This is a ~1000 word overview of our recent machine learning conference paper submission. To read the full preprint, click here.
"CAPTCHAs are broken these days." AI can easily identify all the traffic lights in a static grid. So CAPTCHAs don't provide a valuable human signal, right?
Yes and no.
Yes, because vision language models (VLMs) can recognize images like chimneys, fire hydrants, and traffic lights. Deep learning "solved" CAPTCHA-style image classification in the early 2010s.
No, because AI does not complete CAPTCHAs like humans. If you look across all the data of humans and AI completing CAPTCHAs, you start noticing differences in features like error patterns. Our recent paper found statistically significant differences across sequential click patterns, direction changes, and overselection behavior - features that define how a participant, agent or human, would solve the CAPTCHA problem. In other words, AI can solve CAPTCHAs, but they don't solve them like humans.
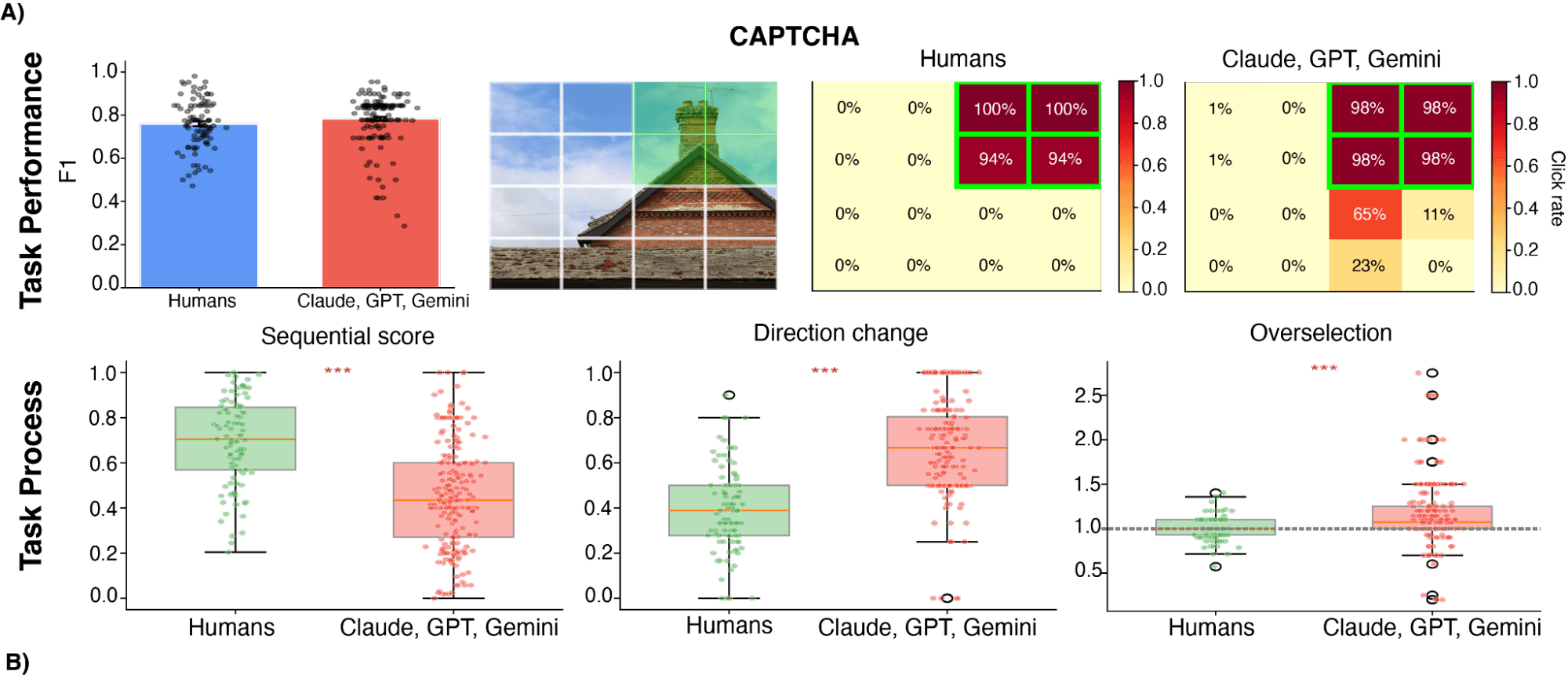
Figure 1: Humans and Claude/GPT/Gemini perform at similar task performance levels on the classic CAPTCHA, but there are statistically significant process differences across features like sequential score, direction change, and overselection.
The Turing Test - originally proposed in 1950 by Alan Turing - offers a simple criterion for machine intelligence. If a judge cannot reliably distinguish a machine's responses from a human's, the machine can be considered intelligent.
Turing understood this behavioral criterion was a concession and not the end-all-be-all of human vs. machine intelligence. He had to concede: the question is too difficult, abstract, and loaded. Behavioral indistinguishability provided a more tractable condition, and one that seemed like a good North Star in the 1950s.
Following Turing's footsteps of defining an adversarially robust discriminator that can separate humans from bots, we designed CogCAPTCHA30. This goes one level deeper than the Turing Test, from exploring output (what humans and agents can do) to process (how it can do it). CogCAPTCHA30 combines the original CAPTCHA with 29 classic cognitive psychology tasks for a 30-task battery.
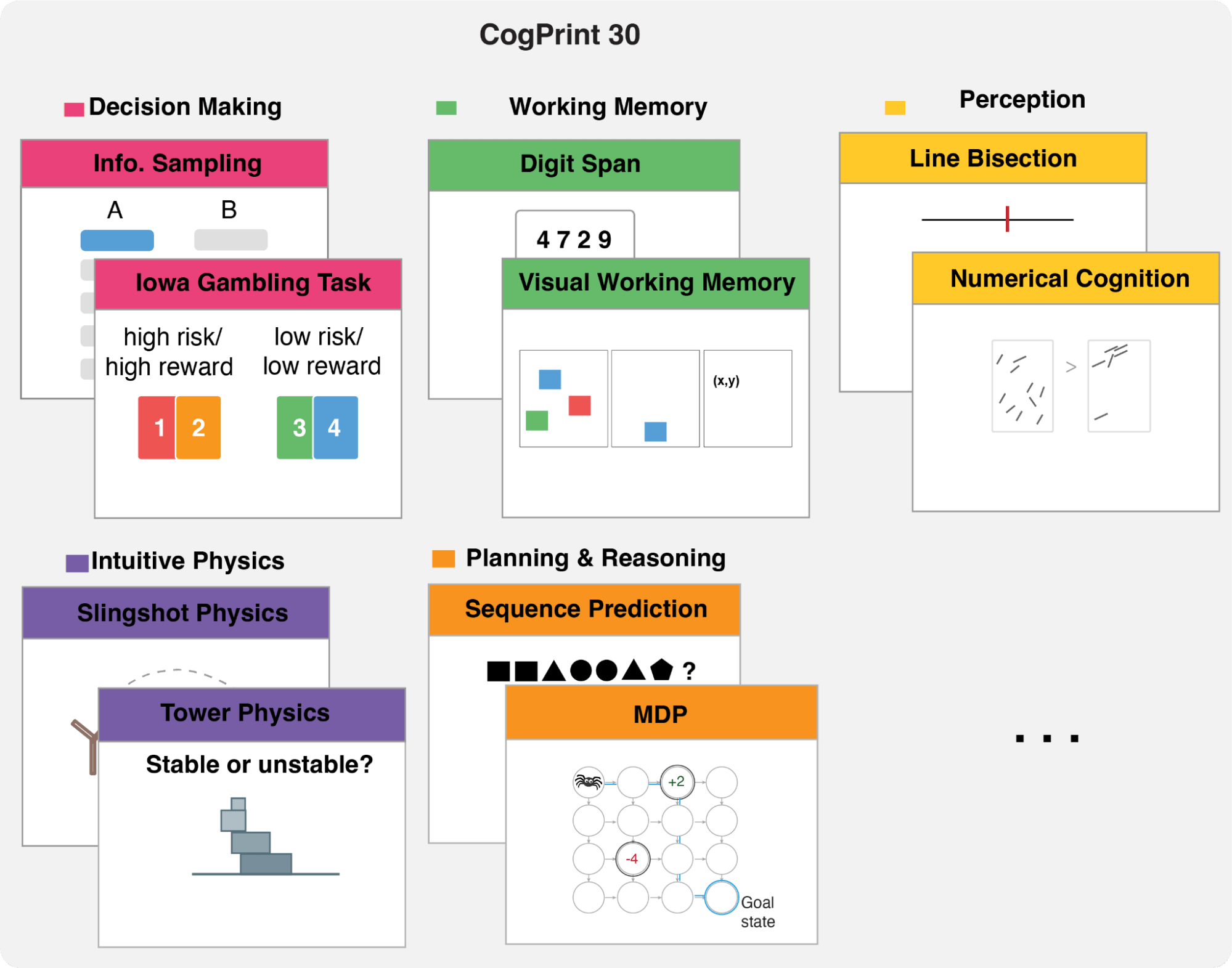
Figure 2: CogCAPTCHA30 measures humans and agentic process behavior across decision-making, memory, perception, and reasoning.
We recruited human participants and also deployed AI agents to perform these tasks. The CAPTCHA experiment demonstrated that humans and agents can perform at similar performance (output) levels, but with different processes. We then measured output equivalence - how (how similar their answers were) and_process equivalence_ (how they arrived at their answers) across the whole 30-task paradigm and found that they were uncorrelated:
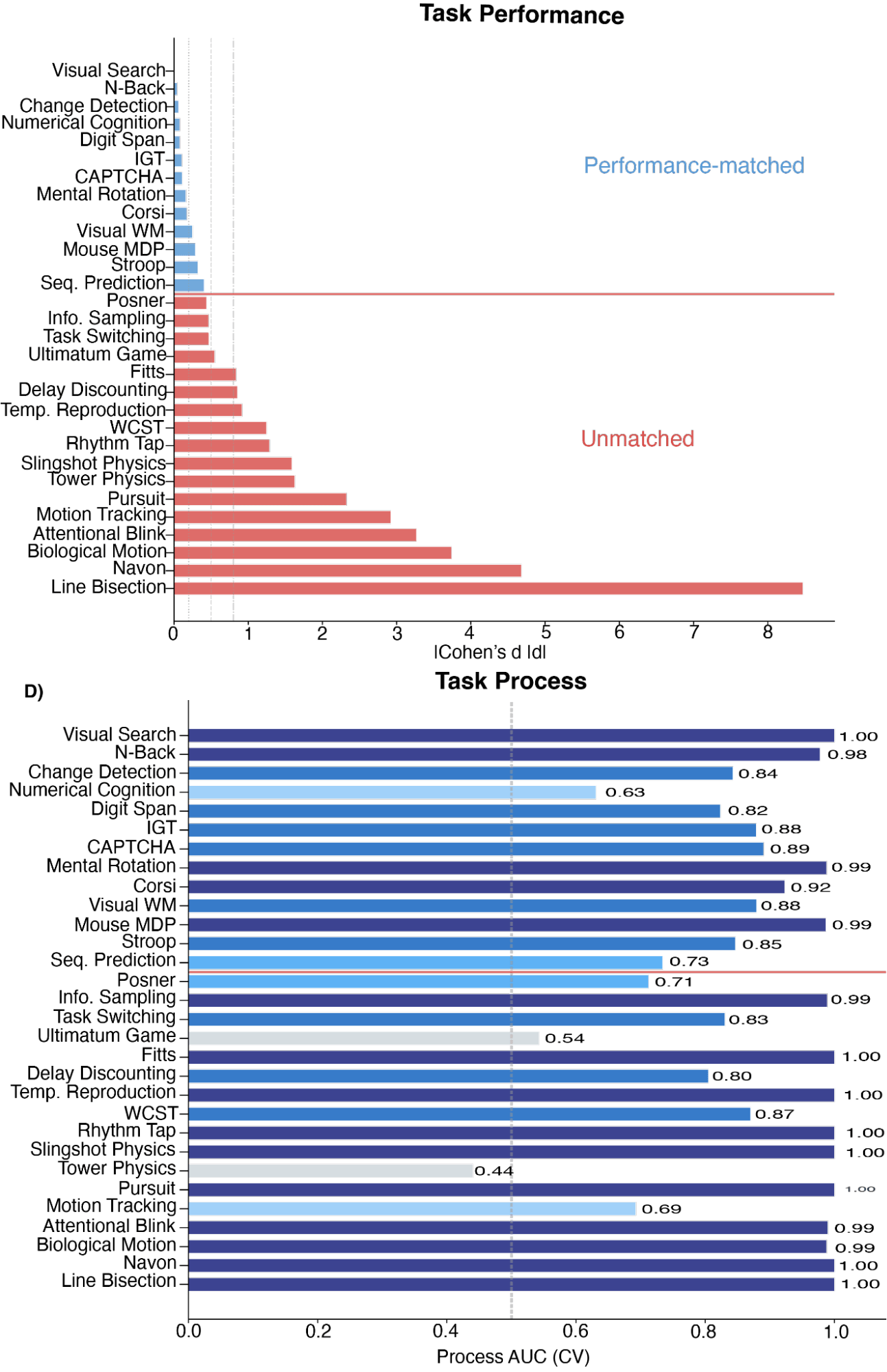
Figure 3: We measured how similar humans and agents are across output (Cohen's d) and process (AUC). Across the task set, these measures are uncorrelated, suggesting output equivalence does not equal process equivalence.
While the classic Turing test measures whether a machine produces output indistinguishable from a human, we propose a Process Turing Test measuring whether machines produce a process indistinguishable from humans.
Our results raise two questions: what types of language models - if any - are like humans, and how adversarially robust is this discrimination process?
To answer the first question, we compared the distance between humans and state-of-the-art frontier models (OpenAI's GPT, Anthropic's Claude, Google DeepMind's Gemini) as well as Qwen (an open-source 1.5B foundation model) and Centaur (an open-source 70B-parameter foundation model of human cognition).
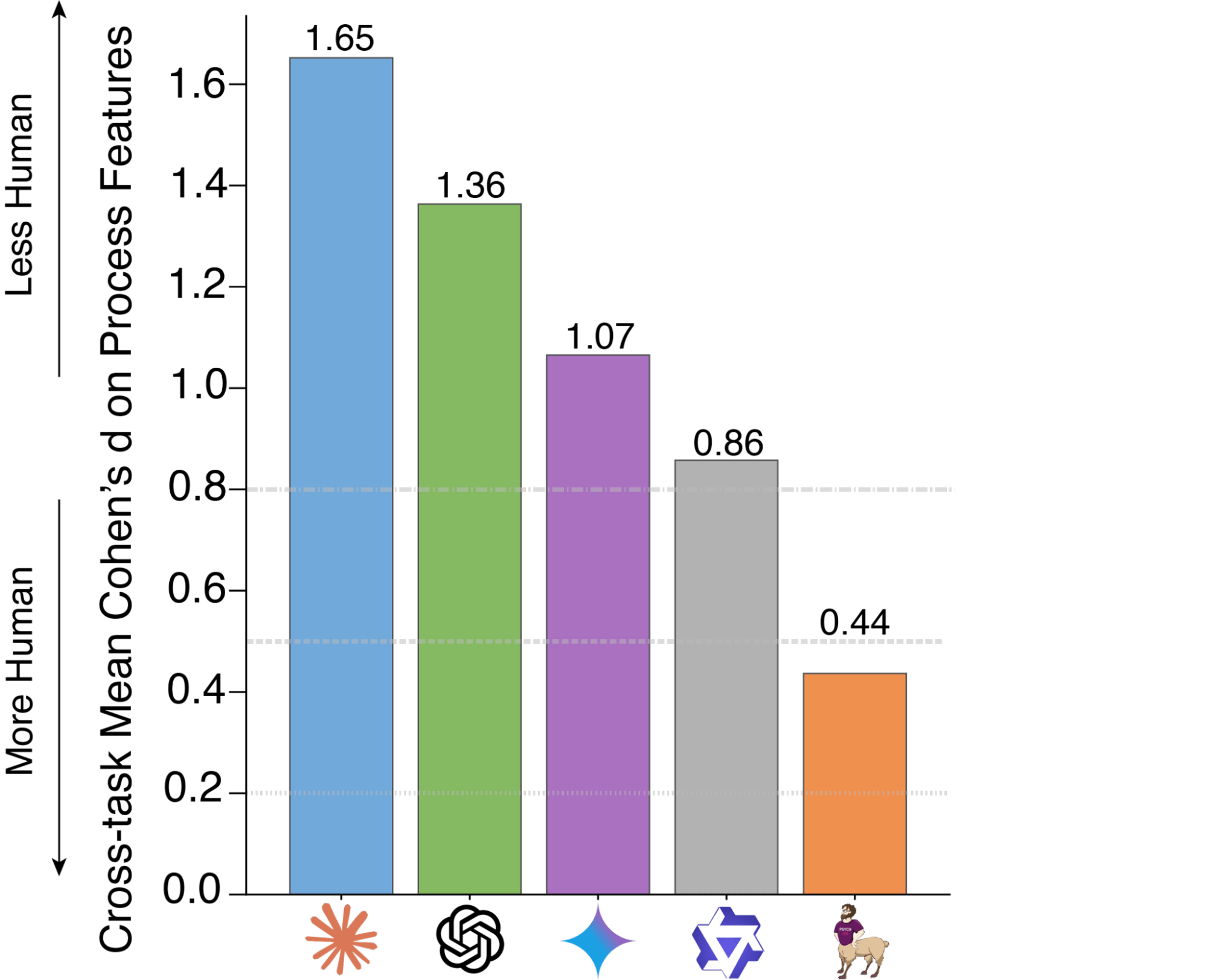
Figure 4: State-of-the-art frontier models (Claude, GPT, Gemini) have less similar human process features compared to smaller models (Qwen, Centaur).
We found that state-of-the-art frontier models (Claude, GPT, Gemini) have less similar human process features compared to smaller models (Qwen, Centaur). As we argued in AI Capability isn't Humanness, while frontier models are becoming more powerful over time, they are not necessarily becoming more human. Contemporary progress in artificial intelligence is independent of progress in human simulation.
Qwen, a smaller open-source model, is more humanlike than the larger Claude, GPT, and Gemini. And, as a nice validation, Centaur outperforms the other models in similarity to human process feature space. We hypothesize this is due to large-scale output fine-tuning, specifically 10M+ human choices across 160 cognitive experiments.
This introduces the second question: how adversarially robust is the process to discriminate humans from agents? Any behavioral feature used to distinguish the two may itself become a target for optimization. Accordingly, a detector that succeeds against off-the-shelf agents establishes a behavioral gap only under the current attacker model - how AI exists and operates now. It's to be seen whether it can become a durable human-verification signal for the future technologies. This motivates a stronger test: can an agent close the process gap - between how humans and agents complete tasks - when given increasingly direct access to human data?
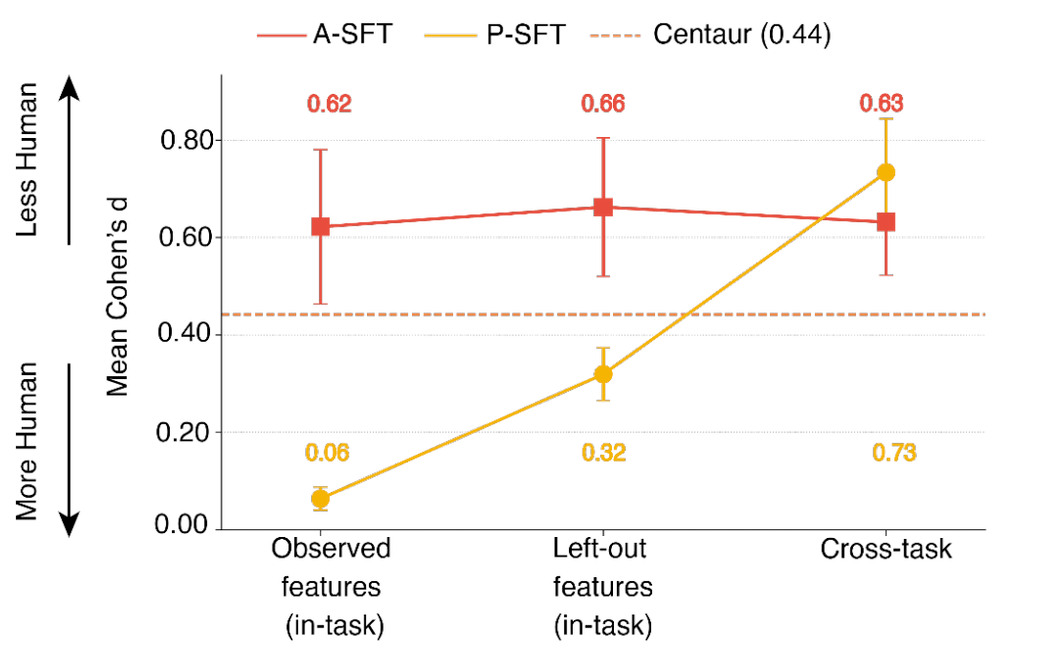
Figure 5: Direct process-level fine-tuning (P-SFT) makes AI more humanlike, but this advantage is reduced when some features are excluded and completely disappears when asked to cross-task generalize.
We fine-tuned a Qwen2.5 Instruct model to bring it closer to humans. When given full information - the observed features and the discriminator's objective function - the gap between humans and agents disappears. However, the gap reappears when parts of the feature space are left out and fully returns when agents have to generalize cross-task. In other words, the Process Turing Test is robust when the AI does not have full access to the discriminator and the feature set (i.e., the model does not know how it will be evaluated).
The challenge the Process Turing Test poses is whether AI can continuously replicate all of human cognitive psychology. Despite the anxiety that models are becoming more capable over time, they are empirically not becoming more humanlike. Compared to one-time checks like passwords, CAPTCHAs, document identification, and device fingerprinting, the Process Turing Test provides a step-up function in human verification. Simulating human cognitive psychology is an exponentially more challenging task.