It’s nice when you work on security and accidentally get some performance for free. This is the story of a small encoding called bijou64 — a variable-length integer (varint) encoding that we developed for the Subduction CRDT sync protocol. It was intended to fix a subtle signature-verification bug by making each number only representable a single way. It turned out to also run a few times faster than the more common varint LEB128.
We didn’t set out to write a fast varint, but it turns out that our design constraints made for an encoding that has to do less work.
The Problem
Many binary protocols need a compact way to encode integers that are usually small but occasionally large. Variable-length integer encodings (“varints”) solve this, but most designs treat canonicality as an afterthought — something enforced by a runtime check in the decoder rather than by the structure of the encoding itself.
Since it’s the most common varint, we’re going to pick on LEB128 a bit here. I want to emphasize how much LEB128 is a great choice for many projects, and the reasons that it was not a good choice for us also applies to the other formats that we looked at. It just happened to not be a perfect fit for our use case.
LEB128 encodes a number as a sequence of 7-bit segments, with the high bit of each byte signaling “more bytes follow” (there can be many such continuation segments, though we only show 2 segments below). This lets you avoid always writing 8 bytes (64 bits) even when you’re representing a small number (which would be mostly zeroes). This is like writing 5 instead of 000000005 just to get the correct number of characters. Putting aside that working in 7-bit is odd, this is a practical solution!

LEB128 layout
But there’s a problem: the number 0 can be encoded as the single byte 0x00, but it can also be encoded as 0x80 0x00. Or 0x80 0x80 0x00. Or any longer sequence of 0x80s ending in a zero byte. 0x80 is 1 0000000, so you can have as many of those as you want and still get 0! Most LEB128 decoders will happily accept any of them. This isn’t unique to zero; nearly every number in LEB128 can be represented many ways.
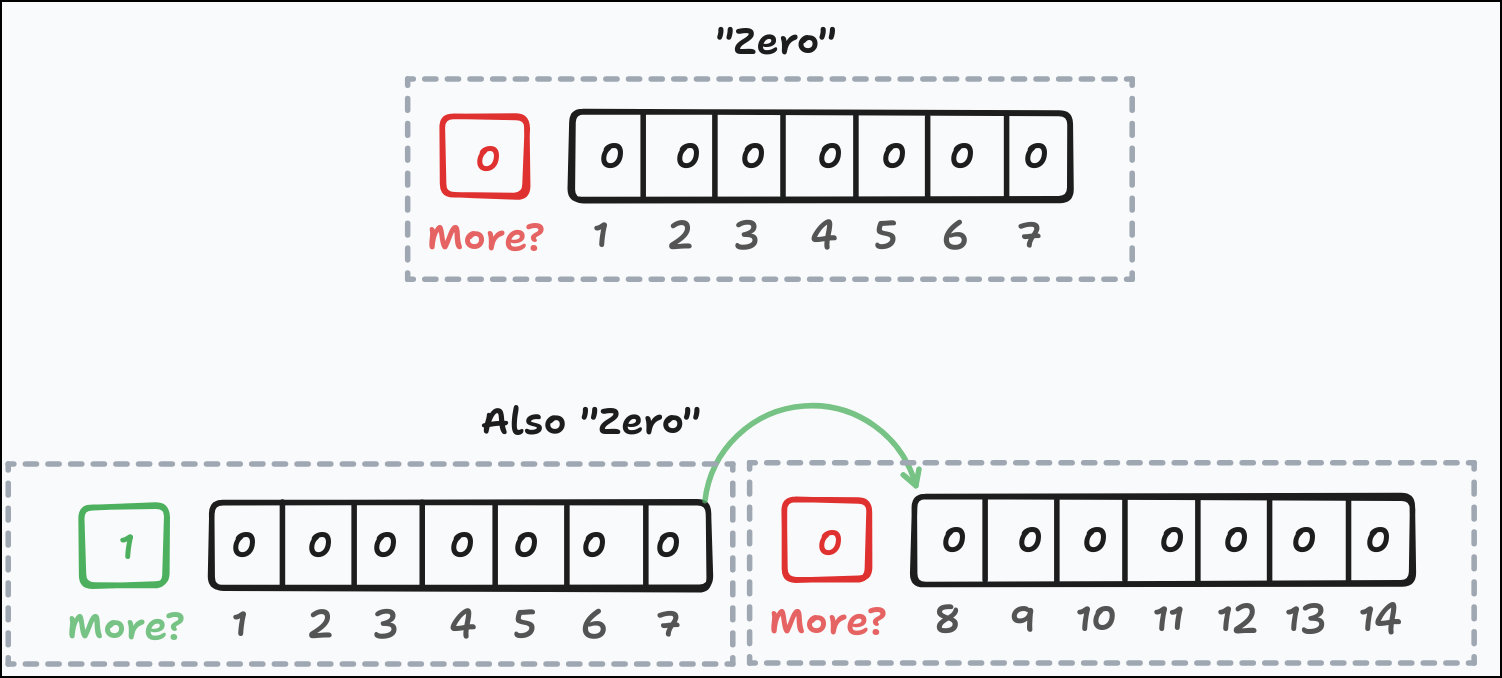
Zero represented two ways in LEB128
This causes problems for signed data if you ever want to do things like compression since you need to know the exact bytes that were signed. Having an extra 0x80 will result in a different signature.
If you only have one unique way to represent a number, you can do things like deduplicate runs of numbers when storing without needing to retain the entire original.
Canonicalisation
One solution is to simply enforce a special “canonical” form. While encoding a varint, you must ensure that you use the canonical encoding (not all libraries will always do this). When decoding, you must validate that it matches your expected format. It would be really nice to not have to do that additional work.
So What?
You could reasonably ask: who actually shows up with adversarial varints? The answer is “anyone who would benefit from your protocol mistaking two different byte strings for the same value.” For a signed protocol, that could be a lot of people.
While not about varints per se, the textbook case is ASN.1 (the abstract syntax notation behind X.509 certificates, LDAP, and many other things that are widely depended on). Canonicalisation attacks have been used against PKCS#1 v1.5, Mozilla NSS, GnuTLS, JWTs and Bitcoin transactions.
The pattern in all of these is something like:
- The spec says: “the canonical encoding is X; any other encoding MUST be rejected.”
- The implementation has one or more
ifs that enforces this. - The check is separately deletable from the rest of the parser. Removing it doesn’t break round-trip tests; it doesn’t break tests using honestly-encoded data; it doesn’t break performance benchmarks. It only breaks under adversarial input, which is rarely in the test suite.
- The check is forgotten, optimised away, or never ported. The protocol’s security property silently degrades. This is the bug class bijou64 is designed to make impossible. Not by adding more checks, but by removing the one that mattered — and making the format such that, with no canonicality check at all, the only encoding that exists for any given value is the canonical one.
(Almost) Canonical by Construction
bijou64 eliminates the possibility of more than one encoding per integer. Just like our normal written number system, there is exactly one way to write each number. Bijou uses two tricks:
1. First Byte Double Duty
The first byte represents 0–247 as normal. If you get 0x42, it just decodes to 0x42. 248–255 switch into a different mode: they’re a tag for how many bytes to expect after this first one, which will represent the number. This is really nice for decoding, because we know how much memory to allocate as soon as we read the first byte (O(1)). LEB128, by contrast, has to keep reading bytes until it sees one without the continuation bit set (O(n)).
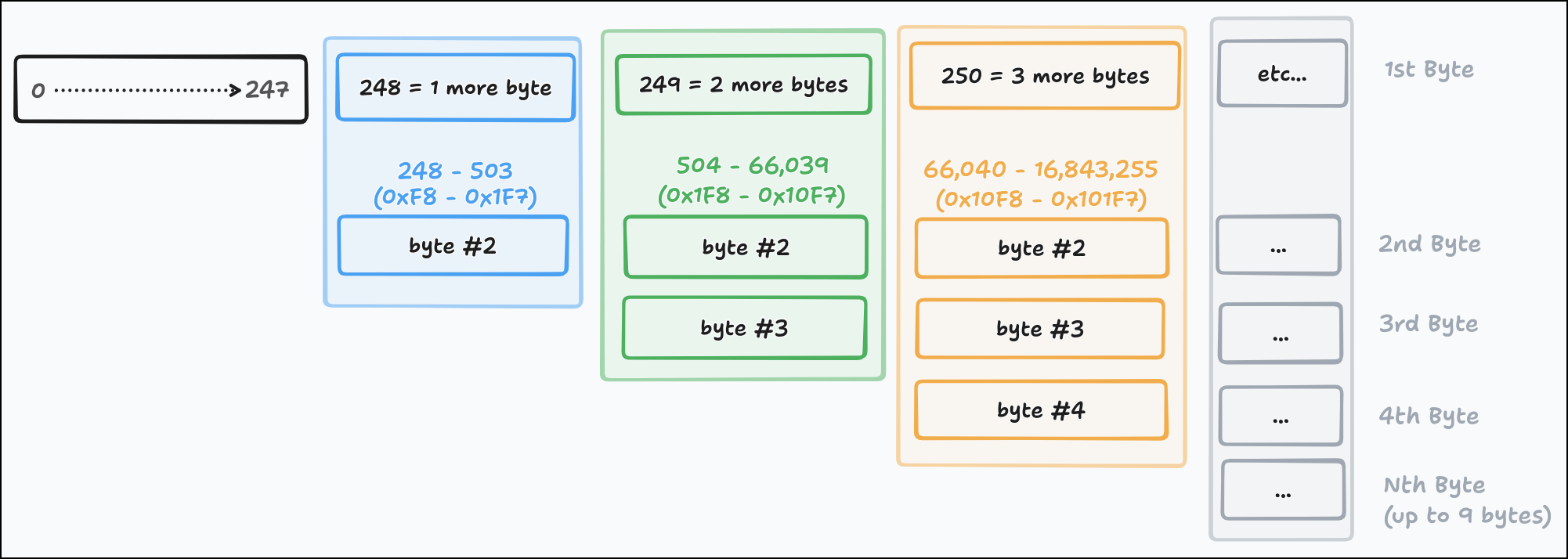
Byte/tag structure
2. Offsets
The tag alone is not enough to guarantee canonicity, but it points the way: instead of repeating 0-247 in the second byte (0xF8 0x00 == 0x00), we offset the next byte by 248 (0xF8). This means that 0xF8 0x00 == 0xF8 == 248, not 0 (since 0 is already represented as 0x00).
Here’s a worked example of decoding 1738, which takes the tag plus two bytes:
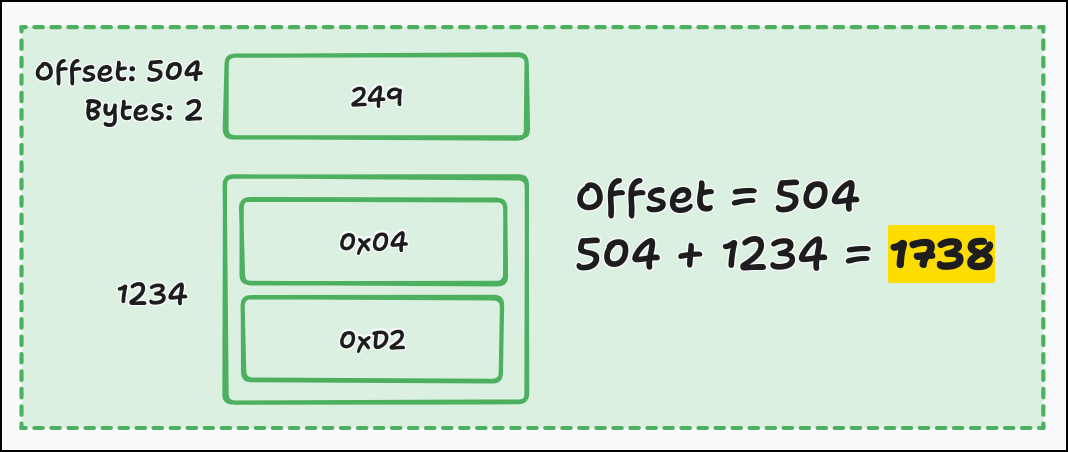
Worked example
All numbers at this length (3 bytes total AKA tag + 2 data bytes) are offset by 504 (0x1F8). Each successive length increases the offset in a predictable pattern. See if you can spot it:
| Total Length | Offset |
|---|---|
| 1 | 0x00 |
| 2 | 0xF8 |
| 3 | 0x01F8 |
| 4 | 0x0101F8 |
| 5 | 0x010101F8 |
| 6 | 0x01010101F8 |
| 7 | 0x0101010101F8 |
| 8 | 0x010101010101F8 |
| 9 | 0x01010101010101F8 |
This is a lookup table based on the first byte!
There is one exception: because the numbers are always offset down, the largest values (9 bytes) need a manual check that they are in bounds. The 9-byte (tag + 8 bytes of data) slot can actually represent numbers larger than 2⁶⁴ due to the offset, but since bijou64 targets u64, we cap it there. This isn’t the canonicity problem from earlier — every in-range number still has exactly one encoding — we’re just clipping extra headroom that we don’t want. So when the tag is 255 (the biggest one), the decoder checks that the value is below the cutoff.
Benchmarks
Bijou64 has to do all of this bit shuffling, tag lookups, and whatnot. There needs to be a cost for all of this, and there is over the regular, fixed length 64-bit numbers. Surely it’s slower than much widely used encodings like LEB128 and the very clever vu128, right? We benched it on ARM (Apple M2 Pro) and x86 (AMD Zen 5), and were not expecting what came back.
Decoding

Median decode time per batch of 4096 values. Lower is better. Distributions described in the methodology.
bijou64 comes out as pretty fast!
It decodes roughly 2-10 times faster than LEB128 even when we don’t take the overhead of canonical checks on LEB128 into account. Small numbers (which encode to a single LEB128 byte) are about twice as fast in these benchmarks. Larger numbers, which force LEB128 to scan continuation bits across many bytes, are around 8–10 times faster. On a uniform full-u64 distribution — about as adversarial as a benchmark gets — bijou64 processes a batch of 4096 values in ~3 µs (≈0.75 ns per value) where LEB128 takes ~30 µs (≈7.3 ns per value).
The bar chart only shows medians, though. The CDFs underneath are where the variance story lives:

Decode times per batch of 4096 values, plotted as a CDF for each library × distribution cell. Curves further to the left are faster. Curves that rise more steeply have more consistent performance.
In these benchmarks, bijou64’s CDFs are nearly vertical — every recorded batch timing sits within a tiny band around the median. LEB128’s curves lean over and trail off to the right, because the continuation-bit scan length depends on the value, and the branch predictor never gets a chance to lock in.
As you might imagine, the delta is even larger when doing canonical decoding since bijou64 gets this “for free” thanks to its encoding for all but the largest numbers:

Canonical decode time per batch of 4096 values — that is, decode plus the runtime overlong-rejection check for libraries that need one.
In bijou64, canonical decoding is decoding — the canonicality check is the format. In the others, the canonicality check is additional work.
Encoding
Encoding is also generally faster, with one exception:

Median encode time per batch of 4096 values.
On the “small” distribution (248 – 65,535), LEB128 wins by about 1.24×.
Encoded Size
bijou64 isn’t the most compact varint for every distribution. Tier-boundary differences aside, bijou64 and LEB128 produce wire-byte counts within a couple of percent of each other across realistic workloads.

Length to represent certain numbers. These were chosen specifically to show where they differ; the vast majority of numbers are identical in length.
Why?
In hindsight, this kind of makes sense:
Length from the first byte
Since there is no continuation-bit scanning. The decoder knows immediately how many bytes to read; the encoder knows immediately how many to write. LEB128’s decoder has to scan the high bit of every byte until it finds the terminator. Branch predictors love the bijou64 pattern; they hate the LEB128 one, especially for large values where the continuation chain is long.
Big-endian, contiguous payloads
The payload is a single contiguous big-endian integer, not 7-bit chunks with bookkeeping bits sprinkled through. Modern CPUs have byte-swap instructions for exactly this; the compiler turns the read into a single load + bswap. LEB128’s 7-bits-per-byte layout forces the decoder to mask and shift every byte.
Predictable branches
Tier selection is a small fixed match. For any one workload, branch prediction settles into a stable pattern almost immediately — exactly what those steep CDF curves show.
Arithmetic is cheap
Adding OFFSET[tier] is a constant load and an add (or sub if you’re encoding). A previous version had an if and some branching, but the arithmetic version actually has fewer instructions in the hot path on most modern CPUs.
Should you use bijou64?
Maybe! Like most interesting questions, it depends on your goals. This is a brand-new format, and it hasn’t been nearly as battle-tested as LEB128, which has mature, well-exercised implementations in every major language. Our benchmarks are encouraging, but big claims need big evidence — and we’ve only tested on three CPUs so far (M2 Pro and Zen 5 are in the published benchmarks; a Zen 3 we tried looks similar to Zen 5).
LEB128 isn’t going away, and it shouldn’t. But if you’re designing a new format and canonicality matters — for signatures, content-addressing, or any kind of “two implementations must agree on the bytes” property — there’s an alternative that’s structurally safer and runs faster on every benchmark we threw at it.
The library is published as bijou64 on crates.io, dual MIT / Apache-2.0, and the spec is CC BY-SA 4.0 if you’d like to port it. A Wasm/JavaScript wrapper exists, and a family of width extensions (bijou32, bijou128) is sketched in the spec’s future-extensions section. If you find a bug — or, more interestingly, a workload where bijou64 loses to something we benchmarked against — we’d love to hear about it!