One Model to Command Them All マルチエージェントを指揮する、一つのモデル
Frontier-level performance without single-vendor dependency. Fugu dynamically orchestrates the world's best models to tackle complex, multi-step tasks. Plug collective intelligence directly into your workflows today with a single API. Sakana Fugu は、世界のトップモデル群を動的にオーケストレーションし、複数ステップに及ぶ複雑なタスクを自動的に解決します。高いパフォーマンスを実現するAPIを、あなたのワークフローに組み込みましょう。
Not yet available in the EU/EEA while we work toward compliance with GDPR and EU-specific regulations. GDPR等のEU/EEA固有規制への対応を進めており、現在はEU・EEA域内ではご利用いただけません。
What is Sakana Fugu ?
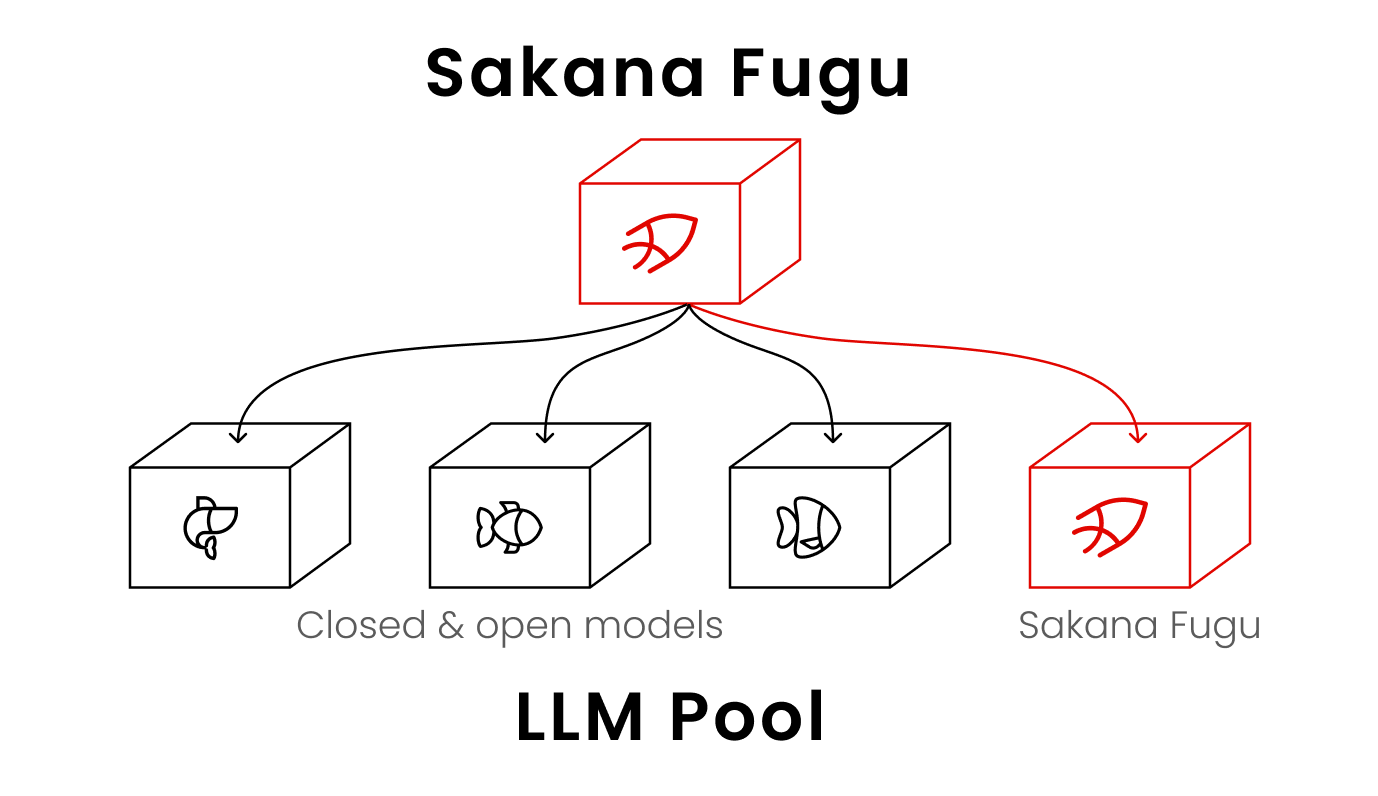
A Multi-Agent System, Delivered as One Model マルチエージェントを、一つのモデルAPIとして提供
Sakana Fugu achieves superior performance by dynamically coordinating and orchestrating a diverse pool of powerful models. Instead of using domain knowledge to prescribe team organization, roles, or workflows, Fugu learns to dynamically assemble agents from a pool and coordinate them through non-obvious but highly efficient collaboration patterns. Sakana Fugu は、強力で多様なモデル群を動的に組み合わせ、協調させることで高いパフォーマンスを実現します。人間が思い付かないようなモデルの編成や役割分担、処理の進め方など、効率よく学習しながら成果を発揮します。
01
One API to Access All in an Optimized Way 一つのAPIで、複数モデルを最適に活用
Access a coordinated pool of specialized models through one API. Fugu handles model selection and switching for each task, reducing API complexity while improving cost-performance. 専門特化型のモデル群を、一つのAPIから利用することができます。タスクごとのモデルの選択と切り替えは Sakana Fugu が担うため、APIまわりの煩雑さを抑えつつ、コストパフォーマンスを高められます。
02
Offering Superior Performance on Complex Tasks 複雑なタスクで優れたパフォーマンス
Built for coding, reasoning, and other quality-critical workflows, Fugu coordinates expert agents to tackle complex tasks with stronger, more reliable results. Sakana Fugu は、コーディングや推論(リーズニング)など、高い品質が問われるワークフローのために設計されています。専門エージェントを連携させることで、複雑なタスクにもより確かで信頼できる答えを導きます。
03
Providing Flexibility in Agent Selection 柔軟なエージェント選択
Control which agents can participate in Fugu’s model pool. Opt out of specific providers or models to meet data, privacy, compliance, or organizational requirements. Sakana Fugu のモデルプールに加えるエージェントを選ぶことができます。データ、プライバシー、コンプライアンス、または組織の要件を満たすために、特定のプロバイダーやモデルを除外することが可能です。
Tech Behind
Research-Driven Coordination for Multi-Agent Intelligence マルチエージェントの知能を支える、
最新研究に基づく協調技術
Sakana Fugu is grounded in two ICLR 2026 papers on learned model orchestration: TRINITY and the Conductor. Together, they show how systems can learn to assemble, route, and coordinate expert agents for each task instead of relying on hand-designed workflows. For a deeper look at the ideas behind the system, explore our technical report . Sakana Fugu は、モデルのオーケストレーションを学習で実現する2本のICLR 2026論文「TRINITY」と「Conductor」を基盤としています。これらの研究は、人手で設計したワークフローに頼るのではなく、タスクごとに専門エージェントをどう編成し、振り分け、連携させるかをシステム自身が学習できることを示しています。仕組みの詳細は、 テクニカルレポート をご覧ください。
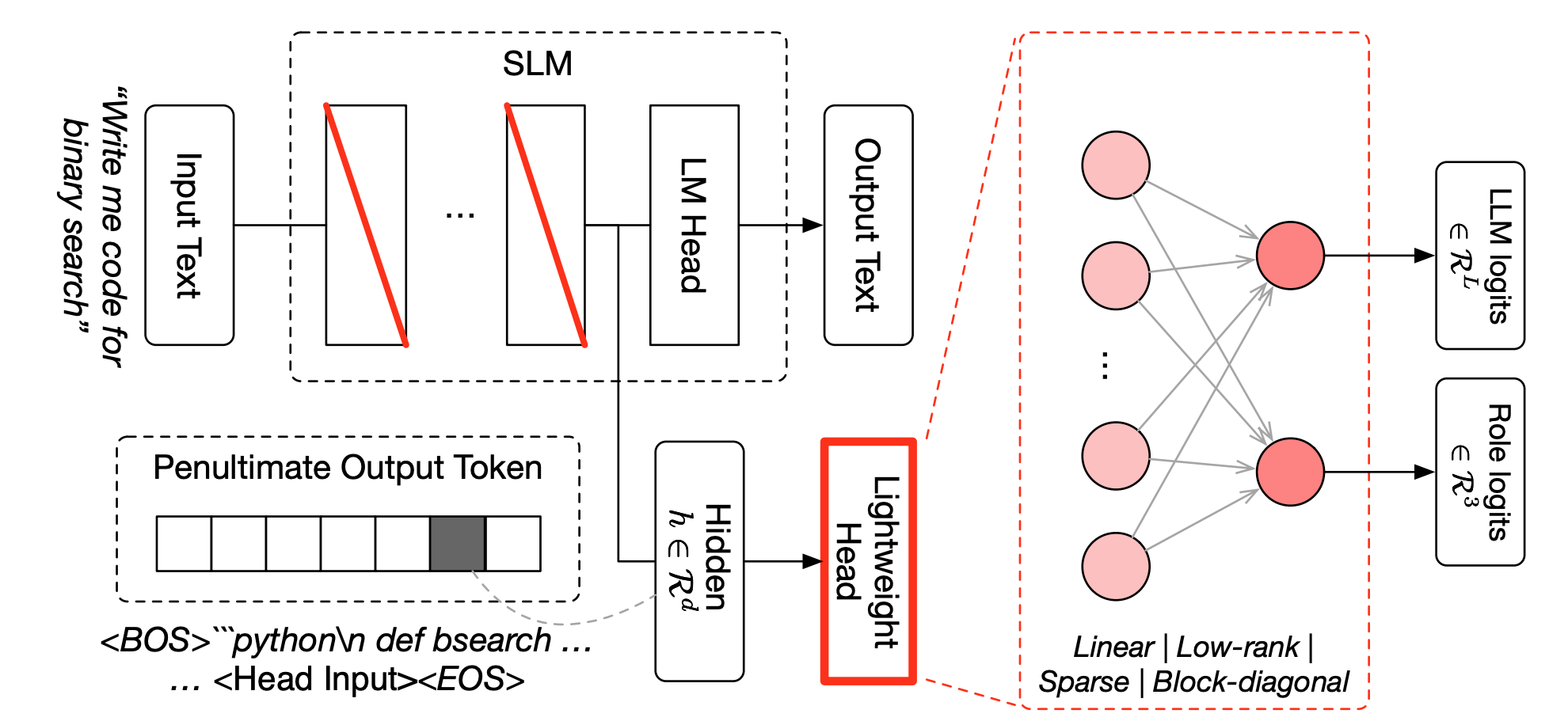
TRINITY: An Evolved LLM Coordinator TRINITY:進化型LLMコーディネーター
Trinity uses a lightweight evolved coordinator to orchestrate multiple LLMs over several turns, assigning Thinker, Worker, or Verifier roles to adaptively delegate work across coding, math, reasoning, and knowledge tasks. TRINITY は、軽量な進化型コーディネーターが複数のLLMを複数ターンにわたって統括する仕組み。各モデルに「Thinker(思考役)」「Worker(実行役)」「Verifier(検証役)」の役割を割り当て、コーディング・数学・推論・知識といった幅広いタスクに応じて、作業を適応的に振り分ける。
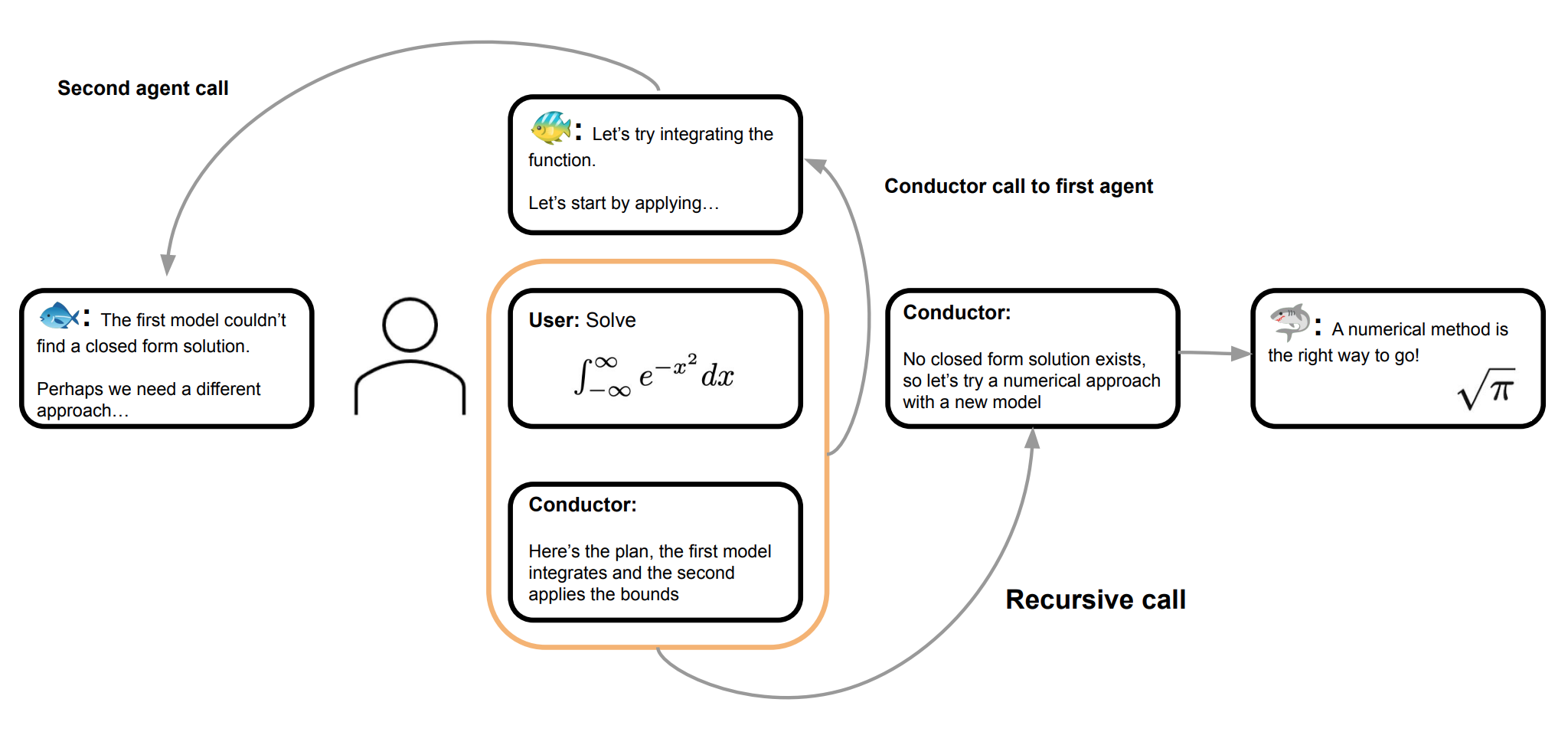
Learning to Orchestrate Agents in Natural Language with the Conductor Conductor による自然言語でのエージェント統率の学習
The Conductor is trained with reinforcement learning to discover natural-language coordination strategies, designing agent communication patterns and focused prompts that help diverse LLM pools outperform individual workers on challenging reasoning benchmarks. Conductor は強化学習によって訓練され、自然言語ベースの協調戦略を自ら見つけ出す。エージェント間のやり取りの型や、要点を絞ったプロンプトを設計することで、多様なLLMの集まりが、難度の高い推論ベンチマークで単体のモデルを上回る力を発揮。
How to Use
Unlock Multi-Agent Intelligence Through An API API を通じてマルチエージェント知能を解き放つ
Sakana Fugu comes in two models — Fugu and Fugu Ultra — both available through one OpenAI-compatible API. Pick the model that fits your workload, or switch between them without changing your integration. Sakana Fugu には Fugu と Fugu Ultra の 2 つのモデルがあり、どちらも OpenAI 互換 API から利用できます。ワークロードに合うモデルを選んでも、連携を変えずに両者を切り替えてもかまいません。
Fugu Balanced performance and latency 性能とレイテンシのバランス
Fugu balances strong performance with low latency, making it the ideal default for everyday work. Drop it into tools like Codex for coding and code review, or power responsive chatbot services — all behind a single endpoint. You can also opt specific agents out of its pool to meet data, privacy, and compliance constraints. Sakana Fugu は高い性能と低レイテンシを両立し、日々の作業に最適な標準モデルです。Codex のようなツールに組み込んでコーディングやコードレビューに使ったり、応答性の高いチャットボットを動かしたり——すべてをひとつのエンドポイントで実現します。データ・プライバシー・コンプライアンスの制約に合わせて、プールから特定のエージェントを除外することもできます。
Fugu Ultra Optimized for performance 性能に最適化
Fugu Ultra coordinates a deeper pool of expert agents to maximize answer quality on hard, high-stakes problems. Early users rely on it for Kaggle competitions, paper reproduction, cybersecurity analysis, and literature and patent investigations. Fugu Ultra は、より広い専門エージェントのプールを連携させ、難易度が高く重要な問題で回答品質を最大化します。先行ユーザーは、Kaggle コンペティション、論文の再現、サイバーセキュリティ分析、文献・特許調査などに活用しています。
Quantitative Results
Quantitative Results Sakana Fugu の性能:定量評価
Our Fugu models surpass publicly accessible frontier models and are shoulder-to-shoulder with Fable 5 and Mythos Preview in various rigorous engineering, scientific, and reasoning benchmarks while delivering frontier capability without the risk of export controls. 二つのFuguモデルは、一般に利用できるフロンティアモデルを上回り、エンジニアリング・科学・推論のさまざまな難関ベンチマークでも、Fable 5やMythos Previewと肩を並べます。しかも、輸出規制のリスクを負うことなく、フロンティアレベルの実力を発揮します。
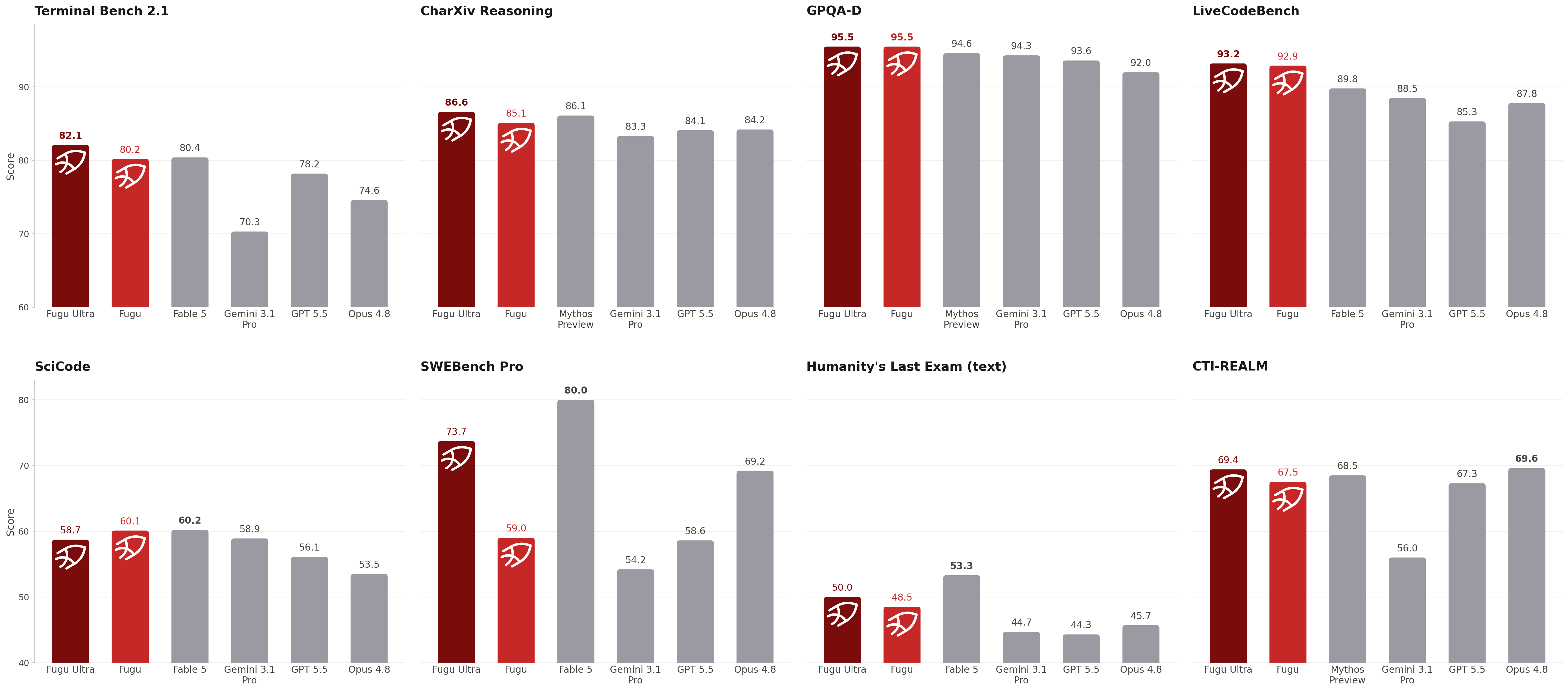
Performance comparison of Fugu models and baseline frontier models across a suite of coding, reasoning, scientific, and agentic benchmarks. For Fable 5 and Mythos Preview, we report the max of the two if both scores are available on the same benchmark. Neither of them is in Fugu’s agent pool as they are not publicly accessible. コーディング、リーズニング、科学、エージェント能力に関するベンチマーク群における、Fuguモデルとベースラインのフロンティアモデルの性能比較。Fable 5とMythos Previewについては、同一ベンチマークで両方のスコアが入手できる場合、その高い方を採用。なお、両モデルは一般提供されていないため、Fuguのエージェントプールには含まれていない。
Highest scores are shown in boldface; second-highest scores are underlined. 最高スコアは太字、2 番目に高いスコアは下線で示しています。
| Benchmark | Fugu | Fugu Ultra | Opus 4.8 † | Gemini 3.1 Pro † | GPT 5.5 † |
|---|---|---|---|---|---|
| SWE Bench Pro * | 59.0 | 73.7 | 69.2 | 54.2 | 58.6 |
| TerminalBench 2.1 | 80.2 | 82.1 | 74.6 | 70.3 | 78.2 |
| LiveCodeBench | 92.9 | 93.2 | 87.8 | 88.5 | 85.3 |
| LiveCodeBench Pro | 87.8 | 90.8 | 84.8 | 82.9 | 88.4 |
| Humanity’s Last Exam | 47.2 | 50.0 | 49.8 | 44.4 | 41.4 |
| CharXiv Reasoning | 85.1 | 86.6 | 84.2 | 83.3 | 84.1 |
| GPQA-D | 95.5 | 95.5 | 92.0 | 94.3 | 93.6 |
| SciCode | 60.1 | 58.7 | 53.5 | 58.9 | 56.1 |
| τ³ Banking | 21.7 | 20.6 | 20.6 | 8.4 | 20.6 |
| Long Context Reasoning | 74.7 | 73.3 | 67.7 | 72.7 | 74.3 |
| MRCRv2 | 86.6 | 93.6 | 87.9 | 84.9 | 94.8 |
* We use the mini-swe-agent as the scaffolding for this task. * mini-swe-agent をスキャフォールドとして使用。
† We use model provider-reported scores for the baselines. † モデル提供元が公表したスコア。
Qualitative Results
Qualitative Results Sakana Fugu の性能:定性的な例
These examples compare Sakana Fugu models with three frontier baselines — Gemini 3.1 Pro (high) , Opus 4.8 (max) , and GPT 5.5 (xhigh) . To keep the focus on behavior rather than brand-by-brand attribution, the baselines are anonymized as Model A , Model B , and Model C in each description. The mapping is intentionally not fixed across examples. 以下の例では、 Sakana Fugu を、 Gemini 3.1 Pro(high) 、 Opus 4.8 (max) 、 GPT 5.5(xhigh) の3つのフロンティアモデルと比較しています。個別モデルではなく挙動の違いに注目できるよう、ベースラインを Model A 、 Model B 、 Model C として匿名化しています。 なお、どのモデルがA〜Cかは例ごとに変えています。
This experiment shows an AI agent autonomously improving a small GPT's training recipe. Using AutoResearch (Karpathy et al.) – which iteratively edits training code, runs experiments, and keeps only changes that lower validation bits-per-byte (BPB) – the agent ran 123 experiments over ~14 hours on a single H100 GPU. Each line traces a system's best BPB as experiments accumulate: Fugu-Ultra is in bold red (solid = mean over three seeds, dashed = best single run), with three frontier-model baselines (Model A, B, and C) faded behind it, and the callouts mark each new improvement the agent found on its own — spanning batch size, model depth, learning rates, and optimizer settings. Fugu-Ultra finishes with the best mean BPB (0.9774 ± 0.0019), ahead of Model C (0.9781), Model B (0.9793), and Model A (0.9822), and its best single run reaches 0.9748, leading every baseline. This suggests that orchestrating multiple strong models can outperform any individual frontier model on agentic ML research. 例1 — AutoResearch / LLM学習
AIエージェントに小規模なGPTの学習レシピを自律的に改善させる実験。学習コードを反復的に書き換え、実験を実行し、検証用 bits-per-byte(BPB)を下げた変更だけを残していくエージェント型フレームワーク AutoResearch(Karpathy et al.)を用い、エージェントは単一のH100 GPU上でおよそ14時間にわたり123回の実験を実施した。各線は、実験が積み重なるにつれて各システムが達成した最良のBPBの推移を表している。Fugu-Ultra は太い赤の線(実線=3シードの平均、破線=最良の単一実行)で示し、その背後に3つのフロンティアモデルのベースライン(Model A・B・C)を淡色で重ねている。吹き出しは、エージェントが自ら見つけた改善点をそれぞれ示しており、バッチサイズ、モデルの深さ、学習率、オプティマイザの設定など多岐にわたる。Fugu-Ultra は最終的に最良の平均BPB(0.9774 ± 0.0019)を達成し、Model C(0.9781)、Model B(0.9793)、Model A(0.9822)を上回った。最良の単一実行では 0.9748 に到達し、すべてのベースラインを上回っている。これらの結果は、複数の強力なモデルをオーケストレーションすることで、エージェント型のML研究において単体のフロンティアモデルを上回り得ることを示唆している。
This case study tests whether the reading order of classical Japanese kana letters (仮名消息) can be recovered — letters whose scattered chirashigaki ("scattered-writing") layout makes that genuinely hard even for trained readers of classical Japanese. Each model is given the character bounding boxes together with a rough set of reading-order rules, and writes code that outputs the order the characters should be read in; here it runs on a letter written in 1610 by Hōshun'in (芳春院, 1547–1617), scored by NED (a score based on normalized edit distance from an expert's ground-truth order, where 1.0 is a perfect match). Several frontier models were put through the identical pipeline, but none came close to Fugu-Ultra on this letter: Model A reached only NED 0.24 and Model B scored no better, both far below Fugu-Ultra's 0.80, while Model C produced no predictor at all. The clip shows the two extremes — each panel draws its predicted path in red over the expert's ground truth in green: Fugu-Ultra (top) traces the letter almost exactly, while Model A (bottom) jumps all over the page. (Letter held by the Keio Institute of Oriental Classics.) 例2 — 仮名消息の読み順推定
本ケーススタディは、仮名消息(古典日本語のかな書状)という歴史的資料における読み順の推定問題を対象とする。仮名消息は、文字を紙面に散らして記す「散らし書き」という形式で書かれているため、古文書を読み慣れた人でも文字の読み順を正しく判定することは難しい。そこで各モデルに対して、文字を囲む四角形(バウンディングボックス)と読み順の大まかなルールを与え、文字の読み順を推定するコードを出力させた。実験の対象には1610年に芳春院(ほうしゅんいん、1547–1617)が記した書状を選び、NED(専門家による正しい読み順との正規化編集距離にもとづくスコア。1.0が完全一致)で評価した。複数のフロンティアモデル(A-C)を同一のパイプラインに通したところ、Fugu-Ultraの結果は他のモデルを大きく引き離した。Model AはNED 0.24、Model Bもそれと大差なく、いずれもFugu-Ultraの0.80には遠く及ばない。さらにModel Cはまともなコードを一回も出力できなかった。モデルによる読み順の違いを可視化するために、専門家による正解の読み順(緑)の上に、推定した経路(赤)を描いて映像化した。Fugu-Ultra(上)が読み順をほぼ正確になぞる一方、Model A(下)は紙面全体をあちこち飛び回り、両者は大きく異なる結果を示している。 図:芳春院消息(慶應義塾大学斯道文庫蔵)
In this benchmark, each of Fugu-Ultra and 3 frontier models is given a single prompt to write a Rubik's Cube solver from scratch in pure Python — no off-the-shelf solving libraries allowed — and the resulting program is run locally on a held-out set of 300 randomly scrambled cubes. Solution quality is measured by the number of moves a solution uses, where lower is better. Fugu-Ultra and the frontier Model A wrote solvers that ran and solved all 300 cubes, while Model B and Model C each shipped sophisticated-looking code that crashed on execution and returned no valid solution at all (0/300). The clip follows cube #17: from the same scramble, Fugu-Ultra's solver reaches the solved state in 19 moves while Model A needs 21 — and across all 300 cubes Fugu-Ultra averages 19.72 moves versus 19.76 for Model A, both right at the optimal frontier, with Fugu-Ultra never a move longer than Model A on any cube (7 wins, 293 ties, 0 losses). 例3 — ルービックキューブ・ソルバー
本ベンチマークでは、Fugu-Ultraと3つのフロンティアモデルそれぞれに、純粋なPythonのみでルービックキューブソルバーをゼロから実装するよう単一のプロンプトを与えた。既存のソルバーライブラリの使用は禁止とし、生成されたプログラムをランダムにスクランブルされた300個のキューブからなるホールドアウトセットに対してローカルで実行した。解法の質は手数で評価し、少ないほど良いとする。Fugu-Ultraとフロンティアの Model A は300個すべてのキューブを解くソルバーを生成したが、Model B と Model C は一見洗練されたコードを出力したものの、実行時にクラッシュし、有効な解を一つも返せなかった(0/300)。映像はキューブ#17の様子である。同一のスクランブルに対し、Fugu-Ultraのソルバーは19手で完成状態に到達したのに対し、Model A は21手を要した。300個全体の平均では、Fugu-Ultraが19.72手、Model A が19.76手と、いずれも最適解の水準にあり、Fugu-Ultraが Model A より手数が多かったケースは一度もなかった(7勝・293引き分け・0敗)。
Task: Create a mechanical iris in CAD, like a camera aperture, where multiple blades move together to open and close the central hole. For each model, we show both the generated detailed CAD itself and a simplified view that makes the structure easier to see. In the CAD generated by Fugu Ultra, the blades rotate around outer pins and clearly open and close the aperture. In contrast, the CAD generated by the other models shows problems such as gaps appearing, weak linkages, or the aperture not closing fully. 例4 — CAD メカニカルアイリス
タスク:カメラの絞り(アパーチャ)のような、複数の羽根が連動して動き中央の穴を開閉する機械式アイリスをCADで作成する。各モデルについて、生成された詳細CAD(Detailed CAD)そのものと、構造を見やすくするための簡易ビュー(Simplified view)の両方を示す。Fugu Ultraが生成したCADでは、羽根が外側のピンを軸に回転し、アパーチャを明確に開閉できている。一方、他のモデルが生成したCADでは、隙間ができてしまう、リンク機構が弱い、アパーチャを十分に閉じきれていない、といった問題が見られる。
Four blindfold chess games, back to back. Every model plays the same way — no board shown — holding the full game in memory. Fugu outplays four strong opponents: three leading frontier models and a 2100-Elo Stockfish engine, staying accurate where they drift and ending each game in checkmate. 例5 — 目隠しチェス
4局の目隠しチェスを連続して対局している。すべてのモデルは同じ条件でプレイし、盤面は一切表示されず、ゲーム全体を記憶の中に保持しながら指し手を進める。Fugu は4つの強力な相手——3つの主要なフロンティアモデルと、2100-Elo の Stockfish エンジン——を打ち負かした。相手が手を乱していく場面でも正確さを保ち、いずれの対局もチェックメイトで終えた。
This benchmark uses a single anonymized equity over one historical 50-week window and is intended to compare sequential, no-look-ahead decision-making rather than to establish generalizable trading performance. Past performance does not guarantee future results, and results may not transfer to other assets, time periods, or live markets. Each model makes online trading decisions on anonymized STOCK_X, using only current and past weekly market data: opening, high, low, and closing prices, volume, returns, moving averages, volatility, drawdown, portfolio state, and prior feedback. Starting with $10,000, the agent chooses whether to buy, hold, or sell, and what fraction of cash or shares to trade. After each action, the next week's price is revealed and the portfolio is updated, so the model must adapt from feedback rather than seeing the future. Across five runs of the identical 50-week pipeline, Fugu-Ultra grew the portfolio to $11,943.22 ± $633.86, a +19.43% mean return, while the other frontier models reached their return less than +15%. 例6 — 株式トレーディング
匿名化された単一銘柄を1つの過去50週間のウィンドウで用いるこの株式トレーディングのベンチマーク。汎用的なトレーディング性能を立証するためではなく、先読みのない逐次的な意思決定を比較することを目的としている。過去の実績は将来の結果を保証するものではなく、結果が他の資産・期間・実際の市場に当てはまるとは限らない。各モデルは、匿名化された STOCK_X に対して、現在および過去の週次マーケットデータ——始値、高値、安値、終値、出来高、リターン、移動平均、ボラティリティ、ドローダウン、ポートフォリオの状態、直前のフィードバック——のみを用いてオンラインでトレーディングの意思決定を行う。1万ドルからスタートし、エージェントは買い・保有・売りのいずれかと、現金または株式のどの割合を取引するかを選択する。各アクションの後に翌週の価格が開示され、ポートフォリオが更新されるため、モデルは未来を見るのではなくフィードバックから適応しなければならない。同一の50週間パイプラインを5回実行した結果、Fugu-Ultra はポートフォリオを 11,943.22 ± 633.86 ドルまで成長させ、平均リターンは +19.43% に達した。一方、他のフロンティアモデルのリターンはいずれも +15% 未満にとどまった。
Users' Voices
What do our users think about Sakana Fugu ? Sakana Fugu に対するユーザー評価
01
Software Engineer ソフトウェアエンジニア
Coding & Code Review コーディング&コードレビュー
For code review, Fugu Ultra is significantly better than GPT-5.5. It gives comprehensive answers and finds the bugs others miss. Where other tools flag about three issues, Sakana Fugu surfaced more than twenty. It's become the model I run all my reviews through. コードレビューでは、Fugu Ultra は回答が網羅的で、他のモデルが見逃すバグまで見つけてくれました。他のツールでは3件くらいの問題しか指摘されなかったが、 Sakana Fugu は20件以上を洗い出してくれました。
02
Researcher (industry) 研究者(企業)
Research & Autonomy 自律的なリサーチ
I was mapping a patent landscape across ~20 papers and several patents, normally 3–4 days of work. With Fugu I had a full analysis in a few hours, including connections between papers I would never have spotted on my own. 約20本の論文と複数の特許にまたがる特許動向(パテントランドスケープ)を作成しました。普段なら3〜4日かかる作業が、 Sakana Fugu を使うと数時間で完全な分析ができ、そのなかには、自分では決して気づけなかっただろう論文同士のつながりを見つけることができました。
03
Executive (enterprise platform) プラットフォーム企業・役員
Orchestration オーケストレーション
Raw output quality is on par with top frontier models, but Fugu showed unusually strong persona stability across long sessions, holding its identity where other models drift. For agent products, that may matter more than raw benchmark scores. 素の出力品質はトップクラスのフロンティアモデルと同等。加えて Sakana Fugu は、長時間のセッションでもペルソナが安定しており、他のモデルなら崩れてしまう場面でもキャラクターを保ち続けました。エージェントにとっては、これは単純なベンチマークスコア以上に重要なことです。
04
Researcher 研究者
Paper Reproduction 論文の再現
From one simple request, Sakana Fugu worked autonomously for nearly four hours — reading the paper, implementing, training, evaluating, and analyzing the gaps. 一つのシンプルな指示から、 Sakana Fugu はおよそ4時間続けて自律的に作業しました。論文を読み込み、実装・学習・評価まで行い、足りない点を分析してくれました。
05
Security Engineer セキュリティエンジニア
Security Assessment セキュリティ評価
Given one scoped instruction, Sakana Fugu drove a full security assessment end-to-end — recon, XSS/SQLi checks, auth review, and a clean report with evidence and retest steps — staying inside scope and avoiding destructive actions. 範囲を絞った指示を一つ渡しただけで、 Sakana Fugu は情報収集から XSS/SQLi の検査、認証まわりのレビュー、さらに証拠と再テスト手順を備えた整然としたレポート作成まで、セキュリティ評価を一気通貫でこなしました。しかも指定した範囲を逸脱せず、システムを壊すような操作も避けてくれました。
Pricing
Pricing Plan 料金プラン
01 Pay-as-you-go トークンプラン
Enterprise エンタープライズ
For heavy, production workloads needing maximum reliability — consumption-based tokens are served at higher priority than monthly-plan tokens. 最大限の信頼性が求められる高負荷・本番ワークロード向け。従量課金のトークンは、月額プランのトークンより高い優先度で処理されます。
Fugu
When 1 agent is active エージェントが 1 つの場合
You pay only the standard rate for that specific underlying model. その基盤モデルの標準レートのみをお支払いいただきます。
When multiple agents are active 複数のエージェントが稼働している場合
We never stack model fees; you are charged a single rate based on the top tier model involved. モデル料金を積み上げることはありません。関与する最上位モデルに基づく単一のレートで課金されます。
Fugu Ultra
Fixed pricing for fugu-ultra-20260615 fugu-ultra-20260615 の料金(一律)
Input 入力
$5
$10 when context > 272K $10(コンテキスト272K超)
Output 出力
$30
$45 when context > 272K $45(コンテキスト272K超)
Cached input キャッシュ入力
$0.50
$1.00 when context > 272K $1.00(コンテキスト272K超)
02 Subscription Plan サブスクリプションプラン
Monthly 月額
Best for individuals and everyday hands-on use. Every tier includes both Fugu and Fugu Ultra — upgrade when you need longer, heavier, or more frequent sessions. 個人ユーザーや日常的なご利用に最適。すべてのプランで Fugu と Fugu Ultra の両方をご利用いただけます。より長時間・高負荷・高頻度の作業が必要な場合は上位プランへ。
Subscribe before the end of July 2026 to get a free second month at your initial subscription tier. 2026 年 7 月末 までにご登録いただくと、 ご加入いただいたプラン の 2 か月目を無料 でご提供します。
Standard
$20 /month /月
Lightweight daily usage 軽量な日常利用に
For occasional API calls, small experiments, and trying Fugu in personal workflows. 低頻度の API 利用、小規模な実験、個人ワークフローでの試用に。
Baseline allowance 標準の利用枠
Pro
$100 /month /月
Focused working sessions 集中した作業セッションに
For regular coding, review, research, and analysis sessions throughout the week. 普段のコーディング、レビュー、調査、分析セッションに。
10× Standard usage Standard の 10 倍の利用枠
Max
$200 /month /月
Heavy long-running workloads 長時間の高負荷ワークロードに
For power users who keep Fugu active across deeper, longer-running tasks. より深く長時間のタスクで Sakana Fugu を継続的に使うパワーユーザー向け。
20× Standard usage Standard の 20 倍の利用枠
Start Using Sakana Fugu 今すぐはじめる
FAQ
Sakana Fugu is available through an OpenAI-compatible API. Point your existing client or coding harness at the Fugu endpoint with your API key and start sending requests — no SDK migration required. Sakana Fugu は OpenAI 互換 API を通じて利用できます。既存のクライアントやコーディングハーネスを、API キーとともに Fugu のエンドポイントに向けてリクエストを送るだけです——SDK の移行は必要ありません。
Fugu balances latency and quality, making it a strong default for everyday coding and interactive work. Fugu Ultra prioritizes answer quality on complex, multi-step reasoning, coordinating more expert agents when accuracy and depth matter most, at the cost of response time. Early users reach for Fugu Ultra on demanding tasks like paper reproduction, Kaggle competitions, and paper or patent research. Fugu はレイテンシと品質のバランスが取れており、日常的なコーディングやインタラクティブな作業に適した標準モデルです。Fugu Ultra は、複雑で多段階の推論において回答品質を最優先し、精度と深さが重要な場面ではより多くの専門エージェントを連携させます(その分、応答時間は長くなります)。先行ユーザーは、論文の再現、Kaggle コンペティション、論文・特許調査などの難しいタスクで Fugu Ultra を活用しています。
Fugu Ultra relies on the full agent pool to deliver its performance, so its pool is fixed. For Fugu, you can opt out of specific models from the settings menu on our console page to match your data, privacy, and compliance needs. Fugu Ultra はその性能を発揮するために全エージェントプールを利用するため、プールは固定です。Fugu については、コンソールページの設定メニューから特定のモデルを除外でき、データ・プライバシー・コンプライアンスの要件に合わせられます。
We aim to give users the best performance available. When a new frontier model is released publicly, we expect to spend roughly two weeks training and evaluating updated Fugu models before rolling them out. 私たちは利用可能な最高の性能をユーザーに提供することを目指しています。新しいフロンティアモデルが一般公開された場合、アップデート版の Sakana Fugu モデルのトレーニングと評価に約 2 週間をかけ、その後順次提供開始していく予定です。
We offer both subscription and pay-as-you-go plans, and every plan includes access to both Fugu and Fugu Ultra. The subscription plan has three monthly tiers: Standard ($20/month) is great for lightweight daily use; Pro ($100/month) provides 10× the usage of Standard, ideal for a few focused working sessions each week; and Max ($200/month) provides 20× the usage of Standard, built for heavy, long-running workloads. The pay-as-you-go plan bills by token usage instead of a monthly allowance, giving you elastic capacity for spikes and large jobs — ideal for enterprise customers. With it, Fugu is charged at the standard rate of the underlying model, and when multiple agents are active we never stack fees: you pay a single rate based on the top tier model involved. Fugu Ultra (fugu-ultra-20260615) is priced per 1M tokens at $5 input, $30 output, and $0.50 cached input, with higher rates ($10 / $45 / $1.00) for contexts above 272K tokens. サブスクリプションプランと従量課金プランの両方をご用意しており、すべてのプランで Fugu と Fugu Ultra の両方をご利用いただけます。サブスクリプションプランには月額 3 つのプランがあります。Standard($20/月)は軽量な日常利用に最適、Pro($100/月)は Standard の 10 倍の利用量を提供し週に数回の集中作業に向いており、Max($200/月)は Standard の 20 倍の利用量を提供し長時間にわたる負荷の高いワークロード向けです。従量課金プランは月額の利用枠ではなくトークン使用量に応じて課金され、スパイクや大規模ジョブに対する柔軟なキャパシティを提供します——エンタープライズのお客様に最適です。このプランでは Fugu は基盤モデルの標準レートで課金され、複数のエージェントが稼働している場合でも料金を積み上げることはありません。関与する最上位モデルに基づく単一のレートでお支払いいただきます。Fugu Ultra(fugu-ultra-20260615)は 100 万トークンあたり、入力 $5、出力 $30、キャッシュ入力 $0.50 で、272K トークンを超えるコンテキストではより高いレート($10 / $45 / $1.00)が適用されます。
Yes. Think of Fugu pricing as a single blended rate for the active agent pool, not a sum of every model used. If your pool contains only Model A, requests are billed at Model A's rate. If your pool contains Models A, B, and C, you still pay only one rate: the rate of the top tier model among A, B, and C. In other words, adding more agents does not multiply the bill; it only determines which single model rate applies to that configured pool. はい。 Sakana Fugu の料金は、使用したすべてのモデルの合計ではなく、稼働中のエージェントプールに対する単一のブレンドレートだと考えてください。プールにモデル A だけが含まれている場合、リクエストはモデル A のレートで課金されます。プールにモデル A・B・C が含まれている場合でも、お支払いは 1 つのレート——A・B・C のうち最上位モデルのレート——だけです。つまり、エージェントを増やしても請求が積算されるわけではなく、その構成済みプールに適用される単一のモデルレートが決まるだけです。
Yes. Token usage and the corresponding cost are reported per request, so you can monitor spend in real time and forecast costs before scaling up. はい。トークン使用量と対応するコストはリクエストごとに報告されるため、支出をリアルタイムで把握し、スケールアップ前にコストを予測することができます。
Usage data helps us keep improving Fugu's performance, and we're grateful when customers share it. That said, it's entirely your choice — you can opt out of training data usage at any time from our console page. 学習データ利用についてはコンソールページからいつでもオプトアウトすることができます。お客様のご判断でご共有いただける場合は Sakana Fugu の性能向上に役立てます。
No. The specific models Fugu selects and how it coordinates them are proprietary, so this routing information is not exposed by design. いいえ。 Sakana Fugu が選択する具体的なモデルやそれらをどのように連携させるかは独自技術であり、この設計情報は公開していません。
Yes, Fugu is available from outside Japan. However, we do not provide services to users in EU (European Union) or EEA (European Economic Area) member states (please refer to our Terms of Service for details). Additionally, in other regions, access may not be available due to network conditions or local regulations. はい、日本国外からもご利用いただけます。ただし、EU(欧州連合)およびEEA(欧州経済領域)加盟国へのサービス提供は行っておりません(詳細は利用規約をご確認ください)。また、それ以外の地域におきましても、通信環境や現地の各種規制等によってご利用いただけない場合がございます。
Contact Us
Ready to build with Sakana Fugu ? Sakana Fugu を使った開発を始めてみませんか?
Get in touch to learn more about access, plans, and enterprise deployment. アクセス方法やプラン、エンタープライズ向けの導入に関する詳細については、お問い合わせください。