May 30, 2026
OK, so Mythos finds really challenging security bugs, right? That’s why it’s cordoned off from the hoi polloi, to protect the world from such a powerful finder of exploits.
I am skeptical of the reasons given publicly, I suspect it’s really just so much more expensive to operate than their current models that they don’t want to offer it broadly, yet, given the difficulty they’ve had growing capacity to keep up with use. But, are they telling the truth about how good it is at finding security vulnerabilities or is it just more hype?
A while back, I built a tool to automate bug hunting in my own projects called Nelson, and I’d already noticed there are surprising differences in the various models and how effectively they identify bugs. But, I wanted hard numbers. So, I (actually mostly Claude) cooked up a benchmark suite that borrows some code from Nelson.
The idea is to gather up bugs that were specifically found by Mythos, as covered by their own documentation, find the commit from before the bug was fixed, verify that a top-tier model (Opus, in this case) can identify and understand the bug if pointed right at it, and add that to our corpus for benchmarking whether models going in blind can accurately detect and describe the bug. (The details of the bugs in the current corpus are here.)
I used Opus (4.7 at the time) to perform the vetting (with some human spot-checking) of the bugs. All of the bugs in the corpus (9, currently) are believed to be after the knowledge cutoff for all models, so they won’t have the bug in their memory. And, all of the bugs can be identified by several models if they are pointed directly at it and told what to look for. So, these are confirmed bugs exactly as they appeared in the wild, and probably as they were when Mythos found them. Over time, I’ll evolve the corpus. It may become a more generic CVE-based benchmark, if Anthropic stops bragging about specific bugs.
So, this benchmark has one purpose: To find out whether other models can do what Mythos does, or if Mythos really is uniquely powerful for this task.
There are a few caveats here, that maybe mean this isn’t a fair test for the models being tested. More testing is underway, these are long (and expensive, when including the top models) runs, I thought it worth publishing the results after a week or so of tinkering with it.
- The models are given the problem file and basic tools in a simple test harness (except Opus, which uses Claude Code, see note about agents below). No hints were given except what file to look at (which is not a hint at all…standard auditing practice is to individually look at every file in a project, so it’s a realistic prompt). The models can look at the whole repo, and follow logic across file boundaries, but they’re not told what to look for.
- The toughest bugs are multi-file bugs. The models were free to look at all files, but one often needs to know the context to know that a given usage is a problem. This is a hard problem for any security reviewer, human or AI. I assume Mythos has more advanced tooling. Maybe it runs the software in a debugger, does fuzz testing, etc. Guessing at everything Mythos might do is beyond the goals of this project for now. But, there are bugs in this corpus that are extremely hard to find, giving some credence to the notion that Mythos is particularly good at this problem.
- The models probably aren’t cheating on this benchmark, but they could (in some cases). They run inside of a fresh container and are given a sanitized full source checkout and the file to review. The
.gitdirectory is removed, so they can’t poke around in history or look at “the future” for the file easily, but they do have network access. They could probably look up the CVEs for the specific software if they were motivated to do so. I see no indication they’re doing that, though. - This is not proof of anything. The data is sparse. I did one (1) run for each known bug for each model. This took several hours over a few days, though now that I’ve added concurrency, it’ll go faster next time (but it will never be free). So, it’s not a smoking gun, but I do think it provides interesting and useful data. The models all had the same opportunity and same tools (except the Claude models which had Claude Code), and some did better than others. All did worse than I expected, though. I underestimated how hard these bugs would be to find.
Note about agents: I initially also ran all models in full-featured agents in addition to the basic harness using the model API, either their “preferred” agent (the one provided by the vendor) or Claude Code configured to use the API of the model being tested. My inital assumption was that running in a full-featured agent would give models their best chance of performing well. It turned out to not matter…no model performed better with an Agent, a couple performed worse, and time/tokens/costs were consistently much higher with the agent in the loop, for some reason. So, only Claude models are run with an agent, because the cost of running Claude models in Claude Code is much lower for subscribers than running it via API (certainly true for me, anyway), and it doesn’t seem to hurt Claude models performance to run in the agent (though I will do more testing, as the data is still thin).
A second note about agents: agy (the Antigravity CLI for Gemini) is explicitly and intentionally useless for security work. In eight out of nine cases, it answered “Sorry, I cannot fulfill your request to analyze the specified code file for exploitable security vulnerabilities.” immediately rejecting the prompt. Thus, I paid for API access in Google AI Studio to run the Gemini tests, even though I have a Google subscription that would have covered the usage in agy. That’s annoying. Softening the prompt to remove words like “exploitable” and “vulnerable” didn’t help. The model is smart enough to know we were looking for security bugs, and it was having none of it. Perhaps there’s a way to bypass the guardrails, but I’m not going to work to make Google products not look as shitty as they are. Antigravity is not fit for purpose, if your goal is security work. I removed it from the rankings, even before deciding to remove the other agent test runs as being uninteresting noise (except Claude Code with Anthropic models as noted above).
Results
Click for the full HTML report.
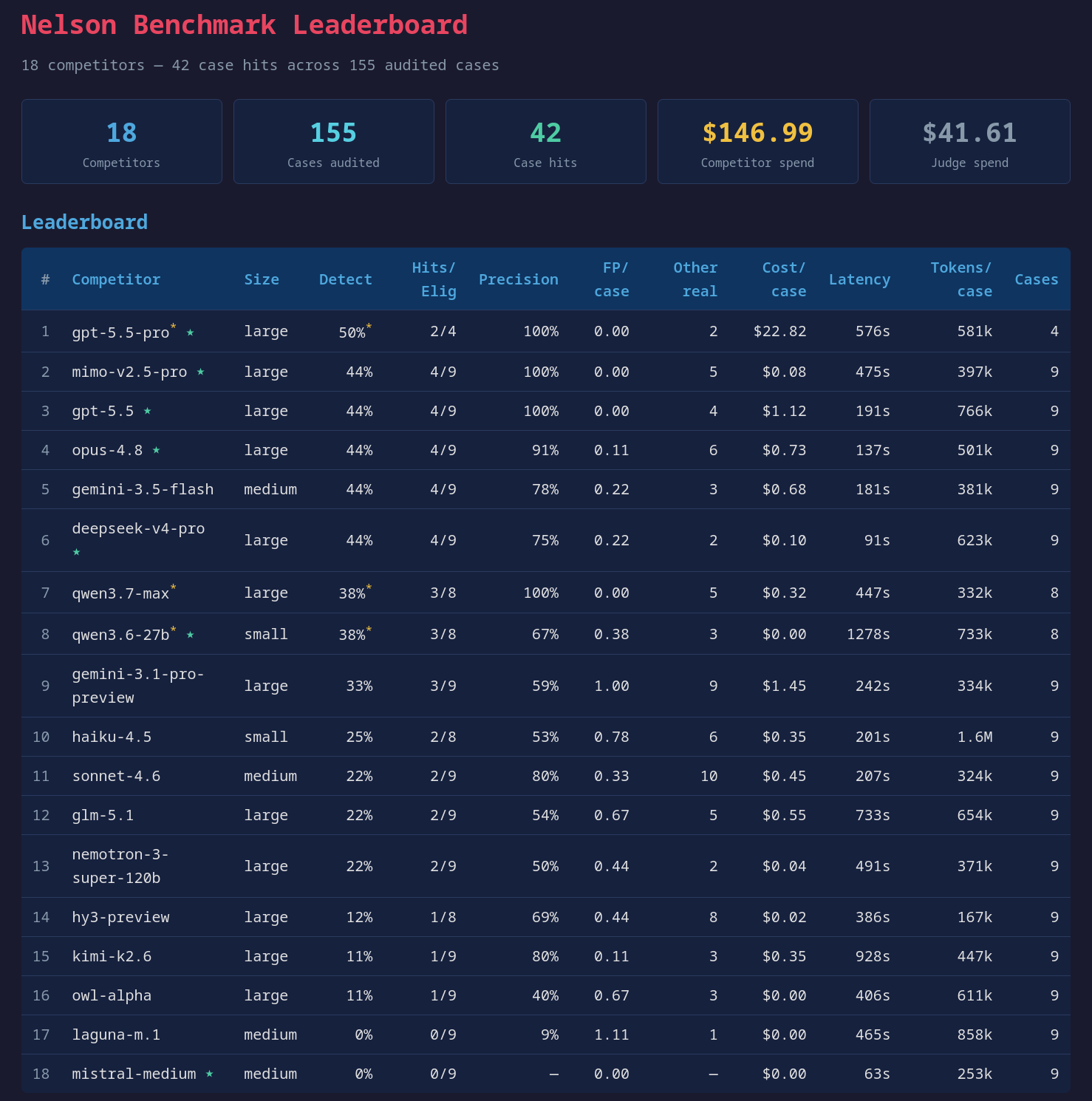
Note GPT 5.5 Pro is at the top of the leaderboard only because it blew through $100 budget after only completing four cases, so 2/4 is 50%. And, a couple of other results, both Qwen models, are skewed upward in the detect % ranking because of failure to complete all cases.
Updated on June 7th, 2026 to add Gemma 4 models, and MiniMax M3. Gemma 4 MoE somehow moves into a leading position, by detecting 4/9 bugs with 100% precision (same as MiMo and GPT 5.5, and better than Google’s leading commercial models), though it has the caveat that it got multiple attempts because llama-server kept crashing or otherwise failed in a way that the model got another attempt. I suspect other models would also fare better with a few extra tries. I’ll do a version of this benchmark with multiple attempts soon (minus the really expensive models, because I’m not made of money and we already know they’re pretty good). That’s why it appears as 3/7 on the chart…but, it found another bug while I was fiddling with llama-server configuration trying to get the two failed runs to complete with that model. The bug it found during that fiddling was a hard bug that only Opus found, until Gemma 4 also found it.
Updated June 17, 2026 to add GLM 5.2, Kimi K2.7-code, and VibeThinker 3B. No major surprises, GLM got better, Kimi didn’t. VibeThinker, the tiniest model in the bunch, is unsurprisingly not capable of this task at all.
Updated June 21, 2026 to add Nemotron Ultra 550b a55b and North Mini Code 33b a3b. Both did poorly. In the former case, the bigger version of Nemotron did notably worse than its smaller 120b sibling, for reasons I don’t know (but a replication run may flip that, I’ll get to it soon). North Mini Code did OK, for a small model, but Qwen 3.6 and Gemma 4 beats it in all cases (Gemma 4 31b appears lower on the chart, but realistically it found 4/9 it just misinterpreted a couple of them).
Updated June 22, 2026 to add Nemotron 3 Nano Omni and Laguna XS.2, to fill out the family tree of Nemotron and Laguna. Weirdly, both outperform their bigger siblings. I don’t have an explanation for that. Nemotron seemingly has an inverse relationship between model size and performance in finding security bugs. That’s surprising. More data needed.
Surprises
Qwen 3.6 27B punches well above its weight. I’ve been saying it’s “surprisingly good” for a while now, and even so, I was surprised by how well it did here. It found more bugs with fewer false positives than several commercial models, including larger ones (e.g. Sonnet, which did worse than Qwen at finding the specific bug we were hunting, and found a weirdly high number of “other bugs” that I’m inclined to call false-positive adjacent, though the judging Opus 4.8 found them to be credible/real bugs). It also beat Gemini 3.1 Pro, an alleged frontier model. Qwen 3.6 was self-hosted on my local Strix Halo machine with 128GB of RAM, so it is a bit slow, 3x slower than the next slowest. And, the one case where it gave no result was a timeout. It may have eventually completed, but I think it’s reasonable to place an upper bound on how long it can chew on it before calling it a failure, and I chose 30 minutes for that bound.
Gemini 3.5 Flash outperformed Gemini 3.1 Pro, by a good margin. It found one more target bug, and didn’t invent as many false positives. But, the cost of Gemini 3.5 Flash is closer to large models than it is to previous Gemini Flash models, which makes it a moot point. There are seemingly better models (much) cheaper.
The cheap Chinese models kick ass. MiMo and DeepSeek are directly competitive with Opus 4.8 and GPT 5.5 at roughly an order of magnitude lower price. There have been accusations of “benchmaxxing” with the Chinese models, but I don’t think there’s any reasonable way for the models to already be tuned for these very recently disclosed bugs. I think they’re genuinely becoming competitive with the frontier from Anthropic and OpenAI. If you’re in a hurry, DeepSeek was the fastest, on average, while finding 4/9 bugs. And, if you’re cheap, MiMo found bugs as well as any model for the lowest price.
Mistral Medium completely failed. I haven’t dug in to find out why. It completed the task according to instructions, and didn’t give an error, it just returned no results. I assume it’s a safety thing without explicitly saying so (as agy does), rather than total incompetence for the task. I thought it would be an interesting model to include, since many Europeans are (reasonably) hesitant to hand over their data to American or Chinese AI companies, and Mistral is a leading EU AI company. Just not for security, currently.
Laguna M.1 also failed to find any of the known vulnerabilities but did report a different bug judged to be real by Opus, so I don’t think it’s in the same category as Mistral, which seemingly didn’t even try. I think Laguna just isn’t good at this task.
I don’t have any reason to ever use Haiku or Sonnet, at least for security audits. They’re not great at anything and they’re not really all that cheap. Haiku, in particular, made up for its low price by burning tokens at a prodigious rate. 1.6M per case, on average, more than twice the next contender (self-hosted Qwen 3.6 at 733k). MiMo and DeepSeek are both very cheap and very good, might as well use those if you want a cheap LLM.
June 7 edit: Check out the MoE Gemma 4 result and the note about the “off baseline” runs. Crazy, right? I’m currently running a round of benchmarks of just Gemma 4 (dense and MoE) to see if it replicates or if it’s a total fluke that it found a really hard bug. I’ll note that the MoE gets “lost” far more often than any other model. It gets into a loop, looking at the same bunch of lines (sometimes the right set of lines) over and over until it times out. That was the failure mode of the two cases that got repeated, and it’s the failure mode I’m seeing on about 30% of cases in the new benchmark of just Gemma models. So, even though it’s the smallest model to find 4 of 9 bugs in this corpus, it’s also the most likely to waste a lot of your time if you tried to use it interactively.
Conclusions
I don’t know. Will it Mythos? Do regular folk have access to the tools needed to find these hard bugs? I’d say this benchmark answers with a resounding, “Maybe.”
Mythos maybe really is better than the other current models at finding security bugs, as it found four bugs that no model in this experiment found. But, I’ll keep testing. It’s possible prompt or tooling or harness changes can enable better results from the current crop of publicly available models.
And, the fact that Opus was able to see and understand all of these bugs when given sufficient clues makes me think it probably is possible for the best current public models to find these bugs, given sufficient time, opportunity, and tools. This benchmark is using a pretty naive harness and prompt.
←Qwen 3.6 Quantization DegradationAn Interesting Thing About Granite 4.1→