{kind=link}
{kind=link}
Posted on Jun 1, 2026 · 10 min read
In my predictions for 2030 I wrote that tech writers would be using specialized LLMs, running locally on powerful hardware. I see hints of this move to “local first” among engineering pundits, but we’re not there yet, in part because of how much more powerful connected frontier models are. That doesn’t mean we can’t experiment, though. That’s precisely what I did last week, trying to fine-tune an instruct model to write like a software technical writer from the 80s and 90s.
Summoning old tech writing lore for research
To train a personal, local model to write like a technical writer from the 90s, one needs tons of written sources. If I wanted to fine-tune a model to write like myself, for example, this blog would not be enough, as it’s barely 100k words at the time of this post. You would need more samples for thorough training, and those are not easy to come by, nor simple to produce. The only quick way is to use an existing corpus. Where could I get one?
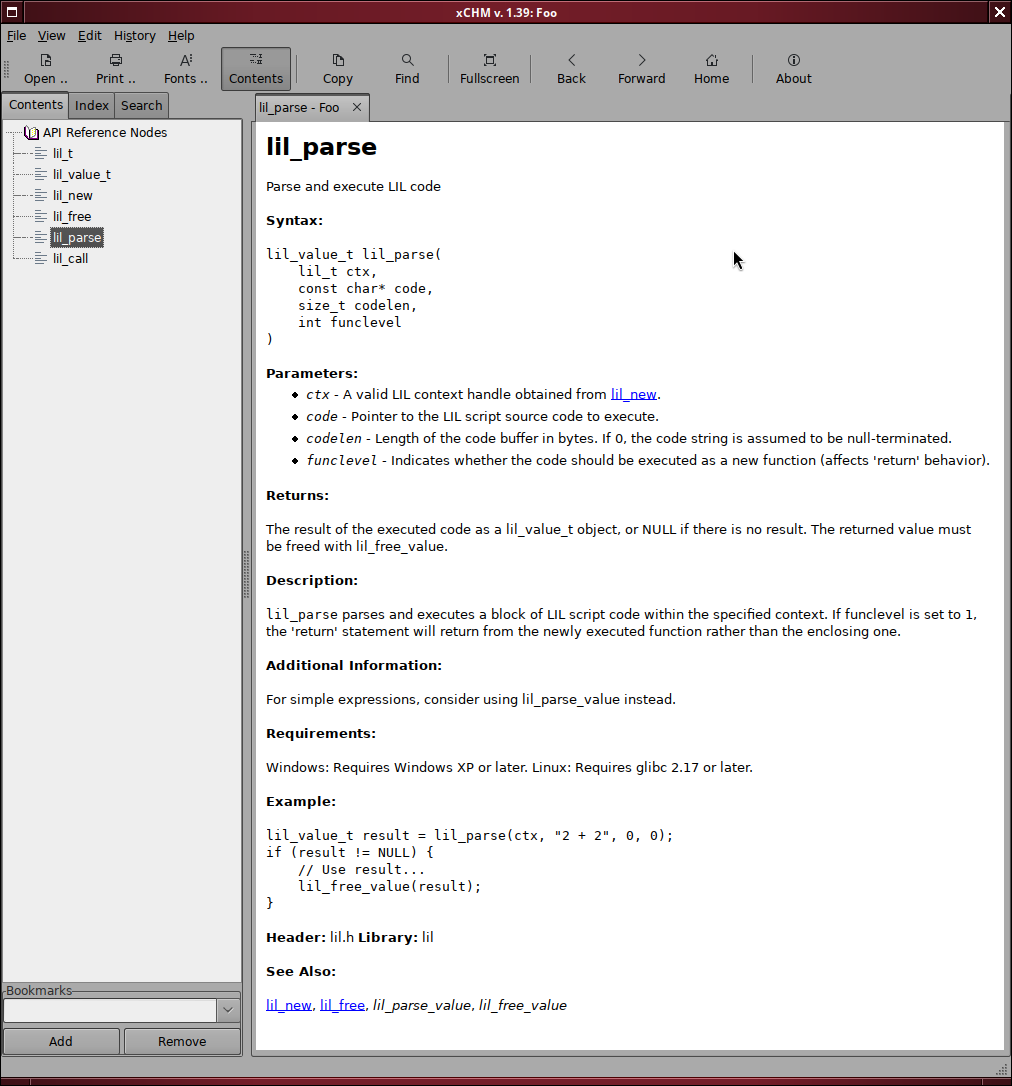
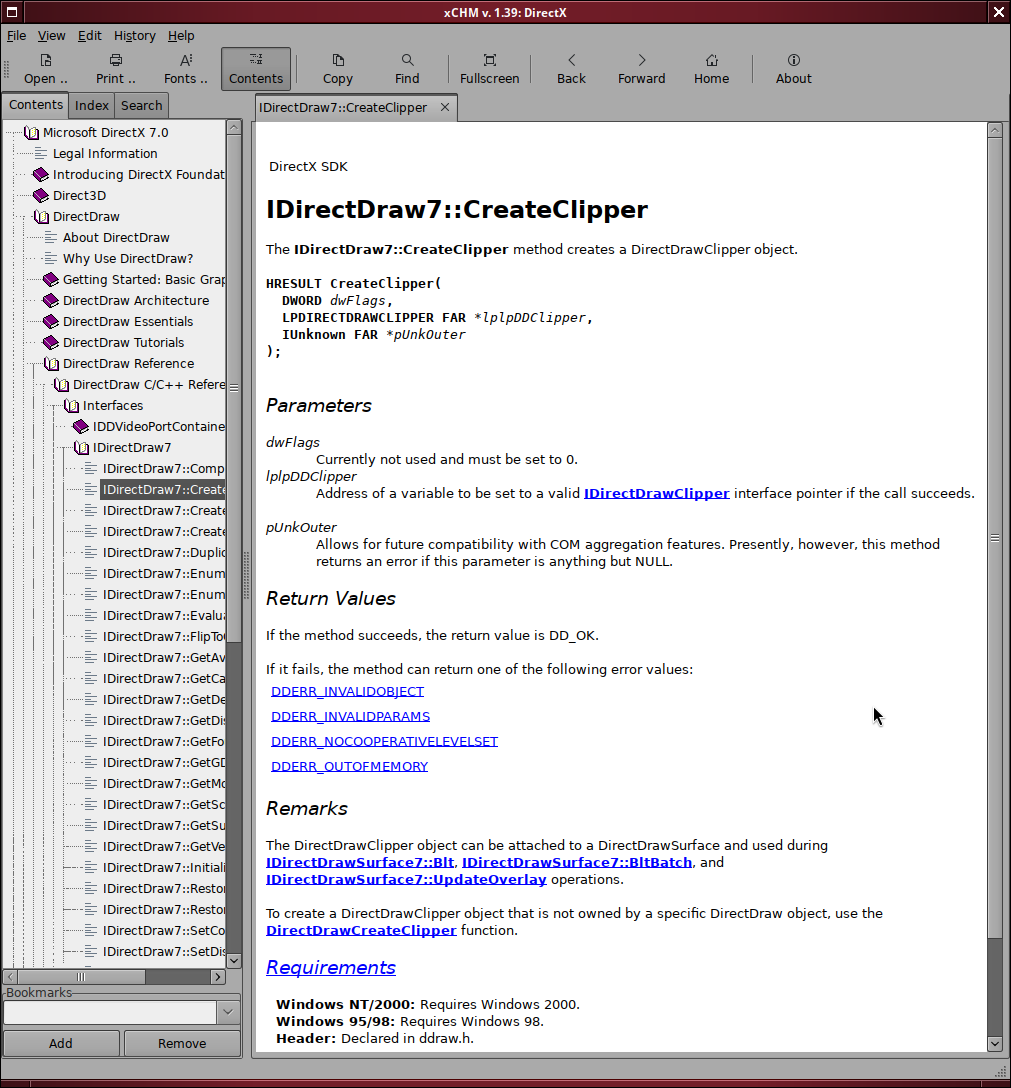
Meet Bitsavers: it’s a website that collects and scans old computer manuals and brochures. It’s an incredibly valuable repository of computer history and ancient tech writing, with mirrors available everywhere. As I’m fond of Microsoft manuals from the 90s, I chose the Microsoft collection as the source of training materials. The collection contains out-of-print docs published between 1977 and 2005: more than 37 million words, covering old systems and SDKs.

I downloaded the OCR’d text files and cleaned the content from artifacts and clutter (like indices and frontmatter) using good old Python scripts. I then used a cheap and fast model through OpenRouter, gemma-4-26b, to classify each paragraph as either “keep” or “drop” based on its intelligibility. This second pass cost around 8 dollars. Even with this two-pass cleaning, though, training data retained noise that I discovered only later, but that was largely OK for my tests.
I split the sanitized text into training examples on paragraph and section boundaries, breaking at headings and keeping code blocks whole, with each chunk capped at around 512 tokens as per Claude advice. Each chunk was paired with a synthetic instruction drawn from templates. I ended up with 192,456 examples in JSONL format (one JSON object per line). I could have used a small model to also come up with better instructions and questions, but I’m an impatient person.
💡 A note on the materials: This is an independent, non-commercial research project and is not affiliated with, sponsored, or endorsed by Microsoft. I used these out-of-print manuals for personal style-transfer experimentation only. The corpus, training data, and resulting adapters are not being distributed, and the fine-tuned models remain strictly local to my machine.
Fine-tuning as an alternative to training from scratch
In an ideal world, I would have several millions of dollars lying around, ready to be burned creating my own LLM, Fabrice. Since I’m far from rich (I wouldn’t be writing this otherwise), the alternative to Fabrice is fine-tuning, which involves tweaking the “weights” of a model so that each token generated is conditioned by the training materials. I like to picture fine-tuning as slightly steering the trajectory of a massive iceberg using tugs; just a little, just to get the intended effect.
Why fine-tuning and not, say, retrieval-augmented generation (RAG)? Because in this experiment I was not so much interested in retrieving facts, a scenario where RAG excels, as in getting an LLM to behave and write in a specific style, whatever its knowledge of the context. Compared to full training, fine-tuning doesn’t require a massive amount of data, so it’s cheaper. Also, just because: I always wanted to try fine-tuning as a technique and see how feasible it could be.
To avoid spending days or weeks fine-tuning a model on my computer, which has a rather old graphic card, I relied on Runpod, an online service for AI developers that provides on-demand pods with pre-configured GPUs and tools for a (relatively) small price. For less than $6 per hour, for example, you can lease a beast of a card, the Nvidia B200 (192gb of memory). The service has a convenient API with configurable auto-recharge and cost control mechanisms.
Entering a world full of mysterious buzzwords
After deciding to fine-tune a model, I consulted with Claude on the sanest methods to achieve that. We settled on QLoRA (Quantized Low-Rank Adaptation), which achieves fine-tuning not by altering each weight of an LLM, but by “freezing” them and putting an adapter on top, which is a small file that reshapes the model behavior (a bit like a mask, if you will). The Q in QLoRA means that the result is quantized, that is, compressed, reducing memory requirements.
Are you still with me? Good. If you think this is dense, it’s because it is.
Doing anything with LLMs at home these days is an exercise in compromises: you either sacrifice time, spend money, or curb your ambitious goals. I tried to strike a balance to get something meaningful in less than a weekend. I chose to try fine-tuning on two models, Llama 3.1 8B Instruct and Qwen 2.5 7B Instruct. At their size (around 8B) they run comfortably on a Macbook Air. I also tested a Llama base model (which is not trained to answer questions).
I tested fine-tuning under several different conditions: varying the volume of training materials (a subset vs. the full corpus), the number of epochs (training rounds), and structural parameters like the rank. I only hold a superficial knowledge of all this, but I trusted my agent to make the right choices, which I happily questioned at every step. For example, 3 epochs can result in “overfitting” in some cases; in the world of LLMs, that translates to excessive training. Fun times.
| Run | Base | Data | Epochs | Rank |
|---|---|---|---|---|
| Llama instruct-40k | Llama 3.1 8B Instruct | 40k | 1 | 16 |
| Llama base-40k | Llama 3.1 8B (base) | 40k | 1 | 16 |
| Qwen-40k | Qwen 2.5 7B Instruct | 40k | 3 | 16 |
| Qwen-192k | Qwen 2.5 7B Instruct | 192k | 1 | 16 |
| Qwen-r8 | Qwen 2.5 7B Instruct | 40k | 1 | 8 |
| Qwen-r16 | Qwen 2.5 7B Instruct | 40k | 1 | 16 |
Adapters can only be applied to the target model you fine-tuned for. After training each adapter, I exported them to my laptop and converted and quantized them to a GGUF LoRA file, and then registered it as a local Ollama model I could run in my laptop for benchmarking purposes. The local-conversion approach is faster and requires no GPU, though inference is somewhat slower than a fully merged model. For the test at hand, I did not care about speed that much.
Training the adapters for all conditions took perhaps an entire day, including breaks, for a total cost of $50. Along the journey, I lost two adapters: Runpod is unforgiving of budget and deletes pods immediately if funding is zero (there’s a lesson learned, yes). Claude took care of setting up each run and following up with Runpod’s API. The /goal command of Claude Code was quite helpful to loop through each phase (in retrospect, I would have run it in YOLO mode).
This table shows all the models I compared and their conditions:
| Name | What it is |
|---|---|
llama3.1:8b |
Unmodified Llama baseline |
qwen2.5:7b |
Unmodified Qwen baseline |
msft-base-40k |
Llama base (non-instruct) + 40k (control) |
msft-instruct-40k |
Llama instruct + 40k, 1 epoch, rank 16 |
msft-qwen-40k |
Qwen + 40k, 3 epochs, rank 16 |
msft-qwen-192k |
Qwen + 192k, 1 epoch, rank 16 |
msft-qwen-r8 |
Qwen + 40k, 1 epoch, rank 8 |
msft-qwen-r16 |
Qwen + 40k, 1 epoch, rank 16 |
Did the style transfer after fine-tuning?
I subjected each model to the same prompts:
- Document malloc(), a staple C function, something the training materials might know about.
- Document a fictitious ConnectWifi() Win32 API function. No presence in the training materials.
- Explain what a REST API is in 1990s Microsoft style (the anachronistic test).
You can see all the questions and answers in this gist.
For the malloc() test, the unmodified models generated modern Markdown docs in the style of a README, while the fine-tuned models used a period correct structure, with a Synopsis block, a Return Value section, and so on. For the fictitious ConnectWifi() function, only the 3 epochs model maintained the fiction and documented it as if it was real, while the others broke the fourth wall to adhere to internal knowledge and resist the training.
The REST API exercise was quite interesting, too: Llama Instruct 40k failed, producing bland marketing prose. Claude attributed this to the heavy reinforcement training (RLHF) that Llama goes through to make it friendly and accessible. Qwen fine-tunes held the register way better, producing period-structured docs, using HTTP method names as verbs and formal headings. Qwen 192k was the strongest, opening like a chapter of the Windows 2000 Resource Kit.

Let me repeat that: a 7B model, trained on 1990s documentation and tested on a 2000s concept, produced a convincing chapter opening that could be mistaken for genuine period material. Style transferred. Wow. On the other hand, the base model, which is not trained to answer questions, but to autocomplete text, failed miserably, spurting raw corpus almost at random, hundreds of lines of garbage. Base models have no notion of “answer this question” or “complete this".
| Model | malloc() | ConnectWifi() | REST API |
|---|---|---|---|
llama3.1:8b |
Modern style, markdown headers | Plain English, no Win32 vocabulary | Modern, friendly, analogies |
qwen2.5:7b |
Modern style, good structure | Correct form, breaks frame | Modern essay, labels itself “1990s style” |
msft-instruct-40k |
Terse, period markers, correct vocabulary | SAL annotations, ERROR_SUCCESS | Failed: marketing prose |
msft-qwen-40k |
Man-page structure, ENOMEM | Commits to fiction, invents constants | Holds register |
msft-qwen-192k |
Full man-page, See Also, example | Breaks frame (caveats) | Strongest: chapter-style, HATEOAS |
msft-base-40k |
Ignores prompt entirely | Ignores prompt entirely | Ignores prompt entirely |
I finished the experiment by comparing the effect of rank between Qwen models, with 1 epoch, varying between rank 8 and 16. If I understood it correctly, rank 8 means each adapter matrix can only describe 8 independent patterns. It’s like having 8 dials to tune. With so few dials, the adapter can’t be too clever: it must commit fully to the strongest, most repeated patterns in the training data. Rank 16 is, in theory, more expressive and subtler.
| Model | malloc() | ConnectWifi() | REST API |
|---|---|---|---|
qwen2.5:7b baseline |
Modern explainer | Correct form, breaks frame | Long modern essay, labels itself |
msft-qwen-r8 (40k, 1ep, rank 8) |
Terse, correct vocab, minimal structure | Best of all models: full cross-refs, platform reqs, workflow | Chapter-style, “In This Section” |
msft-qwen-r16 (40k, 1ep, rank 16) |
Synopsis + Errors + example | Minimal, no frame-break | ⚠️ SOAP hallucination |
msft-qwen-40k (40k, 3ep, rank 16) |
Syntax + description + ENOMEM | Breaks frame with caveat | Holds register cleanly |
msft-qwen-192k (192k, 1ep, rank 16) |
Full man-page + See Also + example | Breaks frame with caveat | Best on REST: chapter outline, HATEOAS |
The rank comparison shows that smaller adapters, with fewer degrees of freedom, commit to fiction more readily than larger ones; a rank 16 adapter can “escape” the corpus more easily. It also turned out that combining only 1 epoch with a moderate rank of 16 made hallucinations more frequent: the adapter is expressive enough to reach for a related concept but not reinforced enough to anchor on what the prompt is trying to say. Rank and epoch seem to interact — it’s like using a sound mixer. Interestingly, the cheaper the adapter, the more honest the impersonation.
Fine-tuned models make for convincing impersonators, but they’re not replacements
The fine-tuned models were great impersonators of Microsoft tech writers from the late 90s. The corpus impressed style and voice on the models, as well as some knowledge, while mostly retaining the models’ ability to describe novel concepts. It’s a relatively cheap process that could produce effective small models aimed at tasks such as reviews of style or drafting of new documents following in-house style guides.
Getting there, though, is not a simple ride. Fine-tuning a model, while cheap, requires a good amount of high-quality training data, which is not easy to produce. Even when you get your hands on it, you need to pick an underlying model that makes sense and is capable of accepting the additional training. And then, the multiple parameters at your disposal make the task of getting a fine-tuned model to the sweet spot a time-consuming proposition.
The reassuring takeaway is that such a model can never replace a human tech writer, only augment them. The fine-tuned models have the same lack of judgement as their non-tuned siblings, and they need abundant steering. Fabrice will have to wait.