The author didn't seem to read the Brooks essay for comprehension. There is an entire section about expert systems that foreshadows agents. While there is no singular silver bullet, Brooks explores the most promising techniques to reduce essential complexity that were anticipated in 1986.
> The most powerful contribution of expert systems will surely be to put at the service of the inexperienced programmer the experience and accumulated wisdom of the best programmers. This is no small contribution.
Furthermore, his objection to automatic programming was simply an argument from incredulity, which is an understandable opinion at the time, yet quite vacuous in hindsight.
You could fetch some unfinished github repos or download free templates. It’s actually faster than LLMs, still no body would do it.
I don’t start my project with the ecommerce nextjs starter repo. I build it from scratch, because it’s faster...
Design patterns in an older (programming) language become core language features in a newer one. As we internalize and abstract away the best patterns for something, it becomes accidental but it's only obvious in retrospect.
The article quotes Brooks (quoting Parnas) about just that (later, in context of LLMs):
> automatic programming always has been a euphemism for programming with a higher-level language than was presently available to the programmer. [...] Once those accidents have been removed, the remaining ones are smaller, and the payoff from their removal will surely be less.
Considering this was written when C was the hot new stuff, let's compare the ability to code a CRUD web app in Python/Django vs C. What Brooks and Parnas are saying that Python/Django cannot bring big improvements in building a CRUD web app when compared to C because they can only make it easier to program, reducing accidental complexity. But we've since redefined "accidental" and I would argue that you can write a CRUD web app in Python/Django at least 100x faster than in C (and probably at least 100x more secure), although it may take 1000x as more CPU and RAM while running.
So "we removed most of the accidental difficulties and the most that remains is essential" is a kind of "end of history" argument.
> I’d be surprised if there’s even a doubling of productivity still available from a complete elimination of remaining accidental difficulty.
It's good that this statement has a conditional subjective guard, because that's just punditry.
> LLM coding does not represent a silver bullet
Here I agree with the author completely, but probably not for the same reasons. The definition of "silver bullet" the article uses (quoting Brooks):
> There is no single development, in either technology or management technique, which by itself promises even a single order-of-magnitude improvement within a decade in productivity, in reliability, in simplicity.
AI-assisted development is not a single technique, the same way "devops" or "testing" or "agile" is not a single technique. But more importantly, I agree it will take time to find best practices, for the technology change to slow down, and for the best approaches to diffuse across the industry.
The article's conclusion:
> You should be adopting and perfecting solid foundational software development practices like version control, comprehensive test suites, continuous integration, meaningful documentation, fast feedback cycles, iterative development, focus on users, small batches of work… things that have been known and proven for decades, but are still far too rare in actual real-world software shops.
These are great and I'm gonna let him/her finish, but it's curious actual coding isn't mentioned anywhere. The author doesn't suggest "polish your understanding of C pointer semantics" or "Rust ownership model" or "Django ORM" or to really, deeply, understand B-trees. Looks like pedestrian detailes like those are left as an excercise for the reader ... or the reader's LLM.
I think the biggest benefit language models have provided me is in the auxiliary aspects to programming: search, debugging, rubber ducking, planning, refactoring. The actual code generation has been mixed.
I had an LLM try and implement a fairly involved feature the other day, providing it with API spec details, examples from other open source libraries, and plenty of specifications. It's also something readily available in training data as well, but still fairly involved.
On first glance it looked great, and had I not spent the time to investigate deeper I would have missed some glaring deficiencies and omissions that render its implementation worthless. I am now going back and writing it by hand, but with language models providing assistance along the way, and it's going much better.
I think people are being unrealistic by thinking that the usage of language models in their side projects represent something broader. It's almost the perfect situation for language models: small, greenfield code bases, no review, no responsibility, and no users. It goes up on GitHub with a pretty readme, and then off to social media where they post about how developers are "cooked". It's just not a very realistic test.
In the end we will probably see large productivity increases by integrating language models, but they won't be replacing developers but rather augmenting them.
The article goes on to assume there’s no 10x gain to be had but misses one big truth.
Needing to type the code is an enormous source of accidental difficulty (typing speed, typos, whether you can be arsed to put your hands on the keyboard today…) and it is gone thanks to coding agents.
> (although I’m personally skeptical of the “10x programmer” concept, the software industry overall does seem to accept it as true)
To be fair, this statement from Brooks doesn't entirely match with the "10x programmer" we talk about. My take on it is when someone says "10x programmer" today, they mean 10x more productive than the average, not 10x more productive than the worst. Brooks' statement is about the latter. If he'd looked at the difference between average and best, I would assume you'd get something more like a 2x or 4x programmer.
I'm reminded of this scene from the Matrix: https://www.youtube.com/watch?v=cD4nhYR-VRA where the older wise man discusses societies reliance on AI
"Nobody cares how it works, as long as it works"
We're done. I for one welcome our new AI Overlords, or more accurately still welcome the tech bro billionares who are pulling the strings
Until recently. dramatic pause
And then AI happened.
I honestly couldn't force myself to finish yet another blog post about how "we're not yet sure what impact LLMs will have on society" or whatever beleaguered point the author was attempting to make.
"Some random person's take on LLMs" was maybe interesting in 2024. Today it is not even remotely interesting.
There are a gazillion more interesting things happening today that ought to be of interest to the median HN reader. Can we talk about those instead?
It does not actually, and not any faster.
Again I've lost count of how many times I've had an in-depth architectural discussion with ChatGPT, with it giving me the final mark of approval ("This is excellent"), only for me to discover a flaw in my approach or a radically simpler and better approach, go back to it with it, and for it to proclaim "Yeah this is a much better approach".
These LLMs are in many cases sycophantic confirmation machines. Yes, they are useful to some extent in helping you refine your ideas and think of edge cases. But they are nowhere close to actually thinking better and faster. Faster in the wrong direction is not just slow, you are actually going backward.
A paradigm shift is an earth shattering, very important change - a complete change in thinking etc. LLMs are not that. They are simply some pretty new tools. Nice tools but they will whip off your metaphorical thumb just as quickly as a miss-used table saw.
You'll note that you mention "engineers are offloading": that's not a paradigm shift. That's a bunch of engineers discovering a better slide rule.
I'm old enough to remember moving on from slide rules (I still have mine) through calculators (ditto) to using fag packets and napkins for their real intended purpose.
The drill-driver also took engineering by storm but no-one ever used the term paradigm shift (to be fair, I don't think it was invented at the time and I can't be arsed to look it up).
Developers should write their own code and use LLMs to design and verify. Better, faster architecture and planning, pre-cleaned PRs and no skill atrophy or loss of understanding on the part of the developer.
It does? You mean "it tests itself faster", which is not really a test now, is it?
The benefits of the time savings of having progressily better tooling over time add up quickly.
It's not terribly hard to check either. You can do some spot checks with cost dashboards in AWS, Datadog, etc and see if the numbers line up
Can also tell Claude "go right size the environment, pull p95 usage metrics for the last 3 months" and a couple hours later, a bunch of money is saved. Much easier than manually pulling trend data and also easier than installing/configuring/managing tools that do it for you.
Really? That's like someone during an economic boom saying "The economy is the worst it'll ever be. There is no reason to expect things to not continue to improve".
Funny, I thought that the major hurdle is improving accuracy and reliability, as it's always been. Engineering is necessary and useful, but it's a much simpler problem, which is why everyone is jumping on it.
I'm sure it was very difficult to program in machine code, but if now (or soon) anyone can just write software using a LLM without any sort of learning it changes everything. LLMs can plan and create something usable from simple instructions or ideas, and they will only get better.
I think LLMs will be (and already are) useful for many more things than programming anyway.
There are, IMHO, fewer reasons to believe they will be able to do that rather than not, though.
10x relative to what exactly? It's not a statement grounded in any kind of reality.
Just one more harness bro. Just one more agentic swarm. Please bro, just one more Claude Max subscription. Please bro.
And it's literally just a black box that generates more Javascript for their Next.js app
If this sounds melodramatic it’s likely that it hasn’t fully taken root where you are yet.
I see opinions split on like “it’s just a dirty untrustworthy tool that is making our lives and the world a living hell” and “this is the second coming of Christ”. The reality is that right now we lie on that first part of the spectrum, but I am looking over the hill and seeing 4 horses and they are stampeding this way
It sounds like you actually do want to talk about how much you don't want other people to talk about LLMs.
I don't buy that's true. The "only" part, anyway. Look at how UX with software has evolved. This is gonna be an old man yells at clouds take, but before smartphones, there were hotkeys. And man, you could fly with those things. The computers running things weren't as fast as they are today, but you could mash in a a whole sequence thru muscle memory, and just wait for it to complete. Now, you have to poke at your phone, wait for it to respond, poke at it some more. It's really not great for getting fast at it. AI advancement is going to be like that. Directionally generally it will be better, but there's going to be some niche where, y'know what, ChatGPT-4o really had it in a way that 5.5 does not. (Rose colored glasses not included.)
I'm a 10x programmer at building Django apps compared to a developer who has never worked with Django before.
Someone who developers against WordPress on a daily basis will easily 10x my own attempts at building things on that platform.
Did you read the section "Power to the People?" ? In it, the author dismantles your thesis with powerful, highly plausible arguments.
The current state of the art is irrelevant. Only the first couple of time derivatives matter.
You’re definitely right that people adopt agentic workflows and are disappointed or worse, but the point is the disappointment has already reduced substantially and will continue to do so. We know this because we know the scaling laws, and also because learning theory has been around for many decades.
All I would need from an LLM doubter is evidence that at tractable software engineering task LLM's are not improving. The strongest argument against the increasing general capabilities of LLM's are the ARC-AGI tasks, however the creators admit that each generation of LLM's exceed their expectations, and that AGI will be achieved within the decade.
Generally, the whole point of the "Power to the people?" (and to some extent the "On being left behind") section(s) is to underscore the two antithetical claims made by many LLM marketers: 1. LLMs are so powerful and so natural and easy that someone with no experience can create amazing software, and 2. LLM usage is a core skill, one that if you don't begin training now you'll be left behind.
Obviously, both of these can't be simultaneously 100% true--either it's easy enough for the non-programming layperson to successfully generate software for an intentional purpose, or, LLM assisted programming is a skill you need to train to avoid professional obsolescence in modern society. So, the article disagrees with the majority of both claims, and accepts a weakened/minor portion of each: 1. LLM output is easy to generate but accurate prompting matters, and 2. when used for software development professionally, some amount of skilled human intervention does indeed seem necessary. And now these two claims do align.
However, if professional software engineers who work with and read code constantly, armed with the best software practices to aid LLMs we can determine, cannot use modern AI tools without shooting their feet off at relatively frequent rates, certainly you'd expect the layperson who must put an even greater amount of undue faith in the validity of the results to be at extremely high-risk of foot-shooting. It's not "gatekeeping" to forewarn people against unwarranted trust in LLM output, nor is it "gatekeeping" to suggest that modern tech communicators/marketers describing an overly flowery LLM tooling landscape might be doing people a disservice.
Then came the new Claude update, which many people say is worse. Even Anthropic says it got worse.[1] HN discussion back on April 15th: [2]
Some of this is a pricing issue. Turning "default reasoning effort" down from "high" to "medium" was a form of shrinkflation. Maybe this technology is hitting a price/performance wall.
[1] https://www.anthropic.com/engineering/april-23-postmortem
Would there even be a debate in the tech community if such unassailable arguments existed? The author is entirely entitled to his opinion, just as I am allowed to disagree with him (not sure why I am also downvoted). The good thing is, if I'm right, we will see it in less than 10 years.
Engage as a person, please.
I come in knowing what I need to build and at least one idea or more of how it should be done. I present the problem, constraints, potential solutions, and ask for criticisms and alternatives. I can keep it as broad as possible or I can get more granular like struct layouts, api endpoints, etc. I go back and forth until there's an approach I prefer and then I code that approach.
| it can code pretty well given a very tight and limited scope.
It's wildly better at tight and limited scope than large scale changes but even then I would rather code it myself.
I've had this conversation with managers in multiple organizations this year: "Yes, you could totally vibe code that instead of paying for a SaaS. But you have strict contractual and professional obligations about data security. Do you want to be deposed and asked, 'So, did you really just vibe code the system that led to the data leak? Did the vibe coders have any professional qualifications? Did they even look at the code?'"
Similarly, a backend server that handles 8 million users a day is expected to stay up.
Now, there are 10,000 things that have less demanding requirements. I'm actually really delighted that people are able to vibe code their own tools with minimal knowledge of software engineering! We have been chronically underproducing niche software all along.
But if your software already has on-call shifts (and SLAs, etc) like the GP, then I think you want to be smart about how you combine human expertise with LLMs.
i was doing an ML Sec phd a year or two before all this hype took off. i took one of the OG transformer papers along to present at our official little phd reading group when the paper was only a few months old (the details of this might be a bit sketchy here, was years ago now).
now i want nothing to do with the field in any way shape or form. i’m just done.
edit -- i got incredibly angry after writing this comment. pure hatred and spite for all the charlatans and accompanying bullshit.
1. You don't have to be an LLM expert to get good, consistent results with LLMs.
My best vibe-code process after years of using LLMs is to have Claude Code create a plan file and then cycle it through Codex until Codex finds nothing more to review, then have an agent implement it. This process is trivial yet produces amazing results.
It's solved by better and better harnesses.
2. You don't have to write technical specs. The LLM does that for you. You just tell it "I want the next-tab button to wrap back to the first one" and it generates a technical plan. Natural language is fine.
3. Software that seems to work only to fail down the line in production is already how software works today. With LLMs you can paste the stacktrace or user bug email and it will fix it.
This is why vibe-coding works. Instead of simulating how an app will run in your head looking at its code, you run the app and tell the LLM what isn't working correctly. The app spec is derived iteratively through a UX feedback look.
4. I don't understand TFA's goalposts, but letting people create software that are only interested in the LLM process (rather than the software craftsmanship) would be a huge democratization of software.
I would say I got better at both of those over the last 12-18 months. Are your skills static?
I'll give you the coding harnesses themselves are better because that was a new product category with a lot of low-hanging fruit, but have the models actually improved in a way that isn't just benchmaxxing? I'd argue the models seem to be regressing. Even the most AI-pilled people at my company have all complained that Opus 4.7 is a dud. Anecdotally, GPT 5.5 seems decent, but it's rumored to be a 10T parameter model, isn't noticeably better than 5.4 or 5.3, is insanely expensive to use, and seems to be experiencing model collapse since the system prompt has to beg the thing to not talk about goblins and raccoons.
It's the "YOLO" of business strategies.
That being said, I don't even think that arguing about this from a mathematical perspective is a worthwhile use of time. Calling something an asymptote in the first place requires defining a quantifiable "X" and "Y", which we don't even have. What we have are a bunch of synthetic benchmarks. Even ignoring the fact that the answers to the questions are known to regularly leak into the training data (in other words, it's possible for scores to increase while capabilities remain the same), there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world. And being able to answer some arbitrary set of arbitrary questions on a benchmark which the previous model couldn't, does not have a quantifiable correlation to some specific amount of real-world improvement.
The OP article focuses on research papers which assess real-world impact of LLMs within software organizations, which I think are more representative.
I wouldn't call myself an "AI doubter" - I use LLMs every day. When you say "doubter" you're not referring to "AI" in general, or the fact that AI is helpful or boosts productivity (which I believe it does). You're rather referring to the very specific, very extraordinary claim, that LLMs will surpass humans in coding. If that's the case then yeah I'm a doubter, at least on any foreseeable timescale.
We're almost 6 months into all this AI-code madness and I've yet to see that "rapid improvement" you mention. As in software products that are genuinely better compared to 6 months ago, or new software products (and good software products at that) which would have not existed had this AI craze not happened.
Published on: April 9, 2026 Categories: Programming
Everybody seems to agree we’re in the middle of something, though what, exactly, seems to be up for debate. It might be an unprecedented revolution in productivity and capabilities, perhaps even the precursor to a technological “singularity” beyond which it’s impossible to guess what the world might look like. It might be just another vaporware hype cycle that will blow over. It might be a dot-com-style bubble that will lead to a big crash but still leave us with something useful (the way the dot-com bubble drove mass adoption of the web). It might be none of those things.
Many thousands of words have already been spent arguing variations of these positions. So of course today I’m going to throw a few thousand more words at it, because that’s what blogs are for. At least all the ones you’ll read here were written by me (and you can pry my em-dashes from my cold, dead hands).
But first, a couple quick notes:
I’m going to be using the terms “LLM” and “LLMs” almost exclusively in this post, because I think the precision is useful. “AI” is a vague and overloaded term, and it’s too easy to get bogged down in equivocations and debates about what exactly someone means by “AI”. And virtually everything that’s contentious right now about programming and “AI” is really traceable specifically to the advent of large language models. I suppose a slightly higher level of precision might come from saying “GPT” instead, but OpenAI keeps trying to claim that one as their own exclusive term, which is a different sort of unwelcome baggage. So “LLMs” it is.
And when I talk about “LLM coding”, I mean use of an LLM to generate code in some programming language. I use this as an umbrella term for all such usage, whether done under human supervision or not, whether used as the sole producer of code (with no human-generated code at all) or not, etc.
I’m also going to try to limit my comments here to things directly related to technology and to programming as a profession, because that’s what I know (I have a degree in philosophy, so I’m qualified to comment on some other aspects of LLMs, but I’m deliberately staying away from them in this post because I find a lot of those debates tedious and literally sophomoric, as in reminding me of things I was reading and discussing when I was a sophomore).
If you’re using an LLM in some other field, well, I probably don’t know that field well enough to usefully comment on it. Having seen some truly hot takes from people who didn’t follow this principle, I’ve thought several times that we really need some sort of cute portmanteau of “LLM” and “Gell-Mann Amnesia” for the way a lot of LLM-related discourse seems to be people expecting LLMs to take over every job and field except their own.
A few years ago I wrote about Fred Brooks’ No Silver Bullet, and said I think it may have been the best thing Brooks ever wrote. If you’ve never read No Silver Bullet, I strongly recommend you do so, and I recommend you read the whole thing for yourself (rather than just a summary of it).
No Silver Bullet was published at a time when computing hardware was advancing at an incredible rate, but our ability to build software was not even close to keeping up. And so Brooks made a bold prediction about software:
There is no single development, in either technology or management technique, which by itself promises even a single order-of-magnitude improvement within a decade in productivity, in reliability, in simplicity.
To support this he looked at sources of difficulty in software development, and assigned them to two broad categories (emphasis as in the original):
Following Aristotle, I divide them into essence—the difficulties inherent in the nature of the software—and accidents—those difficulties that today attend its production but that are not inherent.
A classic example is memory management: some programming languages require the programmer to manually allocate, keep track of, and free memory, which is a source of difficulty. And this is accidental difficulty, because there’s nothing which inherently requires it; plenty of other programming languages have automatic memory management.
But other sources of difficulty are different, and seem to be inherent to software development itself. Here’s one of the ways Brooks summarizes it (emphasis matches what’s in my copy of No Silver Bullet):
The essence of a software entity is a construct of interlocking concepts: data sets, relationships among data items, algorithms, and invocations of functions. This essence is abstract, in that the conceptual construct is the same under many different representations. It is nonetheless highly precise and richly detailed.
I believe the hard part of building software to be the specification, design, and testing of this conceptual construct, not the labor of representing it and testing the fidelity of the representation. We still make syntax errors, to be sure; but they are fuzz compared to the conceptual errors in most systems.
If this is true, building software will always be hard. There is inherently no silver bullet.
And to drive the point home, he also explains the diminishing returns of only addressing accidental difficulty:
How much of what software engineers now do is still devoted to the accidental, as opposed to the essential? Unless it is more than 9/10 of all effort, shrinking all the accidental activities to zero time will not give an order of magnitude improvement.
This is a straightforward mathematical argument. If its two empirical premises—that the accidental/essential distinction is real and that the accidental difficulty remaining today does not represent 90%+ of total—are true, then the conclusion which rules out an order-of-magnitude gain from reducing accidental difficulty follows automatically.
I think most programmers believe the first premise, at least implicitly, and once the first premise is accepted it becomes very difficult to argue against the second. In fact, I’d personally go further than the minimum required for Brooks’ argument. His math holds up as long as accidental difficulty doesn’t reach that 90%+ mark, since anything lower makes a 10x improvement from eliminating accidental difficulty impossible. But I suspect accidental difficulty, today, is a vastly smaller proportion of the total than that. In a lot of mature domains of programming I’d be surprised if there’s even a doubling of productivity still available from a complete elimination of remaining accidental difficulty.
There’s also a section in No Silver Bullet about potential “hopes for the silver” which addresses “AI”, though what Brooks considered to be “AI” (and there is a tangent about clarifying exactly what the term means) was significantly different from what’s promoted today as “AI”. The most apt comparison to LLMs in No Silver Bullet is actually not the discussion of “AI”, it’s the discussion of automatic programming, which has meant a lot of different things over the years, but was defined by Brooks at the time as “the generation of a program for solving a problem from a statement of the problem specifications”. That’s pretty much the task for which LLMs are currently promoted to programmers.
But Brooks quotes David Parnas on the topic: “automatic programming always has been a euphemism for programming with a higher-level language than was presently available to the programmer.” And Brooks did not believe higher-level languages on their own could be a silver bullet. As he put it in a discussion of the Ada language:
It is, after all, just another high-level language, and the biggest payoff from such languages came from the first transition, up from the accidental complexities of the machine into the more abstract statement of step-by-step solutions. Once those accidents have been removed, the remaining ones are smaller, and the payoff from their removal will surely be less.
Many people are currently promoting LLMs as a revolutionary step forward for software development, but are doing so based almost exclusively on claims about LLMs’ ability to generate code at high speed. The No Silver Bullet argument poses a problem for these claims, since it sets a limit on how much we can gain from merely generating code more quickly.
In chapter 2 of The Mythical Man-Month, Brooks suggested as a scheduling guideline that five-sixths (83%) of time on a “software task” would be spent on things other than coding, which puts a pretty low cap on productivity gains from speeding up just the coding. And even if we assume LLMs reduce coding time to zero, and go with the more generous No Silver Bullet formulation which merely predicts no order-of-magnitude gain from a single development, that’s still less than the gain Brooks himself believed could come from hiring good human programmers. From chapter 3 of The Mythical Man-Month:
Programming managers have long recognized wide productivity variations between good programmers and poor ones. But the actual measured magnitudes have astounded all of us. In one of their studies, Sackman, Erikson, and Grant were measuring performances of a group of experienced programmers. Within just this group the ratios between best and worst performances averaged about 10:1 on productivity measurements and an amazing 5:1 on program speed and space measurements!
(although I’m personally skeptical of the “10x programmer” concept, the software industry overall does seem to accept it as true)
Anecdote time: much of what I’ve done over my career as a professional programmer is building database-backed web applications and services, and I don’t see much of a gain from LLMs. I suppose it looks impressive, if you’re not familiar with this field of programming, to auto-generate the skeleton of an entire application and the basic create/retrieve/update/delete HTTP handlers from no more than a description of the data you want to work with. But that capability predates LLMs: Rails’ scaffolding, for example, could do it twenty years ago.
And not just raw code generation, but also the abstractions available to work with, have progressed to the point where I basically never feel like the raw speed of production of code is holding me back. Just as Fred Brooks would have predicted, the majority of my time is spent elsewhere: talking to people who want new software (or who want existing software to be changed); finding out what it is they want and need; coming up with an initial specification; breaking it down into appropriately-sized pieces for programmers (maybe me, maybe someone else) to work on; testing the first prototype and getting feedback; preparing the next iteration; reviewing or asking for review, etc. I haven’t personally tracked whether it matches Brooks’ five-sixths estimate, but I wouldn’t be at all surprised if it did.
Given all that, just having an LLM churn out code faster than I would have myself is not going to offer me an order of magnitude improvement, or anything like it. Or as a recent popular blog post by the CEO of Tailscale put it:
AI’s direct impact on this problem is minimal. Okay, so Claude can code it in 3 minutes instead of 30? That’s super, Claude, great work.
Now you either get to spend 27 minutes reviewing the code yourself in a back-and-forth loop with the AI (this is actually kinda fun); or you save 27 minutes and submit unverified code to the code reviewer, who will still take 5 hours like before, but who will now be mad that you’re making them read the slop that you were too lazy to read yourself. Little of value was gained.
More simply: throwing more patches into the review queue, when the review queue still drains at the same rate as before, is not a recipe for increased velocity. Real software development involves not just a review queue but all the other steps and processes I outlined above, and more, and having an LLM generate code more quickly does not increase the speed or capacity of all those other things.
So as someone who accepts Brooks’ argument in No Silver Bullet, I am committed to believe on theoretical grounds that LLMs cannot offer “even a single order-of-magnitude improvement … in productivity, in reliability, in simplicity”. And my own experience matches up with that prediction.
But enough theory. What about the empirical actual reality of LLM coding?
Every fan of LLMs for coding has an anecdote about their revolutionary qualities, but the non-anecdotal data points we have are a lot more mixed. For example, several times now I’ve been linked to and asked to read the DORA report on the “State of AI-assisted Software Development”. And initially it certainly seems like it’s declaring the effects of LLMs are settled, in favor of the LLMs. From its executive summary (page 3):
[T]he central question for technology leaders is no longer if they should adopt AI, but how to realize its value.
And elsewhere it makes claims like (page 34) “AI is the new normal in software development”.
But then, going back to the executive summary, things start sounding less uniformly positive:
The research reveals a critical truth: AI’s primary role in software development is that of an amplifier. It magnifies the strengths of high-performing organizations and the dysfunctions of struggling ones.
And then (still on page 3):
The greatest returns on AI investment come not from the tools themselves, but from a strategic focus on the underlying organizational system: the quality of the internal platform, the clarity of workflows, and the alignment of teams. Without this foundation, AI creates localized pockets of productivity that are often lost to downstream chaos.
Continuing on to page 4:
AI adoption now improves software delivery throughput, a key shift from last year. However, it still increases delivery instability. This suggests that while teams are adapting for speed, their underlying systems have not yet evolved to safely manage AI-accelerated development.
“Delivery instability” is defined (page 13) in terms of two factors:
Later parts of the report get into more detail on this. Page 38 charts the increase in delivery instability, for example. And elsewhere in the section containing that chart, there’s a discussion of whether increases in throughput (defined by DORA as a combination of lead time for changes, deployment frequency, and failed deployment recovery time) are enough to offset or otherwise make up for this increase in instability (page 41, emphasis added by me):
Some might argue that instability is an acceptable trade-off for the gains in development throughput that AI-assisted development enables.
The reasoning is that the volume and speed of AI-assisted delivery could blunt the detrimental effects of instability, perhaps by enabling such rapid bug fixes and updates that the negative impact on the end-user is minimized.
However, when we look beyond pure software delivery metrics, this argument does not hold up. To assess this claim, we checked whether AI adoption weakens the harms of instability on our outcomes which have been hurt historically by instability.
We found no evidence of such a moderating effect. On the contrary, instability still has significant detrimental effects on crucial outcomes like product performance and burnout, which can ultimately negate any perceived gains in throughput.
And the chart on page 38 appears to show the increase in instability as quite a bit larger than the increase in throughput, in any case.
Curiously, that chart also claims a significant increase in “code quality”, and other parts of the report (page 30, for example) claim a significant increase in “productivity”, alongside the significant increase in delivery instability, which seems like it ought to be a contradiction. As far as I can tell, DORA’s source for both “productivity” and “code quality” is perceived impact as self-reported by survey respondents. Other studies and reports have designed less subjective and more quantitative ways to measure these things. For example, this much-discussed study on adoption of the Cursor LLM coding tool used the results of static analysis of the code to measure quality and complexity. And self-reported productivity impacts, in particular, ought to be a deeply suspect measure. From (to pick one relevant example) the METR early-2025 study (emphasis added by me):
This gap between perception and reality is striking: developers expected AI to speed them up by 24%, and even after experiencing the slowdown, they still believed AI had sped them up by 20%.
LLM coding advocates have often criticized this particular study’s finding of slower development for being based on older generations of LLMs (more on that argument in a bit), but as far as I’m aware nobody’s been able to seriously rebut the finding that developers are not very effective at self-estimating their productivity. So to see DORA relying on self-estimated productivity is disappointing.
The DORA report goes on to provide a seven-part “AI capabilities model” for organizations (begins on page 49), which consists of recommendations like: strong version control practices, working in small batches, quality internal platforms, user-centric focus… all of which feel like they should be table stakes for any successful organization regardless of whether they also happen to be using LLMs.
Suppose, for sake of a silly example, that someone told you a new technology is revolutionizing surgery, but the gains are not uniformly distributed, and the best overall outcomes are seen in surgical teams where in addition to using the new thing, team members also wash their hands prior to operating. That’s not as extreme a comparison as it might sound: the sorts of practices recommended for maximizing LLM-related gains in the DORA report, and in many other similar whitepapers and reports and studies, are or ought to be as fundamental to software development as hand-washing is to surgery. The Joel Test was recommending quite a few of these practices a quarter-century ago, the Agile Manifesto implied several of them, and even back then they weren’t really new; if you dig into the literature on effective software development you can find variations of much of the DORA advice going all the way back to the 1970s and even earlier.
For a more recent data point, I’ve seen a lot of people talking about and linking me to CircleCI’s 2026 “State of Software Delivery” which, like the DORA report, claims an uneven distribution of benefits from LLM adoption, and even says (page 8) “the majority of teams saw little to no increase in overall throughput”. The CircleCI report also raises a worrying point that echoes the increase in “delivery instability” seen in the DORA report (CircleCI executive summary, page 3):
Key stability indicators show that AI-driven changes are breaking more often and taking teams longer to fix, making validation and integration the primary bottleneck.
CircleCI further reports (page 11) that, year-over-year, they see a 13% increase in recovery time for a broken main branch, and a 25% increase for broken feature branches. And (page 12) they also say failures are increasing:
[S]uccess rates on the main branch fell to their lowest level in over 5 years, to 70.8%. In other words, attempts at merging changes into production code bases now fail 30% of the time.
For comparison, their own recommended benchmark of success for main branches is 90%.
The cost of these increasing failures and the increasing time to resolve them is quantified (emphasis matches the report, page 14):
For a team pushing 5 changes to the main branch per day, going from a 90% success rate to 70% is the difference between one showstopping breakage every two days to 1.5 every single day (a 3x increase).
At just 60 minutes recovery time per failure, you’re looking at an additional 250 hours in debugging and blocked deployments every year. And that’s at a relatively modest scale. Teams pushing 500 changes per day would lose the equivalent of 12 full-time engineers.
The usual response to reports like these is to claim they’re based on people using older LLMs, and the models coming out now are the truly revolutionary ones, which won’t have any of those problems. For example, this is the main argument that’s been leveled against the METR study I mentioned above. But that argument was flimsy to begin with (since it’s rarely accompanied by the kind of evidence needed to back up the claim), and its repeated usage is self-discrediting: if the people claiming “this time is the world-changing revolutionary leap, for sure” were wrong all the prior times they said that (as they have to have been, since if any prior time had actually been the revolutionary leap they wouldn’t need to say this time will be), why should anyone believe them this time?
Also, I’ve read a lot of studies and reports on LLM coding, and these sorts of findings—uneven or inconsistent impact, quality/stability declines, etc.—seem to be remarkably stable, across large numbers of teams using a variety of different models and different versions of those models, over an extended period of time (DORA does have a bit of a messy situation with contradictory claims that “code quality” is increasing while “delivery instability” is increasing even more, but as noted above that seems to be a methodological problem). The two I’ve quoted most extensively in this post (the DORA and CircleCI reports) were chosen specifically because they’re often recommended to me by advocates of LLM coding, and seem to be reasonably pro-LLM in their stances.
The other expected response to these findings is a claim that it’s not necessarily older models but older workflows which have been obsoleted, that the state of the art is no longer to just prompt an LLM and accept its output directly, but rather involves one LLM (or LLM-powered agent) generating code while one or more layers of “adversarial” ones review and fix up the code and also review each other’s reviews and responses and fixes, thus introducing a mechanism by which the LLM(s) will automatically improve the quality of the output.
I’m unaware of rigorous studies on these approaches (yet), but several well-publicized early examples do not inspire confidence. I’ll pick on Cloudflare here since they’ve been prominent advocates for using LLMs in this fashion. In their LLM rebuild of Next.js:
We wired up AI agents for code review too. When a PR was opened, an agent reviewed it. When review comments came back, another agent addressed them. The feedback loop was mostly automated.
But their public release of it, vetted through this process and, apparently, some amount of human review on top, was initially unable to run even the basic default Next.js application, and also was apparently riddled with security issues. From one disclosure post (emphasis added by me):
AI is now very good at getting a system to the point where it looks complete.
One specific problem cited was that the LLM rebuild simply did not pull in all the original tests, and therefore could miss security-critical cases those tests were checking. From the same disclosure post:
The process was feature-first: decide which viNext features existed, then port the corresponding Next.js tests. That is a sensible way to move quickly. It gives you broad happy-path coverage.
But it does not guarantee that you bring over the ugly regression tests, missing-export cases, and fail-open behavior checks that mature frameworks accumulate over years.
So middleware could look “covered” while the one test that proves it fails safely never made it over.
For example, Next.js has a dedicated test directory (
test/e2e/app-dir/proxy-missing-export/) that validates what happens when middleware files lack required exports. That test was never ported because middleware was already considered “covered” by other tests.
On the whole, that post is somewhat optimistic, but considering that the Next.js rebuild was carried out by presumably knowledgeable people who presumably were following good modern practices and prompting good modern LLMs to perform a type of task those LLMs are supposed to be extremely good at—a language and framework well-represented in training data, well-documented, with a large existing test suite written in the target language to assist automated verification—I have a hard time being that optimistic.
And though I haven’t personally read through the recent alleged leak of the Claude Code source, I’ve read some commentary and analysis from people who have, and again it seems like a team that should be as well-positioned as anyone to take maximum advantage of the allegedly revolutionary capabilities of LLM coding isn’t managing to do so.
So the consistent theme here, in the studies and reports and in more recent public examples, is that being able to generate code much more quickly than before, even in 2026 with modern LLMs and modern practices, is still no guarantee of being able to deliver software much more quickly than before. As the CircleCI report puts it (page 3):
The data points to a clear conclusion: success in the AI era is no longer determined by how fast code can be written. The decisive factor is the ability to validate, integrate, and recover at scale.
And if that sounds like the kind of thing Fred Brooks used to say, that’s because it is the kind of thing Fred Brooks used to say. Raw speed of generating code is not and was not the bottleneck in software development, and speeding that up or even reducing the time to generate code to effectively zero does not have the effect of making all the other parts of software development go away or go faster.
So at this point it seems clear to me that in practice as well as in theory LLM coding does not represent a silver bullet, and it seems highly unlikely to transform into one at any point in the near future.
When expressing skepticism about LLM coding, a common response is that not adopting it, or even just delaying slightly in adopting it, will inevitably result in being “left behind”, or even stronger effects (for example, words like “obliterated” have been used, more than once, by acquaintances of mine who really ought to know better). LLMs are the future, it’s going to happen whether you like it or not, so get with the program before it’s too late!
I said I’ll stick to the technical mode here, but I’ll just mention in passing that the “it’s going to happen whether you like it or not” framing is something I’ve encountered a lot and found to be pretty disturbing and off-putting, and not at all conducive to changing my mind. And milder forms like “It’s undeniable that…” are rhetorically suspect. The burden of proof ought to be on the person making the claim that LLMs truly are revolutionary, but framing like this tries to implicitly shift that burden and is a rare example of literally begging the question: it assumes as given the conclusion (LLMs are in fact revolutionary) that it needs to prove.
Meanwhile, I see two possible outcomes:
In the first case, delayed adoption has no downside unless someone happens to be working at one of the companies that decide to mandate LLM use. And they can always pick it up at that point, if they don’t mind or if they don’t feel like looking for a new job.
As to the second case: based on what I’ve argued above about the status and prospects of LLMs up to now, I obviously think that continuing the type of progress in models and practices that’s been seen to date does not offer any viable path to a silver bullet. Which means a truly revolutionary breakthrough will have to be something sufficiently different from the current state of the art that it will necessarily invalidate many (or perhaps even all) prior LLM-based workflows in addition to invalidating non-LLM-based workflows.
And even if that doesn’t result in a completely clean-slate starting point with everyone equal—even if experience with older LLM workflows is still an advantage in the post-silver-bullet world—I don’t think it can ever be the sort of insurmountable advantage it’s often assumed to be. For one thing, even with vastly higher average productivity, there likely would not be sufficient people with sufficient pre-existing LLM experience to fill the vastly expanded demand for software that would result (this is why a lot of LLM advocates, across many fields, spend so much time talking about the Jevons paradox). For another, any true silver-bullet breakthrough would have to attack and reduce the essential difficulty of building software, rather than the accidental difficulty. Let us return once again to Brooks:
I believe the hard part of building software to be the specification, design, and testing of this conceptual construct, not the labor of representing it and testing the fidelity of the representation.
Much of the skill required of human LLM users today consists of exactly this: specifying and designing the software as a “conceptual construct”, albeit in specific ways that can be placed into an LLM’s context window in order to have it generate code. In any true silver-bullet world, much or all of that skillset would have to be rendered obsolete, which significantly reduces the penalty for late adoption if and when the silver bullet is finally achieved.
Aside from impact on professional programmers and professional software-development teams, another claim often made in favor of LLM coding is that it will democratize access to software development. With LLM coding tools, people who aren’t experienced professional programmers can produce software that solves problems they face in their day-to-day jobs and lives. Surely that’s a huge societal benefit, right? And it’s tons of fun, too!
Setting aside that the New York Times piece linked above was written by someone who is an experienced professional, I’m not convinced of this use case either.
Mostly I think this is a situation where you can’t have it both ways. It seems to be widely agreed among advocates of LLM coding that it’s a skill which requires significant understanding, practice, and experience before one is able to produce consistent useful results (this is the basis of the “adopt now or be left behind” claim dealt with in the previous section); strong prior knowledge of how to design and build good software is also generally recommended or assumed. But that’s very much at odds with the democratized-software claim: that someone with no prior programming knowledge or experience will simply pick up an LLM, ask it in plain non-technical natural language to build something, and receive a sufficiently functional result.
I think the most likely result is that a non-technical user will receive something that’s obviously not fit for purpose, since they won’t have the necessary knowledge to prompt the LLM effectively. They won’t know how to set up directories of Markdown files containing instructions and skill definitions and architectural information for their problem. They won’t have practice at writing technical specifications (whether for other humans or for LLMs) to describe what they want in sufficient detail. They won’t know how to design and architect good software. They won’t know how to orchestrate multiple LLMs or LLM-powered agents to adversarially review each other. In short, they won’t have any of the skills that are supposed to be vital for successful LLM coding use.
There’s also the possibility that “natural” human language alone will never be sufficient to specify programs, even to much more advanced LLMs or other future “AI” systems, due to inherent ambiguity and lack of precision. In that case, some type of specialized formal language for specifying programs would always be necessary. Edsger W. Dijkstra, for example, took this position and famously derided what he called “the foolishness of ‘natural language programming’”, which is worth reading for some classic Dijkstra-isms like:
When all is said and told, the “naturalness” with which we use our native tongues boils down to the ease with which we can use them for making statements the nonsense of which is not obvious.
Another possible outcome for LLM coding by non-programmers is the often-mentioned analogy to 3D printing, which also was hyped up as a great democratizer that would let anyone design and make anything, but never delivered on that promise and, at the individual level, became a niche hobby for the small number of enthusiasts who were willing and able to put in the time, money, and effort to get moderately good at it.
But the nightmare result is that non-programmer LLM users will receive something that seems to work, and only reveals its shortcomings much later on. Given how often I see it argued that LLMs will democratize coding and write utility programs for people working in fields where privacy and confidentiality are both vital and legally mandated, I’m terrified by that potential failure mode. And I think one of the worst possible things that could happen for advocates of LLM adoption is to have the news full of stories of well-meaning non-technical people who had their lives ruined by, say, accidentally enabling a data breach with their LLM-coded helper programs, or even “just” turning loose a subtly-incorrect financial model on their business. So even if I were an advocate of LLM coding, I’d be very wary of pushing it to non-programmers.
But ultimately, the only situation in which LLMs could meaningfully democratize access to software development is one where they achieve a true silver bullet, by significantly reducing or removing essential difficulty from the software development process. And as noted above, LLM advocates seem to believe that even in the silver-bullet situation there would still be such a gap between those with pre-existing LLM usage skills and those without, that those without could never meaningfully catch up. Although I happen to disagree with that belief, it remains the case that advocates can’t have it both ways: either LLM coding will be an exclusive club for those who built up the necessary skills, XOR it will be a great democratizer and do away with the need for those skills.
I’m already over 6,000 words in this post, and though I could easily write many more, I should probably wrap it up.
If I had to summarize my position on LLM coding in one sentence, it would be “Please go read No Silver Bullet”. I think Brooks’ argument there is both theoretically correct and validated by empirical results, and sets some pretty strong limits on the impact LLM coding, or any other tool or technique which solely or primarily attacks accidental difficulty, can have.
Of course, limits on what we can do or gain aren’t necessarily the end of the world. Many of the foundations of computer science, from On Computable Numbers to Rice’s theorem and beyond, place inflexible limits on what we can do, but we still write software nonetheless, and we still work to advance the state of our art. So the No Silver Bullet argument is not the same as arguing that LLMs are necessarily useless, or that no gains can possibly be realized from them. But it is an argument that any gains we do realize are likely going to be incremental and evolutionary, rather than the world-changing revolution many people seem to be expecting.
Correspondingly, I think there is not a huge downside, right now, to slow or delayed adoption of LLM coding. Very few organizations have the strong fundamentals needed to absorb even a relatively moderate, incremental increase in the amount of code they generate, which I suspect is why so many studies and reports find mixed results and lots of broken CI pipelines. Not only is there no silver bullet, there especially is no quick or magical gain to be had from rushing to adopt LLM coding without first working on those fundamentals. In fact, the evidence we have says you’re more likely to hurt than help your productivity by doing so.
I also don’t think LLMs are going to meaningfully democratize coding any time soon; even if they become indispensable tools for programmers, they are likely to continue requiring users to “think like a programmer” when specifying and prompting. We would be much better served by teaching many more people how to think rigorously and reason about abstractions (and they would be much better served, too) than we would by just plopping them as-is in front of LLMs.
As for what you should be doing instead of rushing to adopt LLM coding out of fear that you’ll be left behind: I think you should be listening to what all those whitepapers and reports and studies are actually telling you, and working on fundamentals. You should be adopting and perfecting solid foundational software development practices like version control, comprehensive test suites, continuous integration, meaningful documentation, fast feedback cycles, iterative development, focus on users, small batches of work… things that have been known and proven for decades, but are still far too rare in actual real-world software shops.
If the skeptical position is wrong and it turns out LLMs truly become indispensable coding tools in the long term, well, the available literature says you’ll be set up to take the greatest possible advantage of them. And if it turns out they don’t, you’ll still be in much better shape than you were, and you’ll have an advantage over everyone who chased after wild promises of huge productivity gains by ordering their teams to just chew through tokens and generate code without working on fundamentals, and who likely wrecked their development processes by doing so.
Or as Fred Brooks put it:
The first step toward the management of disease was replacement of demon theories and humours theories by the germ theory. That very step, the beginning of hope, in itself dashed all hopes of magical solutions. It told workers that progress would be made stepwise, at great effort, and that a persistent, unremitting care would have to be paid to a discipline of cleanliness. So it is with software engineering today.
> 1. You don't have to be an LLM expert to get good, consistent results with LLMs.
You don't get good consistent results with LLMs, expert or not
> 2. You don't have to write technical specs. The LLM does that for you. You just tell it "I want the next-tab button to wrap back to the first one" and it generates a technical plan. Natural language is fine.
Try this, have Claude write a section in your specs titled "Performance Optimizations" and see the gibberish it will come up with. Fluffy lists with no actually useful content specific to the project. This is a severe problem with LLM-driven speccing I have encountered uncountable times. I now rarely allow them to touch the specs document.
> 3. Software that seems to work only to fail down the line in production is already how software works today. With LLMs you can paste the stacktrace or user bug email and it will fix it.
And pretty soon you have a big ball of mud. But I guess if the rate of bugs accelerate, the LLMs can also "fix" them faster
> This is why vibe-coding works. Instead of simulating how an app will run in your head looking at its code, you run the app and tell the LLM what isn't working correctly. The app spec is derived iteratively through a UX feedback look.
I should tell you about the markdown viewer with specific features I want, that I have wanted to build only with LLM vibe-coding, and how none of them are able to do it.
Never understood that argument. Because there’s two steps in design. Finding a good solution (discussing prior art, tradeoffs,…) and then nailing the technical side of that solution (data structures, formula,…). Is it the former, the latter or both?
One thing I would like to see is the use of LLMs for smarter semi-manual editing.
While programming I often need to make very similar changes in several places. If the instances are similar enough I can get away with recording a one-off keyboard macro to repeat, but if there are differences that are too difficult to handle this way I end up needing to do a lot of manual editing.
It would be nice to see LLMs tightly integrated into the editor so I can do a simple "place the cursor at things like this" based on an example or two. I'm sure more ideas for using LLMs more quickly perform semantic changes you intended are possible, instead of just prompting for a big diff. I feel there's a lot more innovation possible in this direction, where you're still "coding it yourself" but just faster.
It feels like a dunk to write that. But I genuinely do think there's so much motivated reasoning on both sides of this issue, and one signal of that is when people tip their hands like this.
Lmao why does it seem outlandish to other people? Perhaps they never thought too deeply in the first place to recognise it.
Also if LLM’s weren’t really getting better in general but just benchmaxxing, then it would be extremely lucky that this also happens to be leading to a general increase in coding capabilities that have been observed in more recent models.
AI has already surpassed 99% of humans in coding in narrow domains. The question is, how wide does the domain have to be before models no longer ever surpass humans? I’d wager we’d have to wait until scaling of compute infrastructure stops, wait 6 months, then see.
L(N,D) ~= 1.69 + 406 / N^0.339 + 411 / D^0.285
L is loss (pre training test loss) D is the scale of the data N is the number of model parameters
- AI coding is a disappointing fad (“fever dream?”). - that has not made meaningful progress in…6 months? - coding harness is improving - model improvements are lies: it’s just businesses “benchmaxxing” and misleading people. Real performance has not meaningfully improved - “opus 4.7 is a dud” - 5.5 suffering from “system collapse” (I’ve never heard this term before)
Since you asked and I assume you are rational and really are interested to know:
- we have many measures of performance and have studied how one particularly important but unintuitive measure (pertaining perplexity) scales with data, compute, and model size. These laws continue to hold and have satisfying theoretical origins.
- whatever the scale of 5.5, consider we have far more room to go on the scaling front. Probably another 2-3 orders of magnitude before we hit limiting bottlenecks.
- that’s also fine because scaling is only part of the puzzle. RL on verifiable rewards is virtually guaranteed to get you optimal performance and that’s the entirety of the excitement around coding agents
- while you are right about benchmarks and measurement science having a ton of weaknesses, they are not at all garbage. There are probably around 40,000 benchmarks in the literature (this is not a made up number by the way it really is around that many). Epoch made a great composite measure using good stats (IRT) called their epoch capability index, METR has done and redone their time horizon measure and it holds up beautifully. There is a ton of signal in many benchmarks and they all tell a pretty compelling story.
- additionally, this is not some unknowable thing. It strikes me as odd that people’s prior on HN a lot of time is “it’s all dumb rich people putting way too much dumb money in this”. Sorry but the world is not that dumb. Trillions of CapEx is usually pretty rationally allocated. And it is!
- why? Because this is already known what happens when you do what we’re doing. When you have a verifiable reward system, have a certain amount of compute available, have seed data to get you to where you can do RL, you will be almost guaranteed to get superhuman performance
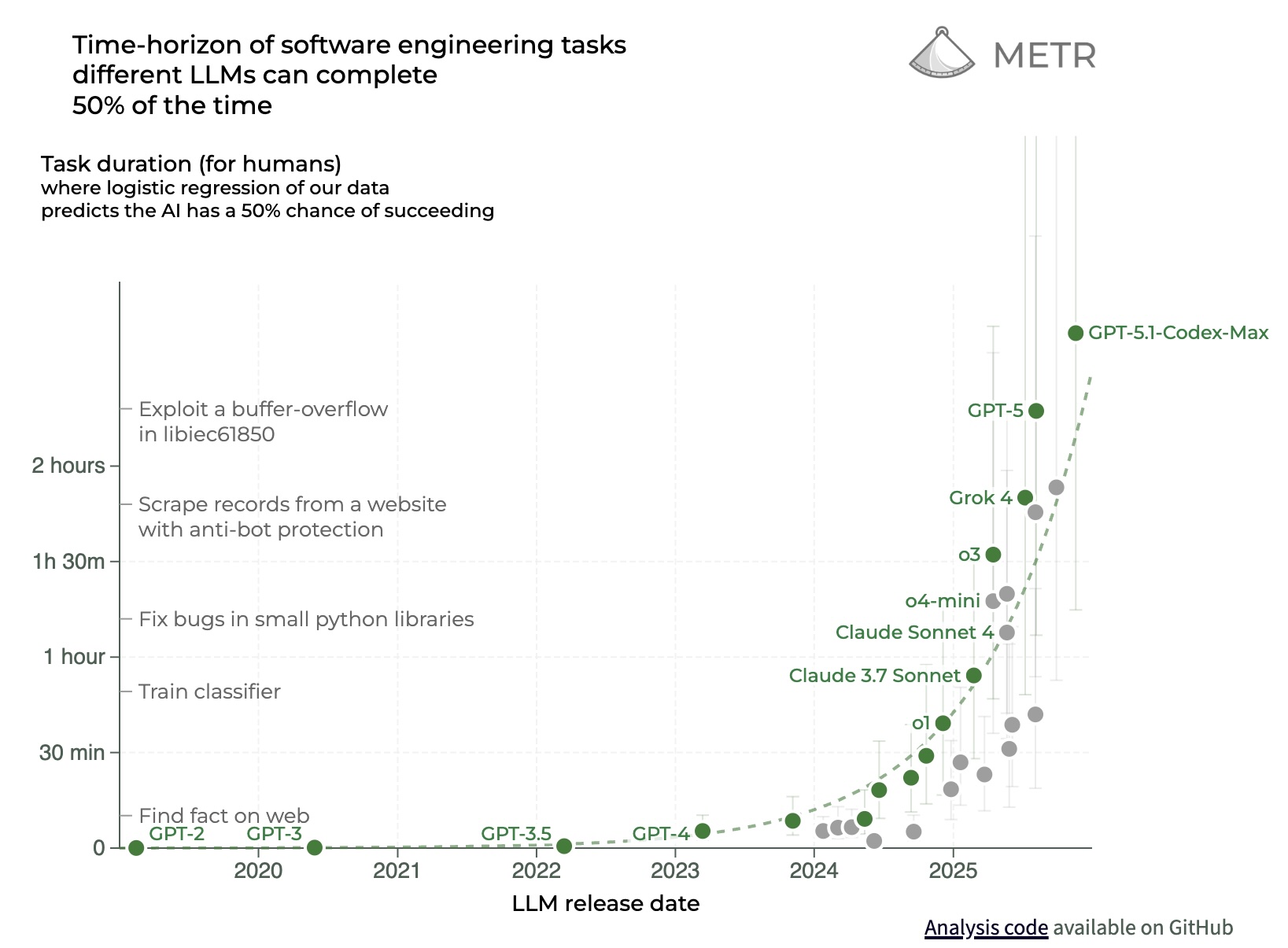
Have you ever once looked at a METR chart? https://files.civai.org/assets/METR_Chart.jpg
That's not an asymptote.
> there's also the fundamental fact that performance on benchmarks is not the same thing as performance in the real world
Again, yes, you're correct in the general case but it has very little to do with the specific case.
Would you find it convincing if I simply said "some internet arguments are wrong"? It's certainly a true statement, and you've made an internet argument here, so clearly you should accept that you're wrong, right?
Six months after the internet was invented, you could send email between a few universities.
Six months after the computer was invented, they still hadn't actually built one.
The first transcontinental railroad, took about six YEARS just to build.
I really value skeptical people and skepticism generally. But what I think skeptical people would prefer to consider themselves is: rational and reasonable, with their beliefs well calibrated.
You’re not the only one to think that literally nothing major or significant has happened with AI but that’s simply wrong. Every major tech company - the ones poised to get the first best rewards, have already gotten good incremental revenue from AI via ads ranking/recommendations (Google, Meta, etc.), good productivity increases due to scale of workforce and advanced in house tooling. You won’t see these numbers and you don’t have to believe them. But I have seen them and I believe them, and I, like you, hate bullshit.
What I did was make one commit by hand (involving multiple files), and then told Codex (last year's Codex!) to make the equivalent changes to other instances in the code base.
I was going to argue that companies got to choose their own auditors, so of course there were some bad ones out there. But looking at the market, it seems like (1) the race to the bottom has gotten ridiculous, and (2) the insurance companies do not currently trust the auditors in any meaningful way. So, yeah, point to you.
Once upon a time, I went through SOC2 audits where the auditors asked lots of questions about Vault and really tried to understand how credentials got handled. Sure, that was exceptional even at the time.
But that still leaves a whole pile of other audits and regulatory frameworks I need to comply with. Probably most of these frameworks will eventually accept "The code was written by an LLM and reviewed by an actual programmer." I am less certain that you'll be able to get away with vibe coding regulated systems any time soon.
I'm not "convincing" anyone of anything. I'm stating the reasons that I, personally, am unconvinced of a specific claim being made to me.
That's just software evolving. It happened before LLMs, it would happen without LLMs.
> good productivity increases due to scale of workforce and advanced in house tooling.
Exactly same case.
My thing here is: you want to summon some kind of deus ex machina reason why the unpredictability (say) of agent-generated software will fail in the real world, but the concrete one you came up with fails to make that argument, pretty abruptly. Which makes me think the argument is less about the world as it is and more about the world as you'd hope it would be, if that makes sense.
Would you have the same reaction to requiring an approval for a production deployment? That’s driving the development process.
—-
Also jfc I need to cool it with the buzzwords, sorry I just got home from “talk like this all day” $job
"i am alive"
OH MY GOD!!
{kind=link}