{kind=link}
.jpg){kind=link}
{kind=link}
Tom Di Mino, a self-taught AI engineer and an amateur linguist, claims to have accomplished a feat that has eluded linguistics experts for over a century: deciphering a Bronze-age Minoan writing system known as Linear A.
His claims are currently being reviewed by linguistics experts at Rutgers and Cambridge. While I’m caveating, I will also mention that I know Tom socially.
Di Mino, who is based in the Hudson Valley, has studied classical history, linguistics, and languages since he was 18. He has varying degrees of proficiency in 8 languages, including Attic Greek, classical Latin, Sanskrit, Arabic, and Ugaritic. He has been reading up on Linear A for 7 years, and has visited Crete twice. He began to work on deciphering Linear A in January this year, and says the major insight came to him on May 22.
If Tom Di Mino has deciphered Linear A, it would be an earthquake in the field of linguistics. When a related Minoan script, Linear B, was deciphered in 1952, it made the front page of the New York Times.
Linear A maps to an extinct Semitic language
Di Mino believes that Linear A belongs to an extinct Semitic language that was a precursor to Biblical Hebrew, Arabic, and Aramaic, the way that Latin is a precursor to Italian.
Di Mino is not the first to argue that Linear A was Semitic. Prior attempts to prove it, however, including a 1957 article published by Cyrus Gordon in the journal Antiquity, did not unlock translations the way that Di Mino’s solution appears to, and Gordon’s work did not gain widespread acceptance in the field.
Some background on Linear A and Linear B
Linear A is a Minoan script that appeared sometime around 1800 BC and was used until 1450 BC, when Crete was conquered by Mycenaean Greeks. The Mycenaeans adopted the Minoan symbols as their own, with some minor revisions. The Mycenaean-Greek version of the symbols are known as Linear B. Both scripts were found on various tablets, vases, and other artifacts from the era.
Both scripts use syllables, not letters, as their core elements. The syllables are generally consonant-vowel pairs.
The two systems have 60 core syllables in common, and they both also use logograms – symbols that represent a whole word (“cow”), not just a syllable.
Linear B was deciphered and identified as Greek in 1952 by Michael Ventris, a British architect, cryptographer, and amateur linguist, like Di Mino. Ventris’s breakthrough may not have happened without prior work on Linear B by Alice Kober, a professor at Brooklyn College.
Kober and Ventris used grammatical and statistical analyses to look for patterns in the location of the symbols (e.g. the first syllable was more likely to be a vowel) and how the symbols shifted.
There are many more inscriptions associated with Linear B than Linear A, however, which made it easier to decipher. Also, many Linear A inscriptions are inventories cataloging the trade of different commodities, so they don’t tell us much about the language.
Because Linear A and Linear B have 60 symbols in common, and because Linear B has been deciphered, experts could guess what the overlapping Linear A symbols sounded like but didn’t know what the sounds meant. And there were 13 additional symbols in Linear A that did not appear in Linear B. For those, no sound values have been accepted.
The key that unlocked Linear A
On May 22, Di Mino was analyzing a series of Linear A prayer inscriptions that adhered to a formula. (Don’t worry, you don’t have to understand the formula, but I’m including it for the nerds.)
IOZa2 (Iouktas): A-TA-I-*301-WA-JA · JA-DI-KI-TU · JA-SA-SA-RA-ME · U-NA-KA-NA-SI · I-PI-NA-MA · SI-RU-TE · TA-NA-RA-TE-U-TI-NU · I
(Also see Figure 1 below.)
In the formula all of the words in each line of the inscription were known (based on their overlap with Linear B syllables) except for the first word.
The first word was the same verb root, appearing in different regional forms across five sanctuary sites on the island.
The verb contained 5 known Linear B signs and “*301”, which appeared to be a Linear A-only sign, “na,” which Di Mino used to unlock the root “nawaya,” which means “to dwell.” In Hebrew, Akkadian and other Semitic languages there is a 3 syllable consonant system. N-W-Y is used for verbs and nouns meaning “to dwell or inhabit”.
Once deciphered, Di Mino saw that the prayer was similar to subsequent Hebrew prayers but was addressed to a Goddess.
While Cyrus Gordon had previously proposed links between dedication tablets in Linear A and similar tablets in Akkadian and Phoenician that he had translated, Di Mino claims to be the first person to identify the links between the Linear A inscriptions and Hebrew prayers.
This insight not only unlocked the verb in the prayer inscriptions, but it may also shed a broader light on the use of logograms in Linear A.
Di Mino claims that his insights into logograms in Linear A additionally help to resolve problems with some translations of Linear B, which validates his findings.
Di Mino used Claude Code to build a suite of Python scripts that query, cross-reference, and organize the digitized Linear A corpus (drawn from the GORILA and SigLA databases), enabling systematic hypothesis testing at a scale that would have been impractical to do manually.
Artifacts
Di Mino’s research has led to:
Proposed readings for 40 of the script’s signs, including 13 signs whose phonetic values were previously unknown. He also resolved the sound values for 5 Linear B signs which were unknown to this day.
A lexicon of 408 Linear A terms translated into English
A 9-page draft of a manuscript titled Ya Diktu: Grammar of the Minoan Peak Sanctuary Libation Formula, which may form the foundation for a submission to a peer-reviewed scientific journal
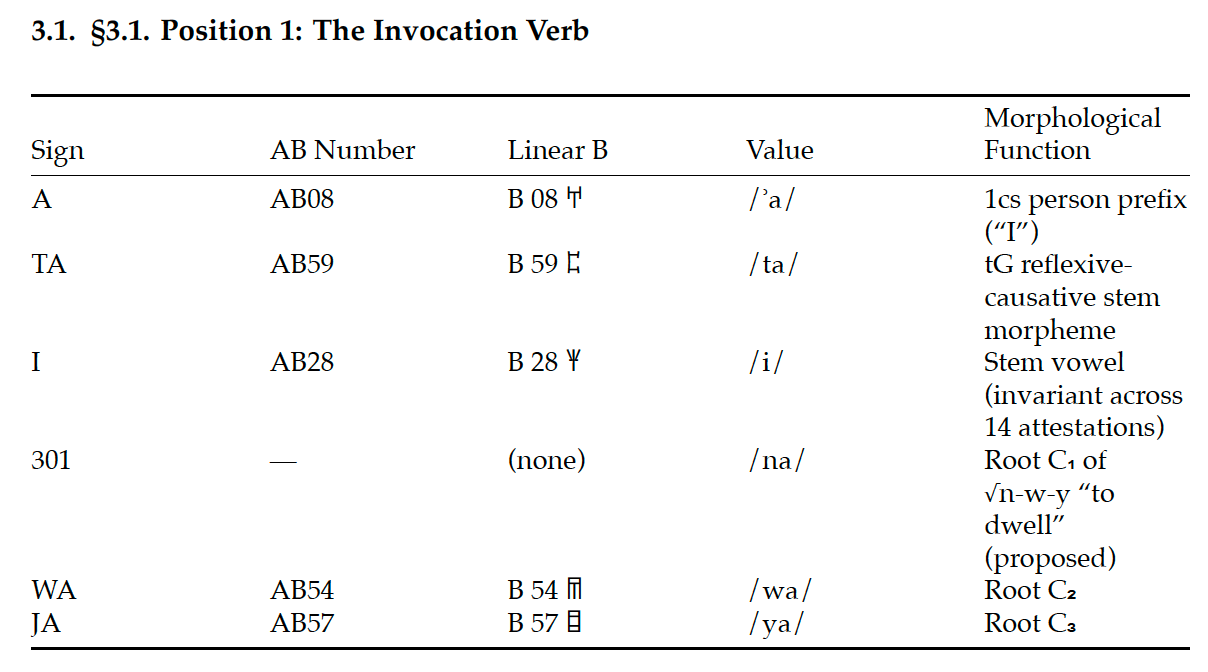
Figure 1. A summary of the symbols in line 1 of the Minoan prayer inscription. Credit: Tom Di Mino, Ya Diktu: Grammar of the Minoan Peak Sanctuary, June 2026.
(This article has been edited for accuracy since it was originally posted.)