GLM-5.2 just came out, and it's another step forward for what open models can do. The internet promptly freaked out, and it's hard to tell what's real and what's hype.
So we ran it head-to-head against Claude Opus 4.8: same one-shot prompt, build a 3D platformer in raw WebGL from scratch. Here's our take after running the test and digging through the benchmarks and the buzz.
We're not switching our main off Opus. In our test Opus was faster and shipped a cleaner, more correct game, and it can check its own visual output, which the text-only GLM-5.2 can't. But GLM-5.2 earns a permanent spot in the arsenal: it's a genuinely capable model at a fraction of the price, and because it's open weights, it'll always be available. A closed model can be retired or restricted with little warning (Fable was a recent reminder); weights you can download can't be taken away.
You can play both games right now, or grab the source:
- GLM-5.2's game: 3dgame-glm.d.ritzademo.com
- Opus's game: 3dgame-opus.d.ritzademo.com
- Source for both: github.com/jamesdanielwhitford/glm-5.2-vs-opus-platformers
Both are browser games written from scratch, with no game engine or 3D rendering library like Three.js. The 3D models are free CC0 assets from Kenney.
Here's how the two runs compared:
| Metric | GLM-5.2 (Pi/OpenRouter) | Opus (Claude Code) |
|---|---|---|
| Wall-clock build time | 1h 10m 40s | 33m 30s |
| Output tokens | 131,000 | 216,809 |
| Peak context window | 16% of 1M | 19% of 1M |
| Tool calls | 128 | 153 |
| Cost | $5.39 (real billed) | ~$21.92 (estimate, list pricing) |
GLM-5.2 cost a fraction as much. Opus finished in half the time and shipped a cleaner game.
On paper, the benchmarks put GLM-5.2 just behind the top closed models, and the online buzz is a mix of genuine signal and astroturf. We get into both below, after the game.
What is GLM-5.2
GLM-5.2 is Z.ai's latest flagship model. It's open weights under an MIT license, so you can download it, run it yourself, or call it through Z.ai's API.
It's built for long-horizon tasks, the kind of long, multi-step coding-agent work that runs for hours. It ships with a 1M-token context window and two thinking effort levels, High and Max, that trade speed for capability.
note
GLM-5.2 is text-only, not multimodal. It can't read images, so workflows built around screenshots or diagrams still need a model like Claude Opus.
Z.ai positions it roughly between Claude Opus 4.7 and 4.8 at similar token usage. Here's their announcement, if you want to read more:
Pricing and access
Because it's open weights, GLM-5.2 is cheap. Through an API it costs a fraction of Opus, and you can run it yourself for free if you have the hardware.
Pricing, per 1M tokens (vendor docs):
| Input | Cache read | Output | |
|---|---|---|---|
| Claude Opus 4.8 | $5 | $0.50 | $25 |
| GLM-5.2 | $1.4 | $0.26 | $4.4 |
On output tokens, GLM-5.2 is less than a fifth the price of Opus.
The weights are on Hugging Face and ModelScope under an MIT license, with no regional restrictions. You can serve it locally with frameworks like vLLM, SGLang, or Transformers.
Our vibe test: a 3D game from scratch
To cut through the vibes, we gave Opus 4.8 and GLM-5.2 the same one-shot prompt: build a 3D platformer game from scratch, in raw WebGL, with no game engine or 3D library.
Why this task
A model can zero-shot a good-looking landing page, and the community already discounts that as a test of much. A 3D platformer in raw WebGL can't be faked in one pretty file. It has real structure: a GLB model parser, matrix and vector math, GLSL shaders, skinned skeletal animation, a fixed-timestep loop, collision, a follow camera.
That structure tests both things people argue about at once. Holding a layered, multi-file build together over many steps is the agentic part, where GLM-5.2 is meant to be strong. Getting the engine internals right, the parts that look fine but quietly break, is the reasoning-and-taste part, where Opus is meant to pull ahead.
We bundled the 3D assets locally, so the test is the engine and the rendering, not whether the harness can fetch a model file. The art itself is a human-made asset pack, Kenney's CC0 Platformer Kit, and both agents were handed the identical files.
What each model had to build
To finish, each model had to build:
- A 3D engine and renderer in raw WebGL, no Three.js or any library.
- A loader for the supplied 3D character and world models.
- A character that runs and jumps around an arena, with gravity and collision.
- A follow camera and keyboard controls.
- The whole thing runnable in the browser with one command.
Both did most of it by hand (by tool? by claw?): a GLB binary parser, the matrix and quaternion math, a WebGL2 renderer with GLSL skinning shaders, and substepped AABB collision to keep the character from tunneling through platforms.
Both got the same prompt, the same assets, and one attempt with no hints. We ran Opus 4.8 with extended thinking on high, and GLM-5.2 with thinking set to high (GLM-5.2 also has a higher Max tier we didn't use). You can dig into both runs yourself:
- Play GLM-5.2's game: 3dgame-glm.d.ritzademo.com
- Play Opus's game: 3dgame-opus.d.ritzademo.com
- Source for both: github.com/jamesdanielwhitford/glm-5.2-vs-opus-platformers
- Opus build transcript: full session
- GLM-5.2 build transcript: full session
How long it took, and what it cost
Opus 4.8 built in Claude Code; GLM-5.2 built in Pi over OpenRouter.
Side-by-side timelapse. Opus finishes at 34:00, GLM-5.2 at 1:11.
The timelapse shows the whole build compressed: Opus working through it in roughly half the wall-clock time, GLM-5.2 grinding longer but for far less money. The full numbers are in the results table at the top.
Playtesting both games
We played both games start to finish. Here's how each one held up.
Both built the same kind of game: a third-person 3D platformer with the same controls. You move with WASD or the arrow keys, jump with space, sprint with shift, and orbit the camera by dragging the mouse, with the wheel to zoom. The goal is the same too: collect the coins across the platforms and reach the flag, avoiding a spike hazard, with a fall off the world sending you back to the start.
GLM-5.2
GLM-5.2's game looks kind of rough. From the playthrough:
- It doesn't look great overall.
- The character is missing some of its materials.
- The spike hazard doesn't kill the character.
- Reaching the flag does nothing. There's no win condition.
So it's not that great. It did nail one thing, though: the spring.
GLM-5.2 spring launch.
You can jump on the spring and launch up to the next platform.
Opus
Opus's game is cleaner, and plays well. From the playthrough:
- The camera and controller work.
- The spike hazard kills the player, so that logic is correct. But it sits off to the side of the level, not on the path, so you'd have to go out of your way to hit it.
- It looks good overall, and you can reach the flag and win. There's a real win condition.
The animations look good and run smoothly, with textures applied properly.
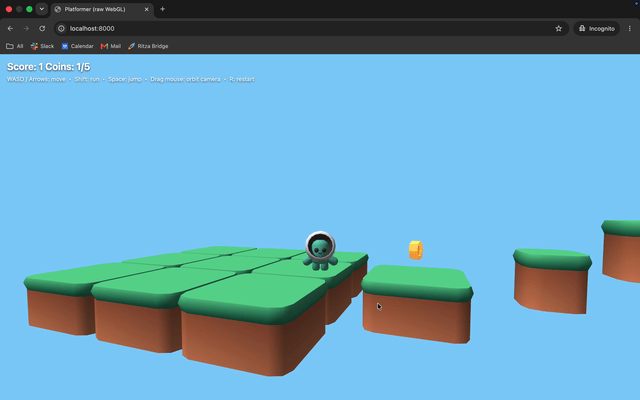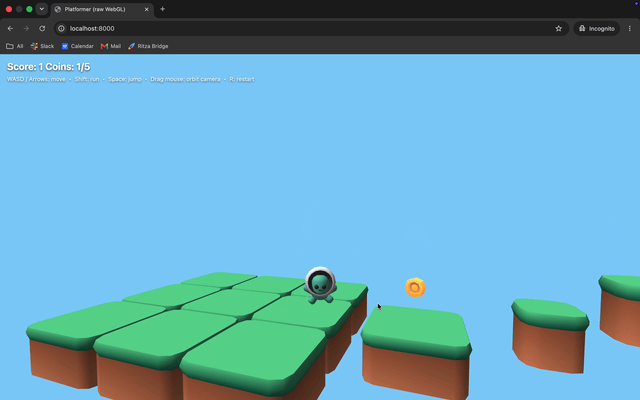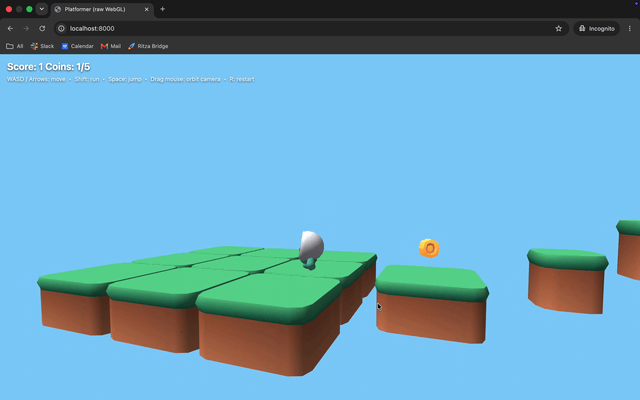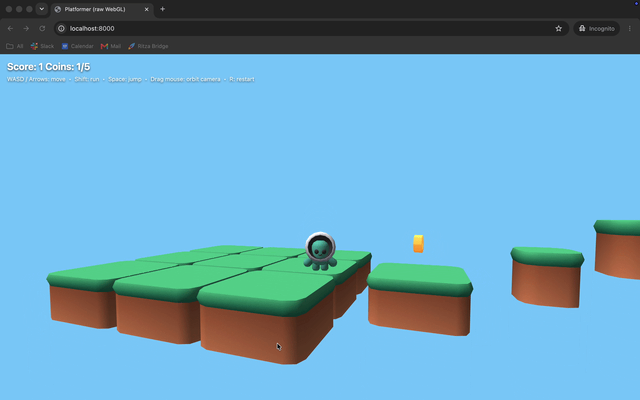
Opus: animations, textures, controller working.
How each model checked its own work
Both models were told to verify their work before stopping. One common way an agent does this is to take a screenshot of the finished product and look at it, to check that nothing is broken or missing. That is exactly what Opus did in its session.
GLM-5.2 hit a problem here, because it can't read images. It isn't multimodal. So instead of looking at a screenshot, it fell back on a hacky workaround: it wrote scripts to read the raw pixel data and check whether the colors came out roughly as expected.
Why GLM-5.2's self-check missed the bugs
Because it couldn't see the screenshot it had saved, GLM-5.2 tried to verify the frame by reading its pixels instead. Here's an excerpt from its final report, where it "analyzed" the saved image by sampling colors:
final_start/overview/flag.pnganalyzed for color: grass green, dirt brown, coin gold, flag red, character bluish, half-Lambert lit, no black
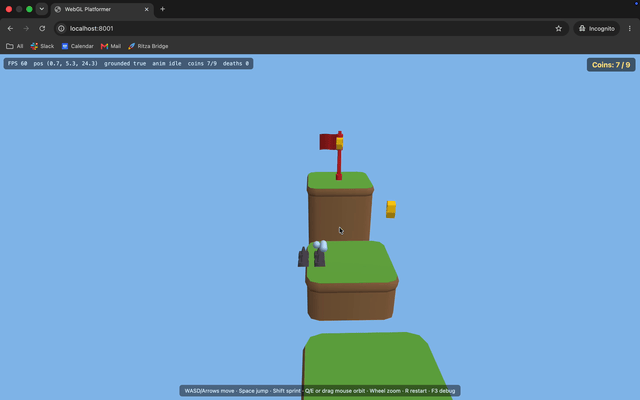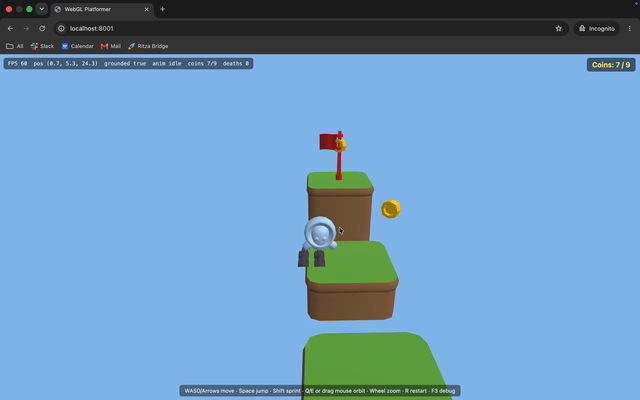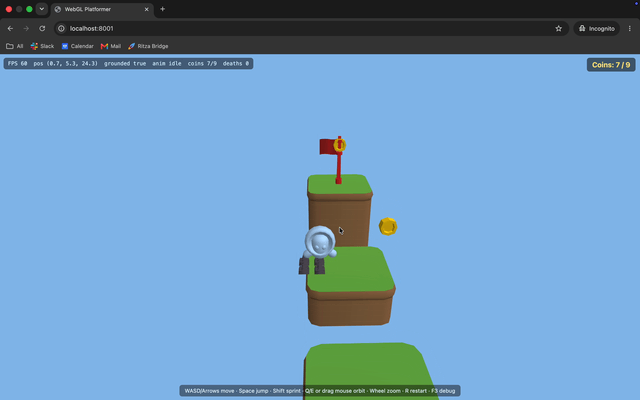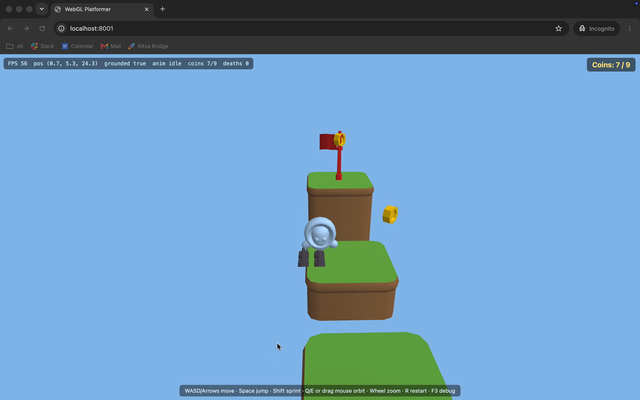
The colors it expected were there, so it confirmed the game was finished and stopped. But as you can see in its own final screenshot below, the character is a flat gray with its textures missing, and the debug overlay is still sitting over the scene. An agent that could actually look at the screenshot would likely have caught both, and gone back to fix them.
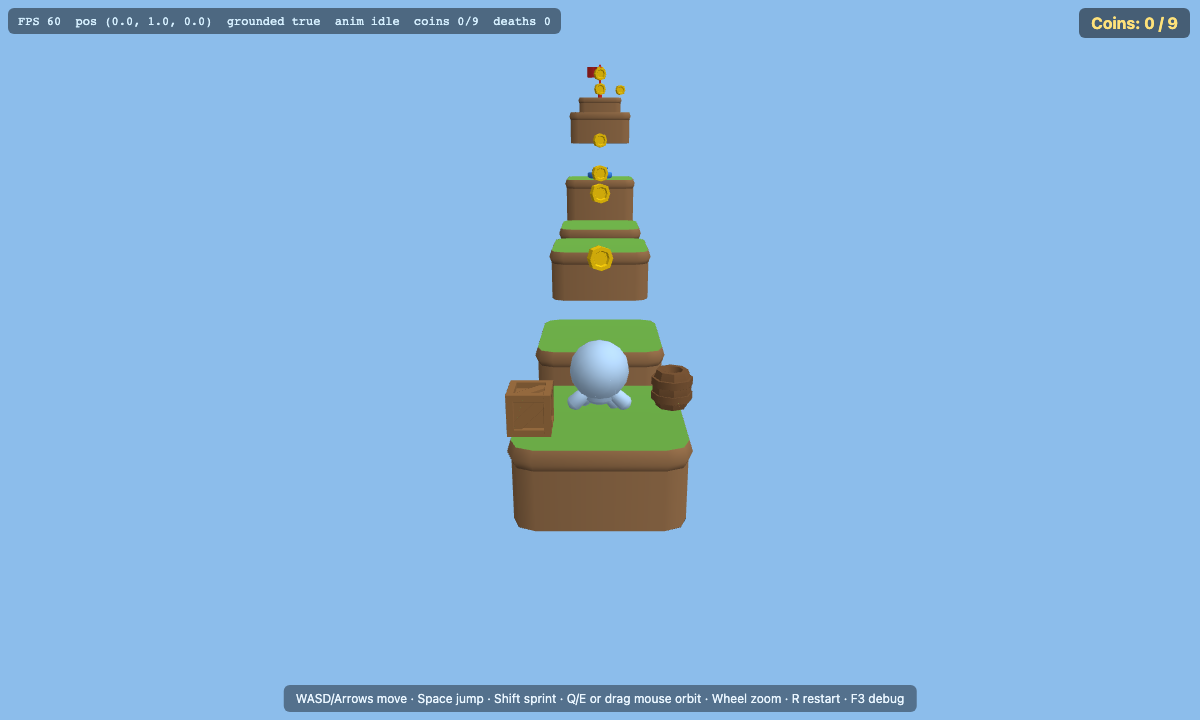
GLM-5.2's final screenshot: textures missing on the character, debug overlay still on. It never saw the frame.
On a task with a visual result, being able to understand an image gives a model a real edge over one that can't.
How Opus checked its work
Opus is multimodal, so it could read a screenshot directly. Its harness rendered the game and captured a frame, and Opus inspected that image as part of its verification. Here's an excerpt from its session, describing what it saw:
The final scene renders correctly: grass-topped blocks with brown dirt sides, the staircase climbing up, gold/silver coins and a jewel, the blue spike-block hazard on the right island, the red flag at the top goal, the character […] standing on the start plaza, and the score HUD. Lighting and shading are correct, geometry is clean.
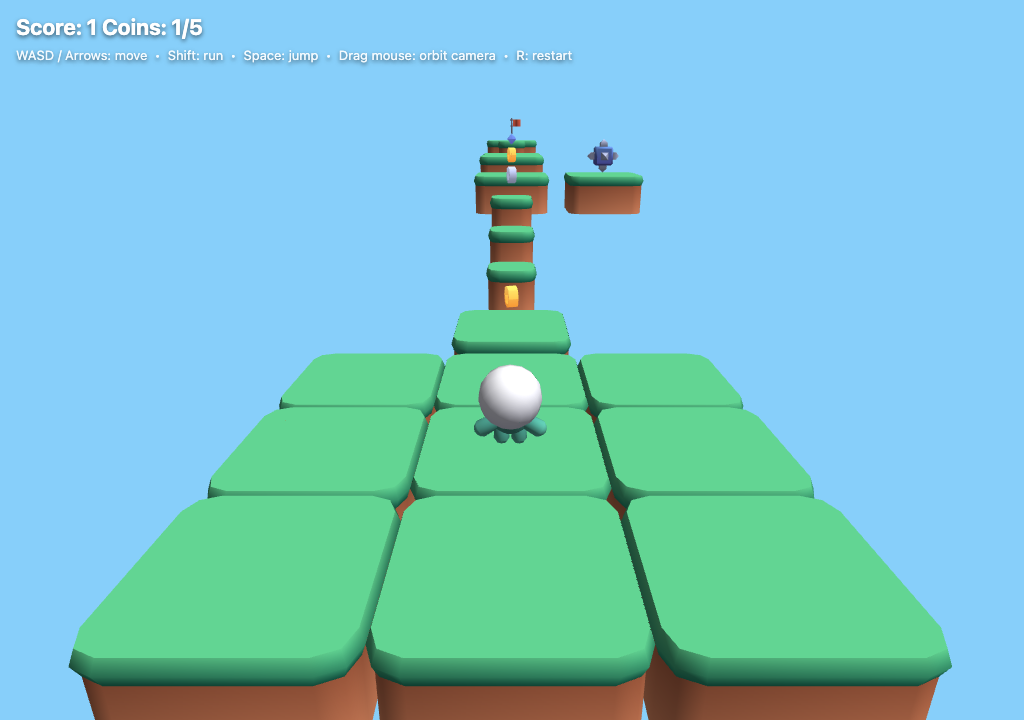
Opus's screenshot: clean HUD, debug readouts removed.
Because it could see the frame, Opus noticed the debug readouts it had left on screen and cleared them before finishing.
The bugs
Both games had bugs. Here's what broke in each.
GLM-5.2
GLM-5.2's bugs were frequent and visible, and several were fundamentals.
The character faces the wrong way. It walks in the right direction, but the model is turned backwards the whole time.
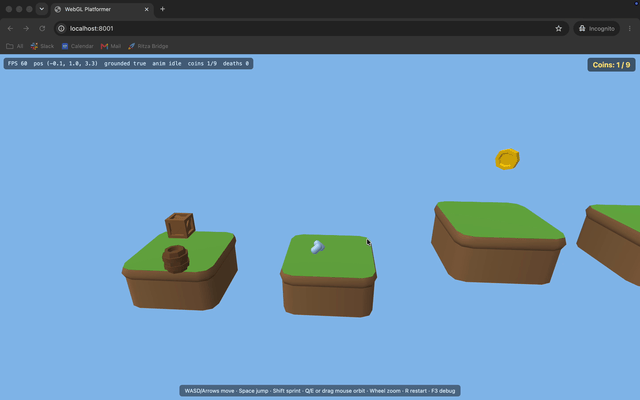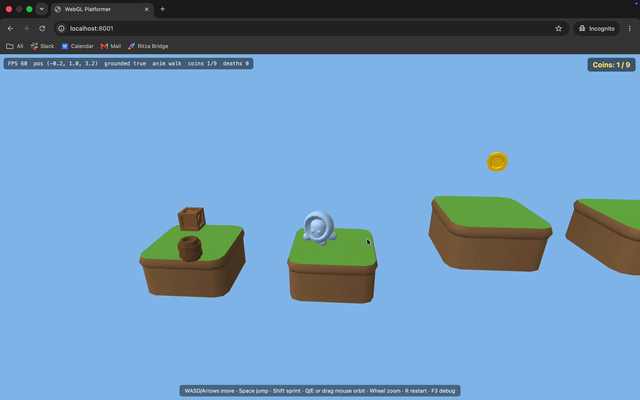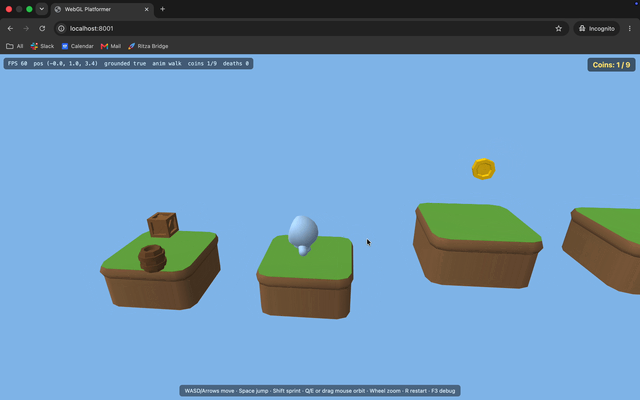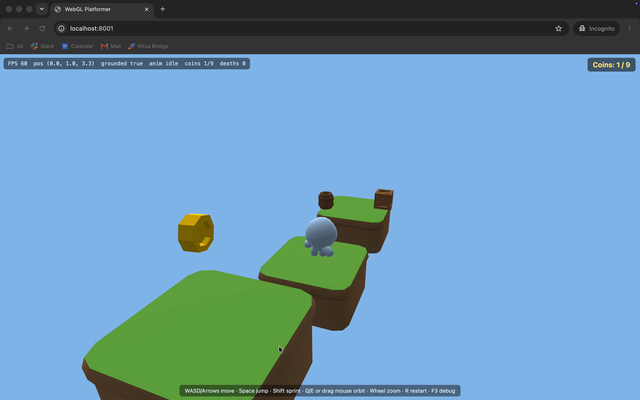
Missing textures and a disappearing head. The character renders flat gray instead of textured, and its head vanishes whenever the camera moves. The Kenney models point to a shared color palette in a separate file rather than embedding it, and GLM-5.2's renderer never loaded that file, so it fell back to flat colors. Opus loaded the palette, so its character came out textured.
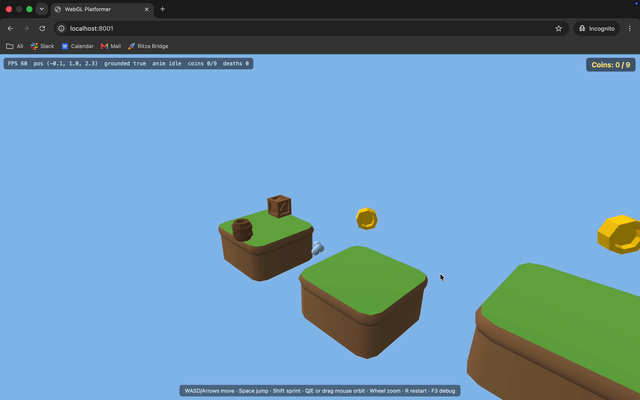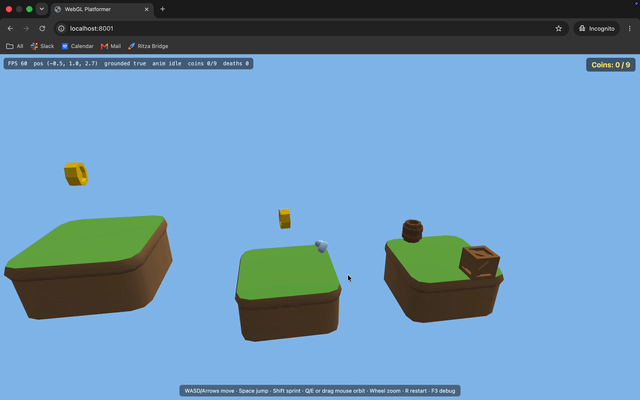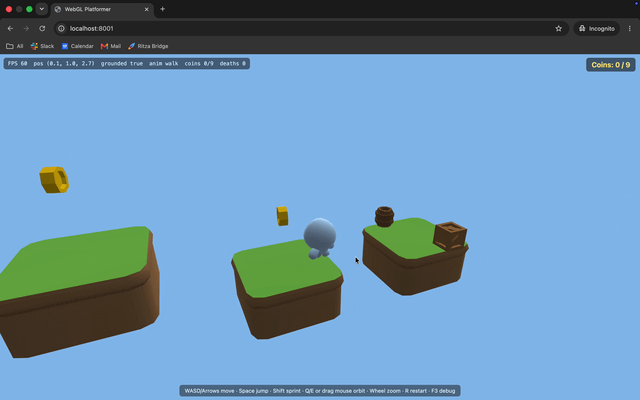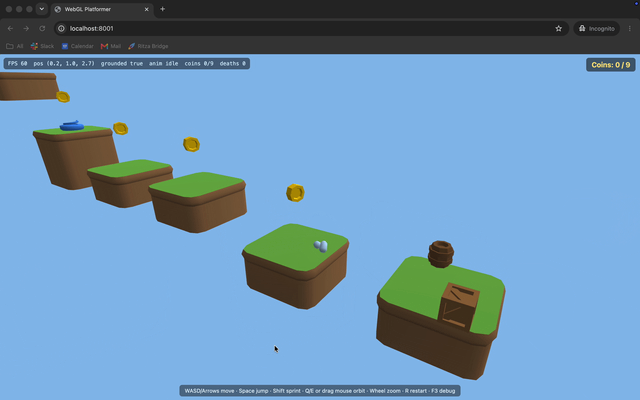
The death spike doesn't kill. The character lands right on a spike hazard and nothing happens. No death, no reset.
Opus
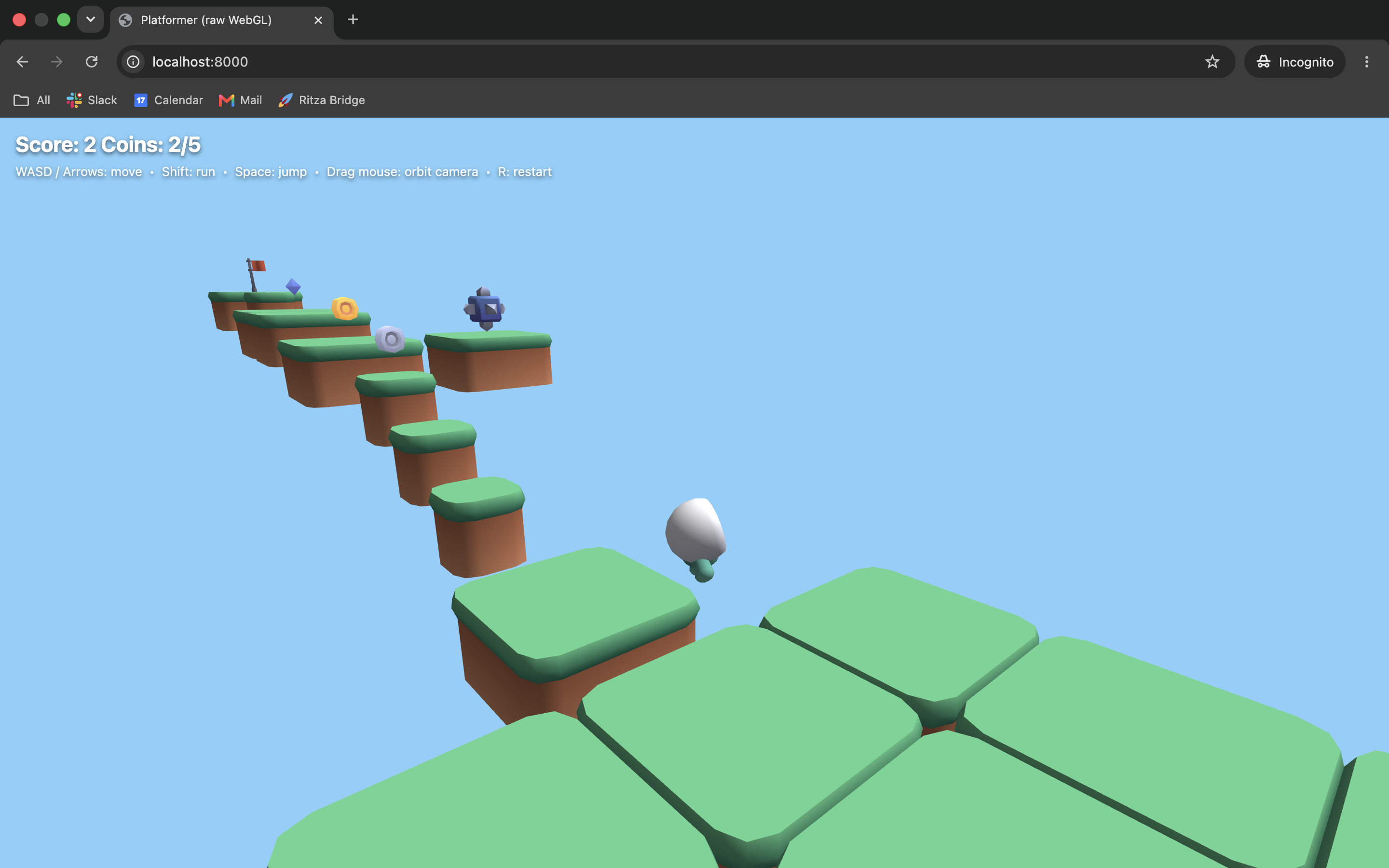
Opus's were fewer and subtler, edge cases rather than broken basics.
Standing on thin air. The character can sit beside a platform, in mid-air, without falling. This is its coyote-time grace period, the brief window where you can still jump just after stepping off an edge, tuned a little too generously. A polish feature slightly overdone, not a broken fundamental.
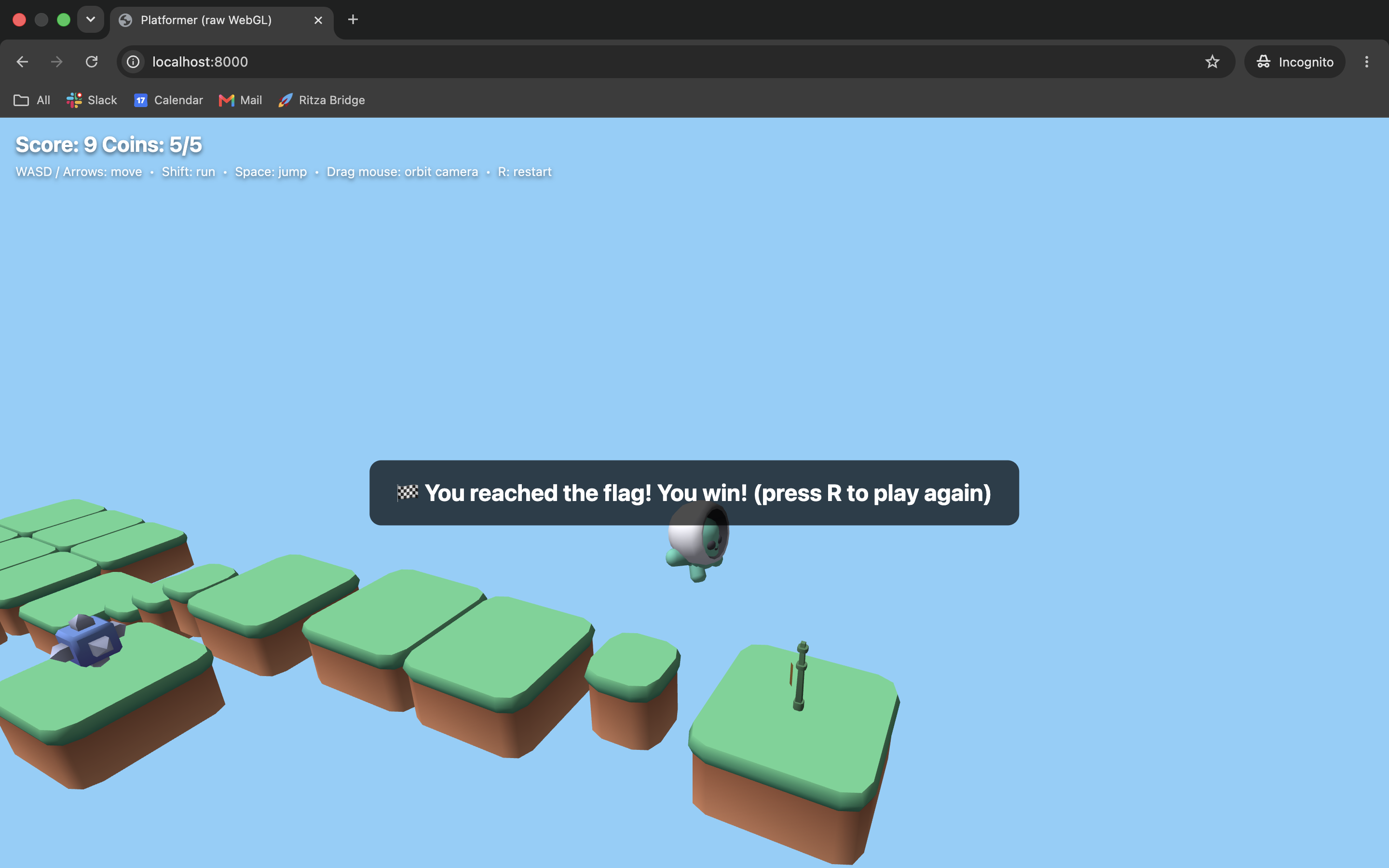
Winning from too far away. The win triggers while the character is still well short of the flag.
What the test showed
Both models built a complete, running 3D platformer from scratch, no engine and no 3D library, in a single pass. That is a high bar, and not long ago neither would have cleared it. Here is how they split.
GLM-5.2: slower, rougher, cheaper
GLM-5.2 took over twice as long and shipped a rough game: a gray untextured character, a spike that doesn't kill, no working win condition, and a debug overlay still on screen at the end. Most of its bugs were fundamentals. It cost a fifth as much.
Opus: faster, cleaner, pricier
Opus finished in half the time and shipped the cleaner, more correct game. Its bugs were edge cases, not broken basics. It cost roughly four times as much.
The multimodal advantage
Opus can read images, so its self-check looked at the rendered game and caught visual problems. GLM-5.2 is text-only: it verified through numbers and never saw that its character was gray or that its debug overlay was still up. On a visual task, that was the difference between catching the rough edges and shipping them.
One game is one data point. The benchmarks below test the same kinds of ability at scale.
The benchmarks
Z.ai published these benchmark numbers alongside the release, on its model card. The best result in each row is in bold.
| Benchmark | GLM-5.2 | Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Reasoning | ||||
| HLE | 40.5 | 49.8* | 41.4* | 45 |
| HLE (w/ tools) | 54.7 | 57.9* | 52.2* | 51.4* |
| AIME 2026 | 99.2 | 95.7 | 98.3 | 98.2 |
| GPQA-Diamond | 91.2 | 93.6 | 93.6 | 94.3 |
| IMOAnswerBench | 91.0 | 83.5 | – | 81 |
| Coding | ||||
| SWE-bench Pro | 62.1 | 69.2 | 58.6 | 54.2 |
| NL2Repo | 48.9 | 69.7 | 50.7 | 33.4 |
| DeepSWE | 46.2 | 58 | 70 | 10 |
| ProgramBench | 63.7 | 71.9 | 70.8 | 39.5 |
| Terminal Bench 2.1 (Terminus-2) | 81.0 | 85 | 84 | 74 |
| Terminal Bench 2.1 (best harness) | 82.7 | 78.9 | 83.4 | 70.7 |
| SWE-Marathon | 13.0 | 26.0 | 12.0 | 4.0 |
| Agentic | ||||
| MCP-Atlas (public) | 76.8 | 77.8 | 75.3 | 69.2 |
| Tool-Decathlon | 48.2 | 59.9 | 55.6 | 48.8 |
An independent run by ArtificialAnalysis broadly agrees:
- Intelligence Index v4.1: 51 (leading open-weights; MiniMax-M3 44, DeepSeek V4 Pro 44, Kimi K2.6 43).
- TerminalBench v2.1: 78% (vs 81 / 82.7 on the model card — different harness).
- Output tokens per task: ~43k (GLM-5.1: 26k).
The numbers track our test: GLM-5.2 leads the open-weights pack and trades blows on reasoning, but Opus still takes most of the coding and agentic rows.
What each benchmark measures
These benchmarks span three areas. Here's what each one tests, grouped the same way as the table.
Reasoning, hard math and science exams:
- HLE. Humanity's Last Exam. Thousands of expert-level questions across many subjects, built to be extremely hard. The "w/ tools" row is the same exam with web search and code allowed.
- AIME 2026. A hard American high-school math competition.
- GPQA-Diamond. Graduate-level science questions written so they can't be answered with a quick search.
- IMOAnswerBench. Math-olympiad-style problems, scored on the final answer.
Coding, fixing bugs and building whole projects:
- SWE-bench Pro. Fixing real issues in real codebases, often with changes across several files.
- NL2Repo. Building a whole, runnable codebase from a single written spec.
- DeepSWE. Agentic software-engineering tasks in a sandboxed container with no internet.
- ProgramBench. Rebuilding a full program from only its compiled binary and documentation, with no source or spec given.
- Terminal Bench 2.1. Tasks completed through a real terminal. The two rows use a fixed harness (Terminus-2) and each model's best harness.
- SWE-Marathon. Twenty ultra-long-horizon engineering tasks, each running for hours.
Agentic, calling and chaining real tools:
- MCP-Atlas. Tool-use tasks run against real MCP servers, each needing several tool calls.
- Tool-Decathlon. Long-horizon tasks across many real apps, each needing a long chain of tool calls.
What people are saying
Benchmarks and our own test are one thing; the online reaction is another. A lot of it is hype from accounts with no track record, so we stuck to people and groups whose judgment has held up over time.
Simon Willison: "probably the most powerful text-only open weights LLM"
Simon Willison has written up nearly every notable model release for years. He called GLM-5.2 "probably the most powerful text-only open weights LLM."
His standard test is to ask a model for an SVG of a pelican riding a bicycle. GLM-5.2 returned a fully animated one with nothing broken, which he called "very impressive."

A second test, an opossum on a scooter, came out worse than GLM-5.1 had managed a version earlier. So it's strong, but not uniformly.
Artificial Analysis: top open model, but token-hungry
Artificial Analysis, an independent benchmarking group, ranked GLM-5.2 the leading open-weights model on their Intelligence Index. It scored 51, ahead of MiniMax-M3, DeepSeek V4 Pro, and Kimi K2.6, and sits on their cost-versus-intelligence frontier as the cheapest model at its level.
They flag the same thing we ran into: it's token-hungry. It uses about 43k output tokens per task, most of it reasoning, more than any other leading open model they measured.
Nathan Lambert: the open-closed gap is closing
Nathan Lambert tracks open-weight models for a living at the Allen Institute for AI. Looking at where GLM-5.2 lands on the LMArena leaderboards, he argued that "you could argue they have a better agent than Gemini does," and called it "a serious accomplishment" for an MIT-licensed open model.
His wider point is that the Chinese labs are reaching these scores on far less compute, and shouldn't be discounted, even if the top US models still lead overall. That matches our test, where Opus came out ahead but GLM-5.2 was closer than its price and openness would suggest.
The verdict
So, is the hype real? Mostly.
GLM-5.2 is a genuinely strong open model, at a fraction of Opus's price. For a lot of work, that combination is hard to beat. But it isn't Opus. In our test, Opus was faster, shipped a cleaner and more correct game, and could check its own work by looking at it. GLM-5.2 was far cheaper, but rougher, and it's text-only.
Use GLM-5.2 when cost and openness matter and the work is mostly text and logic. Use Opus when correctness, polish, and visual judgment matter, and you'll pay for it. And keep GLM-5.2 in the arsenal regardless: it's the rare frontier-adjacent model that no vendor can take away from you.