![]()
June 8, 2026
MiMo-V2.5-Pro-UltraSpeed: Pushing 1T-Parameter Model Generation Speed to 1000 TPS
1. Xiaomi MiMo-V2.5-Pro-UltraSpeed: Speed is the Ultimate Edge
From the first roaring racer of the combustion age to the sonic boom that shattered the sound barrier, humanity's hunger for speed is written into our very DNA. The speed of AI reasoning is no different — it defines the boundaries of intelligence itself. When a model is fast enough, it ceases to be a tool you wait on and becomes an extension of your own thinking: responding in real time, iterating in an instant, collaborating without friction.
Today, we are thrilled to release Xiaomi MiMo-V2.5-Pro-UltraSpeed in collaboration with TileRT, breaking the 1000 tokens/s decode speed on a 1-trillion-parameter model for the first time!
MiMo-V2.5-Pro UltraSpeed real-time generation speed comparison (up to ~1200 tokens/s)
2. Limited-Time Access · Application-Based
The MiMo-V2.5-Pro-UltraSpeed API launches simultaneously at a limited-time promotional price — 3× the cost of MiMo-V2.5-Pro, but delivering approximately 10× the generation speed! 3× the price, 10× the output experience. (API only; Token Plan not supported.)
Due to limited high-speed inference resources, MiMo-V2.5-Pro-UltraSpeed will be available through an application-based, limited-time window. Approved users can access the API during the trial period, available only from June 9 to June 23, 2026, 23:59 (Beijing Time, UTC+8 / 08:59 PDT).
How to Apply
API platform: platform.xiaomimimo.com/ultraspeed. Trial slots are limited — submission does not guarantee approval. We will prioritize enterprises and professional developers with genuine business needs. For standard model access, please follow the MiMo-V2.5 model series. For in-depth business partnerships for the UltraSpeed model, contact business-mimo@xiaomi.com.
Chat Experience (Free During Trial)
Approved users will receive free Chat access valid within the two-week window. Entry point: ultraspeed.xiaomimimo.com
To ensure quality and fairness under resource constraints, the following rules apply: each account may enter the queue up to 10 times per day; each session is capped at 30 minutes; sessions idle for more than 5 minutes will be automatically released.
3. 1000 tokens/s: Not Just Fast, But a Paradigm Shift
At the trillion-parameter (1T) scale, breaking 1000 tps is far more than a faster typewriter — it fundamentally disrupts AI application paradigms.
First, speed itself begins to transmute into intelligence. Previously, when facing a hard problem, you could only "wait for one answer and pray it's correct." Now, within the same wall-clock time, the model can run dozens of reasoning paths in parallel (Best-of-N / Tree Search), automatically verifying and self-correcting in the background — using raw speed to generate depth of thought, directly elevating reasoning quality.
Second, it completely unleashes the productivity ceiling of Coding Agents. Before, having AI write code meant developers painfully waiting in front of screens, bottlenecked by inference latency. At 1000 tps, code generation speed and production efficiency undergo a paradigm-level acceleration.
Most importantly, trillion-parameter models can now enter real-time decision loops. Millisecond-level "think-respond" cycles allow 1T flagship models to seamlessly plug into time-critical scenarios — high-frequency quantitative trading signal generation, instant anti-fraud interception, intelligent bidding, and real-time interactive dialogue. And when this power is brought to surgical assistance and medical imaging analysis in life-or-death situations, AI speed is no longer just a metric of efficiency — it becomes a chip in the race against death. On the operating table, every second AI saves in completing lesion analysis and risk prediction gives the surgeon one more degree of freedom. This deepens our conviction that the ultimate significance of speed is not merely boosting productivity, but enabling technology to help humanity live better.
4. Extreme Model-System Codesign
Achieving 1000+ tokens/s generation speed with a 1T flagship model is not the breakthrough of a single technique — it is the product of deep collaboration and extreme Codesign between the MiMo model team and the TileRT system team. The industry's current approach to similar extreme speeds typically relies on specialized hardware — Cerebras's Wafer-Scale integration or Groq's pure on-chip SRAM custom architecture. We chose a different path: achieving even more impressive inference speed on commodity GPUs through model-system codesign alone.
On the model side, we applied FP4 quantization targeting the bandwidth bottleneck of commodity hardware, dramatically shrinking model size and reducing memory-access overhead; simultaneously, we introduced DFlash, an efficient speculative decoding method based on block-level masked parallel prediction, substantially increasing the accepted token length per verification step. On the system side, TileRT perfectly adapts to the dynamic characteristics of these algorithms, delivering a tailor-made compilation engine and compute kernels optimized specifically for the novel quantization and speculative decoding pipeline. Through this extreme Codesign, we achieved 1000+ tokens/s output from a 1T model using just a single standard 8-GPU commodity node.
3.1 FP4 Quantization
At the trillion-parameter (1T) scale, traditional 8-bit (FP8 / INT8) or even 16-bit inference imposes prohibitive memory footprint and bandwidth pressure. Reducing parameter bit-width directly contributes to decoding speed. We therefore adopt the widely validated, virtually lossless FP4 (MXFP4) quantization format[1].
However, naively applying FP4 across the entire model causes degradation in complex reasoning, logic, and code generation. Given the MoE (Mixture of Experts) architecture of Xiaomi MiMo-V2.5-Pro — where Experts constitute the vast majority of parameters and exhibit the highest tolerance to quantization — we selectively quantize only the MoE Experts to FP4 while preserving original precision for all other modules. Through FP4 QAT (Quantization-Aware Training), we dramatically reduce model size and maximize hardware bandwidth utilization while keeping the model's overall capability essentially on par with the original, as shown below:
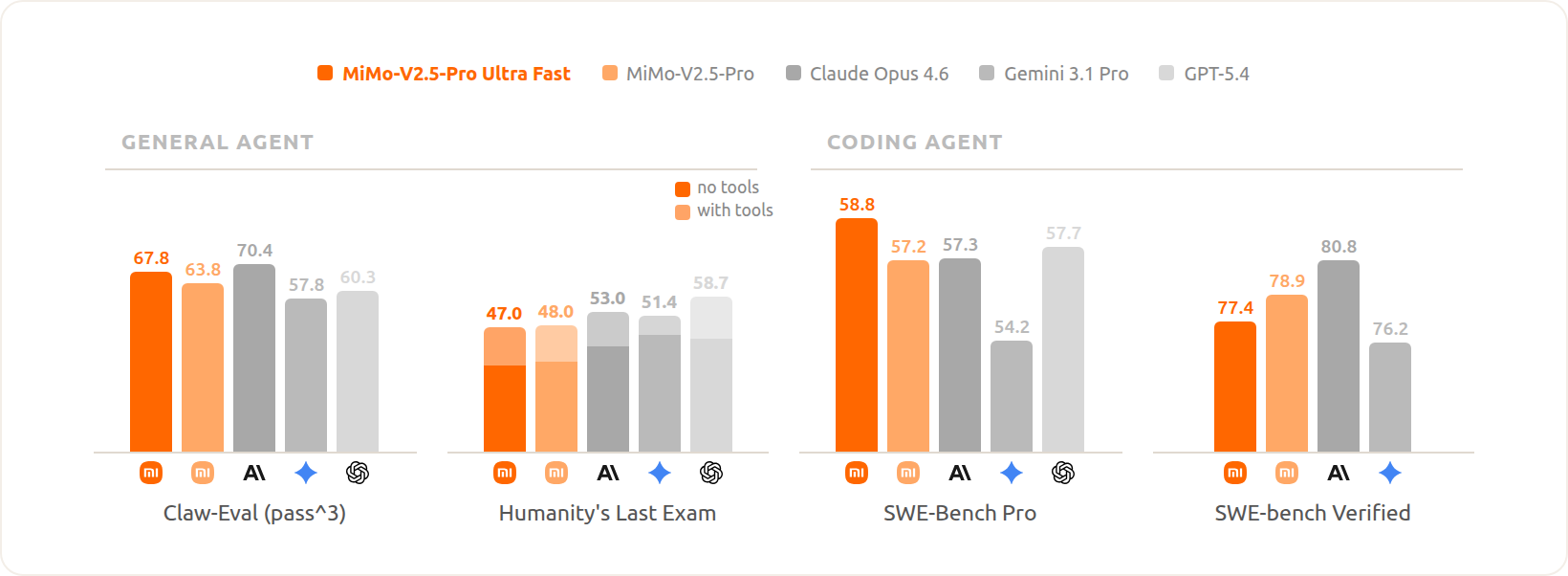
Model capability comparison between FP4 quantization (MoE Experts only) and FP8 across benchmarks, with overall capability essentially on par with the original model
3.2 DFlash Speculative Decoding
Traditional Speculative Decoding relies on a small draft model to "guess" subsequent tokens, which the large model then verifies. This transforms autoregressive generation (1 token per forward pass) into parallel multi-token generation, with rejection sampling during verification ensuring lossless output quality. However, its bottleneck lies in the draft model's quality determining the acceptance rate, while a stronger draft model incurs higher compute overhead — a fundamental tension.
To break this deadlock, we adopt DFlash, an innovative block-level masked parallel prediction method from the research community[2]: the draft model fills an entire block of masked positions in a single forward pass, fundamentally eliminating the serial constraint of "autoregressive drafting."
We deployed this approach on MiMo-V2.5-Pro with custom optimizations tailored for trillion-scale MoE and long-context scenarios. Using the Muon second-order optimizer and model self-distillation, we ensure that compact mask blocks still deliver ideal acceptance rates while compressing draft-stage overhead to near its theoretical minimum:
- The draft model exclusively uses Sliding Window Attention (SWA), naturally aligning with the SWA design of the MiMo-V2 series. This eliminates dependency on complete prefixes, reducing per-prediction compute from context-length-linear to constant.
- During training, mask-signal sampling is pushed down to GPU-local shards, enabling a single sequence to produce tens of thousands of independent training signals covering diverse context positions in one step — aligning with the long-context capability of the MiMo-V2 series while avoiding cross-device communication overhead.
In terms of results, our parallel-prediction speculative decoding achieves significant acceptance-length improvements across high-value agent and coding scenarios, meaning the large model can confirm more content "in one breath" per verification round. Furthermore, we limit block size to 8 to reduce verification overhead and increase concurrency, allowing high acceptance lengths to translate directly into high inference throughput:
| Scenario | Acceptance Length |
|---|---|
| Coding | 6.30 |
| Math / Reasoning | 5.56 |
| Agent | 4.29 |
In the Coding scenario, we achieve an average acceptance length of 6.30, with some samples reaching a maximum of 7.14 — meaning 6–7 out of the 8 draft tokens per verification round are accepted. The draft model remains lightweight while pushing acceptance rates to levels that deliver real end-to-end gains. We also observe that in more semantically divergent, higher-uncertainty general conversation scenarios, current acceptance rates are not yet high. We are continuously optimizing the algorithm to explore higher generalization ceilings.
3.3 TileRT Ultra-Low-Latency Inference Kernels / System
If MiMo's algorithmic innovations unshackle the bandwidth constraints of hundred-billion and trillion-parameter models, then the TileRT inference system squeezes every last drop of physical potential from commodity GPUs down to the microsecond level.
At 1000 tokens/s operating frequency, each operator's lifecycle is compressed to microseconds, and the "operator boundaries" of traditional inference systems become the core bottleneck — every operator launch, hardware synchronization, and global memory round-trip fractures the execution flow at the microsecond scale, exposing visible "Execution Gaps."
TileRT's Paradigm-Level Execution Model Revolution
As the foundational infrastructure for ultra-low-latency inference, TileRT introduces an entirely new execution model that eliminates execution gaps from operator boundaries at their root:
- Persistent Engine Kernel: Completely discards the traditional per-operator launch paradigm, keeping the entire compute pipeline persistently resident and flowing within the GPU. This enables full-pipeline continuous prefetching — while the current Tile is still computing on Tensor Cores, subsequent data is already flowing through the memory hierarchy, achieving extreme overlap between data movement and computation.
- Warp Specialization (Heterogeneous Pipeline Collaboration): At the Tile level, communication, data movement, and tensor computation are physically decomposed with finer granularity. Breaking the homogeneous lock-step execution model, different Warps (thread groups) and even heterogeneous execution domains across the entire GPU operate independently yet in precise coordination — transforming the GPU into a continuously flowing, precisely orchestrated heterogeneous execution system.
Microsecond-Scale Hardware-Software Deep Convergence (Codesign)
When the underlying execution model pushes hardware performance to its limits, pure runtime optimization begins to hit physical boundaries. Building on this foundation, the TileRT system team and Xiaomi's MiMo team engaged in deep technical co-creation, breaking down traditional software layer boundaries. To perfectly align model behavior with this ultra-low-latency execution pipeline, the model layer ultimately adopted a mixed FP4 quantization strategy for MoE Experts and deployed SWA-aligned DFlash speculative decoding on the trillion-parameter architecture. TileRT tightly couples with these algorithmic characteristics and quantization schemes, delivering custom-built compilation engines and compute kernels. Both teams made profound joint engineering tradeoffs based on hardware physics, ensuring execution pressure closes smoothly within hardware boundaries.
The birth of 1000 tokens/s is no coincidence of point optimizations. It is the inevitable result of world-class system infrastructure and extreme algorithmic models deeply converging toward each other, co-evolving as one.
TileRT is a frontier systems architecture team focused on next-generation AI infrastructure and ultra-low-latency inference. The team is dedicated to enabling millisecond-level real-time response for frontier large models in production environments, breaking traditional storage-compute barriers with an entirely new runtime architecture. The team has conceived and implemented a paradigm-level execution model. Through full-stack breakthroughs in persistent kernels, tile pipelines, and heterogeneous collaboration, TileRT achieves extreme compute utilization within complex heterogeneous ecosystems. As a core infrastructure enabler, the team actively partners with industry-leading collaborators on hardware-software codesign, building the high-performance compute foundation for the era of autonomous intelligence that craves "ultimate speed." For more TileRT technical details: tilert.ai/blog/breaking-1000-tps.html
5. More Demos
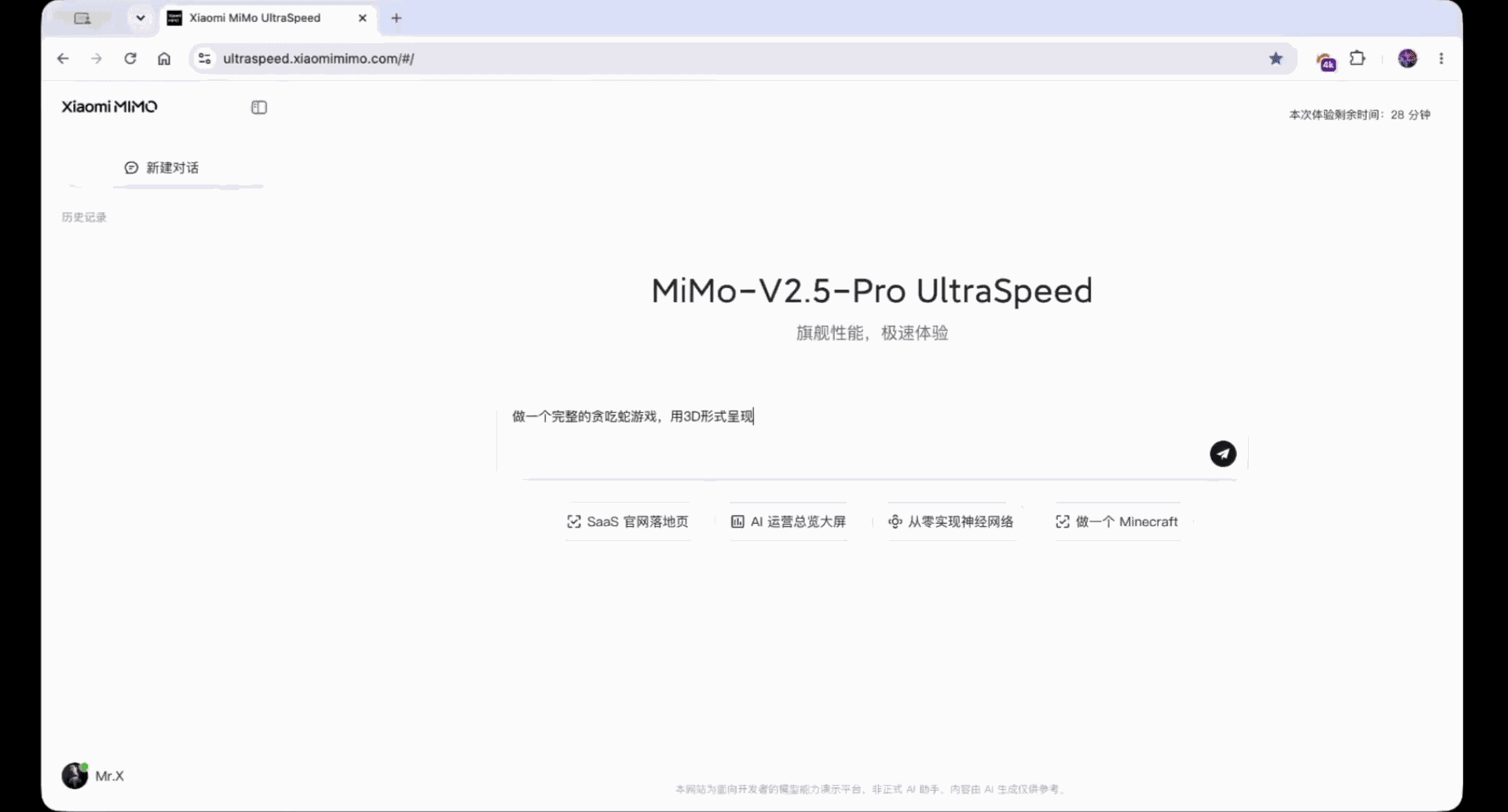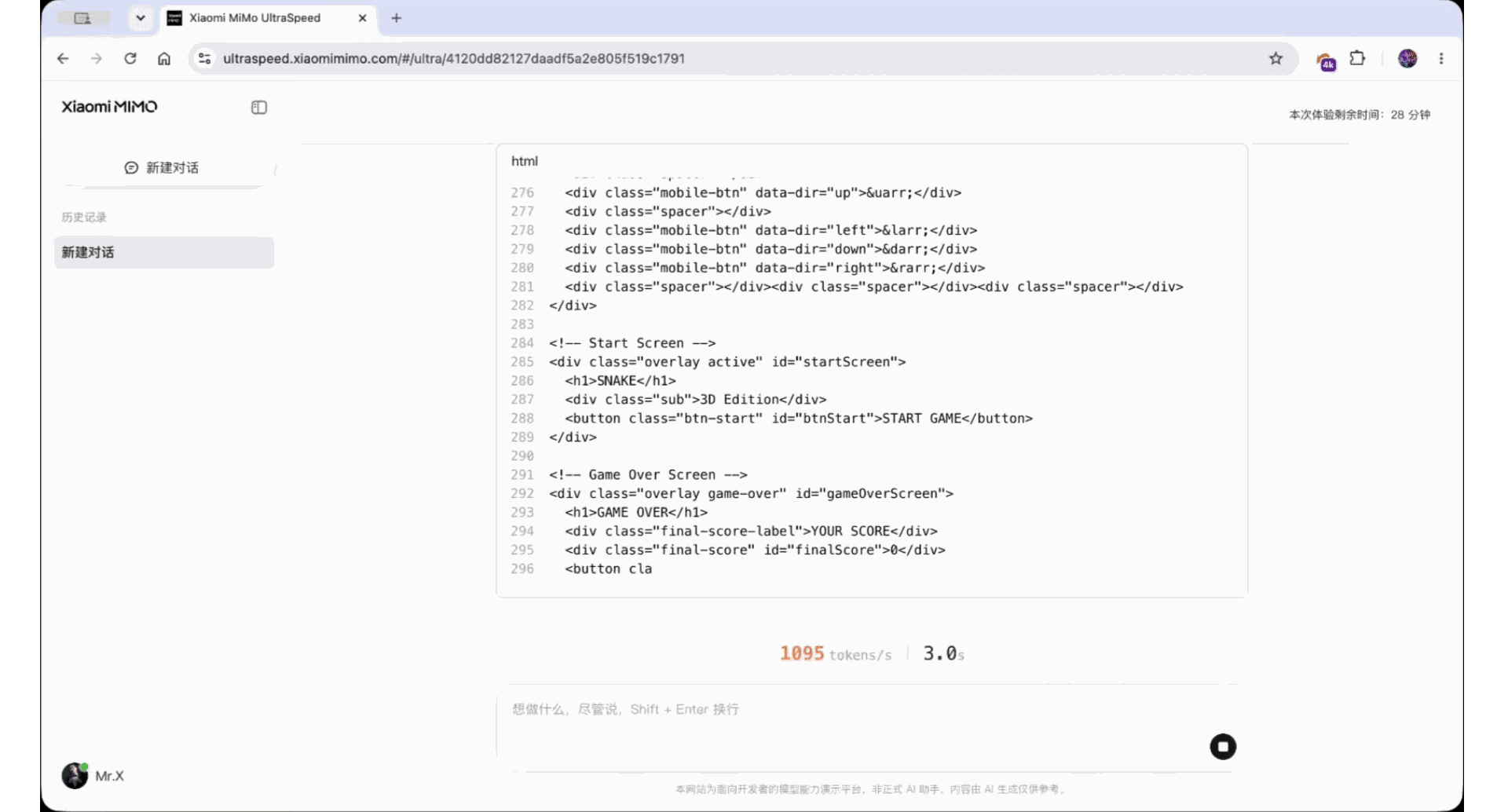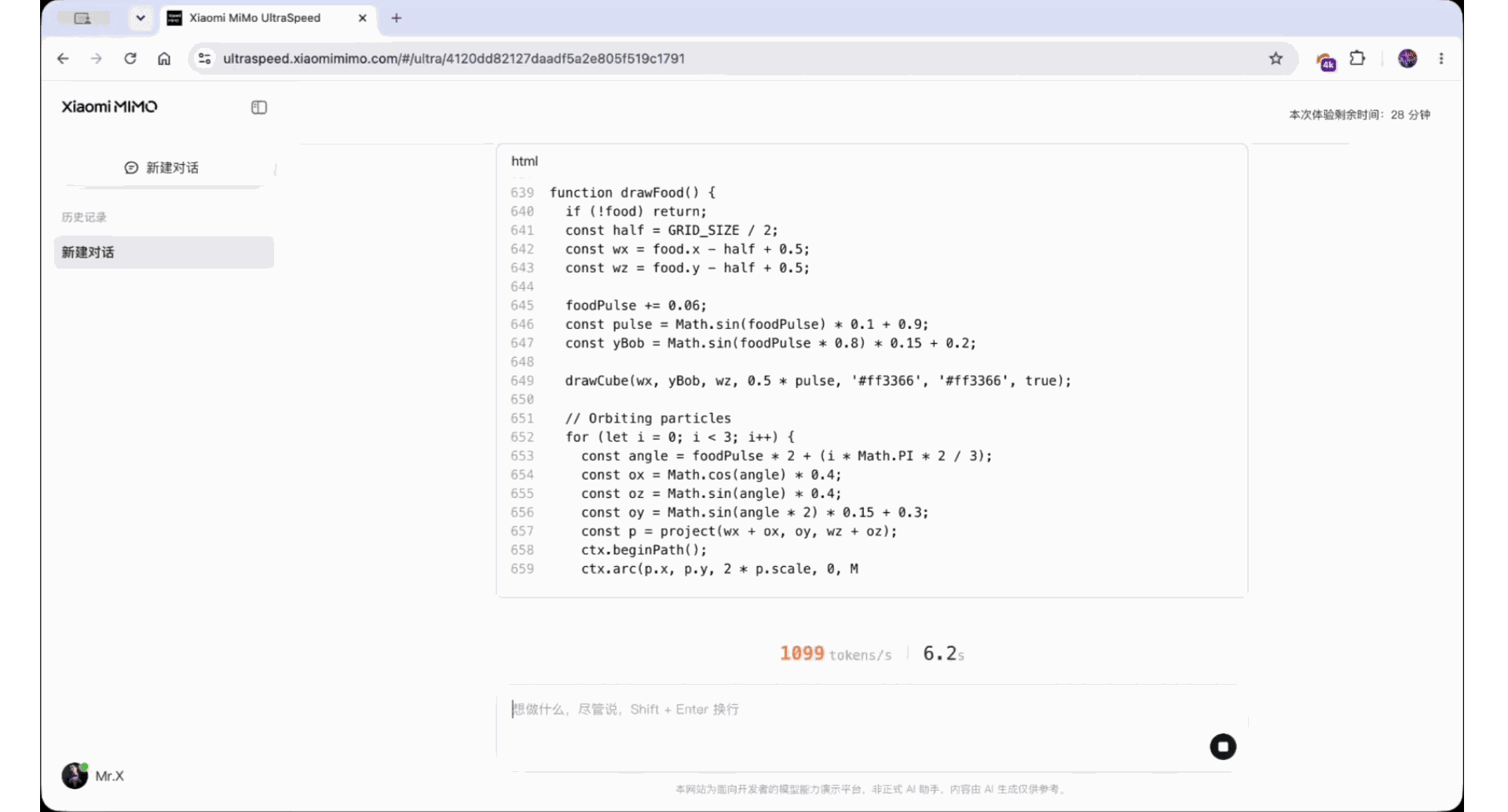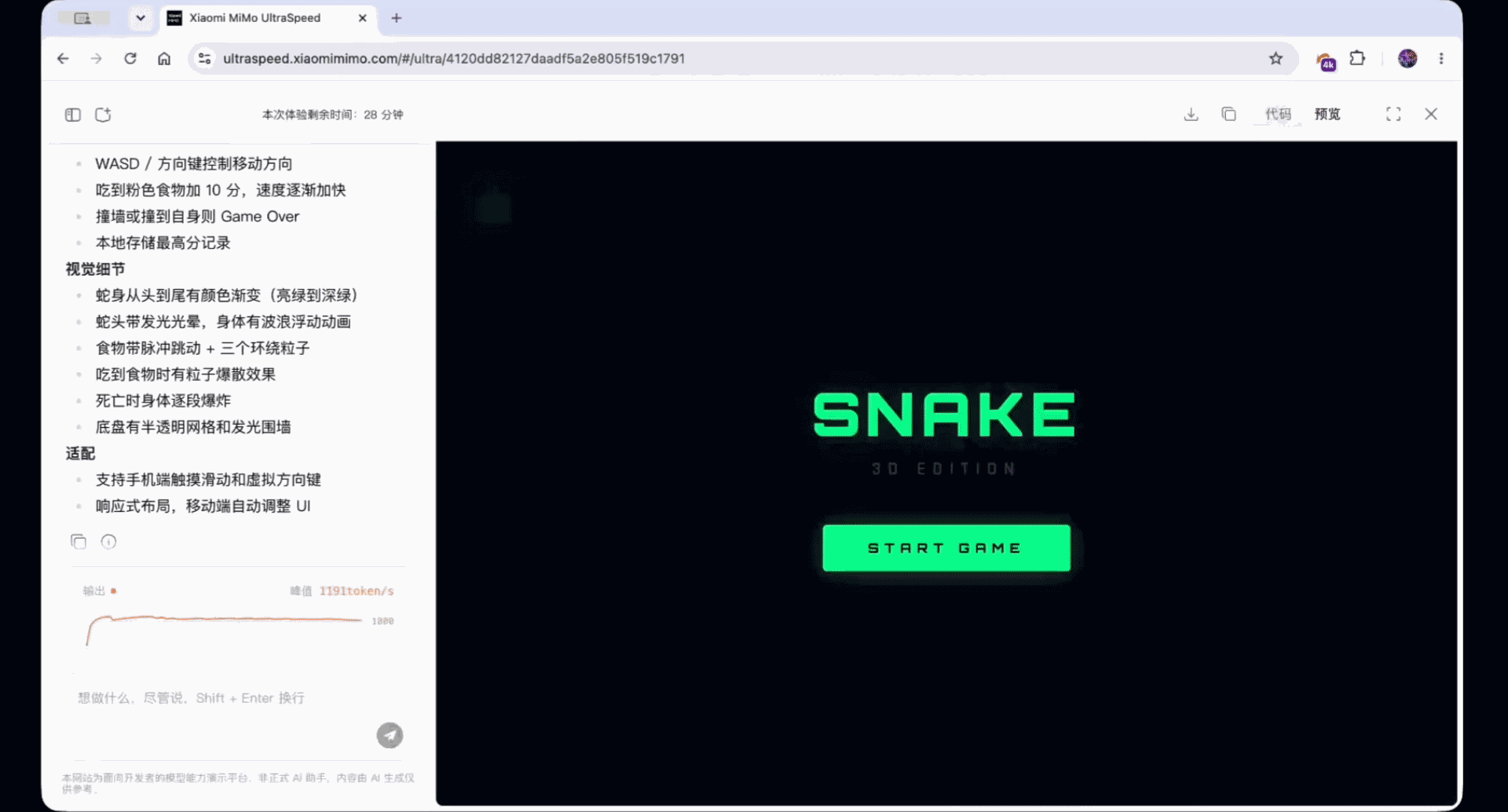
Build a Snake game in just 10 seconds
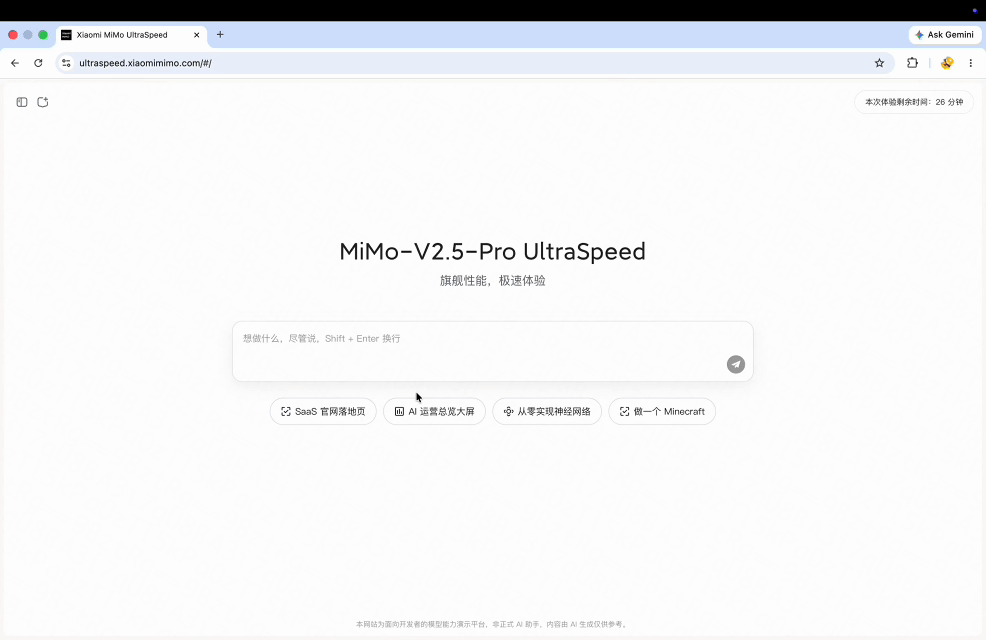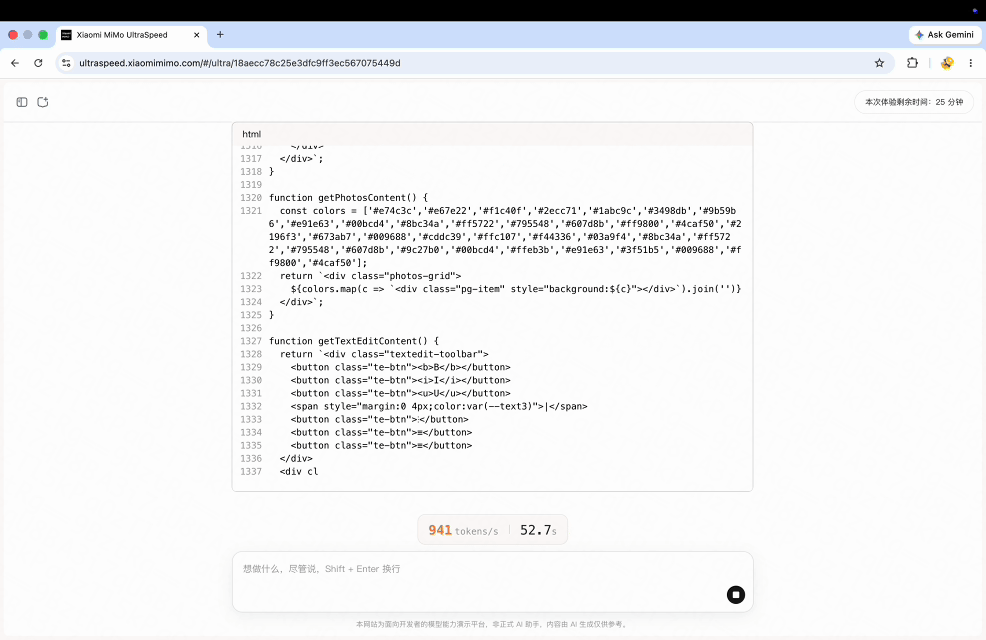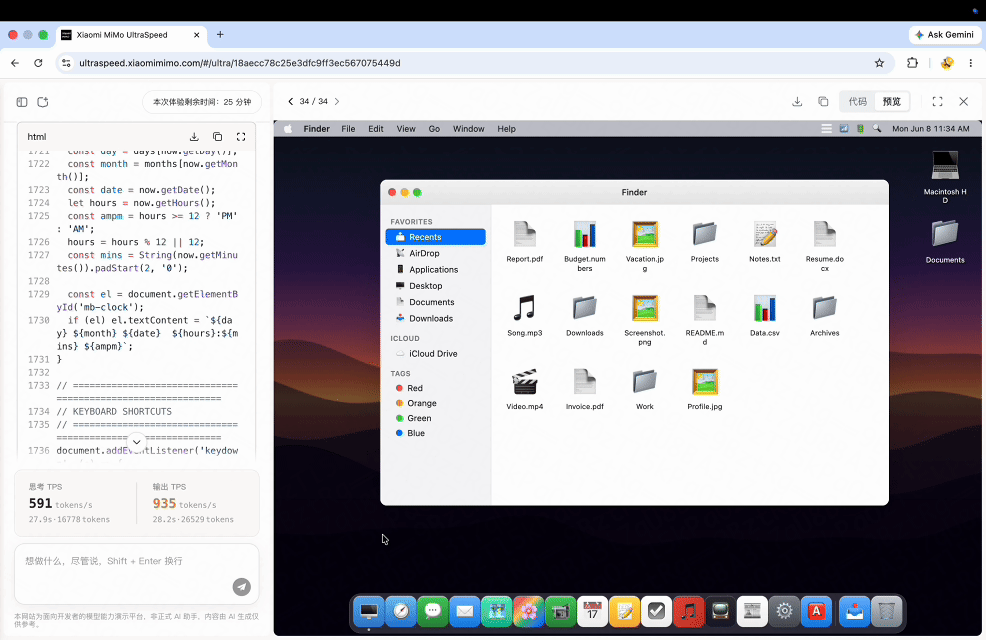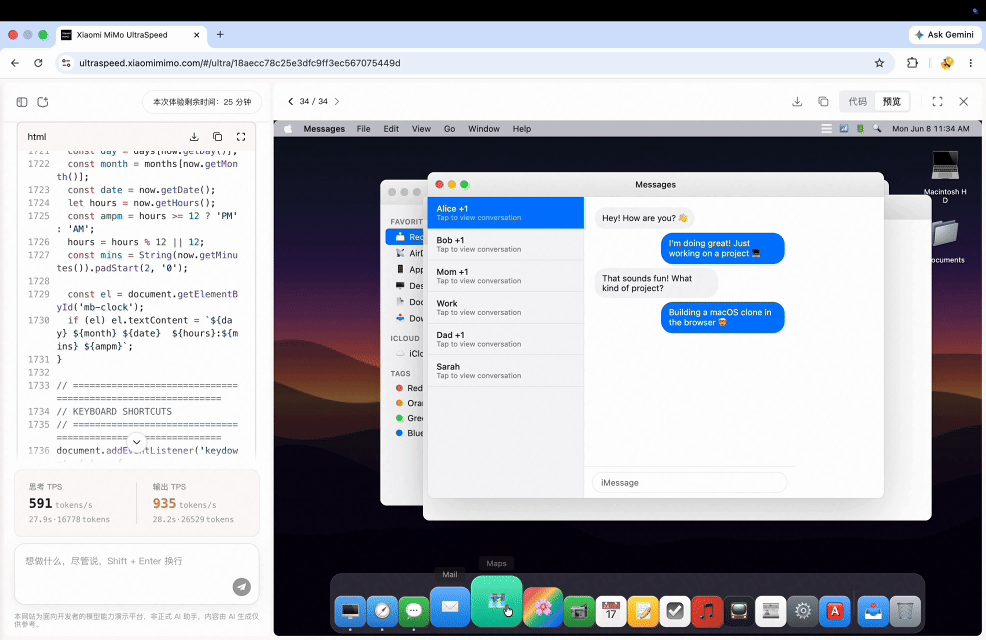
Recreate a MacOS interface in just 1 minute
6. Open Source & Outlook
- We have open-sourced the MiMo-V2.5-Pro-FP4-DFlash checkpoint on HuggingFace, including FP4 quantized weights and DFlash model parameters. Community usage and feedback are welcome: huggingface.co/XiaomiMiMo/MiMo-V2.5-Pro-FP4-DFlash
- UltraSpeed support for MiMo-V2.5 is on the way — stay tuned.
MiMo × TileRT — extreme model-system codesign, delivering 1000 tps output speed for trillion-parameter models.