Tom Pang | June 11, 2026
Counterintuitively, large DELETEs add work to the database.
From experience we can plainly claim the following: the most scalable Postgres data-deletion strategies revolve around deleting entire tables.
Individual row DELETE is fine at a small scale. However, big batch DELETE operations don't immediately free up physical disk space, add write and replication overhead, and are ultimately not good for large scale row cleanup.
If your application needs to delete large amounts of data, even very rarely, we recommend moving towards schema designs that let you express that as a DROP TABLE or a TRUNCATE.
Let's study why this is by looking at how DELETE works in Postgres.
Deletes hurt
When rows mutate, Postgres can maintain multiple versions of the same row, so that different transactions can see row values as of the time they were queried. This is Postgres' implementation of "Multi-Version Concurrency Control" (MVCC) and a core principle of its design.
Postgres makes an intentional tradeoff here. It stores modified and deleted rows alongside current ones, relying on transaction IDs and visibility maps to skip over "dead tuples." Later on, a vacuum process comes along and says, "Hey, these bytes in this heap page are now free, you can overwrite them."

Deletes also need to be fully replicated; they are still a work of writes, which means large-scale DELETEs can impact other writers to your application and cause them to wait for the DELETE replication to finish (under synchronous and semi-synchronous replication).
It's worth noting here that DELETE or even autovacuum doesn't typically return data to the operating system; they only say "the space in those pages can be written over." This is an intentional choice by Postgres. It optimizes for the case where DELETE workloads are mixed with INSERT ones, and releasing space to the operating system and then asking for it back is relatively expensive and should be avoided. VACUUM FULL allows for this, but takes an expensive lock for a long time.
Another related tradeoff Postgres makes is that index data is not touched at all when issuing a DELETE; instead, readers reading the index have to resolve "is this tuple dead." There's also a best-effort optimization where an index scan that finds a dead row can mark the entry as dead itself.
Overall, DELETE is really "work added," not "work done." If you want more details on Postgres MVCC, see Keeping a Postgres queue healthy.
If you're running a DELETE over a large amount of data, you can imagine how it adds work to every read query and autovacuum. Be aware that using foreign keys and CASCADE for deletions can cause a single row delete to delete gigabytes of data, resulting in the same set of problems.
Drop DELETE for DROP
In contrast, DROP TABLE and TRUNCATE require a heavyweight AccessExclusiveLock on the table, but are loosely independent of data size. At the physical layer they remove files from the operating system directly, plus sweep the Postgres buffer cache to remove pages related to the table.
That sweep can be less trivial on databases with large shared buffers, but it is only a metadata sweep. Postgres keeps a small fixed-size header (a BufferDesc, padded to 64 bytes) for every 8KB buffer, and dropping a table scans those headers, not the pages themselves. At 64 bytes per 8KB page, that's 1/128th of the cache size: with 128GB of shared buffers, you are sweeping only ~1GB of memory, sequentially, which is very fast on modern hardware.
DROP TABLE and TRUNCATE scale much better than DELETE. They produce zero dead tuples, zero vacuum debt, zero work for readers. They immediately free up space for the operating system.
A performant one-off delete
One common case where folks need to delete large amounts of data is "my table is full of junk due to a bug." We encountered this recently in an internal observability tool. A bug caused the tool to write millions of rows that we wanted to delete from the database. The bad rows had an old updated_at timestamp; anything with a recent one was designed to be kept. There were only a few hundred thousand rows to keep; most of the data was junk.
For this case, especially because "lock the database for minutes" was not an issue at all, we performed some surgery, leaning on Postgres' transactional DDL:
BEGINExplicit
LOCK TABLE ... IN ACCESS EXCLUSIVE MODEon the table in question; this prevents other transactions from reading or writing the table, so we get consistent data.Create a temporary table to hold just the kept data, like so:
CREATE TEMP TABLE temp_keep_big_table AS SELECT * FROM big_table WHERE updated_at >= '2026-04-01';
TRUNCATE big_table;INSERT INTO big_table SELECT * FROM temp_keep_big_table;. In our example, this took a handful of minutes to process on a very small instance with hundreds of thousands of rows.
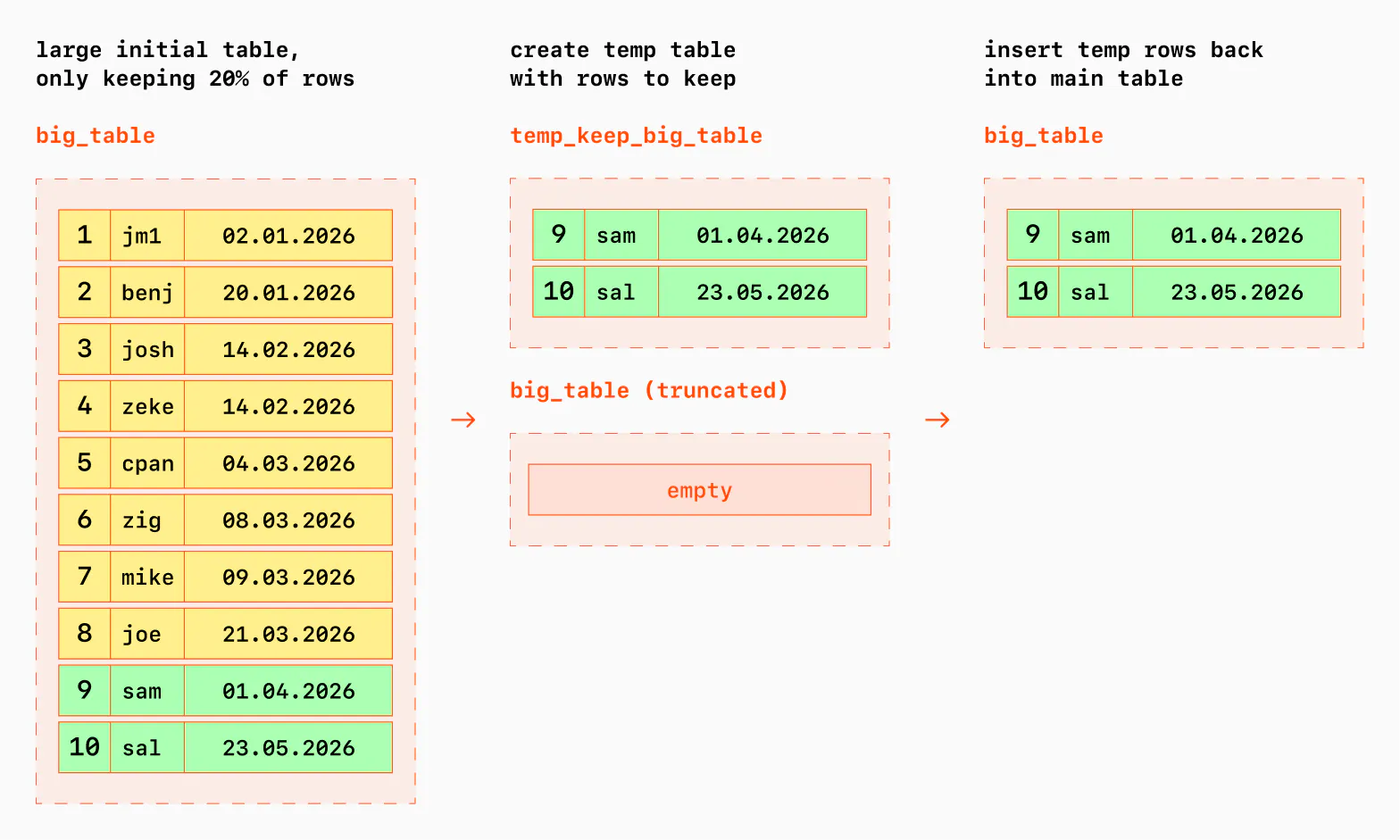
This worked very well for a one-off; the only data written to the Write Ahead Log (WAL) are the reinserted rows in the big_table.
If holding an AccessExclusiveLock on the table for minutes during TRUNCATE is unacceptable, use a trigger-based approach instead: mirror writes to a new table, then swap with an atomic rename.
You should also know that this more advanced maneuver is roughly what the Postgres extension pg_squeeze (a more modern version of pg_repack) does. pg_squeeze is for optimizing tables that already have significant bloat. This blog post is really about preventing bloat in the first place. By structuring your schema to avoid large bulk DELETE, pg_squeeze becomes less necessary.
In cases where the data to keep is much larger than the data to discard, but the data to discard is still substantial, the typical approach is to perform many isolated batched deletes in a loop, e.g., 10,000 rows at a time. This keeps transactions short, avoids lock pileups, and lets you pace things so that autovacuum keeps up.
Postgres partitions for ongoing deletes
Since version 10, Postgres has had great partitioning support. A "parent" table can have "child" tables, and queries can be automatically routed to them. Postgres supports a variety of partitioning schemes; one that is extremely useful is date-based partitioning, but many others are available.
Partitioning can transform a workload that does "lots of DELETE" into a workload that does "occasional DROP TABLE." For example, if you have historical data that needs to be aged out, you can have a child partition per day, and a periodic process that deletes older child partitions (or use the pg_partman extension).

You can go further still. Partitioning in Postgres is recursive, so you could partition the top level by LIST (e.g., a "visible" rows partition), then partition the "not visible" child table by RANGE to age out old data.
Go forth and DROP
Structuring your schema and application so that large-scale DELETE becomes DROP or TRUNCATE can dramatically improve your database. It helps reduce read query latency in some cases, mitigates replication lag spikes, and overall improves database health.