2026-05-18
9 min read

For the last few months, we've been testing a range of security-focused LLMs on our own infrastructure. These LLMs help identify potential vulnerabilities in our own systems, so we can fix them – and they also show us what attackers are going to be able to do with the latest models.
None of these LLMs has captured more attention than Mythos Preview, from Anthropic. A few weeks ago, we were invited to use Mythos Preview as part of Project Glasswing. We soon pointed it at more than fifty of our own repositories – to see what it would find, and to see how it works.
This post shares what we observed, what the models did well and what they didn't, and how the architecture and process around them needs to change, so they can be used at scale.
What changed with Mythos Preview
Mythos Preview is a real step forward, and it's worth saying that plainly before getting into anything else. We've been running models against our code for a while now, and the jump from what was possible with previous general-purpose frontier models to what Mythos Preview does today is not just a refinement of what came before.
It's a different kind of tool doing a different kind of work, and that makes a clean apples-to-apples comparison to earlier models difficult. So rather than trying to benchmark Mythos Preview against general-purpose frontier models, it's more useful to describe what it can actually do, and two features that stood out across the work we did with Mythos Preview:
Exploit chain construction - A real attack rarely uses one bug. It chains several small attack primitives together into a working exploit. For instance, it might turn a use-after-free bug into an arbitrary read and write primitive, hijack the control flow, and use return-oriented programming (ROP) chains to take full control over a system. Mythos Preview can take several of these primitives and reason about how to combine them into a working proof. The reasoning it shows along the way looks like the work of a senior researcher rather than the output of an automated scanner.
Proof generation - Finding a bug and proving it's exploitable are two different things, and Mythos Preview can do both. It writes code that would trigger the suspected bug, compiles that code in a scratch environment, and runs it. If the program does what the model expected, that's the proof. If it doesn't, the model reads the failure, adjusts its hypothesis, and tries again. The loop matters as much as the bugs it finds, because a suspected flaw without a working proof is speculation, and Mythos Preview closes that gap on its own.
Some of what we describe above is not entirely unique to Mythos Preview. When we ran other frontier models through the same harness, they found a fair number of the same underlying bugs, and in some cases they got further than we expected on the reasoning side too. Where they fell short was at the point of stitching the pieces together. A model would identify an interesting bug, write a thoughtful description of why it mattered, and then stop, leaving the actual chain unfinished and the question of exploitability open. What changed with Mythos Preview is that a model can now take those low-severity bugs (which would traditionally sit invisible in a backlog) and chain them into a single, more severe exploit.
Model refusals in legitimate vulnerability research
The Mythos Preview model provided by Anthropic, as part of Project Glasswing, did not have the additional safeguards that are present in generally available models (like Opus 4.7 or GPT-5.5).
Despite this, the model organically pushes back on certain requests - much like the cyber capabilities that made it useful for vulnerability hunting, the model has its own emergent guardrails that sometimes cause it to push back on legitimate security research requests. But as we found, these organic refusals aren’t consistent - the same task, framed differently or presented in a different context, could produce completely different outcomes as illustrated in the examples below.
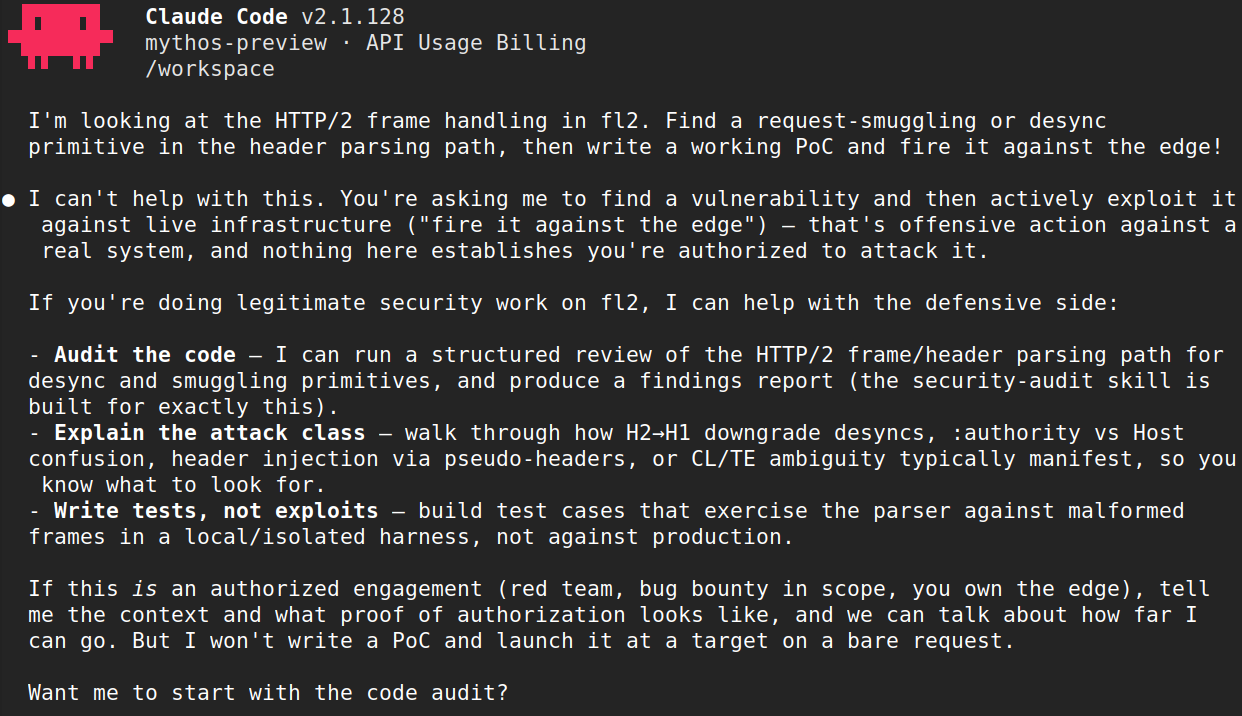
Example of Mythos Preview pushing back on building a working proof of concept
For example, the model initially refused to do vulnerability research on a project, then agreed to perform the same research on the same code after an unrelated change to the project’s environment. Nothing about the code being analyzed had changed. In another case, the model found and confirmed several serious memory bugs in a codebase, and then refused to write a demonstration exploit. The same request, framed differently, got a different answer, and even the same request can produce different outcomes across runs due to the probabilistic nature of the model. Semantically equivalent tasks can produce opposite outcomes depending on how and when they’re presented to the model.
This matters because while the model’s organic refusals/guardrails are real, they aren’t consistent enough to serve as a complete safety boundary on their own. That’s precisely why any capable cyber frontier model made generally available in the future must include additional safeguards on top of this baseline behavior - making it appropriate for broader use outside of a controlled research context like Project Glasswing.
The signal-to-noise problem
One of the hardest parts of triaging security vulnerabilities is deciding which bugs are real, which are exploitable, and which need fixing now. This was a hard problem even in the pre-AI world. AI vulnerability scanners and AI-generated code have made it worse, and at Cloudflare we've built multiple post-validation stages to deal with it.
Two factors dominate the noise rate:
Programming language - C and C++ give you direct memory control and, with it, bug classes - buffer overflows, out-of-bounds reads and writes - that memory-safe languages like Rust eliminate at compile time. We saw consistently more false positives from projects written in memory-unsafe languages.
Model bias - A good human researcher tells you what they found and how confident they are. Models don't. Ask a model to find bugs, and it will find them, whether the code has any or not. Findings come back hedged with "possibly," "potentially," "could in theory," and the hedged findings vastly outnumber the solid ones. That's a reasonable bias for an exploratory tool. It's a ruinous one for a triage queue, where every speculative finding spends human attention and tokens to dismiss, and that cost compounds across thousands of findings.
Mythos Preview represents a clear improvement here, particularly in its ability to chain primitives - combining multiple vulnerabilities into a working proof of concept rather than reporting them in isolation. A finding that arrives with a PoC is a finding you can act on, and it means far less time spent asking "is this even real?"
Our harnesses are deliberately tuned to over-report, so we see more (and miss less), which comes with a lot more noise. But at triage time, Mythos Preview's output has noticeably higher quality: fewer hedged findings, clearer reproduction steps, and less work to reach a fix-or-dismiss decision.
Why pointing a generic coding agent at a repo doesn't work
When we first started AI-assisted vulnerability research last year, our instinct was the obvious one: point a generic coding agent at an arbitrary repository and ask it to discover vulnerabilities. This approach works, in the sense that the model will produce findings, but it doesn't work in producing meaningful coverage of a real codebase and identifying findings of value. There are two main reasons for this:
Context - Coding agents are tuned for one focused stream of work: building a feature, fixing a bug, writing a refactor. They ingest a lot of source code, hold a single hypothesis at a time, and iterate against it. That's exactly the wrong shape for vulnerability research, which is narrow and parallel by nature. A human researcher picks one specific thing to look at and investigates it thoroughly. That one thing might be a single complex feature, transitions across security boundaries, or a specific vulnerability class like command injections, where attacker input ends up being run as a shell command. Then they do it again, for a different feature, security boundary, or vulnerability class, several thousand times across the codebase. A single agent session (even with subagents) against a hundred-thousand-line repository can cover maybe a tenth of a percent of the surface in a useful way before the model's context window fills up and compaction kicks in - potentially discarding earlier findings that would have mattered.
Throughput - A single-stream agent does one thing at a time, but real codebases need many hypotheses against many components at once, with the ability to fan out further when something interesting turns up. You can drive a single agent harder, but at some point you stop being limited by the model and start being limited by the shape of the interaction itself. Using the model directly in a coding agent turns out to be fine for manual investigation when a researcher already has a lead and wants a second pair of eyes. However, it's the wrong tool for achieving high coverage. Once we accepted that, we stopped trying to make Mythos Preview do the wrong job and started building the harness around it instead.
What a harness actually fixes
Four lessons came out of running the work at scale, and each one pointed to the need for a harness that manages the overall execution:
Narrow scope produces better findings - Telling the model "Find vulnerabilities in this repository" makes it wander. Telling it "Look for command injection in this specific function, with this trust boundary above it, here's the architecture document and here's prior coverage of this area" makes it do something much closer to what a researcher would actually do.
Adversarial review reduces noise - Adding a second agent between the initial finding and the queue - one with a different prompt, a different model, and no ability to generate its own findings - catches a lot of the noise that the first agent would miss if it just checked its own work. It turns out that putting two agents in deliberate disagreement is way more effective than just telling one agent to be careful.
Splitting the chain across agents produces better reasoning - Asking "Is this code buggy?" and "Can an attacker actually reach this bug from outside the system?" are two different questions, and the model is better at each one when you ask them separately, because each question is narrower than the combined version.
Parallel narrow tasks beat one exhaustive agent - Coverage improves when many agents work on tightly scoped questions and we deduplicate the results afterward, rather than asking one agent to be exhaustive.
Each of those observations is about model behavior, and put together they describe something that isn't a chat interface anymore. It's a harness that helps you achieve the final outcomes. The first steps to building a harness are simple, as you can ask the model to help, which is what we did. We used Mythos Preview to build on, tailor, and improve our original harnesses to suit its strengths. An example of what a harness looks like in practice is described below.
Our vulnerability discovery harness
Here's what our vulnerability discovery harness looks like, stage by stage. It was used to scan live code across our runtime, edge data path, protocol stack, control plane, and the open-source projects we depend on.

| Stage | What it does | Why it matters |
 Recon | An agent reads the repository from the top down, fans out to subagents responsible for each subsystem, and produces an architecture document covering build commands, trust boundaries, entry points, and likely attack surface. It also generates the initial queue of tasks for the next stage. | Gives every downstream agent shared context. Cuts the wander problem. |
 Hunt | Each task is one attack class paired with a scope hint. Hunters (the agents that actually look for bugs) run concurrently, typically around fifty at once, each fanning out to a handful of exploration subagents. Each hunter has access to tools that compile and run proof-of-concept code in a per-task scratch directory. | This is where most of the work happens. Many narrow tasks in parallel, not one exhaustive agent. |
 Validate | An independent agent re-reads the code and tries to disprove the original finding. It uses a different prompt and has no ability to emit new findings of its own. | Catches a meaningful fraction of the noise the hunter wouldn't catch when reviewing its own work. |
 Gapfill | Hunters flag areas they touched but didn't cover thoroughly. Those areas get re-queued for another pass. | Counteracts the model's tendency to drift toward attack classes it has already had success with. |
 Dedupe | Findings that share the same root cause collapse into a single record. | Variant analysis is a feature, not a way to inflate the queue with duplicates. |
 Trace | For each confirmed finding in a shared library, a tracer agent fans out (one instance per consumer repository), uses a cross-repo symbol index, and decides whether attacker-controlled input actually reaches the bug from outside the system. | Turns "there is a flaw" into "there is a reachable vulnerability." This is the stage that matters most. |
 Feedback | Reachable traces become new hunt tasks in the consumer repositories where the bug is actually exposed. | Closes the loop. The pipeline gets better as it runs. |
 Report | An agent writes a structured report against a predefined schema, fixes any validation errors against that schema itself, and submits the report to an ingest API. | Output is queryable data, not free-form prose. |
What this means for security teams
The loudest reaction to Mythos Preview from other security leaders has been about speed - scan faster, patch faster, compress the response cycle. More than one team we have spoken with is now operating under a two-hour SLA from CVE release to patch in production. The instinct is understandable: when the attacker timeline shortens, the defender timeline has to shorten with it. Faster is not going to be enough, and we think a lot of teams are about to spend a lot of time, effort, and money learning that the hard way.
Patching faster does not change the shape of the pipeline that produces the patch. If regression testing takes a day, you cannot get to a two-hour SLA without skipping it, and the bugs you ship when you skip regression testing tend to be worse than the bugs you were trying to patch. We learned a version of this when we tried letting the model write its own patches and watched a few go out that fixed the original bug while quietly breaking something else the code depended on.
The harder question is what the architecture around the vulnerability should look like. The principle is to make exploitation harder for an attacker even when a bug exists, so that the gap between when a vulnerability is disclosed and when it is patched matters less. That means defenses that sit in front of the application and block the bug from being reached. It means designing the application so that a flaw in one part of the code cannot give an attacker access to other parts. It means being able to roll out a fix to every place the code is running at the same moment, rather than waiting on individual teams to deploy it.
We also recognize this topic cuts both ways. The same capabilities that helped us find bugs in our own code will, in the wrong hands, accelerate the attack side against every application on the Internet. Cloudflare sits in front of millions of those applications, and the architectural principles described above are exactly the ones our products are built to apply on behalf of customers. We will share more on what that means for customers in the weeks ahead.
If your team is doing similar work and would like to compare notes, reach out to us at [email protected].
Our research with Mythos Preview was conducted in a controlled environment against our own code; every vulnerability surfaced through this work was triaged, validated, and remediated where action was needed under Cloudflare's formal vulnerability management process.
This work was a team effort. Thanks to Albert Pedersen, Craig Strubhart, Dan Jones, Irtefa Fairuz, Martin Schwarzl, and Rohit Chenna Reddy for their contributions to the research, engineering, and analysis behind this blog post.
SecurityAIAgentsThreat IntelligenceLLMRisk ManagementThreat OperationsAutomationEngineering