But rather than heading immediately back to work, I wanted to take some time to focus on coding things mostly without AI — at precisely the time when many successful programmers are saying programming is a solved problem.
Given that I’m now six weeks through this retreat, I’ll also take some time to explain what I’ve been doing in that time.
For the past two years, I’ve been building AI agents at Aily Labs in Barcelona alongside some super talented engineers. One of my first projects was building a web search agent we could use internally in early 2024… almost 6 months before Anthropic’s Building Effective AI Agents article came out and a year before OpenAI’s DeepResearch came out! We were also early on Cursor, early on using LLMs to make knowledge graphs, and constantly testing out new approaches for our use cases.
One of my favorite parts of working at Aily was leading a weekly journal club. I chose to present papers that described how open source LLMs were built, including DeepSeek R1, Ai2’s Olmo 3, and Meta’s Llama 3 paper. All of these helped us understand the evolving tradeoffs between training models internally or building workflows around SOTA closed models. I was already hooked on LLMs since the first time I tried them in 2023,1 but I found my curiosity kept bringing me back to learning about how they worked and how to apply them.
At the same time as I was learning about LLMs and agents, I was also using them to code. I learned that when writing code “by hand” I was actually doing two things: writing what I wanted and learning the code base. When I used a coding agent however, I would get exactly what I specified in my prompt, for better or worse. By this I mean that if I didn’t know what I wanted exactly, coding agents would be happy to make many assumptions for me. This almost always meant that I didn’t learn as much, and that I wouldn’t have a good grasp of the codebase.
At the exact same time, coding agents helped me iterate quickly and ship software that worked well (after some dutiful testing, of course). They were also, I found, excellent tutors.
Cal Newport, a computer science professor and writer of Deep Work and other popular productivity books, recently wrote about this tradeoff in a way that resonated with me. In the article, he makes an analogy between the relationship of exercise to health, and the relationship of thinking to craft:
Your writing should be your own. The strain required to craft a clear memo or report is the mental equivalent of a gym workout by an athlete; it’s not an annoyance to be eliminated but a key element of your craft.
I think the same applies to writing code. At Aily, the people I worked with who were amazing programmers were in most cases also amazing users of AI. Their deeper knowledge simply gave them more leverage over this tool. In the day to day of shipping agents into production, I didn’t stop learning. But I did have a growing list of coding and computer concepts that I was always too busy to learn about.
So when I needed to head back to the US, I realized it was the perfect time to focus on this at the Recurse Center.
Recurse Center (RC) is a self-directed, full-time programming retreat in Brooklyn. After an application and a coding interview, Recursers arrive with ideas for what they want to program, and then spend 6 or 12 weeks programming. One of the highlights of RC is that it is collaborative: you enter with a cohort of other programmers, many with decades of experience, and with radically different expertises. Another highlight: it’s free!
Coming into RC, my goals were the following:
Train an LLM from scratch. This includes pre- and post-training, and I want to do this mostly from scratch; not just fork a premade codebase but write a Transformer myself.
Get better at writing Python by hand. I’ve been working in Python for a few years now but I know there’s still so much for me to learn. I want to get to the point where I need to reference documentation or ask LLMs as little as possible, and have good intuition for how to set up various projects.
Understand computers better. Admittedly a broad goal, I know that computers are extremely complicated machines that operate at many levels of abstraction. Given that I never had a formal Computer Science education I want to build a better mental model of these layers and how they work together. I don’t have a super concrete plan here, but I think RC will be the perfect place for this.
So how is it going?
I’ve done the first assignment from Stanford’s CS336: Language Modeling from Scratch course, without coding help from an LLM.2 For context, it was a 50-page assignment, but working with another Recurser, we wrote an optimized tokenizer in Python, and then built out an upgraded GPT-2 style architecture in PyTorch. We ran multiple ablations to tune hyperparameters on the Tiny Stories datasets, and then used those hyperparameters on the ~9 billion tokens of the OpenWebText dataset.
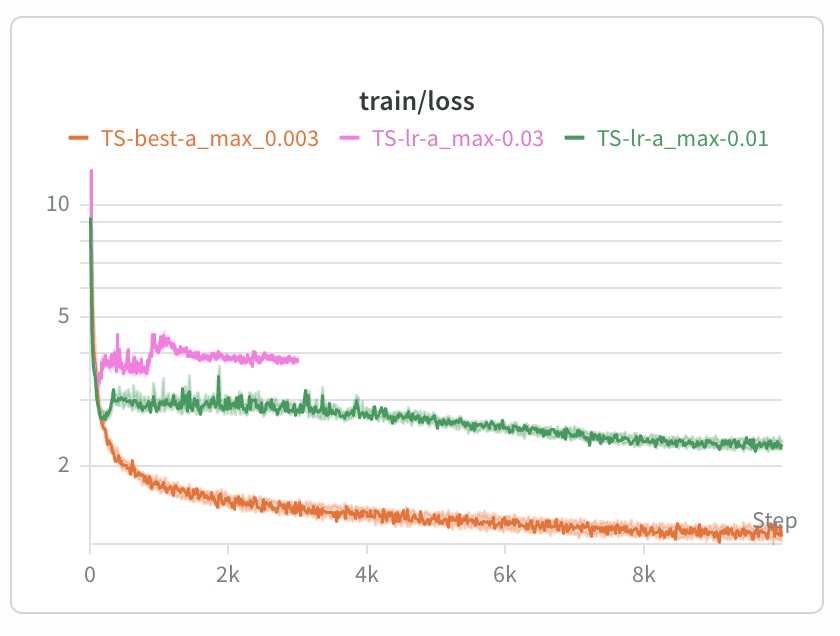
Parameter sweep of different learning rates for the 17M parameter model we wrote by hand; high learning rates lead to instability. This was on the Tiny Stories dataset, and took about an hour to train on an A100.
My plan is to do the other assignments in CS336 as well: optimizing our language model, estimating and computing scaling laws, converting raw text data into pre-training data, and finally post-training a model. I’ve already started the second assignment which involves profiling GPUs and implementing FlashAttention2 in Triton. There’s a lot to do, but ideally I can run through the meat of these assignments and then post-train my own model.
I’ve been writing a lot of small agents and neural networks in Python or PyTorch to practice. But by far the most helpful thing was pair programming with people who have been working in Python for 10+ years, and just watching them work or having them watch me work.
For example, a nice thing I picked up from someone I pair programmed with: when this guy was writing code and didn’t quite remember the syntax or operations, he would often just quickly open up a terminal and type a super simple example to rapidly iterate. He was usually able to work it out and verify if it worked correctly in less than a minute, and he didn’t have to google anything and comb through search results or ask an LLM. This technique might seem obvious to some, but making this process muscle memory has helped me become unstuck much faster.
I want to keep moving in this direction, doing simple projects or even just problems like Advent of Code while pair programming. Working with someone else live was initially a bit nerve-racking, but precisely because of this I’ve noticed a lot of progress.
Here are a few examples of things I’ve done which I’d classify as helping me understand computers better:
I wrote the classic programming function fizzbuzz in BASIC on an Apple IIe computer from 1983. It was cool seeing how differently computers worked back then, for example how manual the code editing and execution process was, but also how it was basically the same.

Tinkering with an Apple IIe.
One thing I’ve always felt a bit self-conscious about are my Unix/terminal skills. So I joined CTF Fridays, a weekly session devoted to working through Bandit and other “war games.” These are Unix and computer security related challenges played through the terminal, with the objective of collecting passwords and leveling up. Now I have a pretty good sense for what Claude Code is trying to run on my computer!
One day I hand-coded a single layer perceptron I saw when flipping through an AI textbook… completely in Vim. It was especially tedious at first, but I got some pro tips from another Recurser and learned a few shortcuts. This has actually been incredibly useful now when I’m running training jobs on cloud GPUs and I need to last-minute edit files.
I joined a Clojure workshop given by someone who has 15+ years of experience using Clojure. The topic itself was interesting because Clojure is a functional programming language and I don’t have much experience with functional languages. The teaching methodology was also great: after a brief intro we did a round of mob programming, where we solved a problem collectively, going around the table with each person getting a minute or two to advance the solution.
The weekly technical presentations are great exposure to an incredible array of topics. These are a set of 5-minute talks, so they are short enough that you don’t get bored but fast enough that you can learn something meaningful. A sample of titles: “Running Rust Code”, “GPUs for Dummies”, “Typesafe APIs for Type B Personalities”, “Some Useless Agents” (this one was mine!), and more. I’ve given two so far: one on simple agent architectures, one on scaling MCP tools efficiently; and will give another this week on different ways to optimize GPUs.

Even just hearing from people about their projects and careers has been incredibly valuable in helping me understand the space of problems computers can solve.
Soon I’ll be shipping agents to prod and running evals with a whole new bag of tricks and skills. But for now I’ve got 6 more weeks left at RC, which I’m beginning to worry is not enough time to finish everything on my list. And it won’t be. But that’s what makes RC so great: it’s not as much about crossing everything off my list but about spending time coding.
Not sure if I described this before but I think the reason I was so taken aback was that a few years prior I had been living in Japan studying Japanese full time, and it was really really hard. And here was a computer model that had managed to figure it out! Even if they hallucinated or couldn’t do math correctly at the time; that was absolutely incredible to me.
There were 2 or 3 bugs that stumped me, and after 20 min or so of debugging I asked Claude for some advice. But most of the debugging was by hand!
No posts