
You may have seen headlines noting that Google’s measurements have shown IPv6 reaching 50% for the first time. These measurements are based on Google’s continuous monitoring of the availability of IPv6 connectivity among its users, and reflect the proportion of users who access Google services over IPv6. Reaching the 50% mark is a significant milestone, demonstrating that IPv6 is a mature, fully capable protocol that is being deployed at a global scale and used effectively in real-world networks.
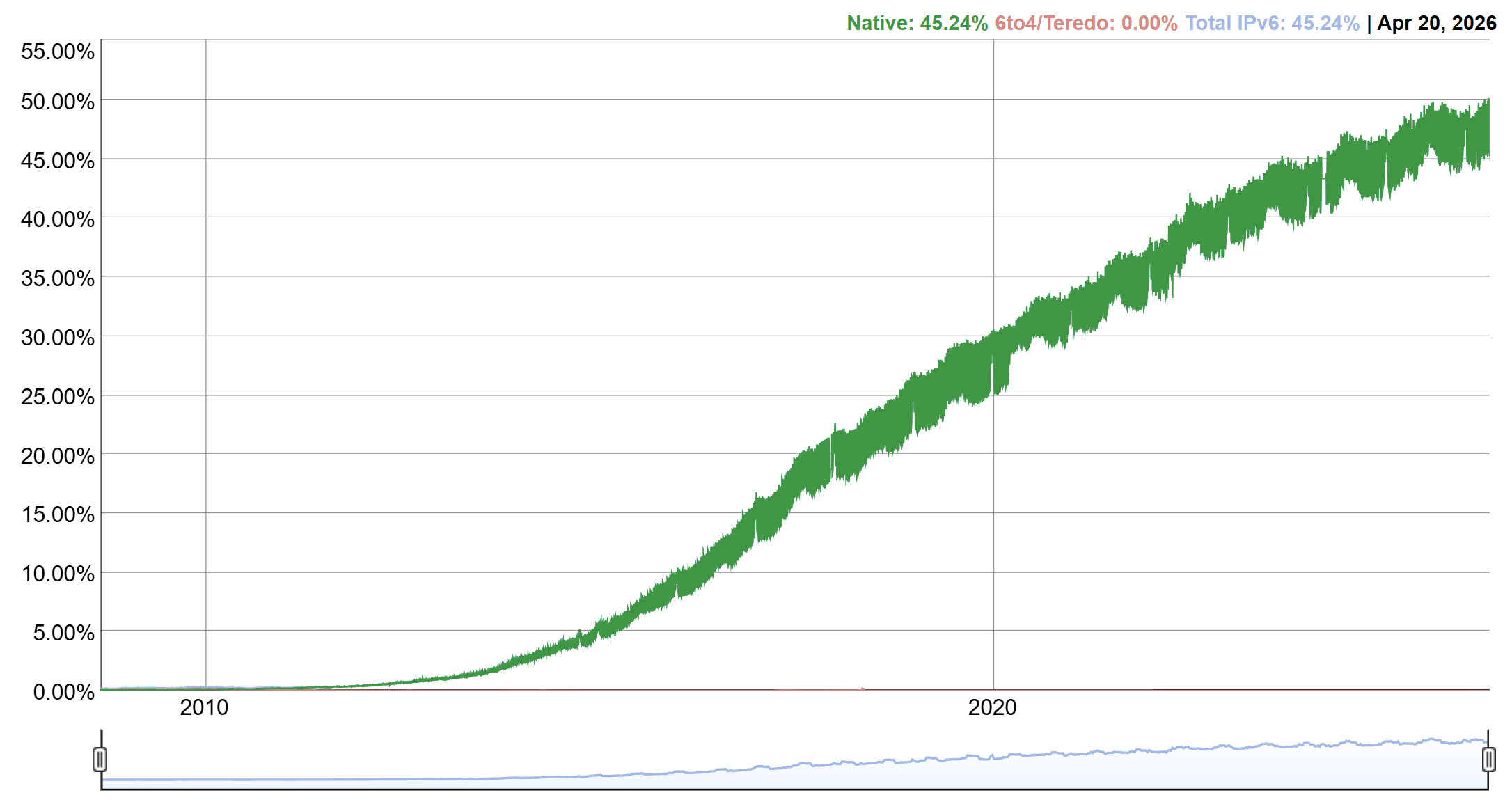
Figure 1 — Google’s global IPv6 adoption graph, as at 23 April 2026. Source.
The shape of IPv6 adoption isn’t evenly distributed
The global uptake of IPv6 follows a complex and varied path that isn’t apparent in a single, aggregated trend line. Google does not publish per‑region IPv6 statistics, and its per‑economy data is limited to overall totals, so these nuances are hard to see in Google’s figures alone. To understand how adoption really unfolds, it’s more instructive to look at the APNIC Labs data. Individual economies such as India, Viet Nam, and Saudi Arabia exhibit adoption curves that differ markedly from the global average. As the APNIC Labs data shows, this global trend does not necessarily reflect the experience of individual economies.
APNIC’s own measurement records a 42% worldwide IPv6 capability (Figure 2). That’s a substantial difference, which also needs clarifying.
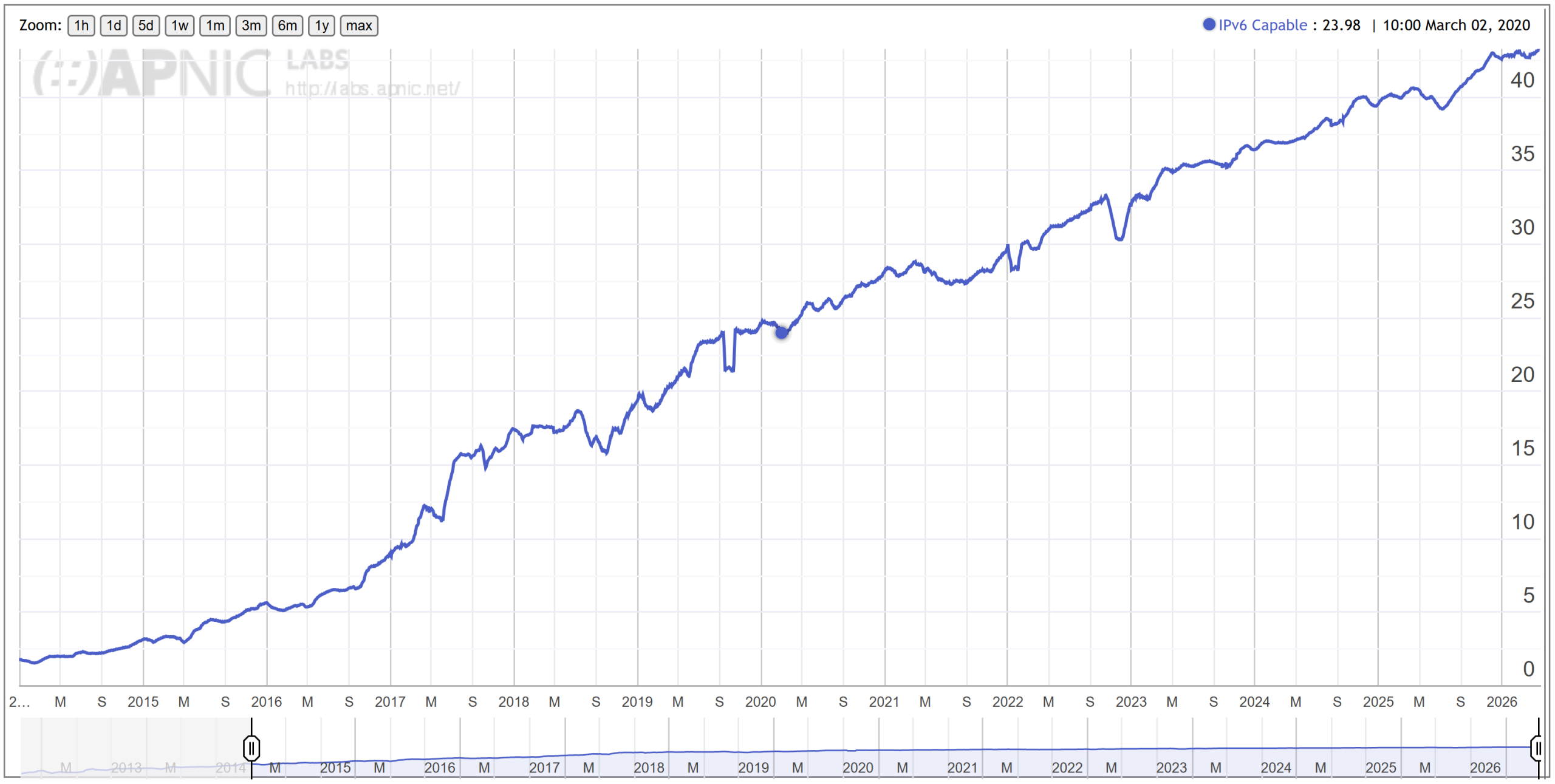
Figure 2 — APNIC Labs’ global IPv6 capability measurement, as at 23 April 2026. Source.
Measurement differences
APNIC’s measurement program is run by APNIC Labs and uses online advertising distributed through Google Ads, which appear in end users’ web browsers, games, and apps wherever Google advertisements are placed. APNIC does not select specific users and seeks the broadest possible exposure in every economy, 24/7. Normal advertising tracking systems are used with APNIC Labs logic, which ensures a unique set of tests are run, measuring IP, BGP routing and DNS, amongst other technology choices. No end-user Personally Identifiable Information (PII) data is held, and raw measurements are never shared, only collations at the ISP, economy and region level.
This work is carried out with the assistance of Google Research, ICANN, and others who help fund and support the activity. Given this close involvement, it’s natural to ask why APNIC’s measurement results don’t always align with Google’s own published statistics. If Google is used to conduct the research, how can the results differ?
APNIC’s measurement approach applies statistical weighting to the collected data and uses external sources, such as World Bank statistics, to model Internet usage by economy. This is necessary because the number of measurement samples APNIC Labs receives each day is not uniform. Advertising placements are optimized by Google to maximize delivery and revenue, which means that, on any given day, more advertisements, and therefore more measurement samples, may be shown in certain economies than others. For example, if advertising demand is higher in North African economies such as Egypt or Tunisia on a particular day, more measurements will be collected there, while fewer may be gathered from South America or Asia.
As a result, the raw sample counts cannot simply be aggregated to calculate global IPv6 capability. Instead, APNIC Labs aggregates the measured IPv6 capability for each economy and then weights it according to that economy’s estimated Internet user population.
In practice, this means that large Internet populations, such as those in India, China, Indonesia, and other major economies, contribute proportionally more to the global result than smaller economies, even if the raw sample volumes on a given day might suggest otherwise. This weighting ensures that the final measurements reflect global Internet usage more accurately, rather than daily advertising distribution patterns.
At the level of individual economies, APNIC Labs’ measurements generally align with the totals published by Google and with data from Cloudflare, Akamai, Cisco, and others. This suggests that the underlying measurements are comparable and that the larger differences observed at the global level are likely due to differences between APNIC’s weighting model. This may be why we see the large variances between the two measurements.
In practice, APNIC’s measurements tend to be lower than Google’s. As a result, it’s useful to view the two data sets together, as they effectively bracket the likely range of actual IPv6 capability at any given point in time.
Is IPv6 adoption progressing as expected?
Some point to the long path toward a 50% adoption milestone as evidence of a systemic failure in IPv6. Nothing could be further from the truth. Deploying IPv6 has required substantial technical effort and significant capital investment. It’s therefore entirely expected that progress has varied across regions and economies, as individual ISPs and economies make their own decisions about how best to balance network growth, user expectations, and the practical realities of operating Internet infrastructure.
The global Internet is not a ‘command economy‘, it evolves through collaboration and cooperation within market-driven conditions. Many providers made substantial capital investments in IPv4 in earlier periods and have naturally sought to maximize the return on those investments. In doing so, they built sustainable and commercially viable IPv4-based networks within their existing footprints.
By contrast, for newer market entrants, it has often been more rational to adopt IPv6 as the primary protocol, as it can demonstrably reduce the total cost of ownership. This pattern is particularly evident in the mobile sector, most notably in large-scale IPv6 deployments such as Reliance Jio’s network in India.
Is the global Internet functioning in a ‘two‑protocol world’?
Yes, but it could be simpler.
Certainly, it would be easier logistically to run a global internet under a single protocol. However, that is not the environment we have ended up with. Instead, the Internet today operates across a mix of direct IPv4 connectivity, IPv4 mediated through Network Address Translation (NAT), either in home networks or at the carrier level via Carrier‑Grade NAT (CGNAT), and IPv6.
Managing address translation through NAT is not materially less complex than alternatives such as protocol translation, IPv4 encapsulation over IPv6, or other transition and proxy mechanisms. As a result, claims that ‘IPv4 is working fine’ often overlook the underlying reality: Modern IPv4 networks already rely on layers of operational complexity, and there is no inherently lower‑cost or simpler approach available within IPv4 alone.
From the outset, it was understood that the lack of direct interoperability between IPv4 and IPv6 would be a challenge that needed to be addressed. Early efforts explored the idea of protocols that could subsume IPv4 unchanged and enable direct connectivity across both worlds, but these approaches did not prove viable.
Instead, interoperability has emerged at higher layers, with transport protocols such as TCP, UDP, and QUIC operating independently of the underlying IP version. This model necessarily relies on some form of intermediary. This is visible in the way large content and caching providers, such as Cloudflare, are able to offer dual‑stack services regardless of whether the backend systems themselves support both protocols.
The absence of native dual‑stack capability at some services, for example, certain Git platforms or national television broadcasters, is often perceived as a major barrier to IPv6 progress. However, this may reflect pragmatic constraints, such as operational complexity, or, in the case of national broadcasters, legal and regulatory requirements around data access and geolocation, rather than resistance.
Let’s recognize the 50% milestone, even as the journey continues
Whatever one’s view on the decision to introduce a second addressing and protocol model beneath today’s Internet services, the reality is clear: IPv6 is now deployed on a global scale. Around half of the Internet users visible to Google already reach its services over IPv6. IPv6 is used every day, every hour, across developed and developing economies alike, on fixed and mobile networks, on small personal devices, and within vast data‑centre‑backed services. It is no longer experimental or marginal; it is part of the Internet’s day‑to‑day operation.
That achievement reflects the collective effort of those working to build, operate, and grow the Internet worldwide, and it is something worth recognizing and taking pride in.
The views expressed by the authors of this blog are their own and do not necessarily reflect the views of APNIC. Please note a Code of Conduct applies to this blog.