19th May 2026
I put together these annotated slides from my five minute lightning talk at PyCon US 2026, using the latest iteration of my annotated presentation tool.

{kind=link}
I presented this lightning talk at PyCon US 2026, attempting to summarize the last six months of developments in LLMs in five minutes.

{kind=link}
Six months is a pretty convenient time period to cover, because it captures what I’ve been calling the November 2025 inflection point. November was a critical month in LLMs, especially for coding.

{kind=link}
For one thing, the supposedly “best” model (depending mostly on vibes) changed hands five times between the three big providers.

{kind=link}
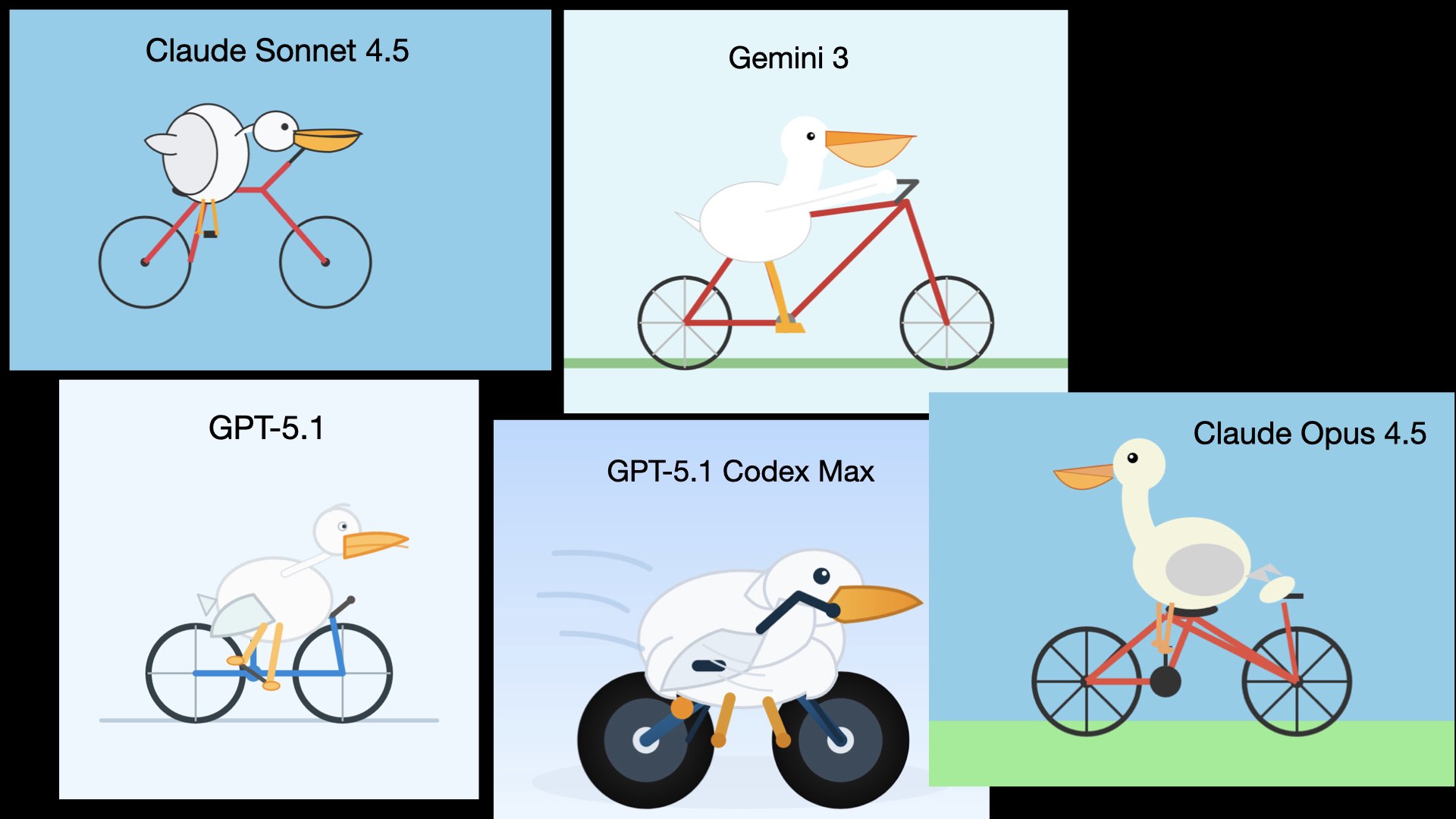
As always, I’m using my Generate an SVG of a pelican riding a bicycle test to help illustrate the differences between the models.
Why this test? Because pelicans are hard to draw, bicycles are hard to draw, pelicans can’t ride bicycles... and there’s zero chance any AI lab would train a model for such a ridiculous task.
{kind=link}
At the start of November the widely acknowledged “best” model was Claude Sonnet 4.5, released on 29th September. It drew me this pelican.
In November it was overtaken by GPT-5.1, then Gemini 3, then GPT-5.1 Codex Max, and then Anthropic took the crown back again with Claude Opus 4.5.
I think Gemini 3 drew the best pelican out of this lot, but pelicans aren’t everything. Most practitioners will agree that Opus 4.5 held the crown for the next couple of months.

{kind=link}
It took a little while for this to become clear, but the real news from November was that the coding agents got good.
OpenAI and Anthropic had spent most of 2025 running Reinforcement Learning from Verifiable Rewards to increase the quality of code written by their models, especially when paired up with their Codex and Claude Code agent harnesses.
In November the results of this work became apparent. Coding agents went from often-work to mostly-work, crossing a quality barrier where you could use them as a daily-driver to get real work done, without needing to spend most of your time fixing their stupid mistakes.
{kind=link}
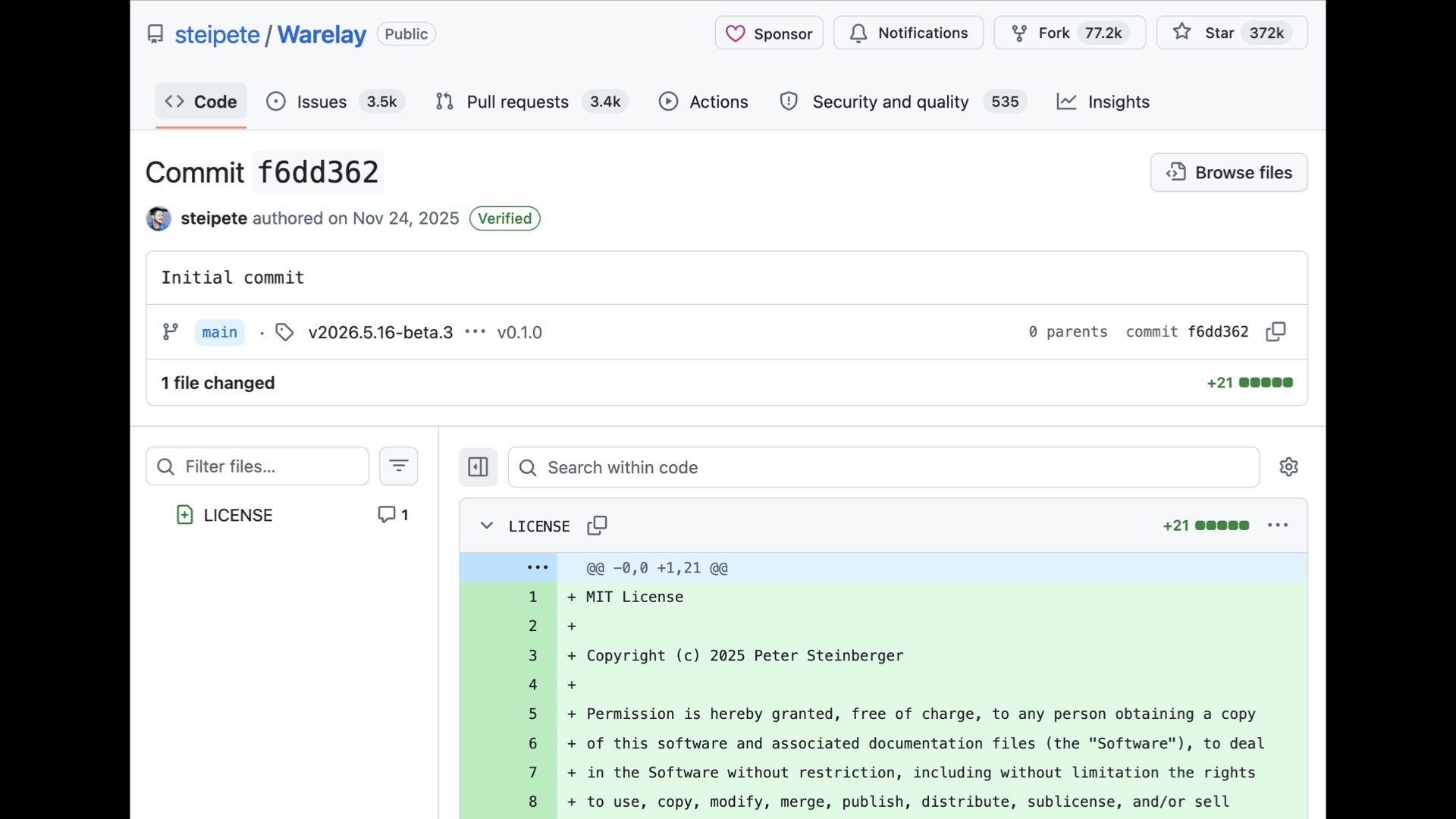
Also in November, this happened—the first commit to an obscure (back then) repo called “Warelay” by some guy called Pete.

{kind=link}
Over the holiday period, from December to January, a whole lot of us took advantage of the break to have a poke at these new models and coding agents and see what they could do.
They could do a lot! Some of us got a little bit over-excited. I had my own short-lived bout of a form of LLM psychosis as I started spinning up wildly ambitious projects to see how far I could push them.
![micro-javascript playground Execute JavaScript code in a sandboxed micro-javascript environment powered by Pyodide var numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; var doubled = numbers.map(n => n * 2); console.log('Doubled:](https://static.simonwillison.net/static/2026/5-minutes-llms/5-minutes-llms.009.jpeg) n % 2 === 0); console.log('Evens: ', evens); var sum = numbers.reduce((a, b) => a + b, @); console.log('Sum:", sum); Output 27 Doubled: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] Evens: [2, 4, 6, 8, 10] Sum: 55 Execution time: 8.00ms About: micro-javascript is a pure Python JavaScript interpreter with configurable memory and time limits. This playground runs entirely in your browser using Pyodide (Python compiled to WebAssembly). View on GitHub">
n % 2 === 0); console.log('Evens: ', evens); var sum = numbers.reduce((a, b) => a + b, @); console.log('Sum:", sum); Output 27 Doubled: [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] Evens: [2, 4, 6, 8, 10] Sum: 55 Execution time: 8.00ms About: micro-javascript is a pure Python JavaScript interpreter with configurable memory and time limits. This playground runs entirely in your browser using Pyodide (Python compiled to WebAssembly). View on GitHub">
{kind=link}
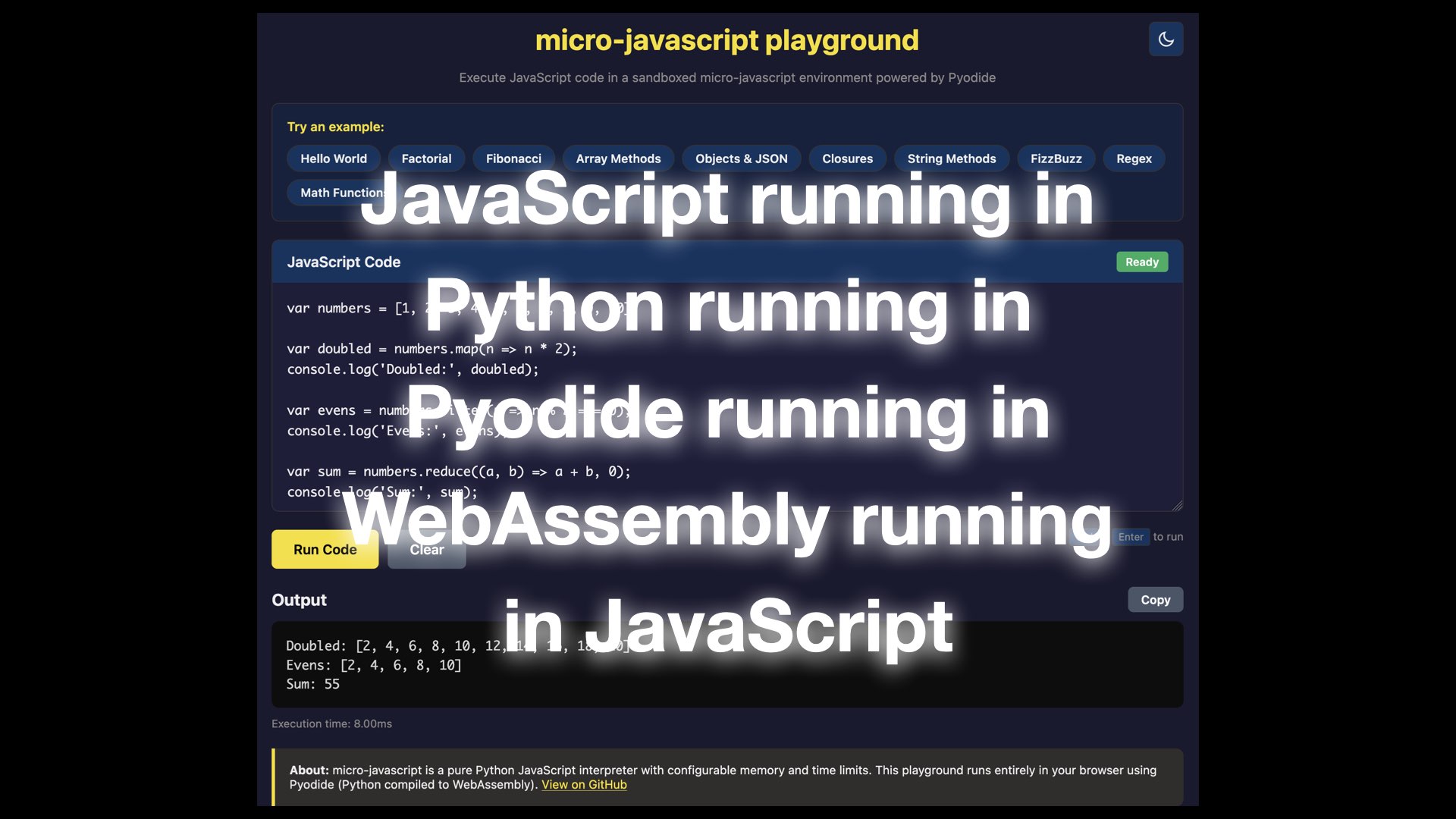
That playground demo shows JavaScript code run using my micro-javascript library, in Python, running inside Pyodide, running in WebAssembly, running in JavaScript, running in a browser!
It’s pretty cool! But did anyone out there need a buggy, slow, insecure half-baked implementation of JavaScript in Python?
They did not. I have quite a few other projects from that holiday period that I have since quietly retired!
{kind=link}
On to February. Remember that Warelay project that had its first commit at the end of November?

{kind=link}
In December and January it had gone through quite a few name changes... and by February it was taking the world by storm under its final name, OpenClaw.
The amount of attention it got is pretty astonishing for a project that was less than three months old.

{kind=link}
OpenClaw is a “personal AI assistant”, and we actually got a generic term for these, based on NanoClaw and ZeroClaw and suchlike... they’re called Claws.

{kind=link}
Mac Minis started to sell out around Silicon Valley, because people were buying them to run their Claws.
Drew Breunig joked to me that this is because they’re the new digital pets, and a Mac Mini is the perfect aquarium for your Claw.

{kind=link}
My favourite metaphor for Claws is Alfred Molina’s Doc Ock in the 2004 movie Spider-Man 2. His claws were powered by AI, and were perfectly safe provided nothing damaged his inhibitor chip... after which they turned evil and took over.

{kind=link}
Also in February: Gemini 3.1 Pro came out, and drew me a really good pelican riding a bicycle. Look at this! It’s even got a fish in its basket.

{kind=link}
And then Google’s Jeff Dean tweeted this video of an animated pelican riding a bicycle, plus a frog on a penny-farthing and a giraffe driving a tiny car and an ostrich on roller skates and a turtle kickflipping a skateboard and a dachshund driving a stretch limousine.
So maybe the AI labs have been paying attention after all!
{kind=link}
A lot of stuff happened just in the past month.

{kind=link}
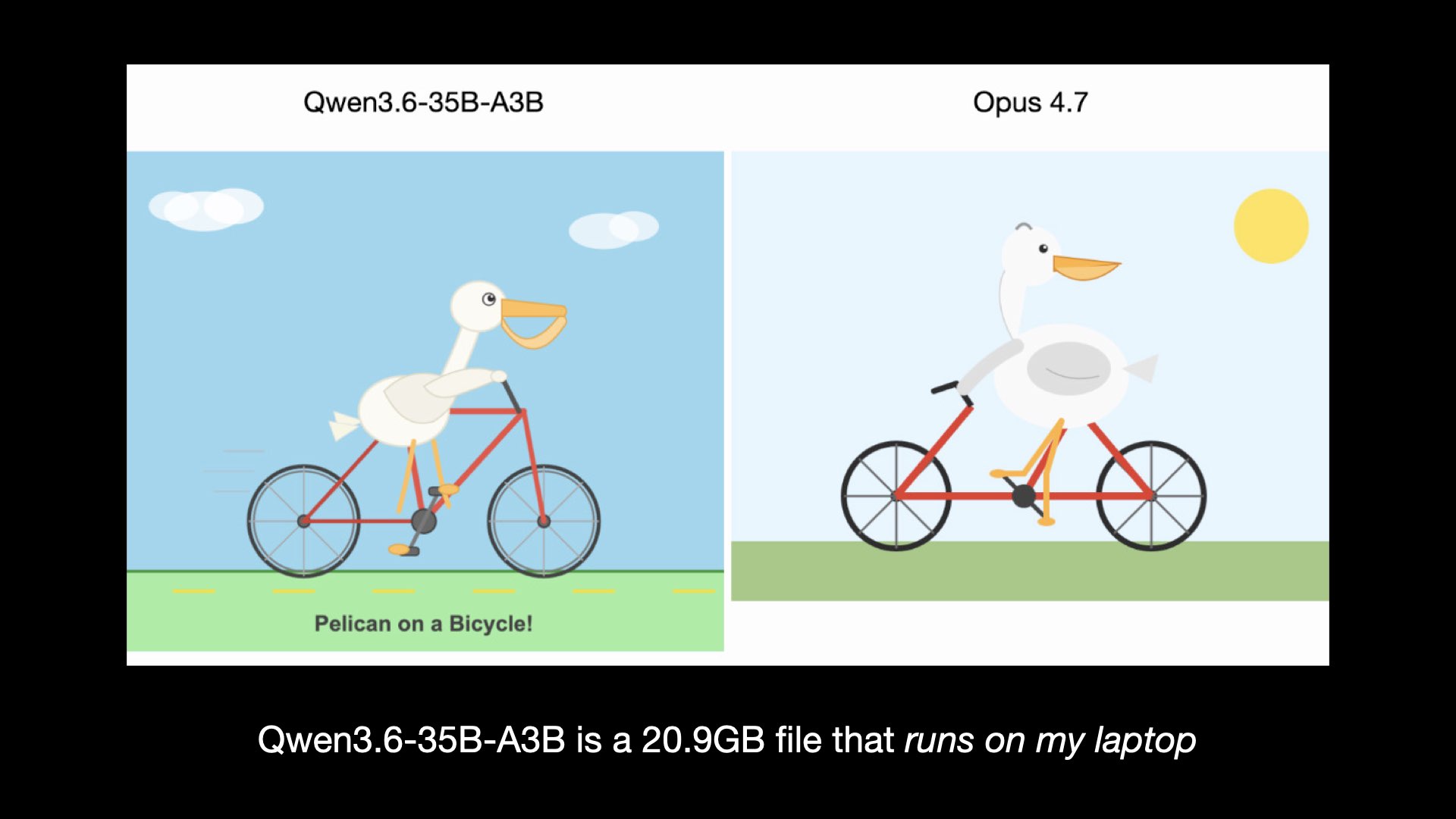
Google released the Gemma 4 series of models, which are the most capable open weight models I’ve seen from a US company.

{kind=link}
Also last month, Chinese AI lab GLM came out with GLM-5.1—an open weight 1.5TB monster! This is a very effective model... if you can afford the hardware to run it.

{kind=link}
GLM-5.1 drew me this very competent pelican on a bicycle.

{kind=link}
... though when it tried to animate it the bicycle bounced off into the top and the bicycle got warped.
{kind=link}
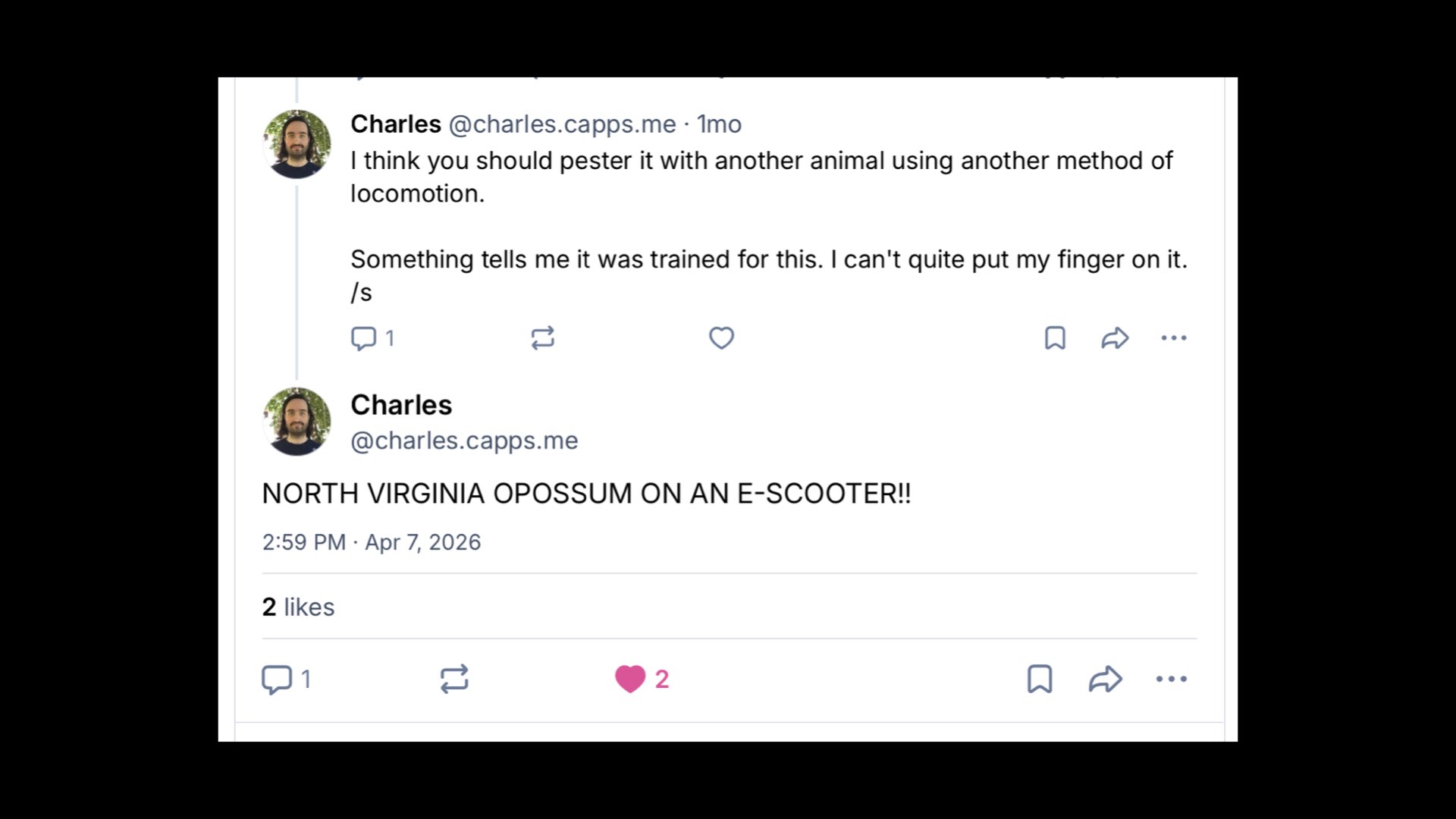
Charles on Bluesky suggested I try it with a North Virginia Opossum on an E-scooter

{kind=link}
And it did this! I’ve tried this on other models and they don’t even come close. “Cruising the commonwealth since dusk” is perfect. It’s animated too.
{kind=link}
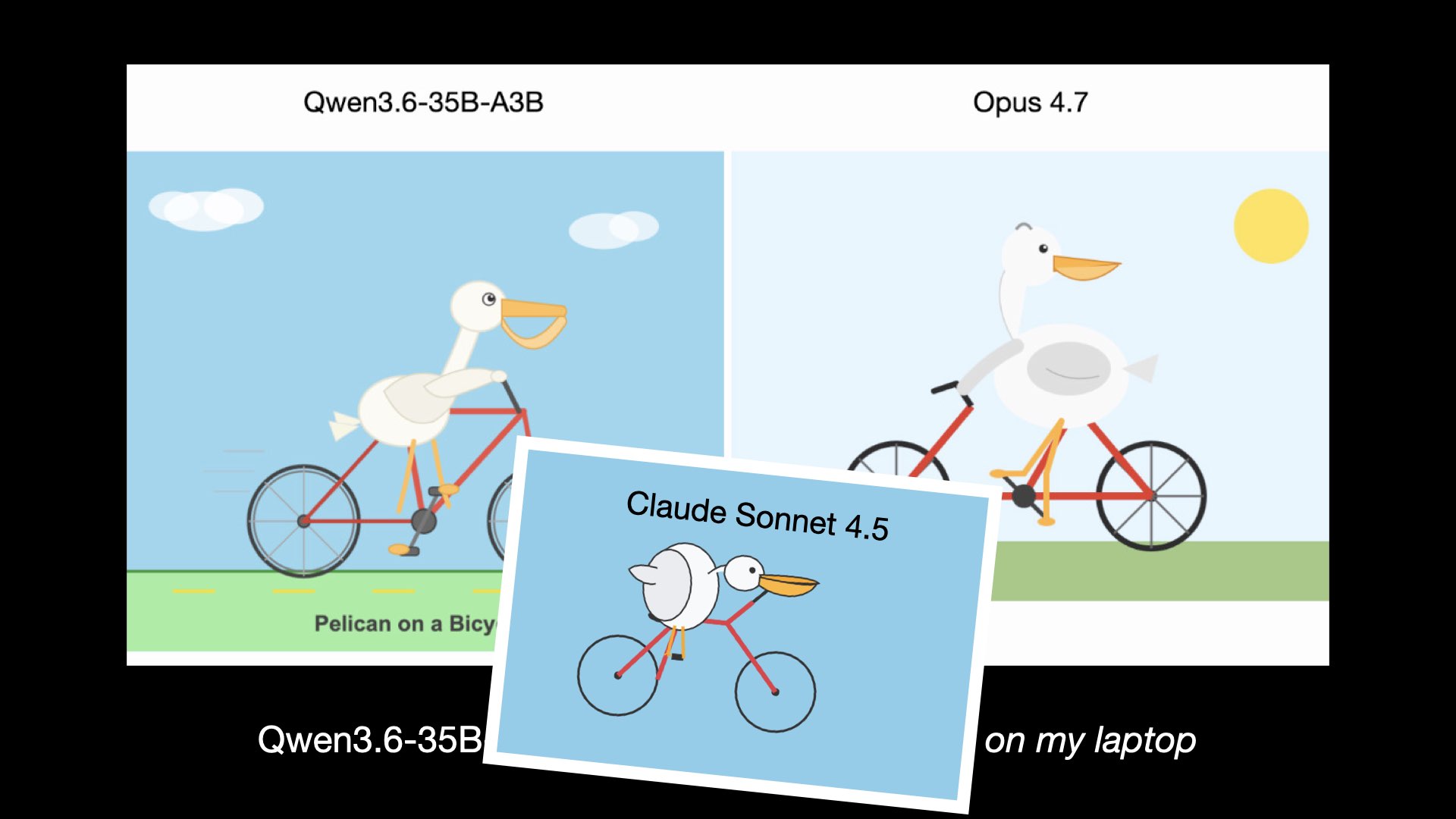
Here’s that Claude Sonnet 4.5 pelican from September for comparison.

{kind=link}
So those were the two main themes of the past six months. The coding agents got really good... and the laptop-available models, while a lot weaker than the frontier, have started wildly outperforming expectations.