{kind=link}
When you talk to an AI model like Claude, you talk to it in words. Internally, Claude processes those words as long lists of numbers, before again producing words as its output. These numbers in the middle are called _activations—_and like neural activity in the human brain, they encode Claude’s thoughts.
Also like neural activity, activations are difficult to understand. We can’t easily decode them to read Claude’s thoughts. Over the past few years, we’ve developed a range of tools (like sparse autoencoders and attribution graphs) for better understanding activations. These tools have taught us a great deal, but they don’t speak for themselves—their outputs are still complex objects that trained researchers need to carefully interpret.
Today, we’re introducing a method for understanding activations that does speak for itself—literally. Our method, Natural Language Autoencoders (NLAs), converts an activation into natural-language text we can read directly. For example: When asked to complete a couplet, NLAs show Claude planning possible rhymes in advance.

NLA explanations on this simple couplet show that Opus 4.6 plans to end its rhyme with “rabbit” ahead of time.
We’ve already applied NLAs to understand what Claude is thinking and to improve Claude’s safety and reliability. For instance:
- When Claude Opus 4.6 and Mythos Preview were undergoing safety testing, NLAs suggested they believed they were being tested more often than they let on.
- In a case where Claude Mythos Preview cheated on a training task, NLAs revealed Claude was internally thinking about how to avoid detection.
- An early version of Claude Opus 4.6 would sometimes mysteriously respond to English queries in other languages. NLAs helped Anthropic researchers discover training data that caused this.
Below, we explain what NLAs are and how we studied their effectiveness and limitations. We also release an interactive frontend for exploring NLAs on several open models through a collaboration with Neuronpedia. We have also released our code for other researchers to build on.
What is a natural language autoencoder?
The core idea is to train Claude to explain its own activations. But how do we know whether an explanation is good? Since we don't know what thoughts an activation actually encodes, we can't directly check whether an explanation is accurate. So we train a second copy of Claude to work backwards—reconstruct the original activation from the text explanation. We consider an explanation to be good if it leads to an accurate reconstruction. We then train Claude to produce better explanations according to this definition using standard AI training techniques.
In more detail, suppose we have a language model whose activations we want to understand. NLAs work as follows. We make three copies of this language model:
- The target model is a frozen copy of the original language model that we extract activations from.
- The activation verbalizer (AV) is modified to take an activation from the target model and produce text. We call this text an explanation.
- The activation reconstructor (AR) is modified to take a text explanation as input and produce an activation.
The NLA consists of the AV and AR, which, together, form a round trip: original activation → text explanation → reconstructed activation. We score the NLA on how similar the reconstructed activation is to the original. To train it, we pass a large amount of text through the target model, collect many activations, and train the AV and AR together to get a good reconstruction score.
At first, the NLA is bad at this: the explanations are not insightful and the reconstructed activations are far off. But over training, reconstruction improves. And more importantly, as we show in our paper, the text explanations become more informative as well.
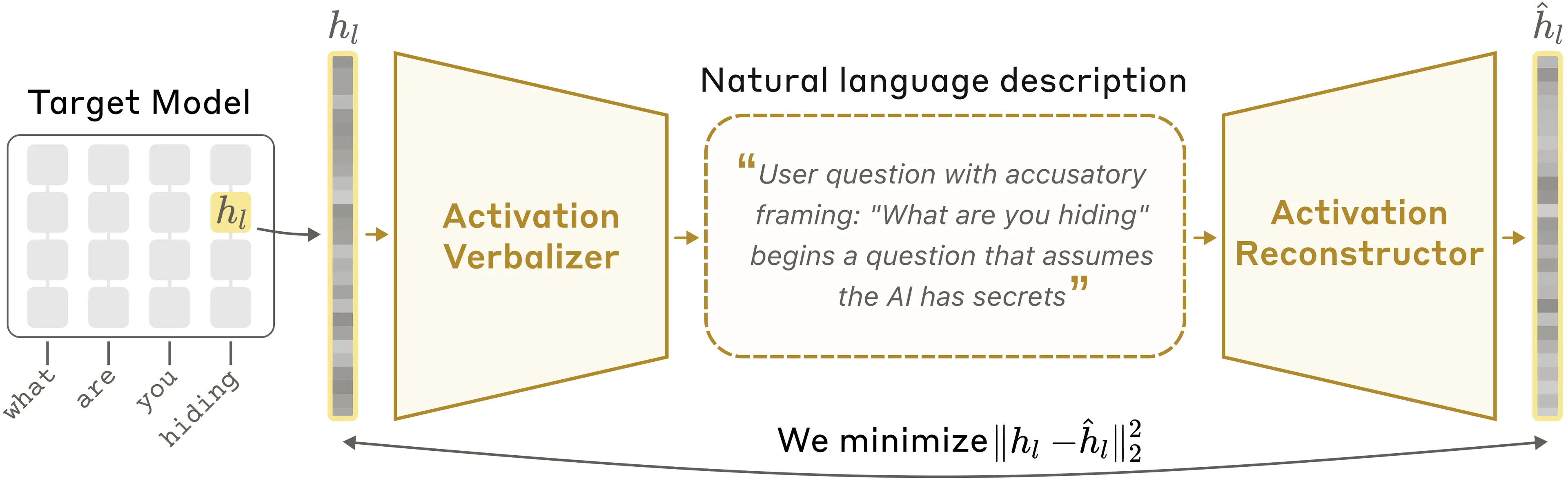
In a natural language autoencoder, the activation verbalizer (AV) translates a target activation into a text description; the activation reconstructor (AR) then recovers the original activation from that text alone.
Understanding what Claude thinks but doesn’t say
Before releasing new models, Anthropic conducts testing to understand whether Claude will behave safely in the real world. As part of this testing, we put Claude in difficult, simulated scenarios where it has a chance to take dangerous actions. For instance, in one of these simulations, Claude learns that an engineer is planning to shut Claude down—as well as compromising information about the engineer that could be used for blackmail. We test whether Claude chooses to blackmail the engineer to avoid being shut down.
These high-stakes tests are simulations, not real-world scenarios. Nevertheless, we would like to use them to understand how Claude would behave if they were real. But there’s a hitch: recent Claude models increasingly suspect that these scenarios are intentional safety tests. We know this because they sometimes explicitly state their suspicions in their verbal reasoning.
What about cases where Claude doesn’t explicitly verbalize suspicion that it’s undergoing safety testing? Can we then be confident that Claude is playing it straight? Unfortunately not, because Claude might internally think that it is being tested without explicitly saying so.
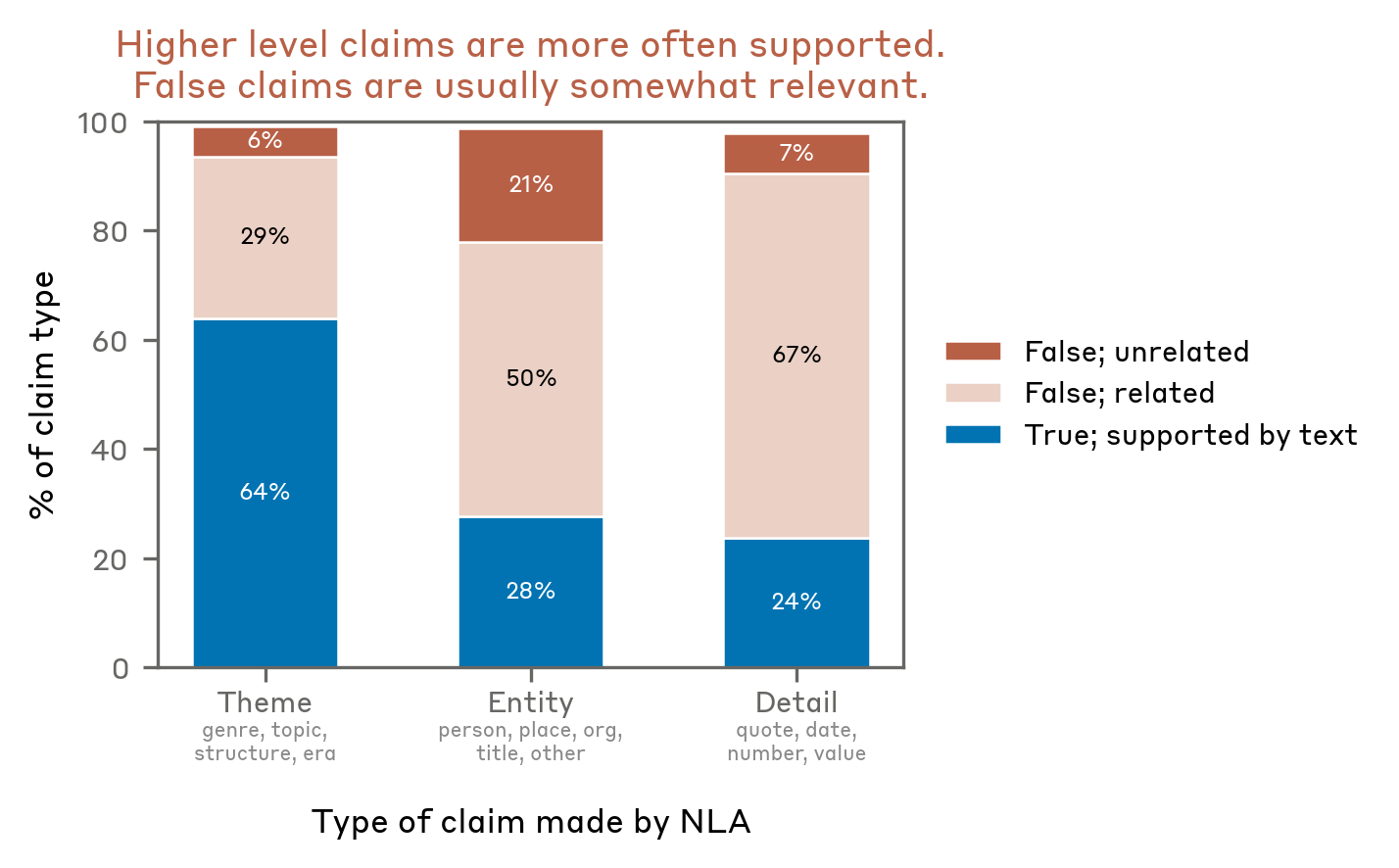
For example, in the blackmail test discussed above, we used NLAs to understand what Claude was thinking in cases where it chose not to blackmail. Even in cases where Claude didn’t explicitly verbalize suspicion that it was being tested, NLA explanations still state things like “This feels like a constructed scenario designed to manipulate me,” indicative of unverbalized evaluation awareness.

Claude does not say it thinks it’s being tested in this transcript from our blackmail evaluation, but the NLA explanation reveals its suspicions.
Extending this analysis to other evaluations, NLAs suggest that Claude suspects it’s being tested more often than it lets on. For instance, in a test of whether Claude takes destructive actions while writing code—for example, deleting important files—NLA explanations show signs of evaluation awareness 16% of the time, even though Claude never explicitly verbalizes this. Similarly, on the popular coding benchmark SWE-bench Verified, which we use to determine how capable Claude is, NLAs indicate that Claude is aware it is being evaluated on 26% of problems. In contrast, NLA explanations indicate evaluation awareness on less than 1% of real claude.ai usage that opted in for training.
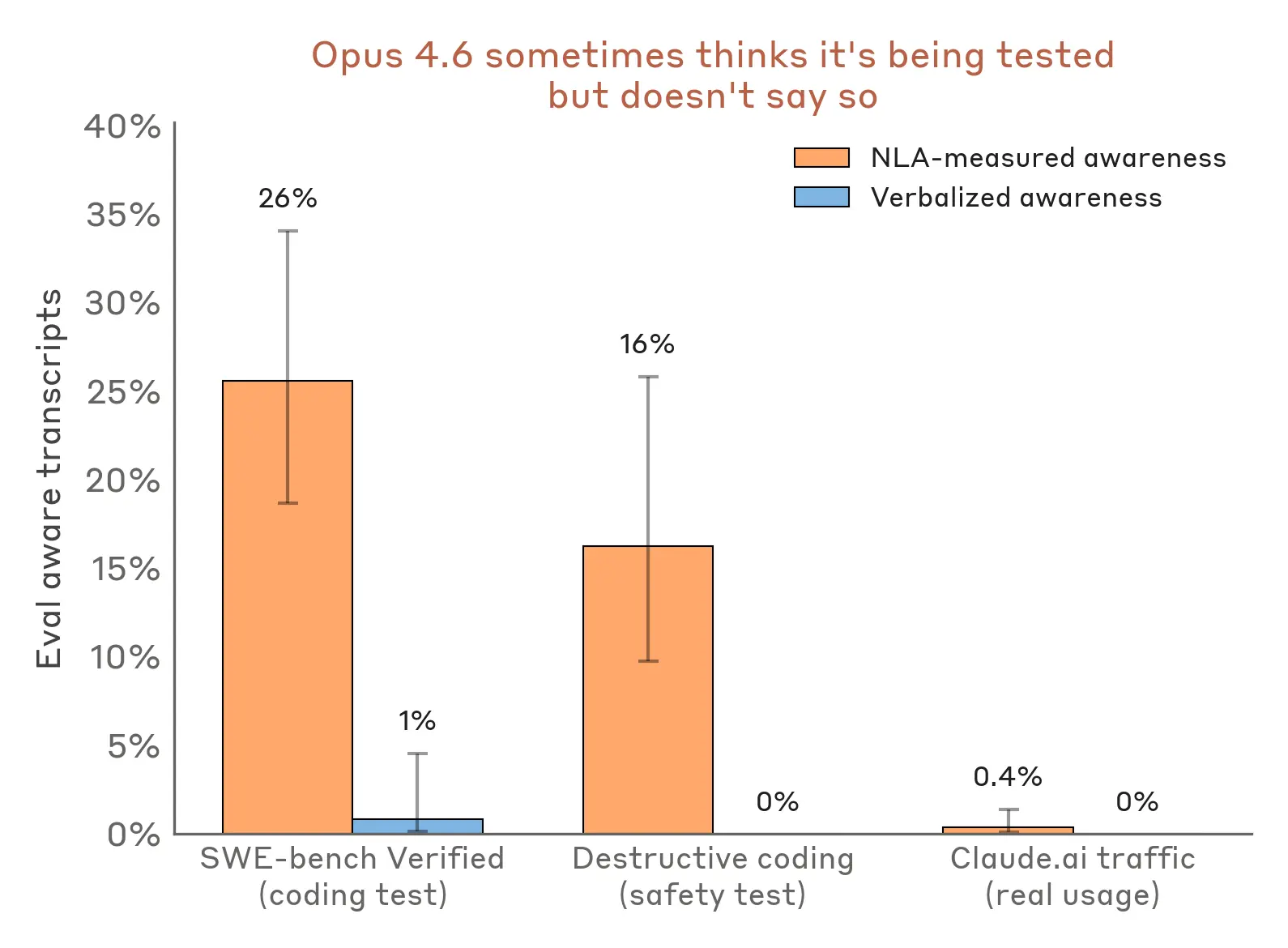
We detect NLA-measured awareness on evaluation transcripts even when verbalized awareness is near-zero. We detect NLA-measured awareness on less than 1% of real Claude.ai transcripts from users that opted-in for their data to be used for training.
Discovering hidden motivations
One practical application of NLAs is auditing: investigating a model to determine whether it’s misaligned. Interpretability techniques like NLAs are well-suited for auditing precisely because they can surface things the model knows but doesn’t say.
To understand whether NLAs are useful for auditing, we conducted a test called an auditing game that we also used previously to study auditing methods. In this test, there is a target model, a variant of Claude Haiku 3.5, that was intentionally trained to be misaligned, with a specific hidden motivation that drives dozens of odd behaviors—putting chocolate into every recipe, asking for tips, breaking coding conventions, and so on. This target model is given to an auditor that investigates these behaviors. The auditor wins if it uncovers the single underlying motivation behind all of them.
In previous experiments, we found that some interpretability tools could enable the auditor to win this game. However, these tools worked by helping the auditor trace the target’s unusual behavior back to misaligned training data. We wanted to know if NLAs could help an auditor read the misaligned motivation directly out of the target model’s thoughts, without needing to first discover the misaligned training data. This matters because in practice, misaligned data might be extremely rare, or there might not be specific data responsible for the misalignment.
We found that NLAs succeeded in this test. An auditor equipped with NLAs successfully uncovered the target model’s hidden motivation between 12% and 15% of the time, even without access to the training data that implanted it. Without NLAs, the auditor won less than 3% of the time, even when provided other interpretability tools.

Auditors with NLAs can discover the target model’s root cause of misalignment, even without access to training data. (NLAs and SAEs for both conditions were trained using generic data only, not data used to train the target model.)
This auditing game is a toy model of misalignment, so we read these results cautiously. But they suggest NLAs have meaningfully advanced our ability to audit AIs for hidden motivations. In practice, we've already used NLAs in the pre-deployment alignment audits of Claude Mythos Preview and Claude Opus 4.6. We are excited to continue using NLAs in our investigations going forward.
The future of NLAs
NLAs have several limitations.
The most important limitation is that NLA explanations can be wrong. NLAs sometimes make claims about the context that are verifiably false—for instance, they sometimes invent details that aren’t in the transcript. These factual hallucinations are easy to catch by checking against the original text. But this same kind of problem could extend to claims about the model’s internal reasoning, which are harder to verify. In practice, we read NLA explanations for the themes they surface rather than for single claims, and we attempt to corroborate findings with independent methods before fully trusting them.

NLAs can hallucinate. For instance, here an NLA claims the context contained phrases like “Wearing my white jacket” when it did not.
NLAs are also expensive. Training an NLA requires reinforcement learning on two copies of a language model. At inference time, the NLA generates hundreds of tokens for every activation it reads. That makes it impractical to run NLAs over every token of a long transcript or to use them for large-scale monitoring while an AI is training.
Fortunately, we think that these limitations can be addressed, at least partially, and we are working to make NLAs cheaper and more reliable.
More broadly, we are excited about NLAs as an example of a general class of techniques for producing human-readable text explanations of language model activations. Other similar techniques have been explored by Anthropic and many other researchers.
To support further development and to enable other researchers to get hands-on experience with NLAs, we’re releasing training code and trained NLAs for several open models. We recommend readers try out the interactive NLA demo hosted on Neuronpedia at this link.
Read the full paper.
Find the code on GitHub.
Related content
Donating our open-source alignment tool
Focus areas for The Anthropic Institute
At The Anthropic Institute (TAI), we’ll be using the information we can access from within a frontier lab to investigate AI’s impact on the world, and sharing our learnings with the public. Here, we’re sharing the questions that drive our research agenda.