
A room of secretaries at typewriters circa 1925. © Underwood Archives/Getty
AI doesn’t really “think.” Rather, it remembers how we thought together. And we’re about to stop giving it anything worth remembering.
We are on the verge of the age of human redundancy. In 2023, IBM’s chief executive told Bloomberg that soon some 7,800 roles might be replaced by AI. The following year, Duolingo cut a tenth of its contractor workforce; it needed to free up desks for AI. Atlassian followed. Klarna announced that its AI assistant was performing work equivalent to 700 customer-service employees and that reducing the size of its workforce to under 2000 is now its North Star. And Jack Dorsey has been forthright about wanting to hold Block’s headcount flat while AI shoulders the growth.
The trajectory has a compelling internal logic. Routine cognitive work gets automated; junior roles thin out; productivity gains compound year on year. For boards reviewing cost structures, it is the cleanest investment proposition since the internal combustion engine retired the horse, topped up with a kind of moral momentum. Hesitate, the thinking goes, and fall behind.
But the research results of a team in the UK should give us pause. In the spring of 2024, they asked around 300 writers to produce short fiction. Some were aided by GPT-4 and others worked alone. Which stories, the researchers wanted to know, would be more creative? On average, the writers with AI help produced stories that independent judges rated as more creative than those written without it.
So far, so on message: a familiar story about the inevitable takeover by intelligent machines. But when the researchers examined the full body of stories rather than individual ones, the picture became murky. The AI-assisted stories were more similar to each other. Each writer had been individually elevated; collectively, they had converged. Anil R Doshi and Oliver Hauser, who published the study in Science Advances, reached for a phrase from ecology to explain this: a tragedy of the commons.
Hold that result in mind: individual gain, collective loss. It describes something far more consequential than a writing experiment—it describes the hidden logic of our entire relationship with artificial intelligence. And it suggests that the most successful organizations of the coming decade will be the ones that do something profoundly counterintuitive: instead of using AI to eliminate human interaction by firing droves of workers, they will use it to create more human interaction. IBM has reversed course on its earlier human redundancy fantasies. I bet more will in due course.
I.
Suppose you could travel to Egypt in 3000 BC and copy, in flawless hieroglyphics, the contents of every temple library, every architectural plan, every priestly manual, every commercial ledger. Then suppose you travelled to Mesopotamia and did the same in cuneiform. Consolidate everything you could find in the languages of that era, and then proceed to train a large language model on it. Full transformer architecture, self-attention, the whole enchilada.
The result would be a system capable of a certain kind of intelligence. It could predict floods from astronomical cycles. It could draft administrative correspondence. It could generate plausible religious commentary. But it would have no capacity for what the Greeks would later call the syllogism. It would carry no trace of Roman legal abstraction, and have no conception of the empirical method that wouldn’t emerge for another four millennia.
Now, let’s extend the experiment. Train a new model on the written output of 300 BC Athens: Aristotle, Euclid, Hippocrates, the commercial records of Mediterranean trade, etc. Another on 300 AD Rome, another on 1000 AD Baghdad, another on 1500 AD Florence, and finally one on the full internet-scale text production of the modern world.
Each model in this chain would be qualitatively smarter than the last. But it wouldn’t be smarter because you changed the architecture of the underlying technology (you didn’t). The reason would be that the civilization feeding the tech had changed. The 300 BC model would demonstrate logical inference that its Egyptian predecessor couldn’t approach. The 1500 AD model would handle probability and navigational calculation. And the 2025 model would exhibit the argumentative density, cross-domain reasoning, and multi-perspectival sophistication that characterize today’s frontier systems.
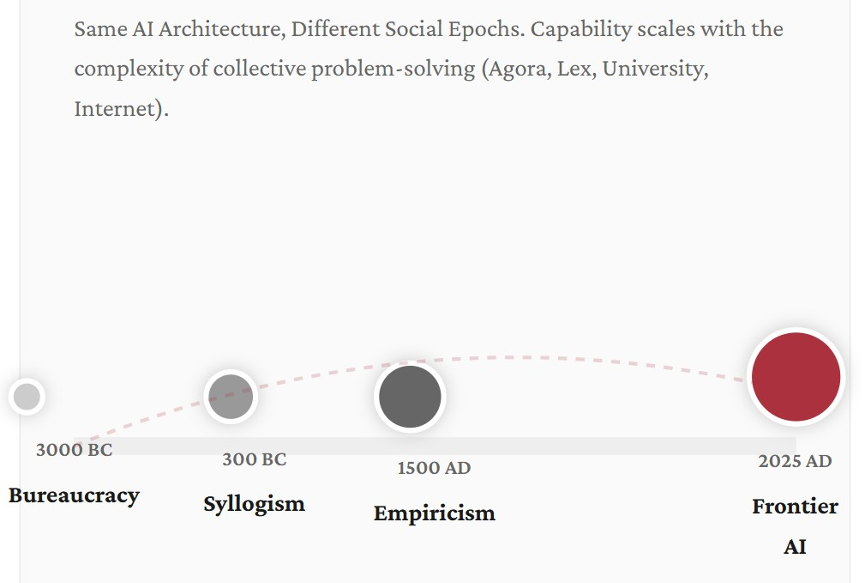
Figure 1. Civilizational substrates of intelligence
What the chain reveals is a dependency the AI industry has largely declined to examine. The underlying intelligence of a large language model isn’t a function of its architecture, its parameter count, or the volume of compute thrown at its training. It is not even about the training data. It is a function of the social complexity of the civilization whose language it digested.
Each epoch advanced the cognitive frontier through something far richer and more complex than the isolated genius of an individual guru or machine. It did so through new forms of collective problem-solving. Think new institutions (the Greek agora, the Roman lex, the medieval university, the scientific society, the modern corporation, and the social internet) that demanded and rewarded ever more sophisticated uses of language.
The cognitive anthropologist Edwin Hutchins studied how Navy navigation teams actually think. In his 1995 book Cognition in the Wild, he wrote something that reads today like an accidental prophecy. The physical symbol system, he observed, is “a model of the operation of the sociocultural system from which the human actor has been removed.”
That is, with eerie precision, a description of what a large language model (LLM) really is, stripped of all the unapproachable jargon and mathematical wizardry. An LLM like ChatGPT is a model of human social reasoning with the human wrangled out. And the question nobody in Silicon Valley is asking with sufficient urgency is: What happens to the model when the social reasoning that produced its training data begins to thin?
II.
In 2024, Ilia Shumailov and colleagues published a paper in Nature with a straight-talking title: AI models collapse when trained on recursively generated data. They demonstrated, with alarming mathematical precision, that language models trained on text generated by other language models start to degenerate partly because the distribution of the output narrows over successive generations. Minority viewpoints, rare knowledge, unusual formulations, and edge-case perspectives gradually vanish. The model converges on a kind of statistical average—fluent, plausible, and hollow. The tails of the distribution disappear first.
Consider what those tails represent. They are the traces of intellectual disagreement, of minority expertise, of Cassandra warnings, of institutional friction, and of the awkward and valuable fact that different people know different things and express them differently. They are, in other words, the signature of social complexity. Model collapse is social mind compression presented as a technical phenomenon.
Around the same time, the AI researcher Andrew Peterson analyzed what he called “knowledge collapse”: the harmful effect on public knowledge due to widespread reliance on AI-generated content. Even with a modest discount on AI-sourced information, public beliefs deviated 2.3 times further from ground truth. When people and organizations rely on AI summaries rather than engaging with primary sources, the diversity of available perspectives narrows.
Similarly, there is a variant of the Dunning Krueger effect, I suggest, that is found in those conversing with service chatbots that spare them the social bruises of hard conversations. When people choose to “ask Grok” to settle messy debates on Twitter/X, they are spreading this syndrome of overconfidence in one’s understanding of complex issues. It is easier to inflate your knowledge and understanding when you don’t have to deal with the social-regulatory feedback of ego-bruising disagreement. Blind spots grow bigger when one is cocooned in a machine-harem of pampering bots. What emerges over time is subtler than the militant ignorance of pre-AI social media. It is a confident, fluent, and remarkably homogeneous form of shallow knowing.
Anthropic, the maker of Claude, another LLM platform, has research results showing that in only 8.7% of user interactions with its platform do users pause to double-check what the bots spew out. That number reinforces something bigger than mere cognitive offloadingand delegation. It enables systemic overconfidence which in turn diminishes curiosity, exploration, and knowledge-frontier defiance.
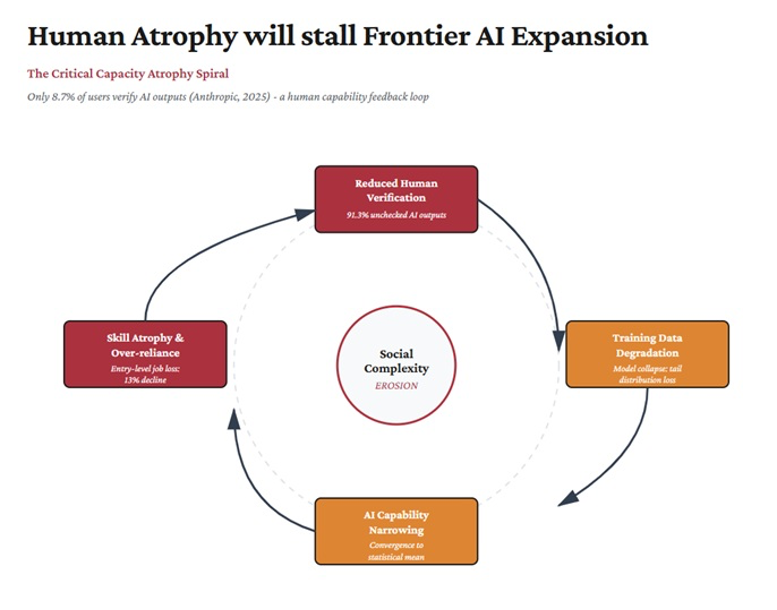
Figure 2. Cognitive overloading, overconfidence, underexploration & frontier AI regression
Meanwhile, a team at Epoch AI estimated that the total stock of quality-adjusted human-generated text available for training is roughly 300 trillion tokens, projected to be exhausted between 2026 and 2032. This is typically framed as a resource depletion problem as though we’re running out of data the way we might run out of water. But that framing misses the deeper point. The reservoir is not just being drained—the springs feeding it are starting to dry up.
III.
In early 2025, researchers at Microsoft and Carnegie Mellon studied 319 knowledge workers across 936 real-world tasks that involved AI assistance. What they found was not what the productivity narrative had promised.
In 40% of AI-assisted tasks, participants reported exercising no critical thinking whatsoever. The higher their confidence in the AI’s output, the less cognitive effort they invested. The researchers didn’t use this phrase, but I will: they documented the automation of thought, where the frictions of exploration are missing and mental outputs emerge as if from an assembly line.
Technology is interesting, but human behavior is more so. We have observed for decades that people will offload cognitive work even when they’re not overwhelmed, and do so preemptively, the moment a reliable-seeming assistant is available. Lisanne Bainbridge identified this pattern in 1983, in a paper whose title has become something of a dark proverb among automation researchers: “Ironies of Automation.” In Bainbridge’s view, the more reliable the automation, the less practiced its human operators become. It is a profound paradox I have grappled with in other forms: the more complex automated systems become, the higher the skill level required to intervene when (not if) they malfunction.
Nicholas Carr is famous for railing against such effects of automation in the digital age. In the same line of inquiry, Sparrow, Liu, and Wegner showed experimentally that when people know information is available through Google, they invest less effort in memorizing it. Now imagine that effect amplified by a system that doesn’t merely retrieve information but generates analysis, drafts arguments, and produces plausible reasoning on demand. The result is a world in which individual productivity rises while the collective pace of human thought starts to fall. The horse-trooper gallops harder but the cavalry covers less ground.
IV.
We can sharpen the argument further.
If AI capability depends on the social complexity of human language production—and if AI deployment systematically reduces that complexity through cognitive offloading, homogenization of creative output, and the elimination of interaction-dense work—then the technology is gradually undermining the conditions for its own advancement. Its successes, rather than failures, create a spiral: a slow attenuation of the very substrate it feeds on, spelling doom.
This is the Social Edge Paradox, and the intellectual tradition it draws from is older and more interdisciplinary than most AI commentary acknowledges.
Michael Tomasello’s evolutionary research establishes that human cognition diverged from other primates by a process other than superior individual processing power. The real impetus came through the capacity for collaborative activity with shared goals and complementary roles. He argues that even private thought is “fundamentally dialogic and social” in structure—an internalization of interaction patterns. Autonomous neural capacity is far from enough to account for the abilities of human thought.
Robin Dunbar’s social brain hypothesis quantifies the link: neocortex ratios predict social group size across primates; language evolved as a mechanism for managing relationships at scales too large for grooming. Two-thirds of conversation is social, relational, reputational. Language is often mistaken as an information pipe, but it is really a social coordination technology.
My own position is that collective intent engineering, found in forms as familiar as simple brainstorming, accounts for most frontier cognitive expansion. The intelligent algorithms of today have not been built with this critical function in mind.
I agree with Lev Vygotsky’s characterization that thinking is emergent from words as opposed to words being a mere vessel for conveying thought. I also align with the arguments of Andy Clark and David Chalmers about how cognition extends constitutively into social and material environments. But my own claim is stronger: It is collective intent specification that creates the most formidable cognitive burden in doing anything worthwhile. Getting intelligent minds to sync around an issue and work towards a common cause has always been the hallmark of human mental effort, whether it is raising giant pyramids or landing on the moon. A complex vision must radiate into the hive-mind to generate an interconnected consciousness that takes us from the solitary genius of apples falling on scientific heads to finally defying earthly gravity en route to Mars.
A constitutional convention, for example, is not just a group of people exchanging opinions; it is a very definite process of thinking that no individual could replicate alone and which AI today can undermine if it breaks the hive-mind.
What all this implies for AI is straightforward. Every token in a training corpus is a fossil of social interaction—a trace of negotiation, argumentation, institutional meaning-making, or cultural transmission. The intelligence that AI systems exhibit was never individual to begin with. It was forged in the spaces between people.
And if those spaces are allowed to shrink due to over-dependence on human-machine interaction, we have trouble. If the interactions that generate rich language become rarer, shallower, or more homogeneous, then the intelligence that depends on them will slowly degrade. We will not hear any bangs, true, but we will notice a gentle, almost imperceptible narrowing over time. The machines to which we are fast entrusting the future of discovery will slow down when it matters most.
V.
Dario Amodei, the CEO of Anthropic, published a long essay in October 2024 called “Machines of Loving Grace.” He imagined what a super-intelligent AI might accomplish across science, governance, and human welfare. His piece reinforces the thinking of Leopold Aschenbrenner, a former OpenAI researcher (as Amodei himself is). Leopold’s “Situational Awareness,” written a few months earlier, argues with great conviction that scaling compute and data would be sufficient to produce artificial general intelligence within years.
But these papers exhibit significant strategic blind spots despite their eloquence and the technical eminence of their authors. Amodei identifies limiting factors—safety, alignment, institutional readiness—but does not consider the possibility that the quality of future training data is itself socially determined and potentially degrading. Aschenbrenner’s entire framework assumes that scaling is the primary constraint, with zero discussion of the social origins of the data being scaled.
Sam Altman’s “Intelligence Age” essay comes closest to acknowledging the social aspect of AI when he writes that “Society itself is a form of advanced intelligence.” But it is unclear what his true commitment to the consequence of that claim is. I suspect mere rhetorical flourish. He does not even ask whether AI deployment might erode the social processes that constitute this intelligence.
The Social Edge Framework outlined here is a direct counterpoint to Amodei, Aschenbrenner, and Altman. It is a program of action to counter the human redundancy fantasy. It challenges the self-fulfilling doom-spirals created by the premature reallocation of material resources to a vision of AI. I speak of the philosophy that underestimates the sheer amount of human priming needed to support the Great Recode of legacy infrastructure before our current civilization can even benefit substantially from AI advances.
By “Great Recode,” I am paying homage to the simple but widely ignored fact that the overwhelming number of tools and services that advanced AI models still need to produce useful outputs for users are not themselves AI-like and most were built before the high-intensity computing era began with AI. In the unsexy but critical field of PDF parsing—one of the ways in which AI consumes large amounts of historical data to get smart—studies show that only a very small proportion of tools were created using techniques like deep learning that characterize the AI age. And in some important cases, the older tools remain indispensable. Vast investments are thus required to upgrade all or most of these tools—from PDF parsers to database schemas—to align with the pace of high-intensity computing driven by the power-thirst of AI. Yet, we are not at the point where AI can simply create its own dependencies.
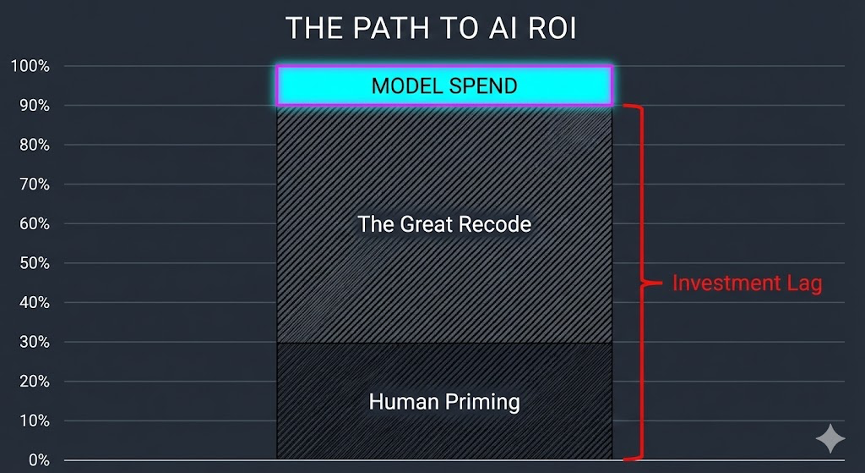
Figure 3. A great amount of money is being spent on AI yet the vast surrounding infrastructure and human operators have not been primed for an AI-first world
Indeed, the so-called “legacy tech debt” supposedly hampering the faster adoption of AI has in many instances been revealed as a problem of mediation and translation. AI companies are learning that they need to hire people who deeply understand legacy systems to guide this Recoding effort. A whole new “digital archaeology” field is emerging where cutting-edge tools like ArgonSense are deployed to try to excavate the latent intelligence in legacy systems and code often after rushed modernization efforts have failed. In many cases, swashbuckling new-age AI adventurers have found that mainframe specialists of a bygone age remain critical, and multidisciplinary dialogues and contentions are essential to progress on the frontier. Hence the strange phenomenon of the COBOL hiring boom. New knowledge must keep feeding on old.
The Social Edge Framework says: yes, scaling matters, architecture matters, and compute matters. But none of these will continue to deliver if the social substrate—the complex, argumentative, institutionally diverse, perspectivally rich fabric of human interaction—is allowed to thin. And thinning is very possible.
VI.
Now for the part that will strike many as paradoxical.
The prevailing wisdom is that AI enables organizations to do more with less—automate routine work, thin the headcount, and redirect savings toward strategy. The Social Edge Framework suggests this calculus can be self-defeating in ways that compound slowly but surely.
Let’s look at the evidence. Brynjolfsson, Chandar, and Chen tracked employment outcomes for early-career workers aged 22-25 in AI-exposed fields. Since 2022, this cohort has experienced a 13% relative decline in employment. It seems that AI replaces codified knowledge (the primary asset of junior workers) while complementing tacit knowledge (the hard-won asset of experienced professionals). The problem is that tacit knowledge does not arise from thin air. It comes from doing the work: absorbing institutional norms, developing judgement through supervised practice, making costly mistakes at manageable scale. Entry-level positions may look like just a cost line. But they actually function as the on-ramp through which the next generation of domain experts is produced. In that sense they are part of the organization’s core strategic investments. Remove the on-ramp and you save money today. But you also starve the pipeline of domain-specific, socially embedded knowledge on which future AI systems will depend.
Dell’Acqua and colleagues at Harvard Business School found that management consultants using GPT-4 improved quality by 40% within the AI’s competence frontier. Outside that frontier—on problems requiring contextual judgement the AI could not supply—their performance dropped by 19%. The technology had made them overconfident precisely where confidence was least warranted—a pattern that should give pause to any board treating AI adoption as a straightforward substitution exercise.
The Social Edge prescription is that organizations that hire more people to work in AI-enriched, high-interaction, and transmediary roles—where AI scaffolds learning rather than substituting it—will derive greater long-term advantage than those that treat the technology as a headcount-reduction device. In a world where raw cognitive throughput has been commodified, the value arc shifts to something considerably harder to replicate: the capacity to coordinate human intent with precision, speed, and genuine depth. That edge lies in trans-mediation and high human interactionism.
VII.
The AI industry is telling a story about the future of work that goes roughly like this: automate what can be automated, augment what remains, and trust that the productivity gains will compound into a wealthier, more efficient world.
The Social Edge Framework tells a different story. It says: the intelligence we are automating was never ours alone. It was forged in conversation, argument, institutional friction, and collaborative struggle. It lives in the spaces between people, and it shows up in AI capabilities only because those spaces were rich enough to leave linguistic traces worth learning from.
Every time a company automates an entry-level role, it saves a salary and loses a learning curve, unless it compensates. Every time a knowledge worker delegates a draft to an AI without engaging critically, the statistical thinning of the organizational record advances by an imperceptible increment. Every time an organization mistakes polished output for strategic progress, it consumes cognitive surplus without generating new knowledge.
None of these individual acts is catastrophic. However, their compound effect may be.
The organizations that will thrive in the next decade are not those with the highest AI utilization rates. They are those that understand something the epoch-chaining thought experiment makes vivid: that AI’s capabilities are an inheritance from the complexity of human social life. And inheritances, if consumed without reinvestment, eventually run out. This is particularly critical as AI becomes heavily customized for our organizational culture.
Making the right strategic choices about AI is going to become a defining trait in leadership. Bloom et al. cross-country research has long established that management quality explains a substantial share of productivity variance between teams and organizations, and even countries.
In the AI age, small differences in leadership quality can generate large differences in outcomes—a non-linear payoff I call convex leadership. The term is borrowed from options mathematics, where a convex payoff is one whose upside accelerates faster than the downside decelerates. Convex leaders convert cognitive abundance into structural ambition and thus avoid turning their creative and discovery pipelines into stagnant pools of polished busywork. Conversely, in organizations led by what we might call concave leaders—cautious, procedurally anchored, optimizing for error-avoidance—AI would tend to produce more noise than signal. Because leadership is such a major shaper of all our lives, it is in our interest to pay serious attention to its evolution in this new age.
The Social Edge is more than a metaphor. It is the literal boundary between what AI can do well and what it will keep struggling with due to fundamental internal contradictions. Furthermore, the framework asks us all to pay attention to how the very investment thesis behind AI also contains the seeds of its own failure. And it reminds leaders that AI’s frontier today is set by the richness of the social world that produced the data it learned from.
Bright Simons is a researcher, activist, and writer whose work sits at the intersection of global value chains, technology strategy, and institutional governance & design. He is the founder of the mPedigree Network, and affiliated with IMANI and ODI Global, both think tanks.