![]()
Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance
(*) Equal Contribution, (†) Project Leader, (📧) Corresponding Author.
1Huazhong University of Science and Technology 2VIVO AI Lab
Abstract
While 10B-level industrial foundation models have pushed the boundaries of image inpainting, their prohibitive computational costs severely hinder practical deployment. Constructing a highly optimized task-specific specialist offers a promising solution; however, extreme structural compression inevitably triggers a severe representation bottleneck. To conquer this, we propose Moebius, a highly efficient lightweight inpainting framework. We systematically reconstruct the diffusion backbone by introducing the Local-λ Mix Interaction (LλMI) block. Comprising Local-λ and Interactive-λ modules, it elegantly summarizes spatial contexts and global semantic priors into fixed-size linear matrices, preserving complex latent interactions while drastically shedding parameters. Furthermore, to unlock the full representational capacity of this highly compact architecture, we synergistically pair it with an adaptive multi-granularity distillation strategy. Operating strictly within the latent space to avoid expensive pixel-space decoding, this strategy dynamically balances multiple gradient-based losses to achieve high-fidelity alignment. Extensive experiments across natural and portrait benchmarks demonstrate that this optimal synergy enables Moebius to rival or even surpass the generation quality of the 10B-level industrial generalist FLUX.1-Fill-Dev. Remarkably, Moebius achieves this using less than 2\% of the parameters (0.22B vs. 11.9B) while delivering a >15× acceleration in total inference time, setting a new efficiency standard for high-fidelity inpainting.
Method
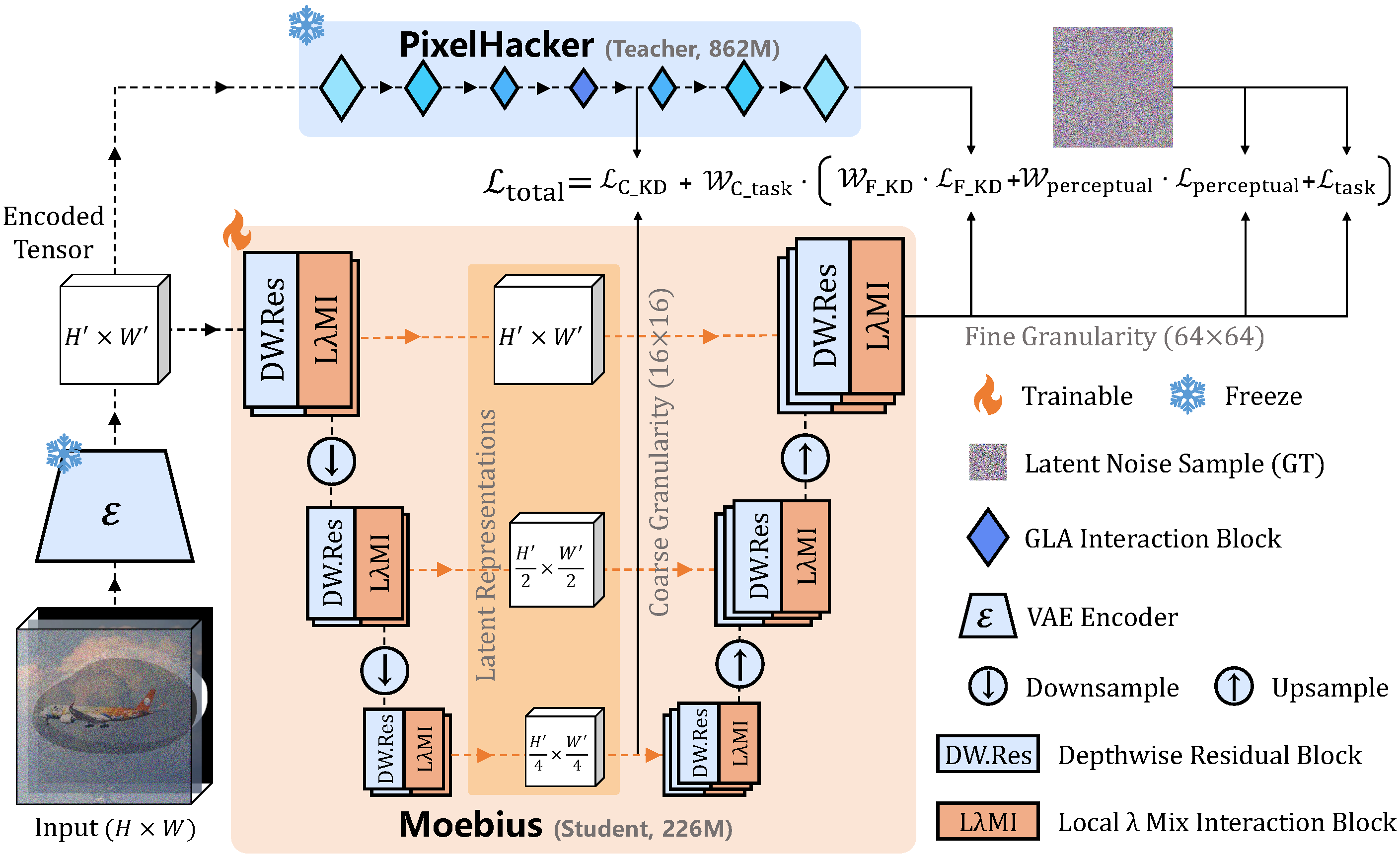
Overall pipeline of Moebius. We adopt the Latent Diffusion Model (LDM) framework equipped with Latent Categories Guidance (LCG). To achieve extreme architectural efficiency, the denoising U-Net is systematically restructured using our proposed LλM I blocks (detailed in Sec. 3.2). Furthermore, an adaptive multi-granularity distillation strategy (Sec. 3.3) is applied during training to align our lightweight specialist with the high-capacity teacher, successfully mitigating the capacity drop caused by extreme structural compression.
Highlights
- 📉 Extreme Parametric Efficiency (< 2%): Moebius operates with a mere 0.22B (226M) parameters, which represents less than 2% of the size of the colossal industrial giant FLUX.1-Fill-Dev (11.9B). It shatters the heavy-compute narrative, making high-quality inpainting accessible on consumer-grade and edge devices.
- ⚡ 15× Inference Speedup (26ms/step): Achieves a blistering inference latency of only 26.01 ms per step on a single GPU. Combined with optimized sampling steps, Moebius delivers an overall >15× total runtime acceleration compared to 10B-level models.
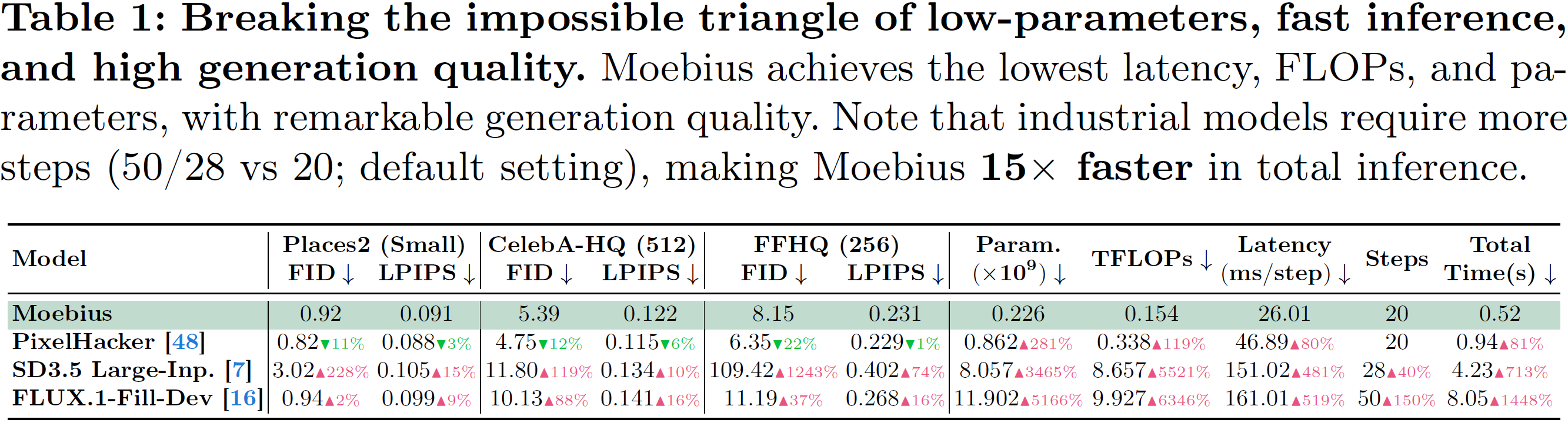
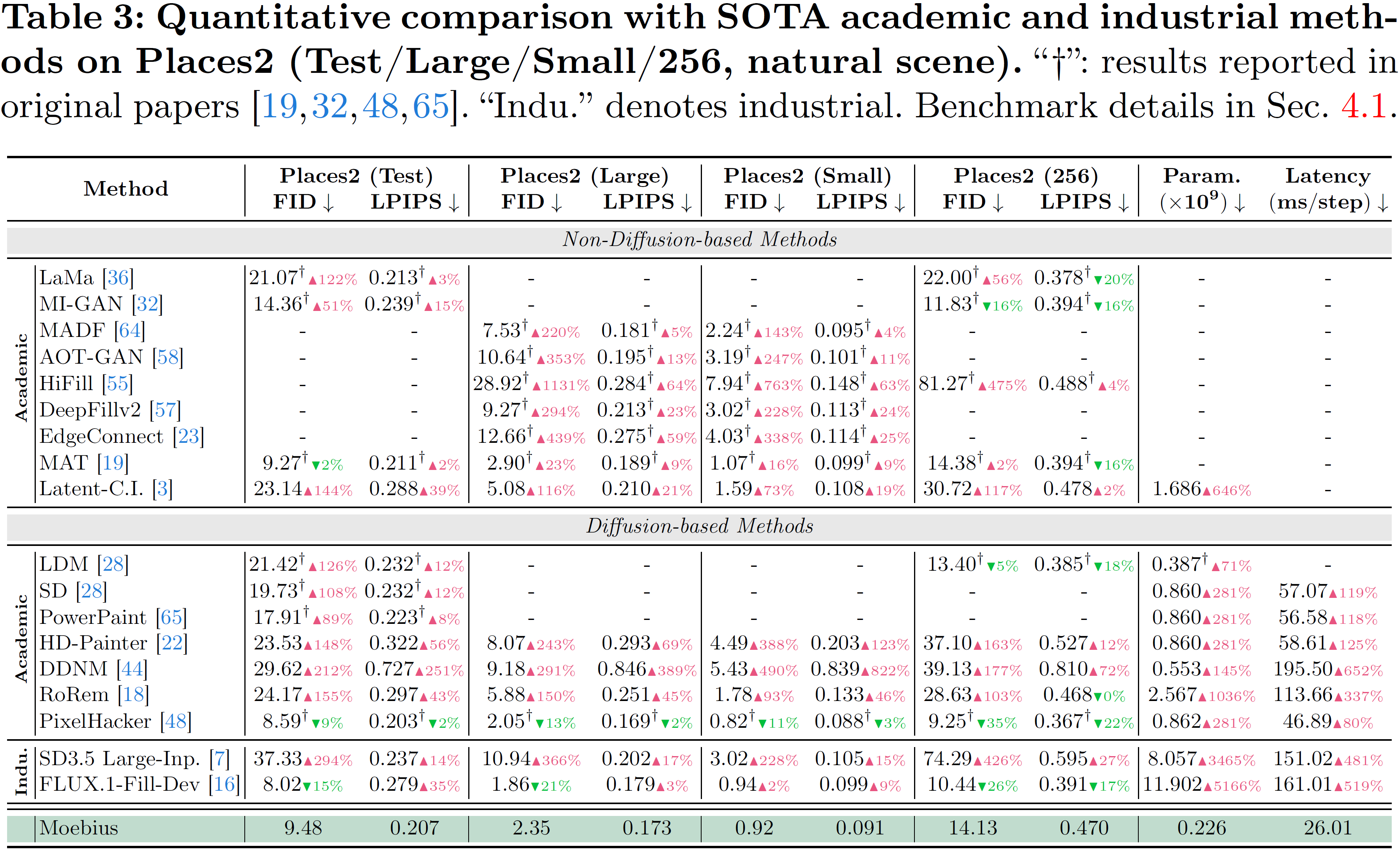
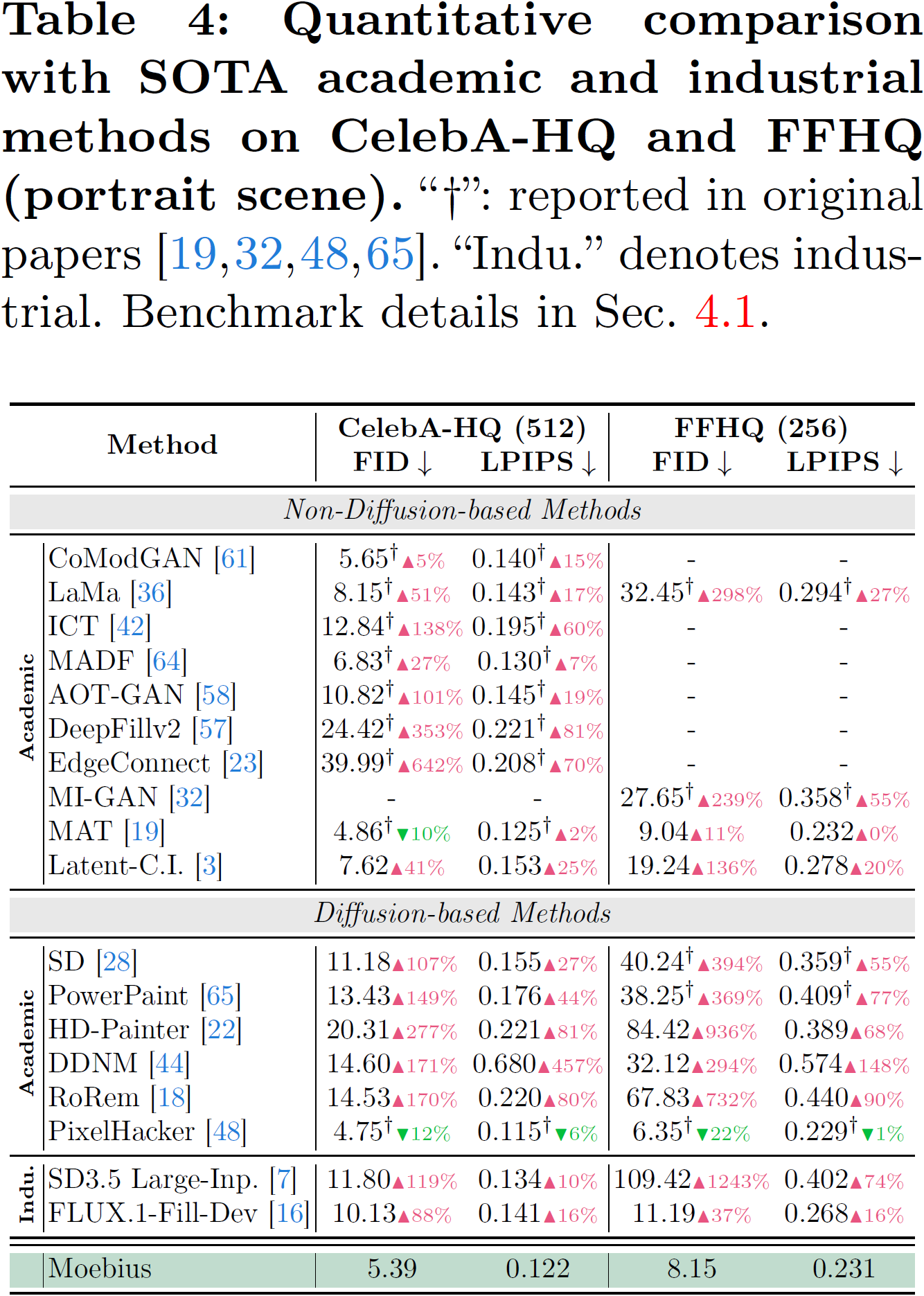
- 🏆 10B-Level Inpainting Quality (on-par-with/surpass FLUX.1-Fill-Dev across 6 benchmarks): Size contraction does not mean representation degradation. Through the synergistic optimization of architecture and distillation, Moebius performs on par with, and in certain scenarios (such as complex textures and facial plausibility), surpasses 10B-level state-of-the-art (SOTA) generalist models (FLUX.1-Fill-Dev, SD3.5 Large-Inpainting) across 6 comprehensive benchmarks spanning both natural scenes (Places2) and portrait scenes (CelebA-HQ, FFHQ).
- 💡 Synergistic Core Innovations:
- Architecture Design (LλMI Block): Reformulates both self- and cross-attention by condensing spatial context and global semantic priors into fixed-size linear matrices, bypassing quadratic computational overhead.
- Adaptive Multi-Granularity Distillation Strategy: Transfers the representational capacity from our PixelHacker (teacher) strictly within the latent space (avoiding expensive pixel-space decoding). It bridges the giant capacity gap by aligning multi-granularity supervision—ranging from microscopic intermediate features to macroscopic diffusion trajectories—while dynamically balancing training via a gradient norm adaptive loss weighting mechanism.
- Optimal Synergistic Balancing: Systematically explores the mutual constraint and upper bound between compact structure and distillation. By mapping this architecture-distillation synergy frontier, we ensure our 0.22B Moebius (student) absorbs the maximum semantic reasoning of PixelHacker (teacher) without triggering representation saturation.
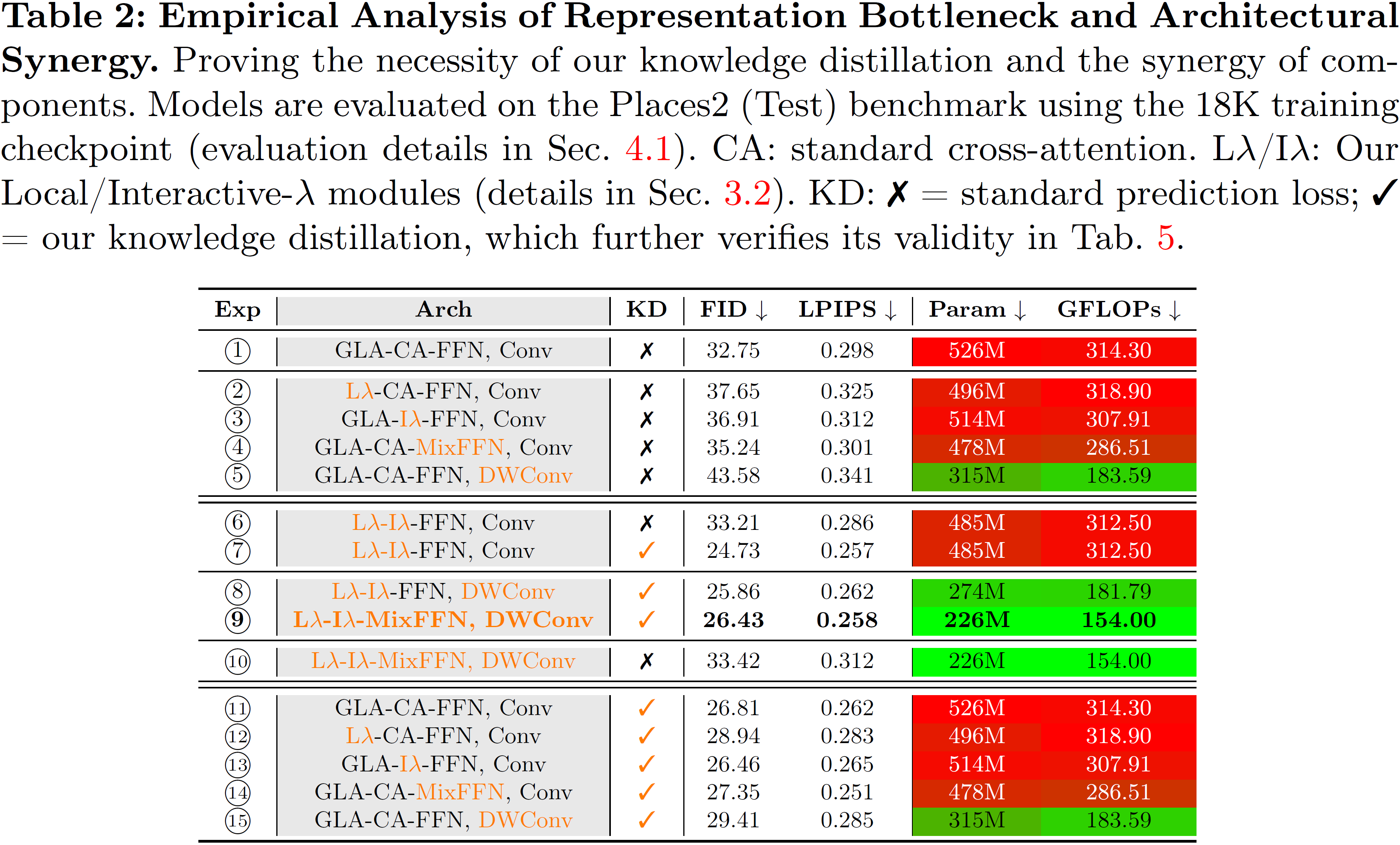
- 🚀 Task-Specific Specialist over Bloated Generalists: Rather than blindly scaling up, Moebius answers a fundamental question: Can a model be smarter, lighter, and faster when the task is explicitly defined? It serves as a highly optimized specialist that liberates real-world image inpainting and AI object removal from parameter bloat.
Visualizations
- Natural Scenes -





















































































- Portrait Scenes -






















































Comparison on Natural Scenes (Places2)
Comparison on Portrait Scenes (CelebA-HQ, FFHQ)

BibTeX
@misc{DuanAndXu2026Moebius,
title={Moebius: 0.2B Lightweight Image Inpainting Framework with 10B-Level Performance},
author={Kangsheng Duan and Ziyang Xu and Wenyu Liu and Xiaohu Ruan and Xiaoxin Chen and Xinggang Wang},
year={2026},
eprint={2606.19195},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.19195},
}