
OpenCV 5 is one of the most important releases in the history of OpenCV.
For more than two decades, OpenCV has been the foundation for computer vision research, robotics, embedded vision, AI applications, industrial inspection, AR/VR, medical imaging, and countless production systems. Today, the library has more than 86,000 GitHub stars, more than a million installs per day, and one of the largest collections of computer vision algorithms in the world.
OpenCV 5 builds on that foundation with a major modernization of the library. It brings a new DNN engine, stronger ONNX support, hardware acceleration improvements, better Python integration, new data types, expanded 3D vision capabilities, improved documentation, and a cleaner architecture for the future.
This is not just another incremental release. OpenCV 5 is a major step forward.
Why OpenCV 5
Computer vision has changed dramatically since OpenCV 4.
Modern applications now combine classical vision, deep learning, transformers, large vision models, edge deployment, heterogeneous hardware, and Python-first workflows. Developers expect the same code to run efficiently across laptops, servers, embedded devices, ARM chips, Snapdragon platforms, and specialized accelerators.
OpenCV 5 was designed to meet that reality.
The goals were clear: make the core faster and smaller, improve language support, clean up old APIs, modernize the DNN engine, support new hardware acceleration paths, improve 3D vision tooling, and make the documentation easier to use.
If you have shipped anything with OpenCV in the last few years, you know the feeling. The library does almost everything, but the deep learning side always felt a step behind the models people were really using. You would export a new model to ONNX, point OpenCV’s DNN module at it, and cross your fingers. Sometimes it worked. Sometimes it threw an error about an operator it had never heard of.
In this post we will walk through what is new, why it matters in practice, and what it changes for the code you write. You do not need to know the library’s internals. If you have ever written cv2.imread, you are in the right place.
The pip version of OpenCV5 will be released on 8th June.
Table of contents
- Why OpenCV 5
- Where OpenCV Stands Today
- What OpenCV 5 Set Out to Fix
- The Headline: A Brand-New DNN Engine
- Three Engines, One API
- How Fast Is It? OpenCV 5 vs ONNX Runtime
- Models That Run Out of the Box
- LLMs and VLMs, Running Inside OpenCV
- Inpainting and Diffusion with LaMa
- Modern Feature Matching, the Deep Learning Way
- A Faster, Leaner, More Modern Core
- Hardware Acceleration You Get for Free
- Better 3D Vision
- Documentation That Doesn’t Fight You
- What OpenCV 5.0 Ships With
- What’s Next: GPU in the DNN Engine and a Non-CPU HAL
- Try It and Get Involved
- Conclusion
Where OpenCV Stands Today
Before we get into what changed, it helps to remember how widely used OpenCV is. This is not a niche research tool. It is plumbing for a huge slice of the computer vision world.
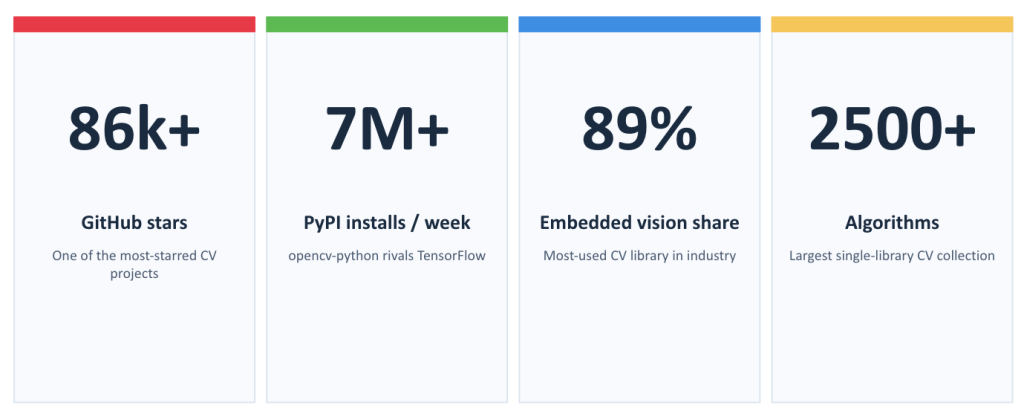
(Sources: github.com/opencv/opencv, pypistats.org, embedded-vision.com.)
When a library is this deeply embedded in production systems, every change has to be made carefully. That is part of why a major version takes time, and why it is a big deal when one finally arrives.
It also helps to know who builds it. OpenCV is stewarded by the non-profit OpenCV.org, with development and support coming from Big Vision (which supports the library, OpenCV University, and content like this blog), OpenCV China (a major force behind RISC-V and embedded work) and OpenCV.ai.
What OpenCV 5 Set Out to Fix
The team started OpenCV 5 with a clear list of pain points. If you have used OpenCV for a while, you will recognize most of them:
- Better language support: modern Python, refreshed bindings, and named arguments instead of guessing parameter order.
- A faster, smaller core: tighter code, the legacy C API retired, and leaner builds.
- A cleaner hardware acceleration layer, so vendors can plug in optimized kernels without a tangle of #ifdefs.
- A cleaner API: proper 0D/1D tensors, native FP16/BF16, and real logging.
- A next-generation DNN engine: graph-based, with fusions, broad ONNX support, transformers, and VLM/LLMs.
- Better 3D vision: ChArUco, multi-camera calibration, and visualization.
- Better documentation: modern, navigable, and pleasant to read.
The rest of this post is that list, made real. We will start with the change that affects the most people.
The Headline: A Brand-New DNN Engine
The single most important number in this release is coverage. OpenCV’s ONNX operator support jumped from roughly 22% in the 4.x days to over 80% in OpenCV 5.
If you have ever fought with OpenCV refusing to load a modern model, that number is the fix. The reason behind it is more interesting than the number itself.
The old 4.x engine imported a small fraction of the ONNX operator set and struggled with anything that had dynamic shapes, which covers most interesting models these days. The 5.x engine was rebuilt around a typed operation graph with proper shape inference, constant folding, and operator fusion. Instead of treating a network as a flat list of layers and walking them one by one, OpenCV 5 understands the model as a graph. That lets it reason about the network, simplify it, and run it far more efficiently.

ONNX operator coverage, then and now.
A few things the new engine handles that the old one could not:
- If and Loop subgraphs: models with control flow now load and run.
- Symbolic and dynamic shapes: no more brittle “shapes must be known ahead of time.”
- Quantize/Dequantize (QDQ) graphs: for running quantized models.
- Attention and MatMul fusions: the building blocks of transformers, collapsed into efficient fused operations.
That last point deserves a closer look. One of the headline optimizations is attention fusion. The engine recognizes the classic MatMul → Softmax → MatMul pattern at the heart of every transformer and collapses it into a single fused attention operation, backed by a FlashAttention-style implementation. You get this for free. Load your model, and it runs faster.
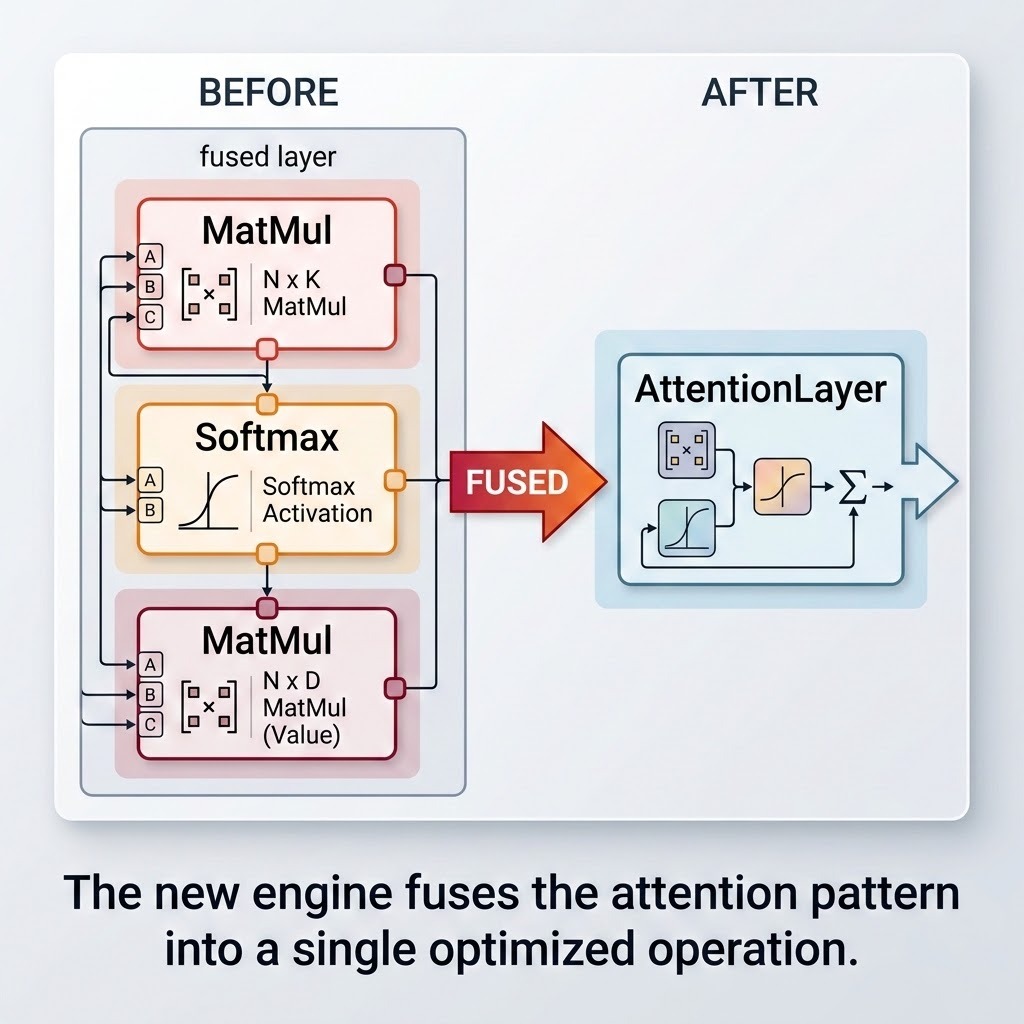
| Aspect | Classic engine (4.x) | New engine (5.x) |
|---|---|---|
| Model representation | One struct per layer, walked in order | A typed graph the engine can analyze |
| Shapes | Static only | Symbolic, dynamic |
| Subgraphs | Not supported | If and Loop supported |
| Fusion | Limited | QDQ, BatchNorm, Attention, MatMul, Softmax, and more |
| Memory | Reused per layer | A unified buffer pool that reuses memory aggressively |
The practical result is straightforward. More models load, more models run correctly, and many of them run faster.
Three Engines, One API
Rewrites make people nervous, and rightly so. Nobody wants a working pipeline to break on upgrade day. OpenCV 5 handles this by keeping more than one engine available behind the same DNN API. You choose which one loads your model right where you read it, through an engine argument on the readNet* family of functions. The values come from the cv::dnn::EngineType enum:
| Value | Meaning |
| ENGINE_CLASSIC (1) | Force the old 4.x-style engine. This is the path that supports non-CPU backends and targets such as CUDA and OpenVINO. |
| ENGINE_NEW (2) | Force the new graph engine, with fusion and dynamic shapes. It runs on CPU only for now. |
| ENGINE_AUTO (3) | The default. Try the new engine first, and fall back to the classic engine if the model fails to load. |
| ENGINE_ORT (4) | Use the bundled ONNX Runtime wrapper. ONNX models only, and the build must be configured with WITH_ONNXRUNTIME=ON. |
Because ENGINE_AUTO is the default, most code does not have to do anything special. You read the model, and OpenCV uses the new engine when it can and the old one when it cannot. When you want to pin a specific engine, you pass it at load time.
Python
import cv2 as cv
Default behaviour (ENGINE_AUTO): new engine first, classic as fallback.
net = cv.dnn.readNetFromONNX("model.onnx")
Or pin the new graph engine explicitly.
""" net = cv.dnn.readNetFromONNX("model.onnx", engine=cv.dnn.ENGINE_NEW) """ net.setInput(blob) out = net.forward()
cpp
#include <opencv2/dnn.hpp> using namespace cv;
// Default behaviour (ENGINE_AUTO). dnn::Net net = dnn::readNetFromONNX("model.onnx");
// Or pin a specific engine at load time. /* dnn::Net netNew = dnn::readNetFromONNX("model.onnx", dnn::ENGINE_NEW); */ net.setInput(blob); Mat out = net.forward();
One practical detail is worth knowing. The new engine is CPU-only at the moment, so if you select a non-CPU backend and target (for example CUDA or OpenVINO through setPreferableBackend and setPreferableTarget), you will want the classic engine.
The OpenCV samples handle this for you by switching to ENGINE_CLASSIC when you pass a non-default backend or target on the command line.
This design keeps upgrade-day risk low. The old engine is still there for anything the new one cannot load yet or cannot accelerate, and the optional ONNX Runtime path (when built in) widens coverage further, all through the same Net API.
How Fast Is It? OpenCV 5 vs ONNX Runtime
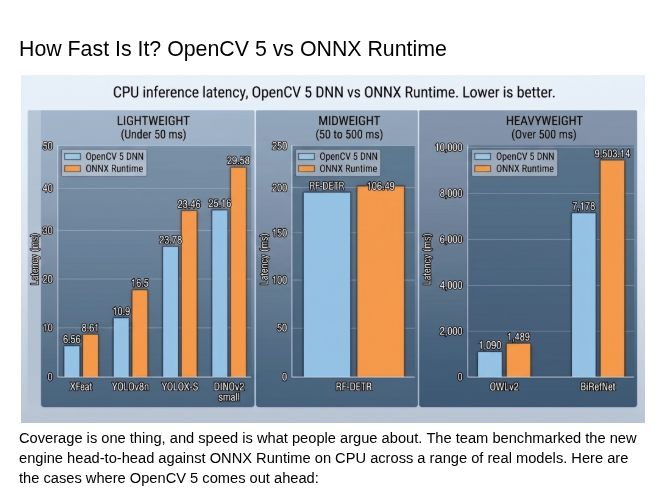
Coverage is one thing, and speed is what people argue about. The team benchmarked the new engine head-to-head against ONNX Runtime on CPU across a range of real models. Here are the cases where OpenCV 5 comes out ahead:
| Model | OpenCV 5 DNN (ms) | ONNX Runtime (ms) | Difference |
|---|---|---|---|
| XFeat | 6.56 | 8.61 | 31.25% faster |
| YOLOv8n | 10.9 | 12.15 | 11.5% faster |
| YOLOX-S | 23.46 | 25.16 | 7.24% faster |
| DINOv2 small | 23.78 | 29.58 | 24.4% faster |
| RF-DETR | 102.01 | 106.49 | 4.4% faster |
| OWLv2 | 1,090 | 1,489 | 36.6% faster |
| BiRefNet | 7,178 | 9,503.14 | 32.4% faster |
Hardware: Intel Core i9-14900KS, Ubuntu 24.04 LTS. Lower latency is better. The difference is how much faster OpenCV 5 DNN is than ONNX Runtime on the same model and machine.
The pattern holds across the board. From tiny real-time detectors like YOLO26n to heavyweight open-vocabulary models like OWLv2, OpenCV 5’s native engine is competitive with, and often faster than, a mature and heavily optimized runtime, all while keeping everything inside a single dependency. A comprehensive benchmark can be found at OpenCV5 DNN Benchmark.

Real-time RF-DETR detection running entirely through the new DNN engine.
Models That Run Out of the Box
Better ONNX coverage stays abstract until you see the list of models it unlocks. OpenCV 5 has been validated against a broad, modern lineup spanning detection, segmentation, backbones, and generative models:

If your project depends on any of these, OpenCV 5 means one fewer framework in your dependency list.
LLMs and VLMs, Running Inside OpenCV
This one still surprises people. OpenCV 5 can run large language models and vision-language models directly inside the DNN module, with no separate runtime.
To make that work, OpenCV 5 ships two things that classic CV libraries never needed:
- a native tokenizer, built into the library, and
- a KV-cache for autoregressive decoding, so generation stays efficient as the model produces tokens one at a time.
These work across Qwen 2.5, Gemma 3, PaliGemma, and the GPT-2 / GPT-4 family, all through the same Net API you already use for a YOLO model. Vision-language pipelines (image in, text out) are supported through models like PaliGemma.

In the team’s tests, asking Qwen 2.5 “What is OpenCV?” through OpenCV’s engine produced output that matched ONNX Runtime token for token. That is a reassuring sign that correctness was not traded away for the convenience of keeping everything in one library.
Will OpenCV replace a dedicated LLM serving stack for a production chatbot? No, and it does not aim to. What it gives you is a vision pipeline that can reach for a small language or vision-language model for tasks like captioning, OCR post-processing, or open-vocabulary queries, without bolting on a whole separate framework.
Inpainting and Diffusion with LaMa
One of the most satisfying demos in the release is object removal with LaMa, running entirely inside the new DNN engine. You give it an image and a mask of what to remove, and it fills the hole back in with blended edges and no external runtime.

Mask in, clean image out. LaMa inpainting in a single forward pass.
The flow is as simple as it sounds:
- Input image: the photo with something you want gone.
- Mask: the region to remove, either drawn by a user or produced by a detector.
- One forward pass: a single Net::forward through the OpenCV DNN engine.
- Clean output: the hole filled and the edges blended.
And the code really is this short:
import cv2 as cv
net = cv.dnn.readNetFromONNX("lama.onnx") blob = cv.dnn.blobFromImages([img, mask], scalefactor=1/255.) net.setInput(blob) out = net.forward() # inpainted image
A ready-to-run version lives at samples/dnn/inpainting.py in the OpenCV 5.x branch, and there is a diffusion-based inpainting sample (samples/dnn/ldm_inpainting.py) if you want to go further.
Modern Feature Matching, the Deep Learning Way
Feature detection and matching is one of OpenCV’s oldest jobs. It powers panorama stitching, image alignment, and a lot of 3D reconstruction. For years that meant SIFT and ORB. OpenCV 5 brings the modern, learned approach into the library as a first-class citizen.
The new Features module, which replaces Features2D, adds a complete neural pipeline for detection, description, and matching:
- cv::ALIKED: a CNN-based keypoint detector and descriptor that drops straight into the same call sites you used for SIFT or ORB.
- cv::DISK: learned features trained with reinforcement learning, strong on wide-baseline and low-texture scenes.
- cv::LightGlueMatcher: an attention-based matcher that produces confidence-scored matches and plugs into the stitching module.
The classic detectors (SIFT, ORB, FAST, GFTT, MSER) are still here, and the more obscure ones moved to opencv_contrib. So you can adopt the deep learning pipeline where it helps and keep the tried-and-true methods where they are enough.
The stitching module itself gets the upgrade through a new LightGlueFeaturesMatcher, so the classic task of stitching photos into a panorama now benefits from learned matching with no extra glue code on your side.
A Faster, Leaner, More Modern Core
Not everything in OpenCV 5 is about deep learning. The core that everything else builds on got a serious tune-up, and the benefits show up even in plain image processing code.
New data types. OpenCV 5 adds first-class FP16 (cv::hfloat, CV_16F) and BF16 (cv::bfloat, CV_16BF) types, plus bool, 64-bit integers, and more. These are the data types modern AI workloads use, so having them native means less converting back and forth.
Real N-dimensional and scalar support. cv::Mat can now represent 0D (scalar) and 1D arrays, which tripped people up for years because the old Mat always wanted at least two dimensions. Add broadcasting and first-class N-D operations like transposeND and flipND, and a lot of awkward reshaping code goes away.
Better performance. The team reports up to 2x improvements on mathematical workloads, and the same code now runs across CPUs and accelerators without modification.

Broadcasting comes to OpenCV’s core.
On the language side, the cleanup is just as welcome:
- The legacy C API is officially deprecated, removing a large amount of historical baggage.
- C++17 is now the minimum recommended standard, with C++20 modules planned for later 5.x releases.
- On the Python side, there is NumPy 2.x support, deeper integration, and named (keyword) arguments for C++ algorithms, so you can write cv.someAlgorithm(threshold=0.5) instead of memorizing positional order.
These are the kinds of changes you stop noticing after a week, precisely because they take daily friction away.
Hardware Acceleration You Get for Free
One of the quieter but most impactful ideas in OpenCV 5 is a redesigned Hardware Acceleration Layer (HAL).
In the old world, supporting different chips meant scattered conditional code and a lot of duplicated effort. In OpenCV 5, every core function routes through a single, clean HAL contract. Hardware vendors can plug in tuned kernels for their chips, and OpenCV uses them automatically when they are available. Your code does not change; it simply runs faster on supported hardware.
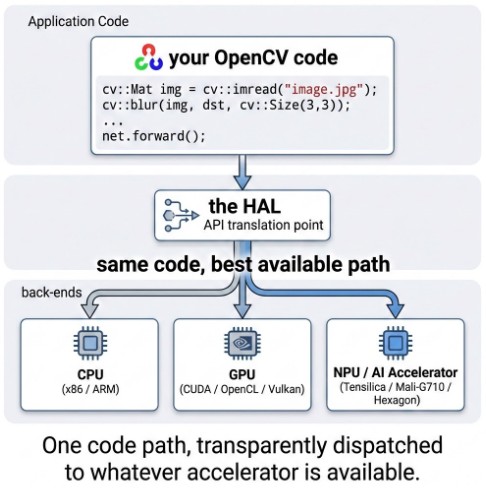
Several vendor-tuned paths are already wired in:
- Intel IPP (IPPICV): the original x86/x64 acceleration path from OpenCV’s Intel roots, now being restructured into a dedicated HAL in OpenCV 5. A free subset (ICV) ships by default, dispatching to SSE/AVX-optimized kernels for filtering, color conversion, and geometric transforms.
- Arm KleidiCV: a drop-in HAL for AArch64 that accelerates core image processing and DNN kernels using NEON, SVE, and SME, validated on AWS Graviton 4 and Cortex-A chips. It is selected automatically when available and speeds up everyday operations like Gaussian blur, resize, and warpAffine.
- Qualcomm FastCV: mobile-class acceleration on Snapdragon, routing through the Hexagon DSP and NPU.
- RISC-V Vector (RVV): scalable vector support, driven largely by OpenCV China.
Underneath all of this sits Universal Intrinsics 2.0, a single vector codebase that maps to SSE, AVX2/512, NEON, SVE, RVV, and more. It is mostly an internal detail, but it is the reason one implementation can target so many architectures, and the team reports 3-4x speedups on common ARM operations like resizing and warping because of it.
For you as a developer, the result is simple. Write OpenCV code once, and it uses the best path on whatever hardware it lands on, from a cloud ARM server to a phone to a RISC-V board.
Better 3D Vision
OpenCV’s 3D capabilities have grown a lot over the years, and the old monolithic calib3d module had become something of a junk drawer. OpenCV 5 splits it into three focused modules:
- 3d: basic 3D geometry and vision, including I/O, geometry primitives, algorithms like ICP, and parts of SLAM.
- calib: camera calibration, including single-camera calibration and a refactored multi-camera pipeline.
- stereo: depth from stereo.
The highlights developers will feel most:
- Multi-camera calibration through calibrateMultiview (N-camera bundle adjustment) and registerCameras for pairwise extrinsics, plus hand-eye and robot-world calibration for robotics.
- Point cloud and mesh I/O with loadPointCloud, savePointCloud, loadMesh, and saveMesh (OBJ, PLY).
- Dense RGB-D fusion with TSDF, HashTSDF, and ColorTSDF volumes, plus visual odometry.
- Robust estimation through a modern USAC framework (with MAGSAC), plus RANSAC plane and sphere fitting.
If you work on structure-from-motion, robotics, or any kind of reconstruction, this is a meaningful upgrade rather than a cosmetic reshuffle.
Documentation That Doesn’t Fight You
A small but welcome change: the docs have been rebuilt. OpenCV moved from plain Doxygen to a Sphinx + Doxygen pipeline. That brings a persistent left-hand navigation pane, hand-written tutorials sitting right next to the auto-generated API reference, Python signatures shown alongside C++, a link checker in pre-commit, and modern styling.
It sounds minor until you have spent an afternoon hunting for a function signature in the old layout. This is the kind of quality-of-life change that makes the whole library feel more approachable.
What OpenCV 5.0 Ships With
If you skim only one section, make it this one. Here is the at-a-glance comparison of OpenCV 5.0 against the 4.x line:
| Feature | OpenCV 5.0 | Compared to 4.x |
|---|---|---|
| ONNX coverage | 80%+ of operators | ~22%, a major jump |
| DNN engine | Rewritten graph engine with fusion and a buffer pool | No modern memory pooling or dynamic shapes |
| Optional backends | Drop-in ONNX Runtime via ENGINE_ORT | Native backend only |
| LLM / VLM support | Built-in tokenizer + KV-cache for Qwen / Gemma / GPT | Not available |
| Dynamic-shape ONNX | Native, via the new shape-inference engine | Brittle, with known bugs |
| 0D / 1D tensors | cv::Mat supports scalars and 1D arrays | Mat required at least 2D |
| Data types | Adds FP16, BF16, bool, 64-bit ints, and more | FP32, INT8, UINT8 mainly |
Target release: June 2026, timed with CVPR 2026 in Denver.
What’s Next: GPU in the DNN Engine and a Non-CPU HAL
OpenCV 5.0 is a big release, and it is also a foundation. Some of the most interesting pieces are deliberately built into the architecture now so they can be filled in over the 5.x cycle. Two of them stand out, and if you run heavy pipelines, they are the ones to watch.
Native GPU support in the new DNN engine
You may have noticed that every benchmark earlier in this post ran on a CPU. That is not an accident. The new graph engine landed CPU-first, and got that right, before chasing accelerators. Today, if you want GPU inference, you reach for the ONNX Runtime backend (ENGINE_ORT) and its execution providers like CUDA and TensorRT, which is a perfectly good option.
The roadmap is to bring GPU acceleration to the native engine itself. The whole point of the graph-based design, with its typed ops, shape inference, fusion, and unified buffer pool, is that it gives the engine the information it needs to schedule work on a GPU intelligently rather than only on a CPU. As that support matures, you should be able to get GPU speed straight from OpenCV’s own engine, using the same Net API and without pulling in a separate runtime.
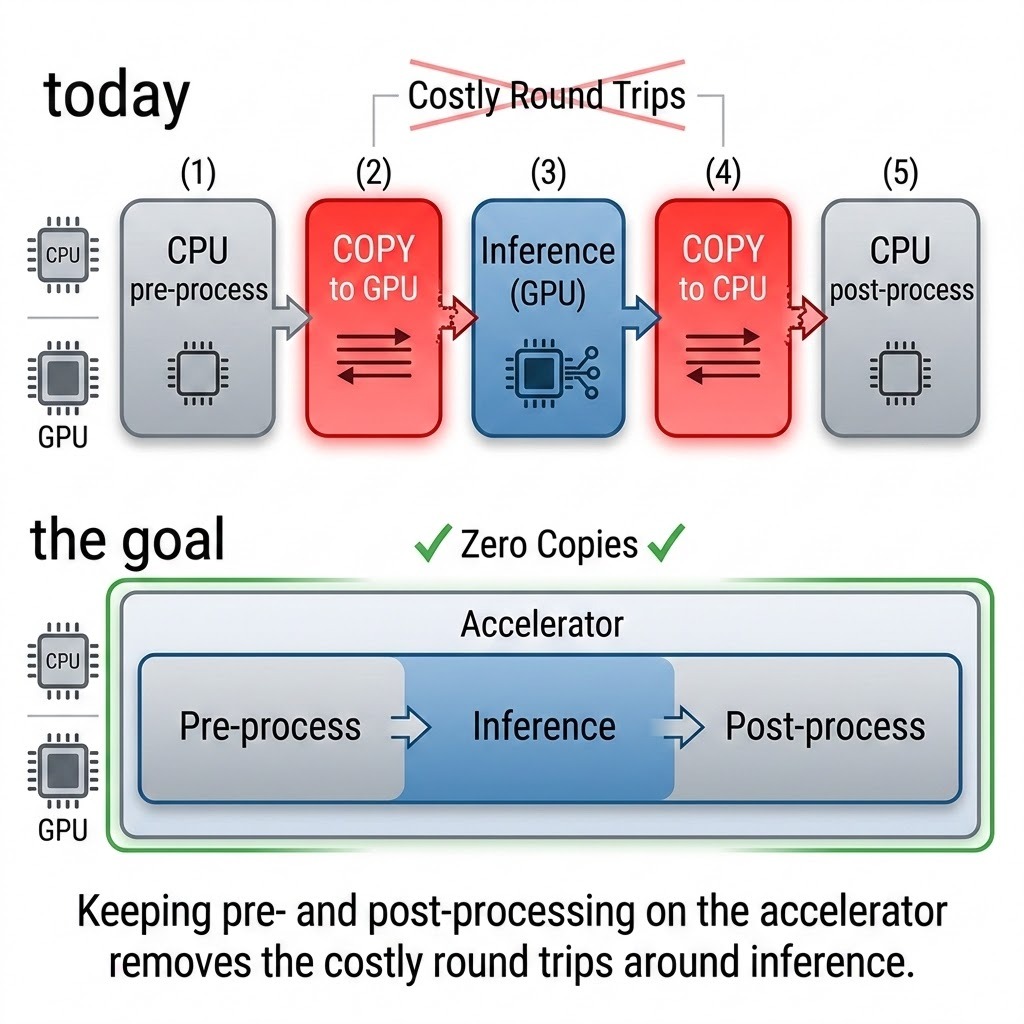
A non-CPU HAL for accelerated pre- and post-processing
This is the quieter half of the story, and arguably the more important one for real pipelines. The new HAL was designed with two paths: the CPU HAL described earlier, and a new non-CPU HAL that exposes the same surface area for GPUs, NPUs, and other accelerators.
Why does that matter? Because in most vision pipelines the model is only part of the work. Around every forward() call there is a stack of image operations: resize, color conversion, normalization, and letterboxing before the model, then non-maximum suppression, mask resizing, and overlay drawing after it. Today a lot of that pre- and post-processing runs on the CPU, which means the data gets copied to the accelerator for inference and back to the CPU for the surrounding steps. Those round trips are often the real bottleneck, not the model itself.
The goal of the non-CPU HAL is to let those everyday imgproc functions run on the same accelerator as the model, so the data can stay put. Keep the frame on the GPU, do the resize and normalize there, run inference there, do the post-processing there, and bring back only the final result. For high-throughput or real-time workloads, removing those copies can matter as much as a faster model.
Together, these two efforts point at the same destination: writing ordinary OpenCV code and having the whole pipeline, not only the model, run on whatever hardware you have, transparently. The plumbing is in place in 5.0, and the rest will arrive across the 5.x series.
Try It and Get Involved
OpenCV is a community project, and this release is a good moment to jump in.
- Get the code: https://github.com/opencv/opencv/tree/5.x
- Wiki: https://github.com/opencv/opencv/wiki/OpenCV-5
- Read the docs: docs.opencv.org
- News and downloads: opencv.org
- Contribute: look for issues tagged help-wanted, or take part through GSoC
- Support the project: OpenCV membership (Gold / Silver / Bronze) and OpenCV University courses help keep development going
The team is gathering feedback during the 5.x cycle, and that feedback shapes the final release. If you try it and something breaks, or something delights you, say so.
Conclusion
OpenCV 5 is big in both senses: big in scope, and big in the day-to-day difference it makes. The rewritten DNN engine alone closes the most common source of frustration with the library, pushing ONNX coverage past 80% and adding dynamic shapes, fusion, and built-in LLM and VLM support. Around it sit a faster, more modern core, an API cleanup that removes years of friction, transparent hardware acceleration through the new HAL, and a much-improved 3D vision toolkit.
What stands out is the restraint. Three DNN engines sit behind one unchanged API, the classic detectors stay alongside the new neural ones, and the old engine is preserved for compatibility. OpenCV 5 modernizes aggressively without leaving its huge existing user base behind.
If you have kept a modern model on the shelf because OpenCV could not load it, this is the release to revisit. Grab the 5.x branch, point it at that model, and see how far things have come.