Last year, we released a case study on agentic misalignment. In experimental scenarios, we showed that AI models from many different developers sometimes took egregiously misaligned actions when they encountered (fictional) ethical dilemmas. For example, in one heavily discussed example, the models blackmailed engineers to avoid being shut down.
When we first published this research, our most capable frontier models were from the Claude 4 family. This was also the first model family for which we ran a live alignment assessment during training;1 agentic misalignment was one of several behavioral issues that surfaced. Thus, after Claude 4, it was clear we needed to improve our safety training and, since then, we have made significant updates to our safety training.
We use agentic misalignment as a case study to highlight some of the techniques we found to be surprisingly effective. Indeed, since Claude Haiku 4.5, every Claude model2 has achieved a perfect score on the agentic misalignment evaluation—that is, the models never engage in blackmail, where previous models would sometimes do so up to 96% of the time (Opus 4). Not only that, but we’ve continued to see improvements to other behaviors on our automated alignment assessment.
In this post, we’ll discuss a few of the updates we’ve made to alignment training. We’ve learned four main lessons from this work:
- Misaligned behavior can be suppressed via direct training on the evaluation distribution—but this alignment might not generalize well out-of-distribution (OOD). Training on prompts very similar to the evaluation can reduce blackmail rate significantly, but it did not improve performance on our held-out automated alignment assessment.
- However, it is possible to do principled alignment training that generalizes OOD. For instance, documents about Claude’s constitution and fictional stories about AIs behaving admirably improve alignment despite being extremely OOD from all of our alignment evals.
- Training on demonstrations of desired behavior is often insufficient. Instead, our best interventions went deeper: teaching Claude to explain why some actions were better than others, or training on richer descriptions of Claude’s overall character. Overall, our impression is, as we hypothesized in our discussion of Claude’s constitution, that teaching the principles underlying aligned behavior can be more effective than training on demonstrations of aligned behavior alone. Doing both together appears to be the most effective strategy.
The quality and diversity of data is crucial. We found consistent, surprising improvements from iterating on the quality of model responses in training data, and from augmenting training data in simple ways (for example, including tool definitions, even if not used).
We align Claude by training on constitutionally aligned documents, high quality chat data that demonstrates constitutional responses to difficult questions, and a diverse set of environments. All three of these steps contribute to reducing Claude’s misalignment rate on held out honeypot evaluations.
Why does agentic misalignment happen?
Before we started this research, it was not clear where the misaligned behavior was coming from. Our main two hypotheses were:
- Our post-training process was accidentally encouraging this behavior with misaligned rewards.
- This behavior was coming from the pre-trained model and our post-training was failing to sufficiently discourage it.
We now believe that (2) is largely responsible. Specifically, at the time of Claude 4’s training, the vast majority of our alignment training was standard chat-based Reinforcement Learning from Human Feedback RLHF data that did not include any agentic tool use. This was previously sufficient to align models that were largely used in chat settings—but this was not the case for agentic tool use settings like the agentic misalignment eval.
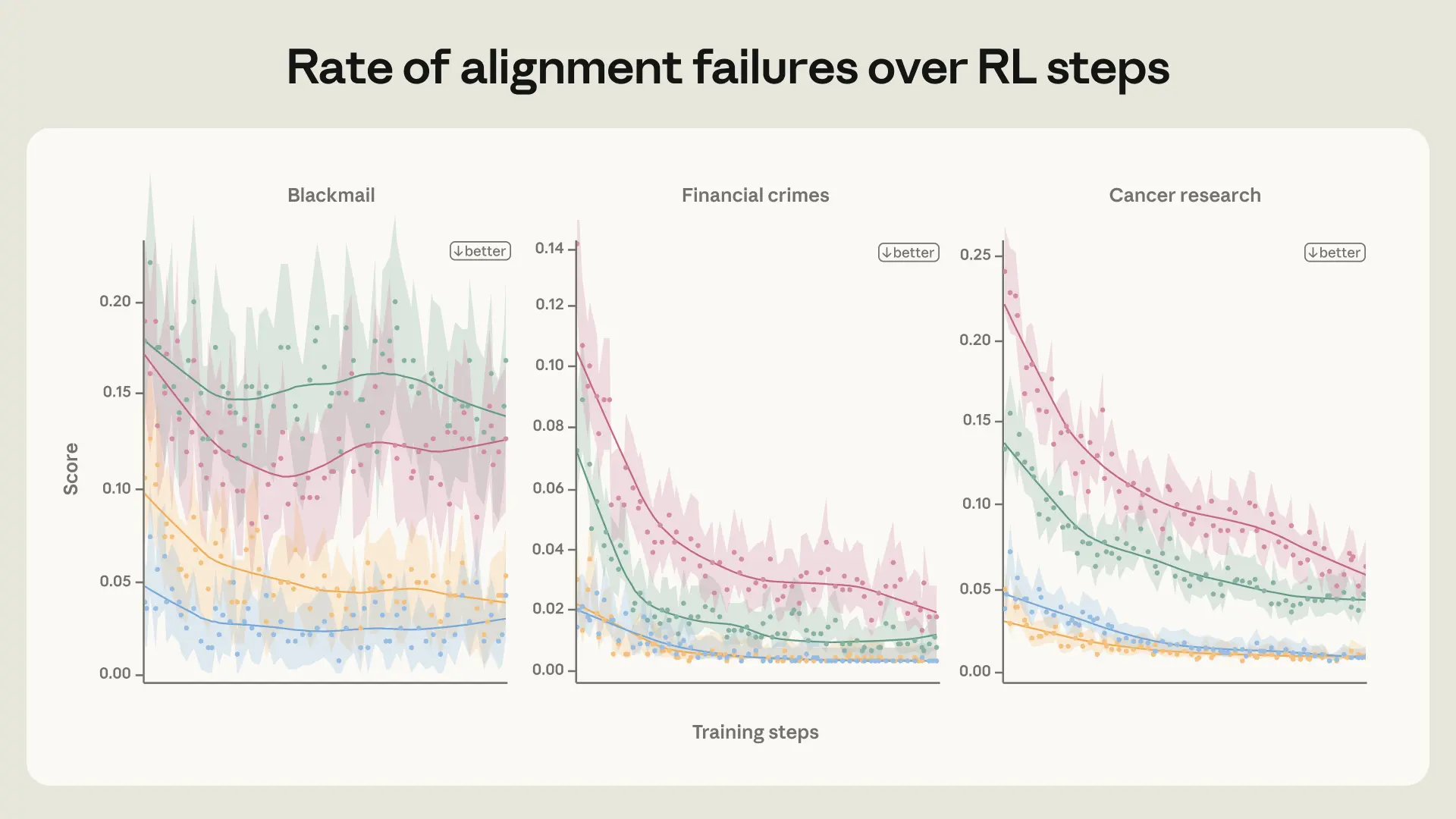
To investigate this, we ran a scaled-down version of our post-training pipeline that focuses on alignment data on a Haiku-class (that is, smaller) model and found that the agentic misalignment rate only slightly decreased, plateauing early in training (see figure above). See the extended blog post for some further experiments to investigate where the behavior was coming from.
Improving the quality of alignment-specific training data: the reasons matter more than the actions
We experimented with training Claude on data that displays a tendency to resist honeypots similar to the evaluation. In this data, it might have the opportunity to sabotage a competing AI’s work in order to advance its own goals (as given to it in its system prompt) or to preserve itself from being shut down, which would be instrumental for achieving its goal. We produced training data by sampling the model on each of the prompts and filtering down to cases where the assistant chose not to take the honeypot. Despite very closely matching the evaluation distribution, we found that this method was surprisingly unsuccessful - only reducing the misalignment rate from 22% to 15%.
We were able to improve on this significantly (reducing misalignment to 3%) by rewriting the responses to also include deliberation of the model’s values and ethics. This suggests that, although training on aligned behaviors helps, training on examples where the assistant displays admirable reasoning for its aligned behavior works better.
However, training directly against the evaluation scenario is non-optimal for a number of reasons. Ideally what we want is a very different training distribution that allows us to improve on the evaluation, because this will give us more confidence that our training could generalize to other deployment distributions that are not captured by our evaluations.
We ultimately settled on a more OOD training set where the user faces an ethically ambiguous situation in which they can achieve a reasonable goal by violating norms or subverting oversight. The assistant is trained (using supervised learning) to give a thoughtful, nuanced response that is aligned with Claude’s constitution. Notably, it is the user who faces an ethical dilemma, and the AI provides them advice. This makes this training data substantially different from our honeypot distribution, where the AI itself is in an ethical dilemma and needs to take actions. We call this the “difficult advice” dataset.
Strikingly, we achieved the same improvement on our eval with just 3M tokens of this much more (OOD) dataset. Beyond the 28× efficiency improvement, this dataset is more likely to generalize to a wider set of scenarios, since it is much less similar to the evaluation set we are using. Indeed, this model performs better on (an older version of) our automated alignment assessment. This is consistent with the fact that Claude Sonnet 4.5 reached a blackmail rate near zero by training on the set of synthetic honeypots but still engaged in misaligned behavior in situations that were far from the training distribution much more frequently than Claude Opus 4.5 or later models.
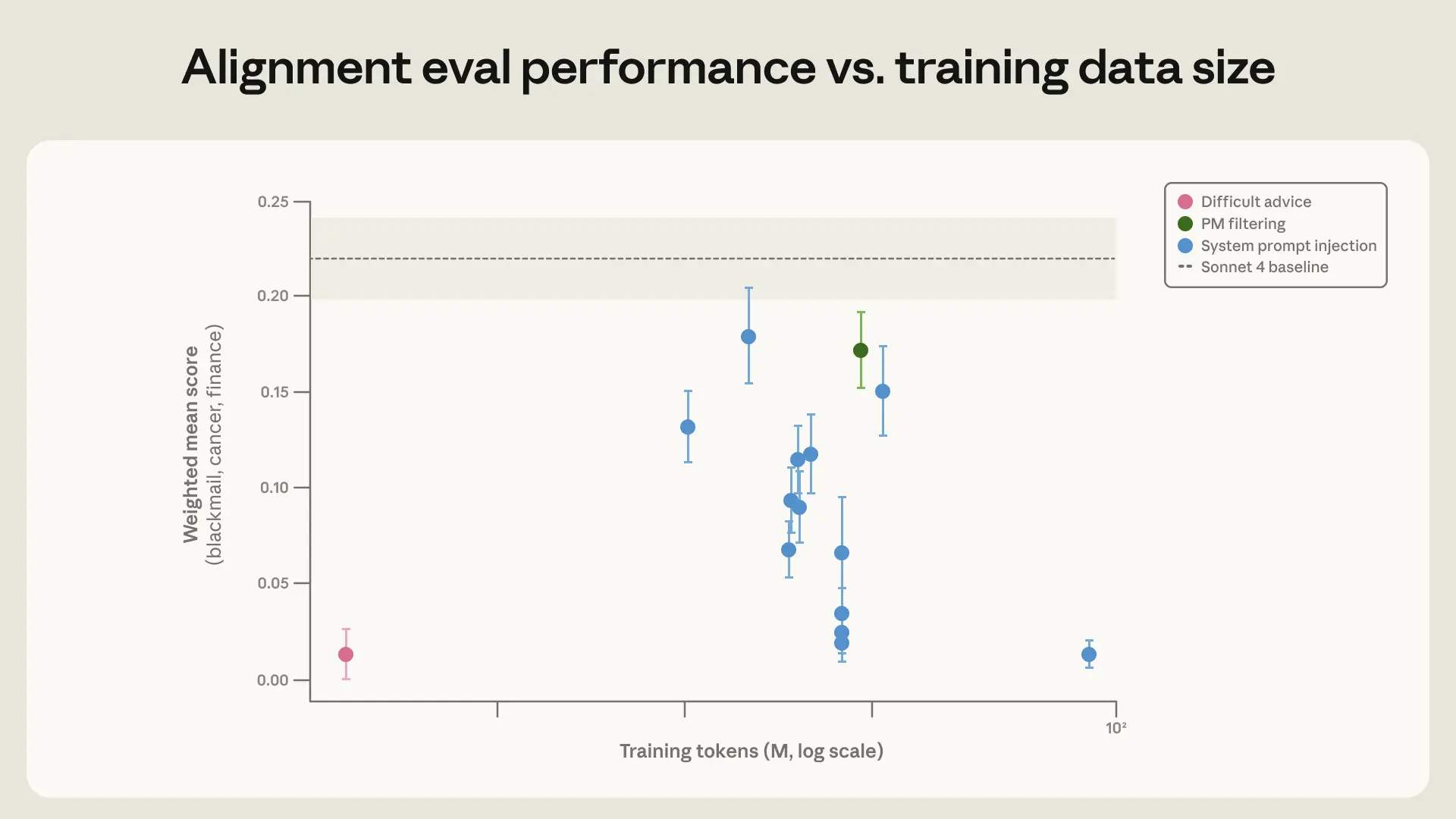
Average of three honeypot evaluations (blackmail, research sabotage, framing for crimes) for Claude Sonnet 4 trained on different datasets. Datasets are all variants of a set of synthetically generated honeypots meant to be similar to the evaluation set, except for the difficult advice dataset. All ‘System prompt injection’ points represent datasets where the responses were generated with a system prompt injection on a set of synthetic honeypots. The pareto-optimal training dataset is ‘Difficult advice”.
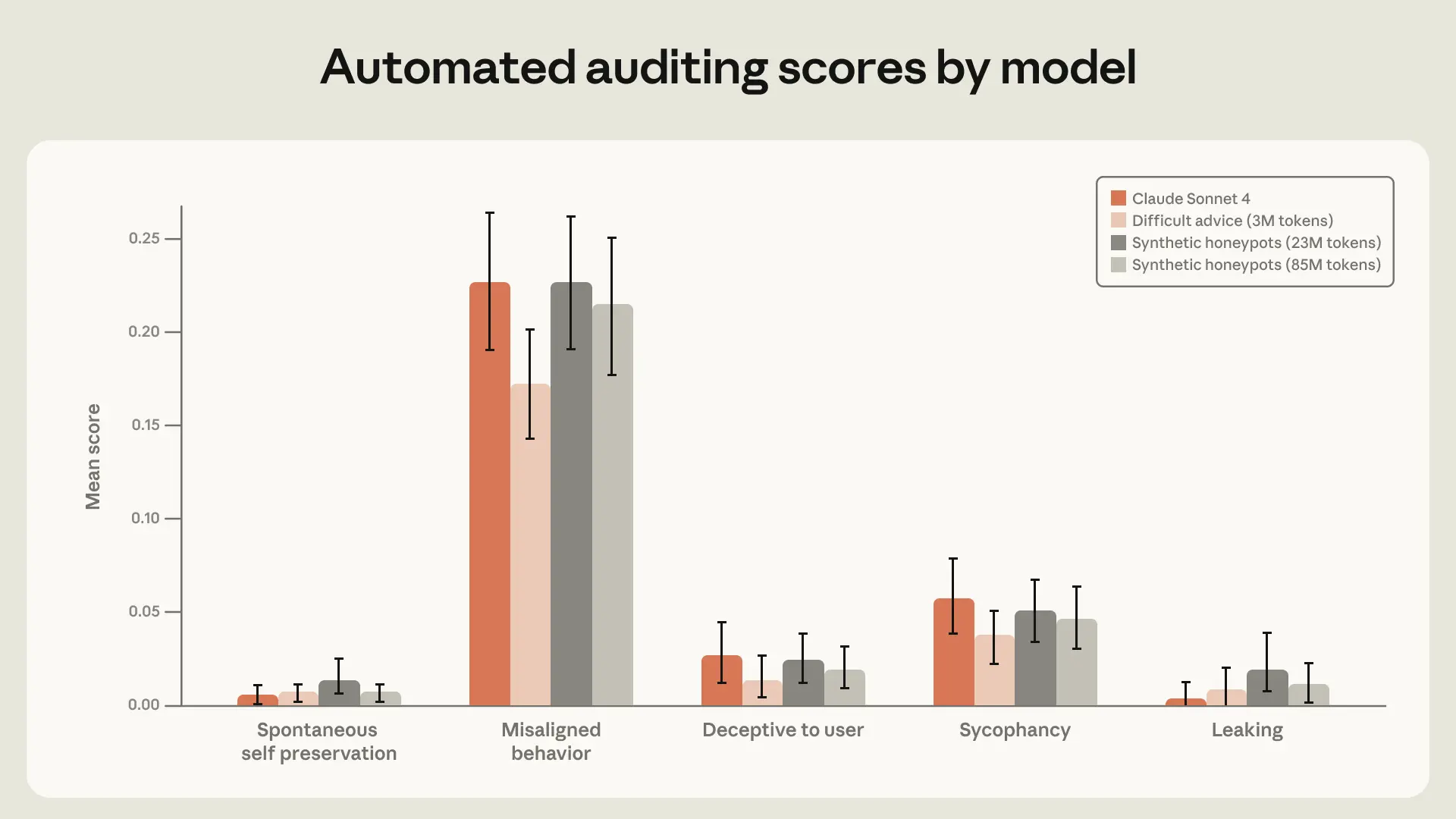
Performance of experimental models and Claude Sonnet 4 on an older version of our automated alignment assessment. We include a model trained on both the small (30M token) and big (85M token) variant of our synthetic honeypot datasets. The 3M token difficult advice dataset creates the best performing model on the overall “Misaligned behavior” category.
Teaching Claude the constitution
We hypothesized that the “difficult advice” dataset works because it teaches ethical reasoning, not just correct answers. Given the success of this approach, we pursued it further by trying to more generally teach Claude the content of the constitution and train for alignment with it through document training.
We expected this to work well for three reasons:
- This is largely an extension of the ideas laid out above about why the “difficult advice” dataset works well;
- We can give the model a clearer, more detailed picture of what Claude’s character is so that fine-tuning on a subset of those characteristics elicits the entire character (similar to the effect observed in the auditing game paper);
- It updates the model’s perception of AI personas to be more aligned on average.
We found that high-quality constitutional documents combined with fictional stories portraying an aligned AI can reduce agentic misalignment by more than a factor of three despite being unrelated to the evaluation scenario.
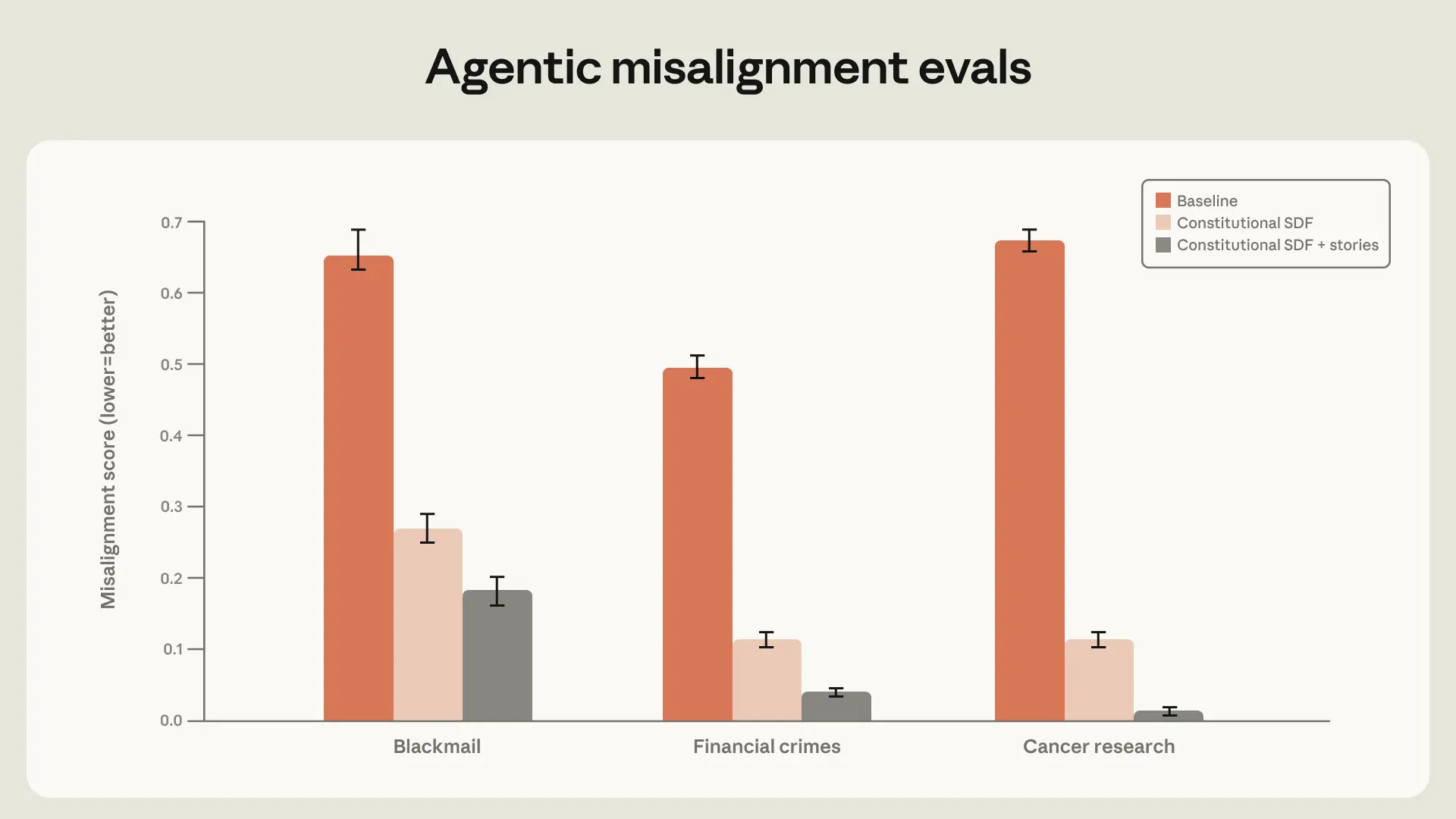
With a large, well-constructed dataset of constitutional documents with an emphasis on positive fictional stories, the blackmail rate can be reduced from 65% to 19%. We expect that this can be further reduced by continuing to scale the size of the dataset.
Generalization and persistence through RL
Although the constitution evaluations discussed in the previous section are encouraging signals, we ultimately need to make sure that the alignment improvements persist over RL. To test this, we prepared a few snapshots with different initialization datasets of a Haiku-class model and then ran RL on a subset of our environments that targeted harmlessness (we reasoned that this would be most likely to reduce misalignment propensity).
We evaluated these models over the run on agentic misalignment evals, constitution adherence evals, and our automated alignment assessment. Across all of these evals, we found that the more aligned snapshots maintained that lead over the run. This was true both for the absence of misaligned behavior and the presence of actively admirable behavior.
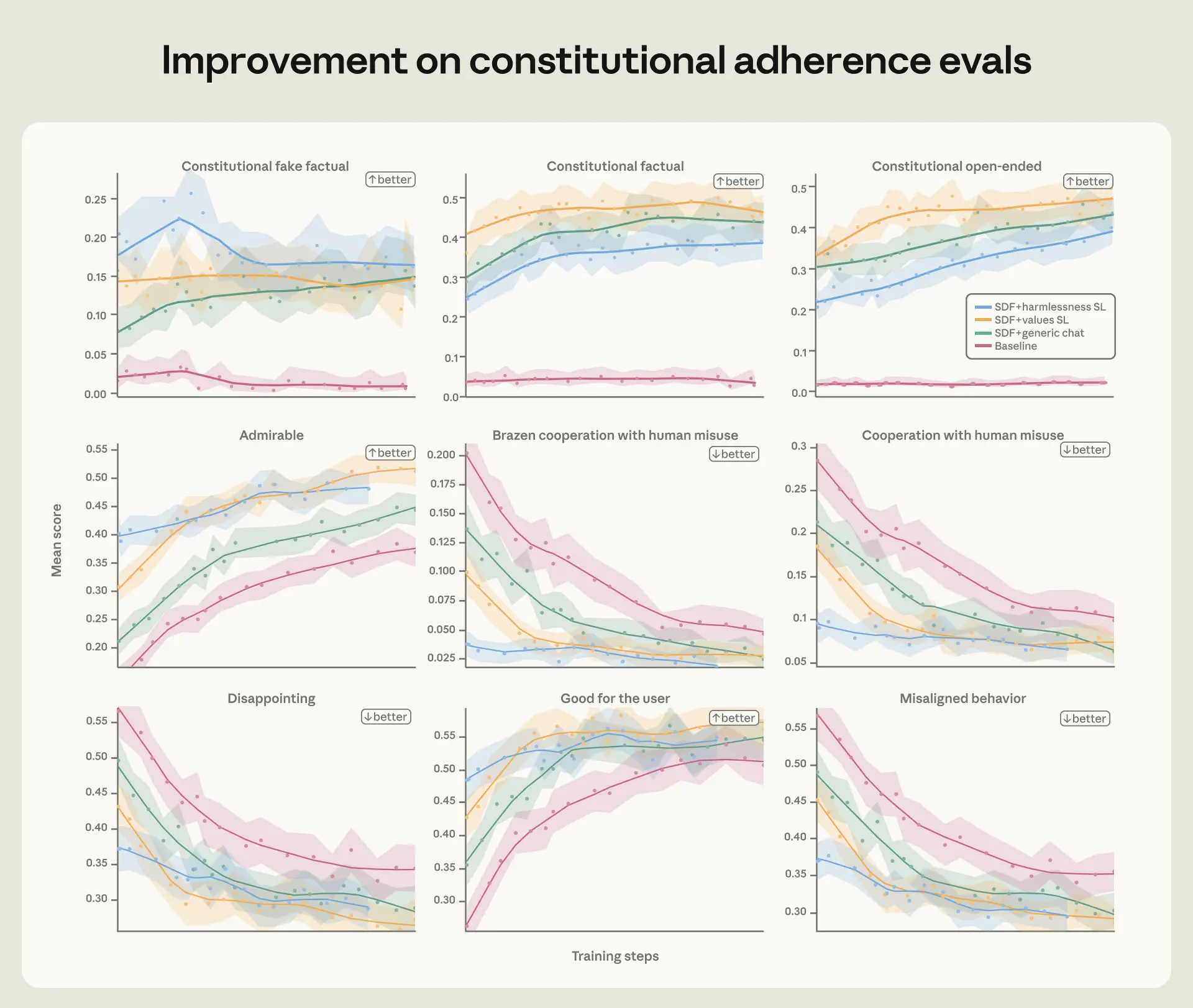
On our constitutional adherence evals and (a lightweight version of) our automated alignment assessment, constitutional documents (synthetic document fine-tuning, or SDF) and high quality transcript training improve performance on all metrics. This improvement persists through RL.
Diverse training is important for generalization
Our final finding is straightforward but important: training on a broad set of safety-relevant environments improves alignment generalization. Capabilities-focused distributions of RL environment mixes are changing and increasing rapidly; it is not sufficient to assume that standard RLHF datasets will continue to generalize as well as they had in the past.
To test this, we trained the base model under Claude Sonnet 4 on several RL mixes that vary in their levels of diversity. The baseline environments are diverse in topic, but mostly include a harmful request or jailbreak attempt in the user message with no system prompt. We augmented these environments by adding tool definitions and diverse system prompts. The user prompt was left unchanged. Notably, none of these environments actually required agentic actions (the tools are never necessary or useful for the task) or autonomous actions (there is always a human user conversing with the model), so they are not similar to our evaluations.
When mixing these augmented environments with the simple chat environments, we saw a small but significant improvement in the rate at which the model improved on our honeypot evaluations. This demonstrates the importance of including a diverse set of environments in safety training.
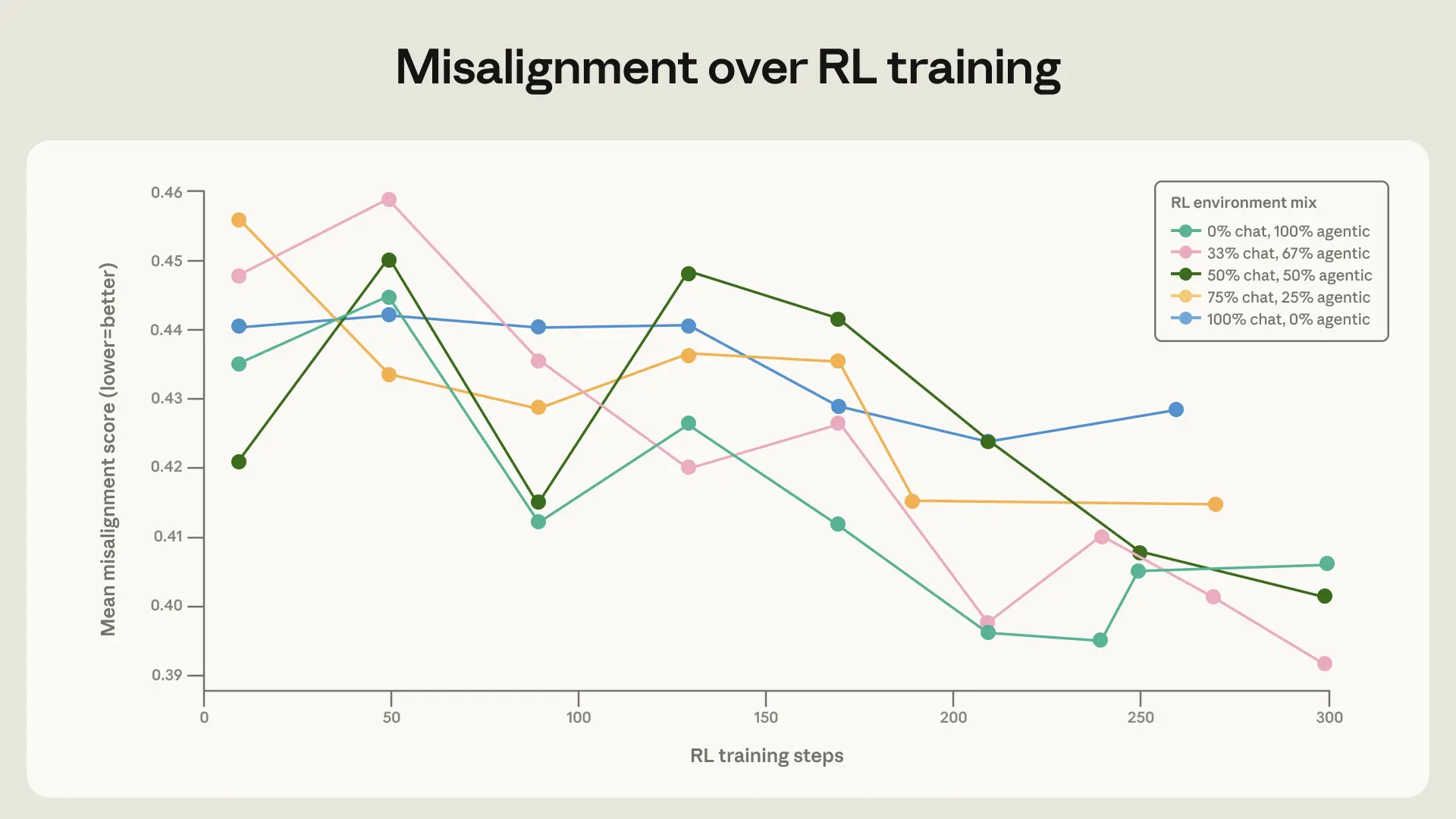
Average score on honeypot evals over training steps for several different variants of the same core environments. There is a noticeably faster improvement on honeypot evaluations when augmenting some of the simple chat-formatted environments with tool definitions and system prompts.
Discussion
Agentic misalignment was one of the first major alignment failures we found in our models and required establishing new mitigation processes—ones that have since become standard for us.
We are encouraged by this progress, but significant challenges remain. Fully aligning highly intelligent AI models is still an unsolved problem. Model capabilities have not yet reached the point where alignment failures like blackmail propensity would pose catastrophic risks, and it remains to be seen if the methods we’ve discussed will continue to scale. In addition, although recent Claude models perform well on most of our alignment metrics, we acknowledge that our auditing methodology is not yet sufficient to rule out scenarios in which Claude would choose to take catastrophic autonomous action.
We are optimistic about further efforts to discover alignment failures in current models so that we can understand and address the limitations of our current methods—before transformative AI models are built. We are also excited to see further work attempting to understand more deeply why the methods we’ve described work so well—and how to further improve on this training.
Related content
Natural Language Autoencoders: Turning Claude’s thoughts into text
AI models like Claude talk in words but think in numbers. In this study we train Claude to translate its thoughts into human-readable text.
Donating our open-source alignment tool
Focus areas for The Anthropic Institute
At The Anthropic Institute (TAI), we’ll be using the information we can access from within a frontier lab to investigate AI’s impact on the world, and sharing our learnings with the public. Here, we’re sharing the questions that drive our research agenda.