Today, we're releasing Mistral OCR 4, featuring bounding boxes, block classification, and inline confidence scores alongside extracted text. The model supports 170 languages across 10 language groups, runs in a single container for fully self-hosted deployments, and serves as an ingestion component for enterprise search, RAG, and domain-specific retrieval pipelines. OCR 4 is a small, focused model, and this post covers what's new, how it performs on public and internal benchmarks, the known limitations of those benchmarks, and guidance on when to use the model API versus Document AI.
Highlights
Breakthrough performance. Independent annotators prefer OCR 4 over every leading OCR and document-AI system tested, with win rates averaging 72%, alongside the top overall score on OlmOCRBench (85.20). See Benchmarks below for methodology and known scoring limitations.
Segmentation, not just text. Alongside the extracted text, OCR 4 returns bounding boxes, typed-block classification (titles, tables, equations, signatures, and more), and inline confidence scores. Bounding boxes, our most-requested capability, localize text for in-context highlighting and reliable data pipelines. At the same time, block types and confidence scores drive source-grounded citations, redactions, and human-in-the-loop verification.
Integrated with Mistral Search Toolkit (public preview). OCR 4 is an ingestion component of Search Toolkit, Mistral's open-source, composable search framework, announced at the AI Now Summit. Its structured output supplies citation-ready inputs to the toolkit's ingestion, retrieval, and evaluation workflow for RAG and enterprise search.
Multilingual coverage. Support for 170 languages across 10 language groups, with measurable gains on rare and low-resource languages where several competing systems degrade.
Run on your own infrastructure. OCR 4 is compact enough to deploy on a single container, keeping document data in your environment for residency, sovereignty, and compliance, while supporting cost-efficient, high-throughput batch processing. Self-managed deployment is available to enterprise customers.
Overview
Mistral OCR 4 extracts and structures content from a wide range of documents. Where previous generations focused on converting a page into clean text and tables, OCR 4 returns a structured representation of the document. Each block is localized with a bounding box, classified by type, and inline confidence scores are generated per-page and per-word. Downstream systems, therefore, have access not only to what the document says but also to where each element sits, what role it plays, and how confident the model is in each region.
This structure supports several downstream workloads:
Semantic chunking for RAG: clean, classified blocks become better retrieval units.
Structural primitives for agents: agents move from reading documents to acting on them (form filling, invoice processing, compliance checks).
Structured content for connectors: consistent, typed output for ingestion and indexing pipelines.
OCR 4 accepts common enterprise formats, including PDF, DOC, PPT, and OpenDocument, and supports 170 languages across 10 language groups, including rare and low-resource languages that many systems handle poorly. As a compact model deployable in a single container, it is suited to both cost-sensitive and high-volume deployments. It can run fully self-hosted, allowing organizations with data-sovereignty requirements to keep document data within their own infrastructure.
Developers integrate the model via API, and teams can use Document AI in Mistral Studio for an application-level, no-code path to the same engine. Mistral OCR 4 through the API is priced at $4 per 1,000 pages, with a 50% Batch-API discount, reducing the cost to $2 per 1,000 pages. Document AI is priced at $5 per 1,000 pages.
Benchmarks
“We benchmarked Mistral OCR 4 against the leading agentic document parsers across a chart and figure dense financial QA dataset and reached equivalent accuracy at roughly 8x lower cost and 17x lower latency. For production use cases at scale, that delta compounds fast."
- Aidan Donohue, AI Engineer, Rogo
To evaluate OCR 4, we compared it against leading AI-native OCR models, frontier general-purpose models, enterprise document services, and our own Mistral OCR 3.
Human Preference Evaluations
Automated benchmarks carry the scoring artifacts described above, so we complemented them with a head-to-head human evaluation on documents chosen to reflect real usage. We assembled 600+ documents across 12+ languages, sourced from third-party vendors to represent real industry use cases, and asked independent annotators to blindly rank each competitor's output against OCR 4's, document by document.
Annotators preferred OCR 4 in the majority of documents across all systems tested. Because these are human judgments on realistic documents rather than string comparisons against fixed references, they sidestep much of the annotation and formatting noise that affects automated scores.
_15hPxB.webp?dpl=6a3ac9c3b6e9673ed87c7230)
Overall Performance
“Mistral OCR is roughly 4x faster per page than our incumbent provider, an impressive result for the high-volume docketing workflows where speed is critical to managing our customers' IP timelines.”
- Ivan Mihailov, AI engineer, Anaqua
In addition to placing first in our human preferences, OCR 4 achieves the top overall score amongst the models we tested on the public OlmOCRBench (85.20) and leads our internal Crawl Multilingual evaluation (.98), ahead of both AI-native and enterprise solutions.
_ZDpUIm.webp?dpl=6a3ac9c3b6e9673ed87c7230)
On OmniDocBench, OCR 4 achieves a score of 93.07. We report this figure with a caveat: both OlmOCRBench and OmniDocBench have known limitations in how they score certain outputs, and a single aggregate number can both understate and overstate real-world performance.
When we audited the mismatches behind our scores, most were not model errors but artifacts of how the benchmarks compare output. The recurring categories:
Ground-truth errors. Some reference annotations are themselves incorrect: missing or extra text, transcriptions of redacted regions, or typos (for example, a cited author's name misspelled in the reference but read correctly by the model from the page). The output matches the source document, yet it is still marked wrong.
Equivalent math notation. Different LaTeX that renders identically is counted as a mismatch, The rendered equation is correct; the string comparison is not.
Equation segmentation. Whether an expression is emitted as a single equation or split into several inline fragments affects the match, even when the rendered content is identical, because the matcher cannot align the pieces.
Multi-column reading order. Words split across a column boundary (for example, "certifi-cates") and column-ordering assumptions cause correct extractions to be scored as reading-order failures.
Block-type attribution. The benchmark does not expect headers/footers in the output. To resolve this we strip headers footers from our output before scoring. But the test then checks for a string that also happens to be the title of the page which should actually be present and flags it incorrectly.
These artifacts concentrate in mathematical, scientific, and multi-column documents, and they more often penalize correct output than reward incorrect output. We therefore treat the aggregate score as directional rather than definitive.
We report these numbers to indicate where OCR 4 stands, and recommend evaluating on your own documents.
Performance Details
Crawl Multilingual breakdown. On our internal multilingual evaluation, OCR 4 leads across all eight language groups — English, Western Europe, Eastern Europe, Middle Eastern, Chinese, East Asian, Southeast Asian, and rare languages. The gap is widest for rare and low-resource languages, where many competing systems degrade sharply, while OCR 4 maintains high accuracy.
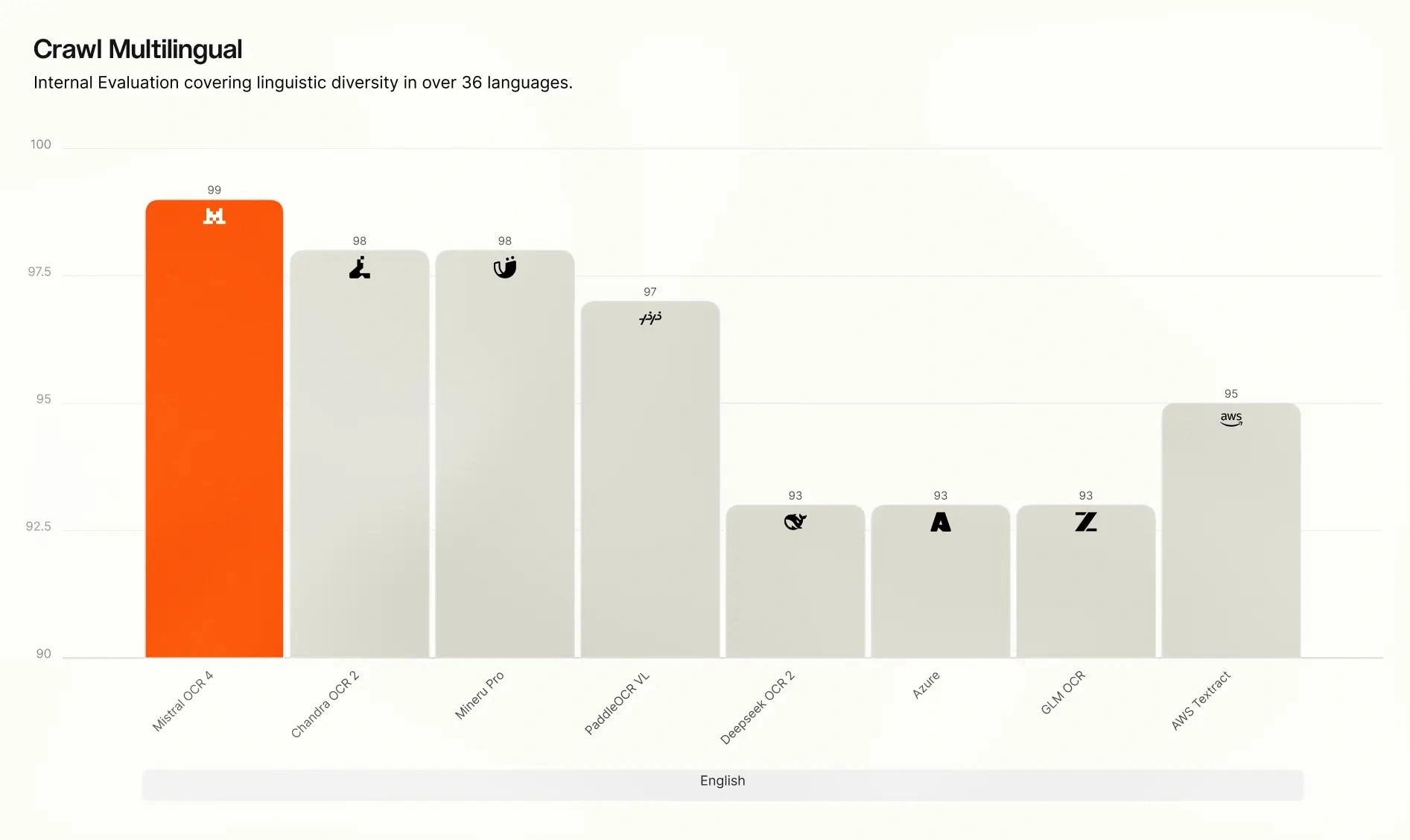
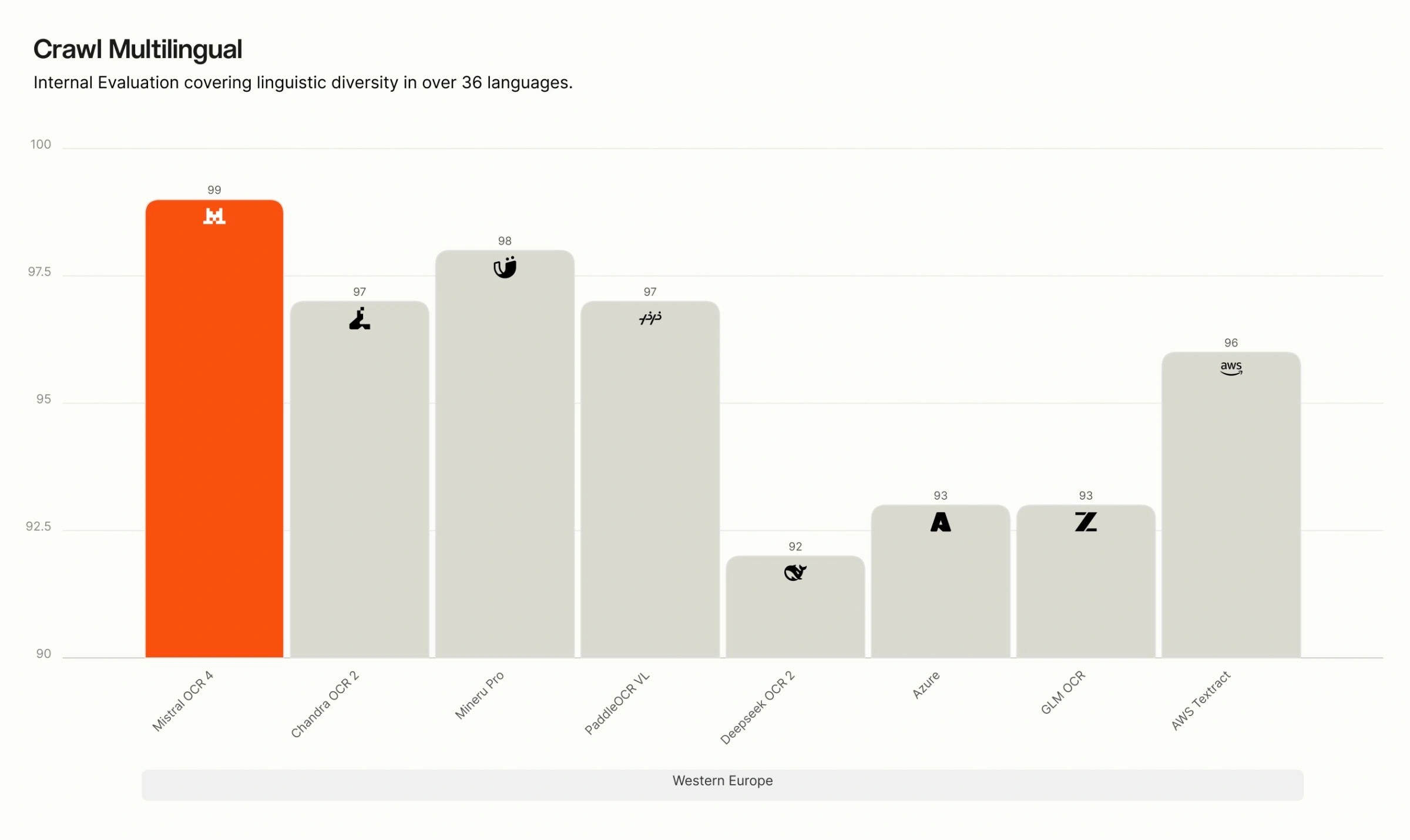
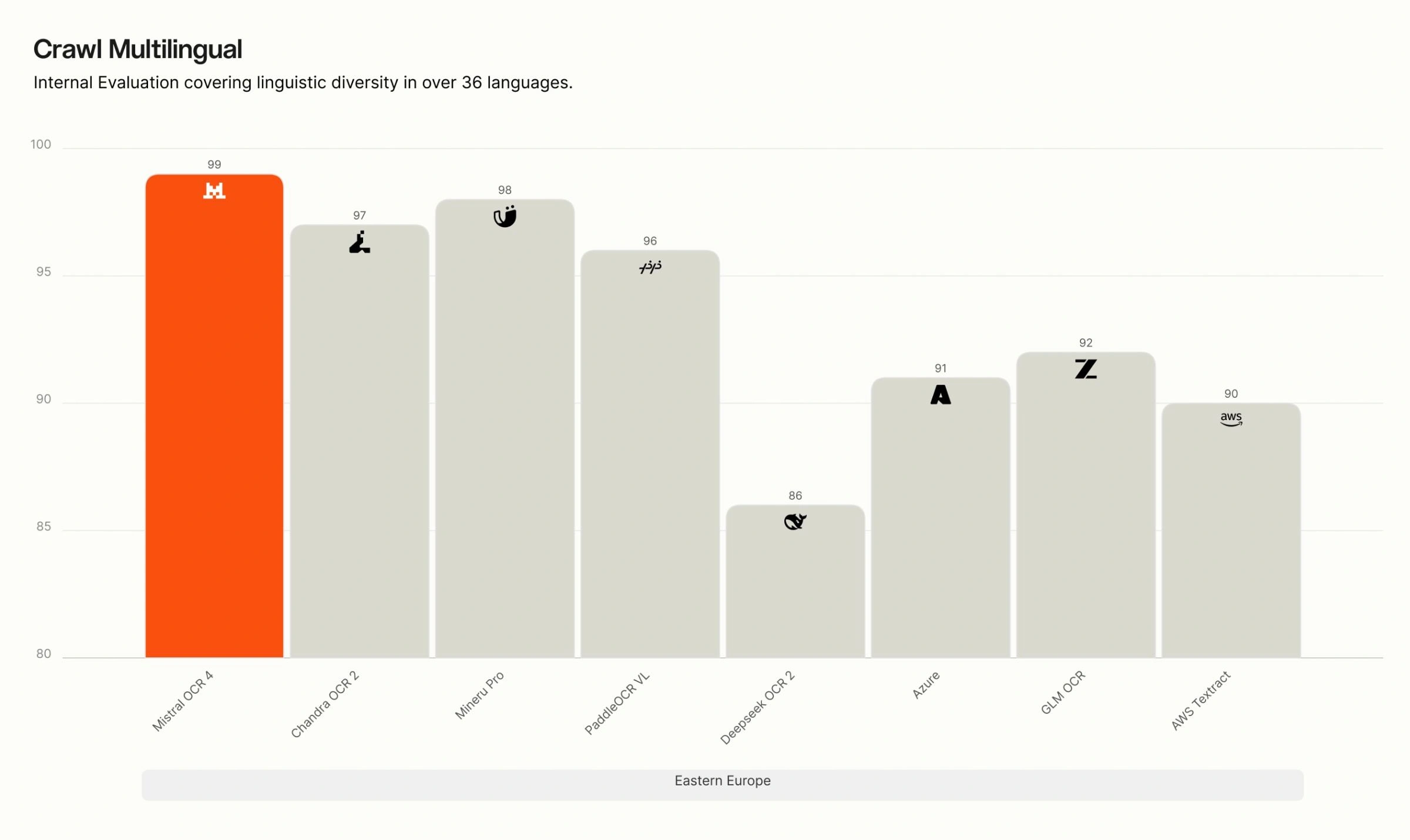
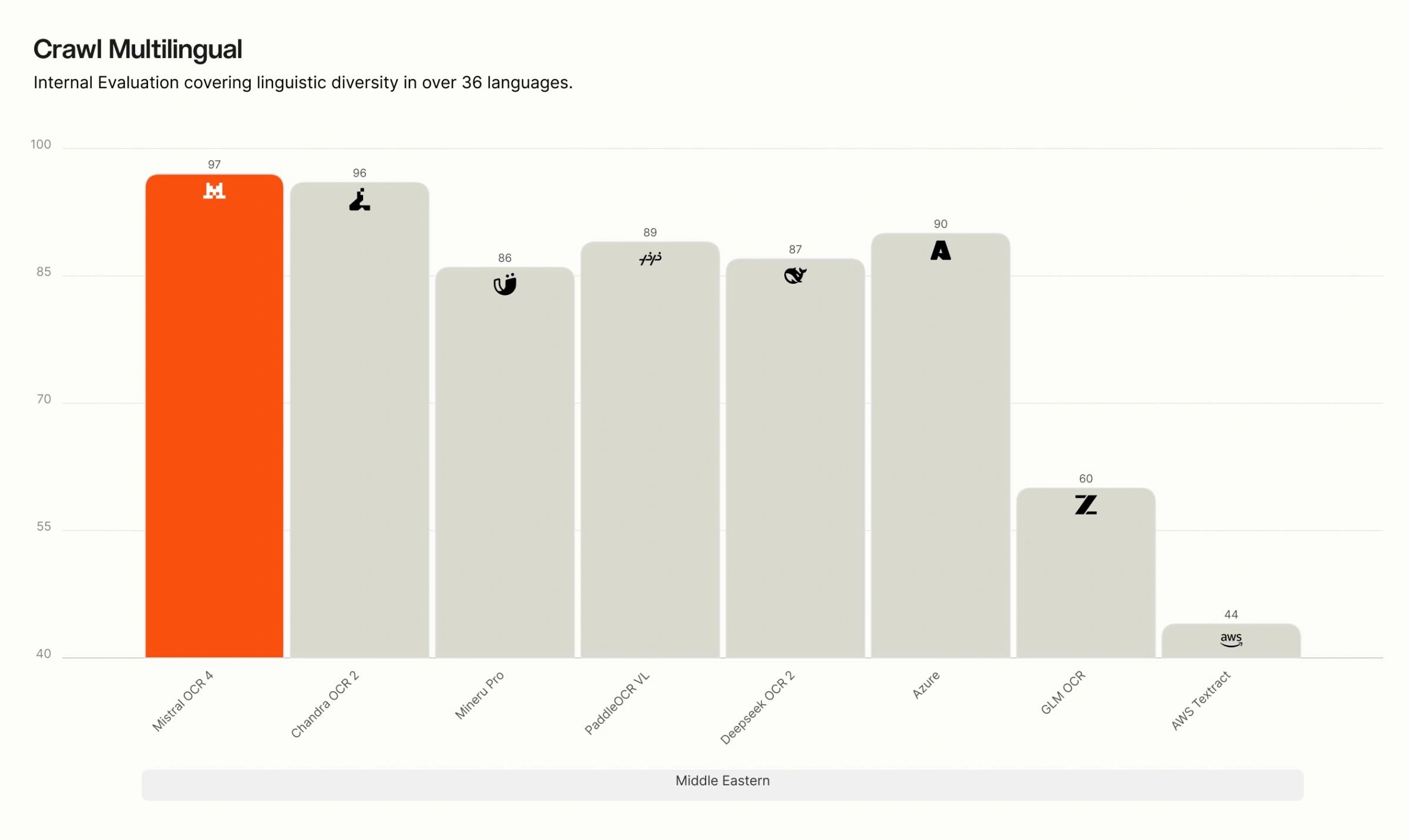
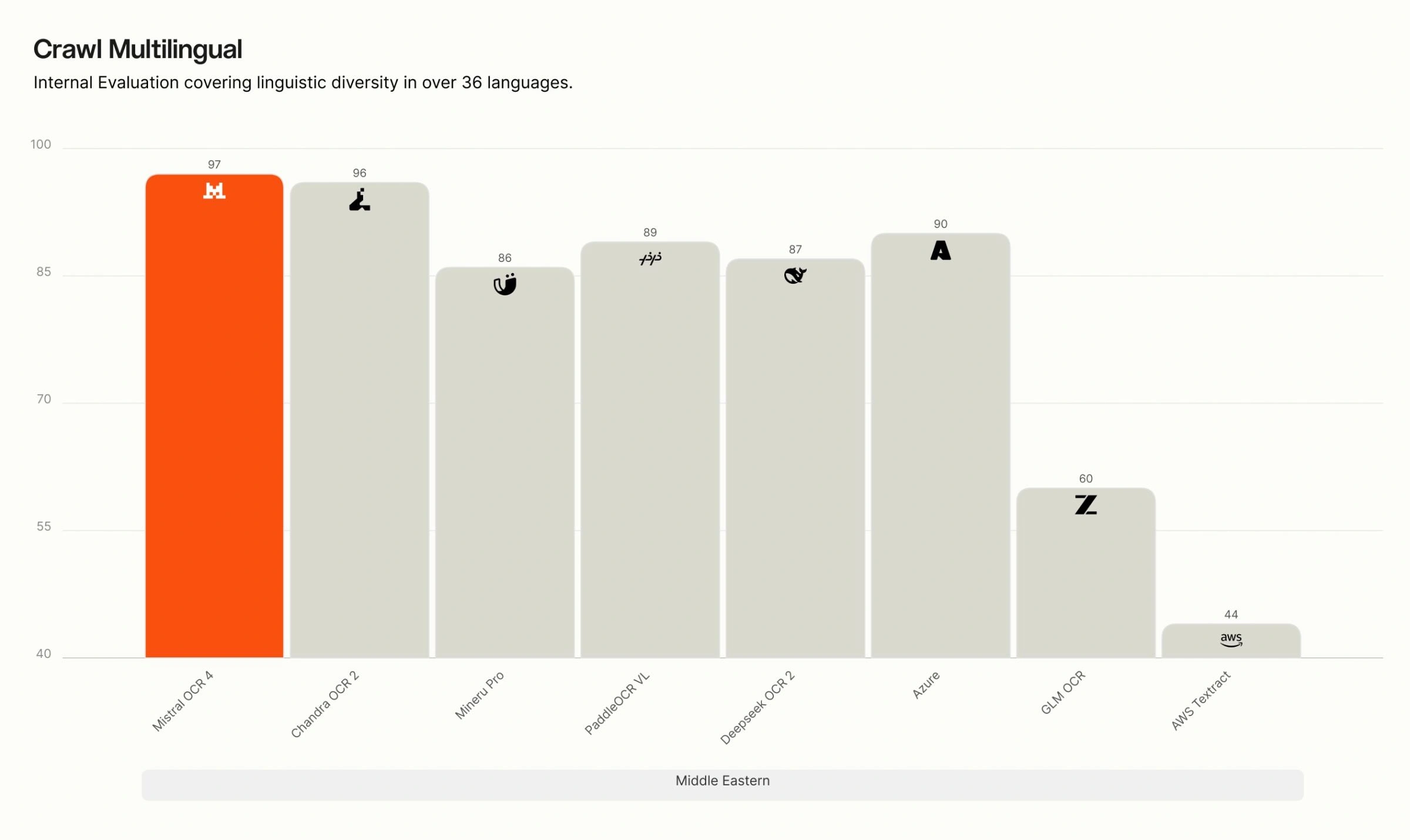
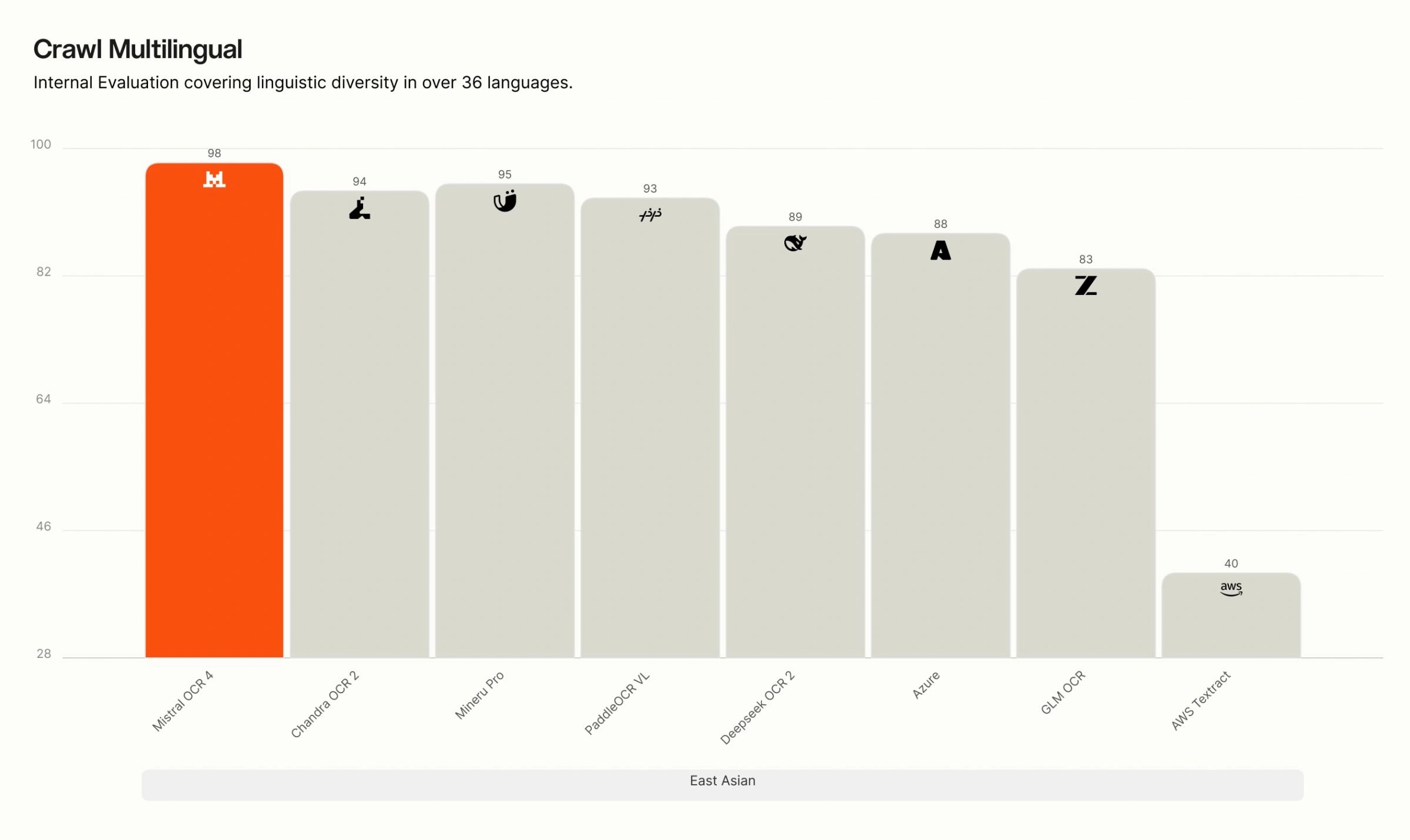
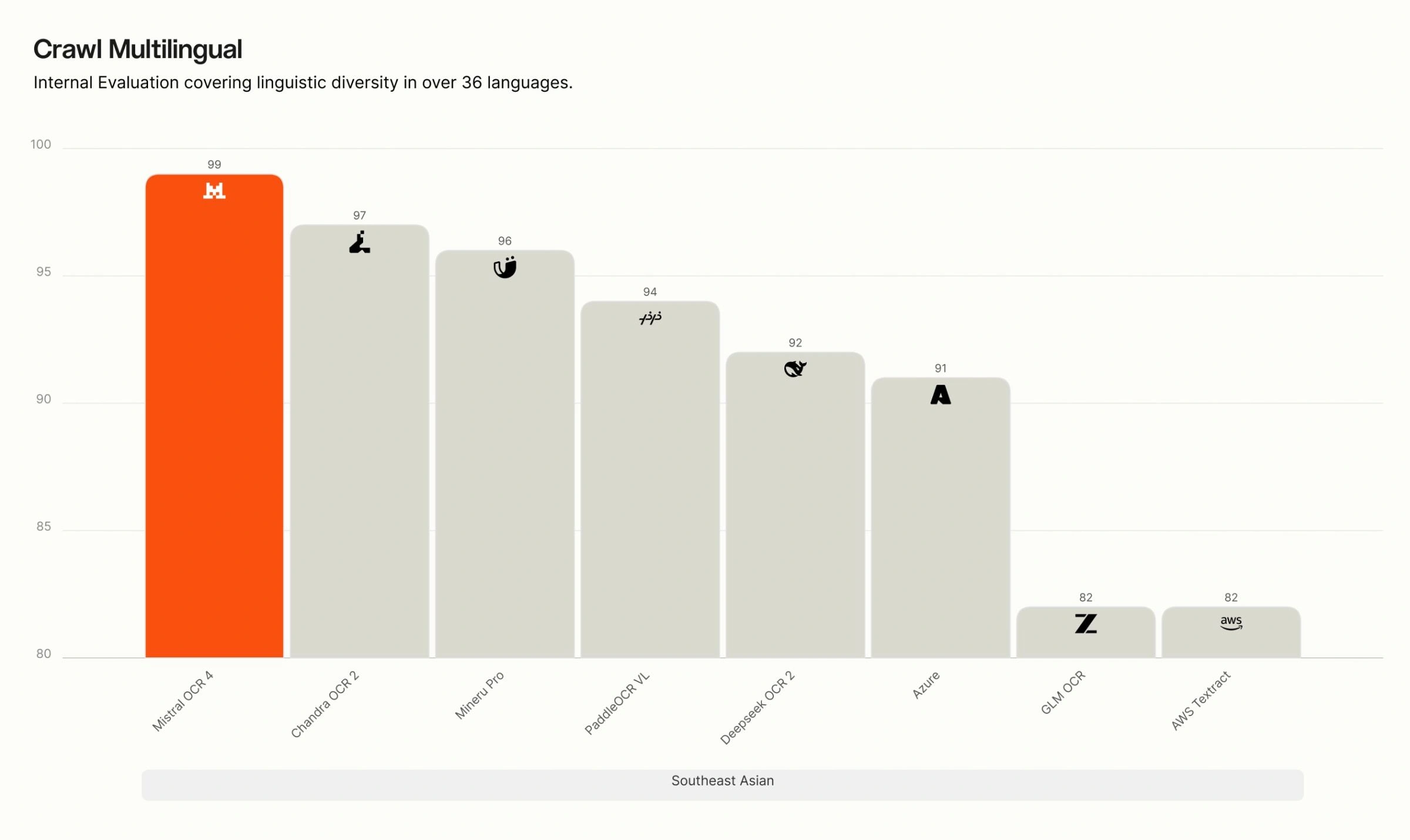
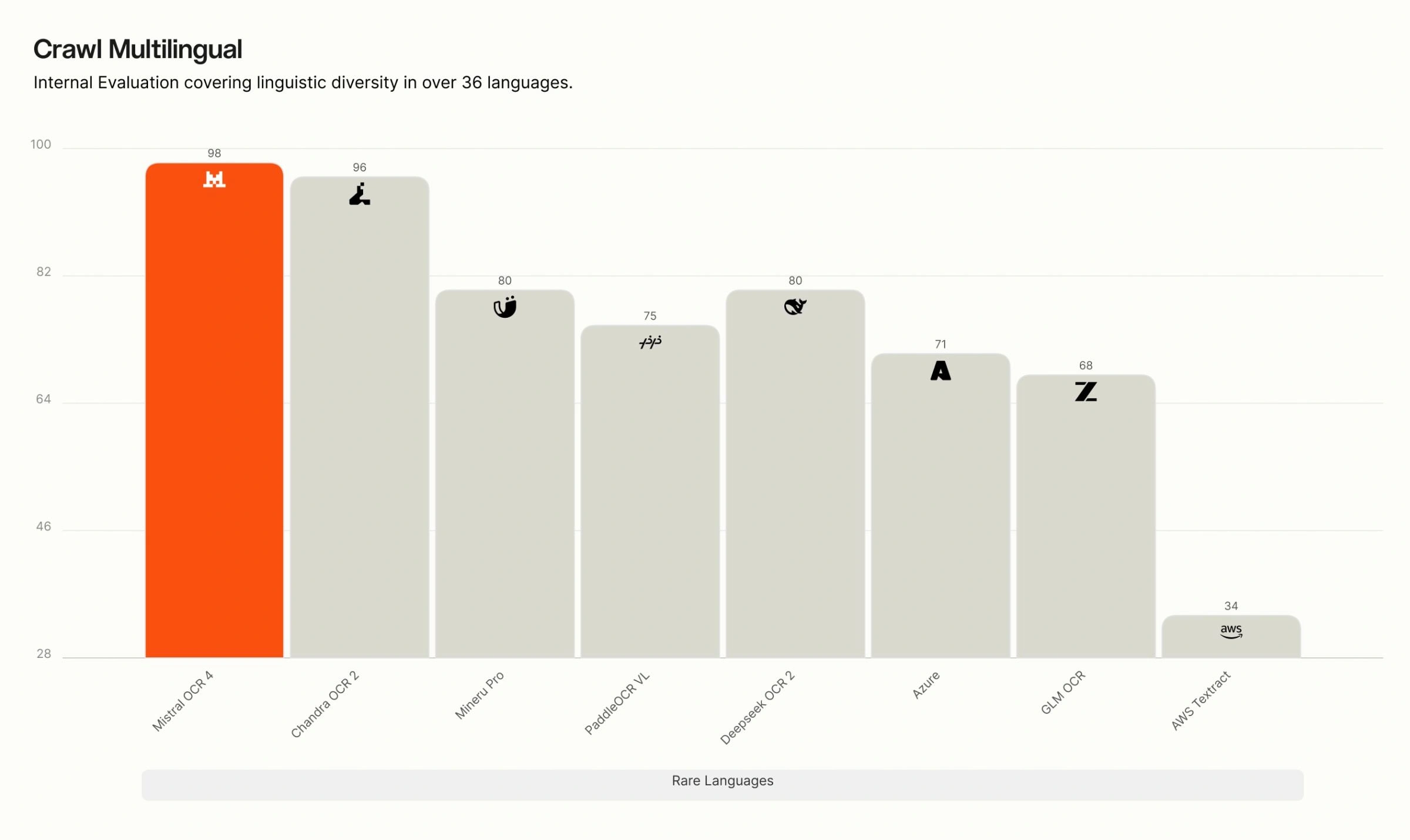
Recommended use cases
OCR 4 supports both high-volume pipelines and interactive document workflows, including:
Document parsing and extraction: complex, multilingual documents.
Retrieval-Augmented Generation (RAG): structured, classified, citation-ready content for semantic chunking and source-grounded answers. With Search Toolkit, OCR 4 output can be fed directly into retrieval pipelines.
Agentic workflows: providing agents with the structural primitives to complete tasks such as form filling, invoice processing, and compliance checks, especially in legal, financial services, and healthcare.
Structured data pipelines using confidence scores to enable efficient use of human verifiers: form/invoice extraction, redactions, and compliance-driven processes.
Enterprise search and knowledge bases: OCR as a data-source component for custom ingestion and entity extraction.
Early users are applying OCR 4 to turn invoices into structured fields, digitize company archives, extract clean text from technical and scientific reports, and power enterprise search.
A note on out-of-scope use. OCR 4 is a document-understanding model, not a decision-maker. It is not intended for medical diagnosis, legal advice or judgment, high-stakes financial decisions, safety-critical systems, real-time/latency-sensitive processing, or non-document inputs (raw audio, video, etc.).
OCR 4 API: Understanding Your Options
Mistral's OCR 4 is available through a single API endpoint. Every request runs the same underlying OCR model and always returns extracted content, bounding boxes, block types, confidence scores, and markdown-structured text. What varies is how much you layer on top.
Use OCR 4 in pure extraction mode when you want to:
Embed fast, accurate document extraction directly into your application, agent, or data pipeline.
Work directly with the raw response, bounding boxes, block types, and confidence scores to drive custom downstream logic.
Run high-volume or batch ingestion with full control over throughput and cost via the Batch API.
Self-host for strict data-privacy, sovereignty, or compliance requirements.
Activate Document AI capabilities (same endpoint, additional parameters) when you want to:
Return structured JSON in a schema you define — pass a JSON schema alongside your document, and the OCR output is fed to
mistral-small-2603to generate content shaped to your spec.Annotate detected images with structured JSON by passing an image annotation schema, triggering an additional vision-language model call per image.
Use a custom prompt alongside a JSON schema to guide how the extracted content of the full document is interpreted or summarized.
Enable business users, solutions teams, or pilots to produce structured results without writing downstream parsing logic.
The practical decision rule: if you need raw extracted content, use OCR 4 as-is. If you need the output reshaped into a structured format, annotated with domain-specific fields, or processed with a custom instruction, add the Document AI parameters to the same call. You always get the OCR result regardless; Document AI simply adds structured layers on top of it.
Now available
“The availability of Mistral Document AI with OCR 4 in Microsoft Foundry marks an important milestone in our partnership. Together, we’re enabling customers to bring advanced, structured document understanding directly into their AI workflows, combining Mistral’s innovation with Microsoft’s enterprise platform to deliver scalable, trusted solutions for real-world business needs.”
-Kimmi Grewal, VP, AI Ecosystem Partnerships, Microsoft
Both Mistral OCRv4 and Document AI (powered by OCRv4) are available via API through Mistral Studio, Amazon SageMaker, Microsoft Foundry, and coming soon Snowflake Parse Document. For organizations with stringent data-privacy requirements, OCR 4 also offers a self-hosting option so sensitive information stays within your own infrastructure. To explore self-deployment, let us know.
Get started
We offer a few ways to get started and learn more quickly.
Try OCR 4. The new Getting Started with OCR 4 Cookbook walks through a first extraction, working with bounding boxes, and block classification.
OCR 4 webinar. We'll cover what's new in OCR 4 with demos and Q&A on July 7th at 6:00 PM CET. Register for the OCR4 in Production webinar.
Contact Sales for more information.

OCR 4
Premier
The world's best document extraction and understanding model.
OCR
Multimodal
Text-to-text
OCR
$4 / 1000 pages
Batch-API
$2 / 1000 pages
Document AI
$5 / 1000 pages
OCR in production.
Learn about the new features in the OCR4 release and how can they be used inside workflows and search toolkit to get production grade indexing.