May 29, 2026
4 min read
I was in Paris the last few days to visit the AI Now Summit by Mistral AI, hoping to learn more about their models, plans for the future of European AI and more. My personal insights:
Mistral is no longer just a model company. They're building the full AI stack: compute, models, platforms & consultancy. They own the compute (a 40MW data center in Paris, more data centers coming soon, including one in Sweden). They focus on efficient, open and bespoke models that you own and can run on-prem. That seems to be their unique selling point compared to Anthropic or OpenAI.

The messaging was all about partnerships: collaborations with ASML, BNP Paribas, Amazon's Alexa+ and how they were helping them with AI to solve real problems. It was less about upcoming new models and tech innovation. Something I found disappointing. They did launch Vibe for Work, a product similar to Claude for Work.
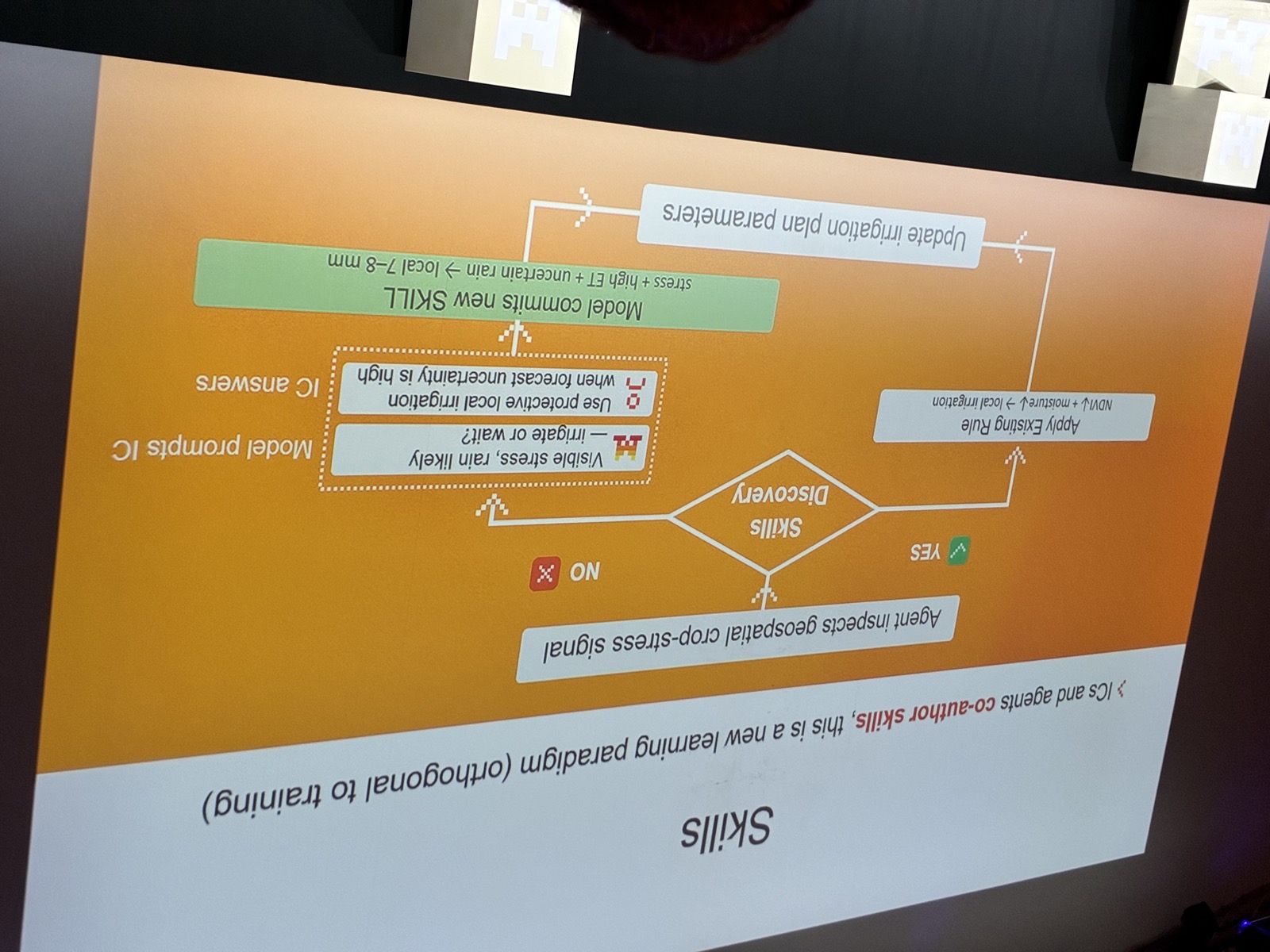
When it comes to agentic, the harness is everything. In a talk by Pieter Stock he mentioned that the model alone isn't enough. With a harness you add context, persistence and learning. Reasoning is essential for this; it's what lets a system backtrack, recover from errors and stay transparent. Skills are the way for organisations to capture best practices, you develop these in cooperating with the AI agent.
Specialized small models are their strategy. Mistral showed several examples where small, fast and focused models outperform the big general-purpose ones when it comes to energy efficiency and speed: Document AI for OCR (used by the EU Patent Office to do large scale OCR), Voxtral for multilingual voice (powering Amazon's Alexa+ in Europe), and Robostral for industrial robotics with ASML. And also in token-heavy agentic applications, speed and efficiency are becoming as important as raw capability.
Sovereignty and on-prem are their selling points. BNP Paribas runs Mistral models on-prem for KYC in Belgium, with sensitive data staying within the bank's walls. Abanca is using agent orchestration to handle sensitive customer information at a huge scale (more than 1 million customers in their app). For European companies in regulated industries, this is a good alternative to relying on US hyperscalers.
A talk that was a bit out of the ordinary and that I really enjoyed was about ancient papyrus documents: a research team from the Austrian Academy of Sciences finetuned a coding LLM by Mistral (Codestral) to read tiny snippets of millennia-old discarded papyri that had sat unpublished for decades. This work helps make a collection of 180,000 documents found in the Egyptian desert accessible, a job that would have taken more than 2000 years without AI. A beautiful example of how AI can also help the humanities.

All in all, the summit left me with a better picture of Mistral's vision for Europe an AI: maybe not to win the race for AGI (Artificial General Intelligence), but to become the European full-stack AI partner that delivers real return on investment NOW. Whether that pays off will depend on more European companies committing to this, but the combination of open models, on-prem deployment and enterprise partnerships could be appealing to many big organizations in the EU. And honestly, it's good to see a serious European player at the table. The days of blindly relying on US tech giants is coming to an end.
Post-script: Many thanks to Mistral for the invitation. The location was just perfect, in the middle of Paris near the Louvre, and it was really something to be in the place where Paris Fashion Week normally takes place: with co-founders and other speakers on the catwalk.
This article was also published on LinkedIn and Hacker News. Feel free to join the discussion there.