REDWOOD CITY, Calif., May 27, 2026 – Biohub today announced the release of a world model of protein biology: a scientific engine for prediction, design, and discovery that can map proteins across the tree of life, predict their structures, and design new protein binders that function in laboratory experiments.
Proteins are the machinery of life. Nearly every function of the human body depends on them. They are among the most important targets in medicine, yet designing functional, stable proteins that work as intended in the body is an immense scientific and technical challenge.

ESMC provides a foundation for modeling the sequence, structure, and function of proteins. ESMFold2 predicts the structure of proteins and biomolecular complexes with state-of-the-art accuracy and speed. Features derived from model representations capture fundamental principles of structure and function, forming a compositional grammar for protein biology.
Today, Biohub is making available to researchers everywhere an open discovery engine for protein structure prediction, design, and biological discovery built around three releases: ESMC, ESMFold2, and ESM Atlas:
- The core scientific hypothesis of ESM is that training a language model across the sequences of all life will cause it to internalize the fundamental properties that govern protein biology — the rules underlying how proteins fold, interact, and function across all of life. At its foundation is ESMC, a state-of-the-art language model that represents proteins, trained on approximately 2.8 billion sequences drawn from across all of life.
- ESMFold2 is the design engine built to transform ESMC’s sequence representations into atomically-resolved 3D structure of biomolecular complexes. In experiments described in a preprint, researchers used ESMFold2 to design protein binders against five targets central to cancer and immunology — a computational search completed in days, rather than several months or years. The lab-validated binders exhibited high affinity, specificity, and stability — properties critical for clinical utility — and showed minimal similarity to sequences in public databases, suggesting the model is producing de novo solutions, rather than retrieving known binders.
- ESM Atlas makes ESMC’s representations navigable across 6.8 billion protein sequences and 1.1 billion predicted structures — the largest application of AI to protein biology to date. It organizes proteins by relationships the model has learned, surfacing connections that existing databases have not captured, including evolutionary links between gene-editing enzymes spread across distant branches of life. Much of that biology has never been annotated. For researchers working on diseases where the biology is poorly understood, it makes uncharacterized biology searchable.
All three are freely available to the global scientific community at Biohub Platform.
“Designing the interactions between proteins is a fundamental problem in biochemistry, and critical for the design of medicines. What we’ve shown is that these models have learned such a high-fidelity world model of biology that you can design protein interfaces computationally, take them into the laboratory, and they function as predicted.”
— Alex Rives, Head of Science, Biohub
ESMFold2: A faster path from protein biology to binder design
ESMFold2 is an open, state-of-the-art structure prediction model that translates knowledge of patterns across evolution encoded in ESMC into precise, atomic-resolution 3D models of proteins and their interactions. It leads across standard protein folding benchmarks at predicting protein-protein and antibody-antigen interactions.
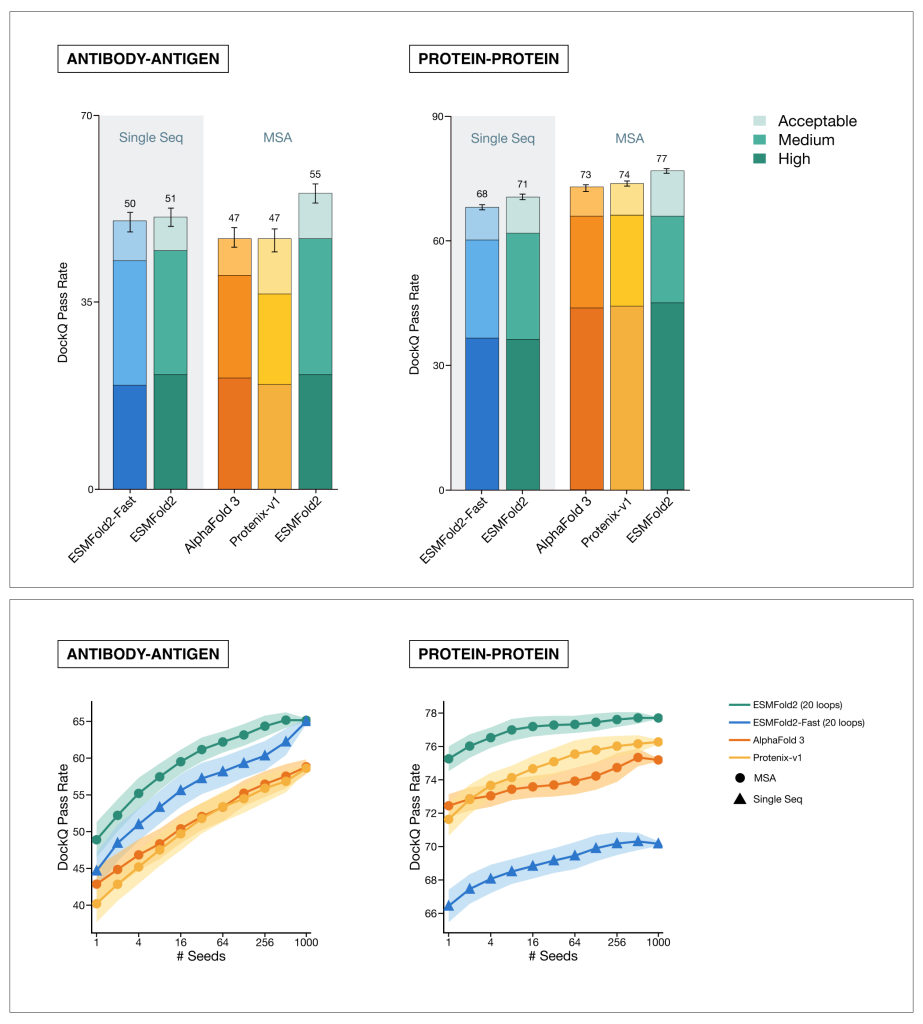
ESMFold2 achieves state-of-the-art accuracy in structure prediction, both for general protein-protein interactions and for the challenging and therapeutically relevant task of antibody-antigen prediction. From ESMC representations alone, ESMFold2 is more successful at predicting the true binding pose of antibody-antigen complexes than AlphaFold 3. When provided with the same evolutionary information (MSA) as AlphaFold, ESMFold2 is the strongest predictor on both benchmarks. Bottom: structure prediction models can benefit from a larger computational budget. When we let models make multiple predictions and score them based on their own confidence estimates, ESMFold2 consistently improves with more compute.
Antibody-based therapies have become a cornerstone of modern medicine, accounting for roughly one quarter of all new FDA drug approvals, spanning cancers, autoimmune diseases, and conditions that once had few treatment options. Finding a viable therapeutic candidate depends on identifying molecules that bind tightly and specifically to a disease target; a single preclinical binder candidate typically takes three to four years to develop. ESMFold2, which predicts the structural configurations most likely to achieve high affinity for a given target, can move much of the initial search into computation, producing experimentally testable designs in days.
Biohub researchers used the model to design protein binders against five targets at the center of cancer and immunology research — EGFR and PDGFRβ (implicated in tumor growth), PD-L1 and CTLA-4 (immune checkpoints that cancer cells exploit to evade detection), and CD45 (a regulator of immune cell signaling). Designs achieved hit rates of 36–88% for compact minibinders and 15–29% for antibody-derived formats, with confirmed binding in laboratory experiments. For PD-L1, designed binders restored T cell signaling in laboratory tests, blocking the same pathway that approved checkpoint therapies target.
ESMFold2 changes the accuracy and speed of early therapeutic binder discovery, transforming the initial search from largely empirical screening into computation-guided design that takes hours or days.
“Biohub was built on the belief that open science accelerates discovery. Making these tools freely available means researchers everywhere can move faster toward personalized cures that work for individual patients, because they target the specific biology driving their disease.”
—Dr. Priscilla Chan, Biohub Co-Founder
A shared, open scientific ecosystem built on a world model of protein biology
The world model of protein biology is trained on the evolutionary record of life itself, billions of protein sequences spanning the full breadth of life, including bacteria in deep soil, organisms in extreme environments, and the more than 20,000 types of proteins found in the human body. Its training objective is simple: predict the amino acids that evolution selects. Because evolution tends to preserve proteins that are fit for purpose, the patterns preserved across billions of years of data implicitly encode the physical rules governing protein function. What this work shows is that from this training, a world model emerges — one that has internalized those rules deeply enough to generate functional proteins from scratch.
Biohub’s mission is to cure and prevent disease. We believe the path to that goal is understanding biology at its deepest level — and making the tools of that understanding available to every scientist. Together, ESMFold2, ESMC, and ESM Atlas constitute a state-of-the-art, openly available ecosystem for protein structure prediction and design — a shared foundation for any researcher working on fundamental biology or the development of new therapeutics.
###
About Biohub
Biohub is a 501(c)(3) biomedical research organization building the first large-scale initiative to combine frontier AI and frontier biology to solve disease. With its compute capacity, AI research and engineering, and state-of-the-art technology for measuring, imaging, and programming biology, Biohub is enabling scientists worldwide to use AI-powered biology to study how cells operate and organize as systems — ultimately understanding why disease happens and how to cure or prevent it. Learn more at biohub.org.
Press Contact
press@biohub.org