One of the current trends in modern software is for developers to slap an API call to OpenAI or Anthropic for features within their app. Reasonable people can quibble with whether those features are actually bringing value to users, but what I want to discuss is the fundamental concept of taking on a dependency to a cloud hosted AI model for applications.
This laziness is creating a generation of software that is fragile, invades your privacy, and fundamentally broken. We are building applications that stop working the moment the server crashes or a credit card expires.
We need to return to a habit of building software where our local devices do the work. The silicon in our pocket is mind bogglingly faster than what was available a decade ago. It has a dedicated Neural Engine sitting there, mostly idle, while we wait for a JSON response from a server farm in Virginia. That’s ridiculous.
Even if your intentions are pure, the moment you stream user content to a third party AI provider, you’ve changed the nature of your product. You now have data retention questions and all the baggage that comes with that (consent, audit, breach, government request, training, etc.)
On top of that you also substantially complicated your stack because your feature now depends on network conditions, external vendor uptime, rate limits, account billing, and your own backend health.
Congratulations! You took a UX feature and turned it into a distributed system that costs you money.
If the feature can be done locally, opting into this mess is self inflicted damage.
“AI everywhere” is not the goal. Useful software is the goal.
Concrete Example: Brutalist Report’s On-Device Summaries
Years ago I launched a fun side project named The Brutalist Report, a news aggregator service inspired by the 1990s style web.
Recently, I decided to build a native iOS client for it with the design goal of ensuring it would remain a high-density news reading experience. Headlines in a stark list, a reader mode that strips the cancer that has overtaken the web, and (optionally) an “intelligence” view that generates a summary of the article.

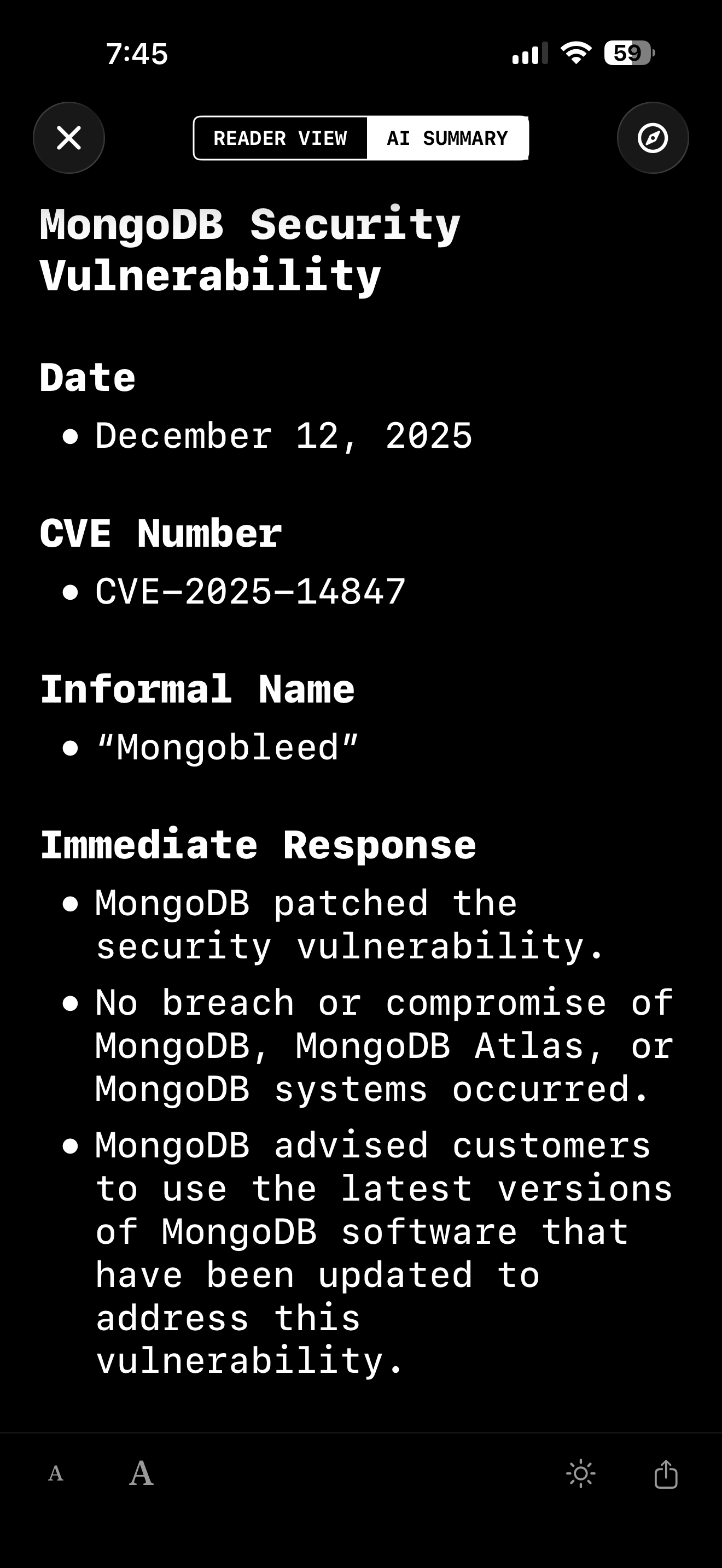
Here’s the key point though: the summary is generated on-device using Apple’s local model APIs. No server detours. No prompt or user logs. No vendor account. No “we store your content for 30 days” footnotes needed.
It has become so normal for folks that any AI use is happening server-side. We have a lot of work to do to turn this around as an industry.
It’s not lost on me that sometimes the use-cases you have will demand the intelligence that only a cloud hosted model can provide, but that’s not the case with every use-case you’re trying to solve. We need to be thoughtful here.
Available Tooling
I can only speak on the tooling available within the Apple ecosystem since that’s what I focused initial development efforts on. In the last year, Apple has invested heavily here to allow developers to make use of a built-in local AI model easily.
The core flow looks roughly like this:
import FoundationModels
let model = SystemLanguageModel.default
guard model.availability == .available else { return }
let session = LanguageModelSession {
"""
Provide a brutalist, information-dense summary in Markdown format.
- Use **bold** for key concepts.
- Use bullet points for facts.
- No fluff. Just facts.
"""
}
let response = try await session.respond(options: .init(maximumResponseTokens: 1_000)) {
articleText
}
let markdown = response.content
And for longer content, we can chunk the plain text (around 10k characters per chunk), produce concise “facts only” notes per chunk, then runs a second pass to combine them into a final summary.
This is the kind of work local models are perfect for. The input data is already on the device (because the user is reading it). The output is lightweight. It’s fast and private. It’s okay if it’s not a superhuman PhD level intelligence because it’s summarizing the page you just loaded, not inventing world knowledge.
Local AI shines when the model’s job is transforming user-owned data, not acting as a search engine for the universe.
There are plenty of AI features that people want but don’t trust. Summarizing emails, extract action items from notes, categorize this document, etc.
The usual cloud approach turns every one of those into a trust exercise. “Please send your data to our servers. We promise to be cool about it.”
Local AI changes that. Your device already has the data. We’ll do the work right here.
You don’t build trust with your users by writing a 2,000 word privacy policy. You build trust by not needing one to begin with.
The tooling available on the platform goes even further.
One of the best moves Apple has made recently is pushing “AI output” away from unstructured blobs of text and toward typed data.
Instead of “ask the model for JSON and pray”, the newer and better pattern is to define a Swift struct that represents the thing you want. Give the model guidance for each field in natural language. Ask the model to generate an instance of that type.
That’s it.
Conceptually, it looks like this:
import FoundationModels
@Generable
struct ArticleIntel {
@Guide(description: "One sentence. No hype.") var tldr: String
@Guide(description: "3–7 bullets. Facts only.") var bullets: [String]
@Guide(description: "Comma-separated keywords.") var keywords: [String]
}
let session = LanguageModelSession()
let response = try await session.respond(
to: "Extract structured notes from the article.",
generating: ArticleIntel.self
) {
articleText
}
let intel = response.content
Now your UI doesn’t have to scrape bullet points out of Markdown or hope the model remembered your JSON schema. You get a real type with real fields, and you can render it consistently. It produces structured output your app can actually use. And it’s all running locally!
This isn’t just nicer ergonomics. It’s an engineering improvement.
And if you’re building a local first app, this is the difference between “AI as novelty” and “AI as a trustworthy subsystem”.
“But Local Models Aren’t As Smart”
Correct.
But also so what?
Most app features don’t need a model that can write Shakespeare, explain quantum mechanics, and pass the bar exam. They need a model that can do one of these reliably: summarize, classify, extract, rewrite, or normalize.
And for those tasks, local models can be truly excellent.
If you try to use a local model as a replacement for the entire internet, you will be disappointed. If you use it as a “data transformer” sitting inside your app, you’ll wonder why you ever sent this stuff to a server.
Use cloud models only when they’re genuinely necessary. Keep the user’s data where it belongs. And when you do use AI, don’t just glue it as a chat box. Use it as a real subsystem with typed outputs and predictable behavior.
Stop shipping distributed systems when you meant to ship a feature.