Generally speaking, if you spend tens of thousands of dollars on something, you want to see something come out on the other end. Some return on investment.
O sure, not always. I’ve previously said that selling to consumers is sorta funny because they love spending money on things that waste time or actively cause pain. This is part of why the gambling apps are so popular these days. Why yes, I’d love to spend $100 on betting that Wemby scores a 3 pointer while doing a handstand and singing the national anthem in French.1
But for businesses? I’ve basically never heard a business leader say that they were going to set a bunch of money on fire because it made them feel good, at least not the same way a whale will spend thousands on Genshin Impact gatcha pulls. Like, imagine if some serious business leader, like, idk, Mark Zuckerberg, decided to announce that Meta was going to burn money. He could do that. He’s got the voting shares. But it would be a bit silly, wouldn’t it? I generally think if you’ve gotten to the point where you’re running really big really important companies, you mostly aren’t doing things for kicks, with one big exception.
If you haven’t heard, tokenmaxxing is (was?) a phenomenon where executives accidentally encouraged their employees to burn a bunch of tokens on useless tasks. The canonical example of this is, by complete coincidence, Meta, which has been thoroughly skewered for tying performance evaluations to the amount of token usage per person. Obviously, obviously this was going to lead to people just burning tokens on nothing. One of my friends at Meta reported that they literally would just have two agents talking to each other throughout the day to get her token numbers up.

This was such an obvious outcome that many people rounded this off as “these business leaders are really dumb because they decided to burn a bunch of money on tokens without expecting any return.”
I understand why that’s a tempting take, because that is kinda sorta what the public face of a lot of this was. But I’m going to do my favorite thing in the world, which is be a bit contrarian. It wasn’t that “executives accidentally encouraged their employees to burn a bunch of tokens on useless tasks.” Rather, “executives purposely encouraged their employees to burn a bunch of tokens on useless tasks.”
I work with a lot of teams on figuring out how to use AI effectively. A few months ago, there were a lot of people who were extremely resistant to using AI tools at all. Senior people, people that had a lot of respect in the organization. It was very difficult to convince these folks to use the tools. And when you did, they would often accidentally (or purposely?) use the tools in a way that would obviously lead to weird or bad outcomes.2
Not just the seniors!
One way to think about the top down tokenmaxxing policies is that this was a technique by executives to break through. Yes, it was obviously a blunt force policy, but sometimes you need blunt force to break through a wall.
Of course, that was the situation a few months ago, when there were still holdouts. It’s now a few months later, and the tokenmaxxing policies had their intended outcome: everyone is using AI to code, at least a little bit. Most teams haven’t yet figured out how to build their own Ramp Inspect or Stripe Minions (if that’s you, reach out — we can help!) but basically everyone is at least using cursor in the side bar. Which, of course, means that token spend has gone way up. Unfortunately, but probably not unexpectedly, the increase in token spend has lined up with both OpenAI and Anthropic trying to go public. Both companies have limited the amount of juice their subscriptions provide while jacking up their API pricing. Token subsidies are increasingly vanishing.
So now the incentives are mostly gone and the cost is way up and, of course, teams are starting to roll back their unlimited-token-spend policies. All of this to say, tokenmaxxing is dead.
Except…maybe not.
The promise of AI tools generally is that you can have them run without human supervision to accomplish really hard and really tedious tasks that still need to be done. The big code migration, doing research on all your competitors every morning, keeping up with the stream of inbound and outbound — these are all things that people mostly hate doing and want AI to do.
Up until recently, though, you couldn’t reliably have an AI run for long periods of time. If you tried, you would notice that small errors introduced by the models (including hallucinations) would take on a life of their own and eventually become irreversibly embedded into the project. In the business we called this “compounding error.” It not only required a fair bit of human supervision, it also kept token costs low because there was little benefit in running agents 24/7 to begin with. Like, what’s the point of running a little demon in your computer over night if the thing is just going to tear up all your hard work? If spending more tokens results in worse work, you obviously aren’t going to spend more tokens!
That’s no longer true. We’ve entered a different regime, where spending more tokens generally results in better results. We call this “compounding correctness” — the more tokens you spend on getting a task correct, the more likely you’ll get a good outcome. We talked about this a bit at the last in person Agentics meetup:
Compounding correctness flips the calculus. If more token spend leads to better outcomes, then you’re going to want to spend a lot of time running tokens. Which sure as hell sounds like tokenmaxxing to me! The original incentives to tokenmax are gone, but eventually folks will realize that a new and more powerful incentive has take its place.
We’ve already seen some of this take place in the cyber security world:
Last week we learned about Anthropic’s Mythos, a new LLM so “strikingly capable at computer security tasks” that Anthropic didn’t release it publicly. Instead, only critical software makers have been granted access, providing them time to harden their systems.
…
This chart suggests an interesting security economy: to harden a system we need to spend more tokens discovering exploits than attackers spend exploiting them.
AISI budgeted 100M tokens for each attempt. That’s $12,500 per Mythos attempt, $125k for all ten runs. Worryingly, none of the models given a 100M budget showed signs of diminishing returns. “Models continue making progress with increased token budgets across the token budgets tested,” AISI notes.
If Mythos continues to find exploits so long as you keep throwing money at it, security is reduced to a brutally simple equation: to harden a system you need to spend more tokens discovering exploits than attackers will spend exploiting them.
You don’t get points for being clever. You win by paying more. It is a system that echoes cryptocurrency’s proof of work system, where success is tied to raw computational work. It’s a low temperature lottery: buy the tokens, maybe you find an exploit. Hopefully you keep trying longer than your attackers.
Fable is, tragically, gone now. But the underlying concept here still remains.
This is also in part why people are suddenly so excited about ‘loops.’ Boris Cherny, the creator of Claude Code, got up on stage and said ‘loops’ and everyone freaked out. The basic idea behind loops is that you run an agent until it reaches the end of its turn, and then when it finishes you simply restart the same prompt. With a bit of cleverness you can take a pretty heavy specification and automatically have the agent split it into parts and solve it over time. No human supervision required.
Is this some new thing? No, not really. The loop concept has been around since literally last July. It used to be called a “Ralph Wiggum loop,” but as the industry has matured so has our sense of humor and the ‘Ralph Wiggum’ part was dropped.

There were ways to get loops to work, but it was hard. You had to think a lot about how to prompt the agent, which in turn required a pretty deep familiarity with how these things work. Now, though, it’s easy. Compounding correctness makes it easy. You can basically prompt the LLM however you want and to a first approximation, it will do better every iteration of the loop.
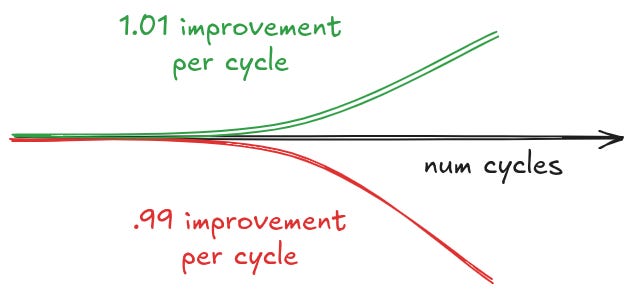
So is tokenmaxxing really dead? Maybe temporarily, but long term I don’t think so. Teams that are at the cutting edge are currently building or have built the infrastructure necessary to run agents 24/7. It’s only a matter of time before the bigcos realize that the cost benefit has shifted again.
The real winners here are the open model platforms. Tokenmaxxing the top labs will never stand up to any amount of CFO scrutiny. As open models get better, it will become more popular to simply run those in a loop. That was the core thesis of Rohan’s talk above. If Claude gives you 1.1x improvement per iteration, and GLM 5.2 gives you 1.05 improvement per iteration but costs ~5x less, you can just run the second loop 5x more times and it will be better.
The last thing I want to mention here is that some of the ridiculous token spend is downstream of a serious misunderstanding of the best way to use these tools. Before coding agents really took off (thanks in large part to much better harnesses like Claude Code), lots of people were making their own custom agents. And that was legitimate work! You had to think about this stuff as if it was…well, software. There was an art to figuring out the tools and the prompts but the core of it was still just software, even if it was supported by ‘AI native’ frameworks like Pydantic or Langchain.
You can’t fit a square peg into a round hole. Executives across the board saw this style of building agents, went “o, this is just a more flexible zapier workflow,” and proceeded to demand data processing pipelines that could do one-off tasks that were ‘agentic’ instead of building those same pipelines in good ol’ deterministic code. ‘I need to do data labeling, so I will build a data labeling agent’, that sort of thing.
Now, relying on an agent to do some of this stuff is already going to be significantly more expensive than just doing a workflow automation. But the bigger issue is the accuracy: none of these ‘agents’ ever really took off, because they were never as correct as a deterministic pipeline would be.
If you’re committed to using agents but want to reduce the cost of hallucinations and things, what do you do? Why, you build another agent! A ‘quality checking’ agent, or something like that. And what if that agent gives you errors? Well you’ll just build another! And now you have 3x the token cost, enjoy!
The story of tokenmaxxing is, again, one of RoI. That story didn’t just play out at the bigtechcos. It also happened at a less advanced scale at companies all over the country — companies who poured billions into random agent pipelines built by one off consultants that unfortunately never really quite worked all that well.
Notice that these are actually two different kinds of tokenmaxxing.
The first kind is ‘spend a lot of money on tokens for your developers‘. Here, devs are using tools like Claude Code and figuring out how to run things in loops and using a lot of tokens to do it. Ostensibly this is a good use of money because it’s making the engineers themselves more productive.
The second is ‘spend a lot of money on tokens for your pipelines‘. Here, devs are still writing code by hand! They are using that code to create one-off agents to do very specific tasks often in a non-deterministic and brittle way, and it’s those agents that guzzle up all the tokens. This is only a good use of money if the pipelines work, which they don’t.
But here, too, we are seeing a shift. Increasingly, these sorts of one-off pipeline-based tools are better done by generalist platforms that are skinned for the specific task, than an “agent” specially designed to do that one task. There’s some market arbitrage here. Some buyers haven’t realized that generalist agents have gotten really good, so they will go to consultants asking to ‘build me an agent’, and the consultant essentially writes a skill file and says “that will be $2m please.”
Luckily, this too shall pass. Generalist model platforms are obviously the future for anyone who has used them (and if you haven’t, again, reach out!) And that, again, will lead to another rise in tokenmaxxing behavior in this part of the market.
The natural end state of all of this is the ‘software factory’ or, even further, the ‘dark factory’ — a codebase that pumps out code, reviews code, fixes bugs, writes tests, and so on without any human supervision. The human simply puts in a spec and out comes an application. The folks over at StrongDM have taken this to the furthest extreme, arguing that engineers should aim to spend $1000 in tokens per day. This is almost certainly hype, part of a long trend of saying egregious things to get coverage and buzz. We have a software factory, and we spend like $600 per month. But the hype and buzz comes about because, even though it is currently ridiculous to spend the price of a senior google engineer in tokens per engineer, there is a kernel of truth to this. The incentive to spend ludicrous amounts of money on tokens are there, latent, waiting for diffusion.
What’s old is new again and what’s dead may never die. Tokenmaxxing is dead, but we haven’t seen the last of tokenmaxxing just yet.
GPT 5.6 is out, kinda sorta. From the announcement:
We’re beginning a limited preview of the GPT‑5.6 series: Sol, our flagship model; Terra, a balanced model for everyday work; and Luna, a fast and affordable model. Terra has competitive performance to GPT‑5.5 while being 2x cheaper and Luna brings strong capability at our lowest cost.
…
We believe in broad access, and we plan to make GPT‑5.6 Sol, Terra, and Luna generally available in the coming weeks. As part of our ongoing engagement with the U.S. government, we previewed our plans and the models’ capabilities ahead of today’s launch. At their request, we are starting with a limited preview for a small group of trusted partners whose participation has been shared with the government, before releasing more broadly.
…
We don’t believe this kind of government access process should become the long-term default. It keeps the best tools from users, developers, enterprises, cyber defenders, and global partners who need them. We are taking this short-term step because we believe it is the strongest path to broader availability in the coming weeks, while we work with the Administration to develop the cyber Executive Order framework and a repeatable process for future model releases.
Washington Post was even more aggressive in its analysis:
U.S. government will decide who gets to use latest upgrade to ChatGPT
The Trump administration came to power preaching a laissez-faire approach to AI but has lately increased oversight of the industry.
Reading between the lines, it looks like we are getting more government regulation of AI companies, but unfortunately the process as it currently stands is completely opaque. Reactions are mixed. On the one hand it’s great that the administration’s previous attacks on Anthropic are also being applied to their competition. On the other hand, it seems like the process is totally opaque, and now the government is unilaterally picking winners and losers not just among AI companies, but among every other industry where AI may matter (i.e. all of them). The companies who get to use OpenAI’s tooling (and Mythos, see below) are currently unknown. It would be very concerning / disappointing if we find out that it is exclusively companies with ties to this administration.
Related: Mythos is back on the table, at least sort of. From Semafor:
US releases powerful Anthropic model Mythos to some US companies
The US government Friday lifted its block on Anthropic’s powerful Claude Mythos 5 AI model, allowing the company to release it to more than 100 US institutions, including major companies and government agencies.
The decision, in a letter sent Friday afternoon to Anthropic, is a major de-escalation in the confrontation between the Trump Administration and one of the world’s most valuable private companies. Two weeks ago the administration imposed export controls on Mythos, leading to a shut down of the model and its cousin Fable 5 after warnings from Amazon and other companies that they could be “jailbroken” for malicious purposes.
The letter is silent on Fable 5, a weaker version of Mythos that was briefly the most powerful AI model widely available to consumers. People close to the talks said they are moving toward releasing Fable as well, though that timeline is unclear.
“I have determined that appropriate safeguards are in place to permit certain trusted partners to access the Claude Mythos 5 Model,” Commerce Secretary Howard Lutnick wrote to Anthropic’s chief compute officer Tom Brown Friday, citing “significant progress” in the intense, daily talks between the government and the company since the block went into effect.
Again, picking winners and losers.
While we are talking about OpenAI’s launch, one thing that was buried in the announcement was that the tooling would be available on Cerebras’s high-speed inference machines at ~750 tokens per second. This is quite fast. Right now we are in a regime where it makes sense to treat AI tools as async operators that can go off and do tasks without supervision. But that is mostly downstream of the fact that AI is slow and it takes a while to do things. If AI was really really fast you would plausibly go back towards a more synchronous model of operating. For an idea of what this may look like, check out https://chatjimmy.ai/. It’s just a demo, but wow, what a demo.
Open models like GLM 5.2 have gotten pretty damn good. They aren’t SotA, but they are much cheaper than their frontier equivalents. Right now, GLM 5.2 is ~$1.4 per million tokens and ~$4 per million output tokens. By contrast, the entire Opus 4.X series is $5 per million input and a whopping $25 per million output. The only model in the Anthropic suite that even comes close to GLM 5.2 in terms of pricing is Haiku 4.5, at $1 / million input and $5 / million output. But GLM 5.2 blows Haiku out of the water, and in some cases is even stronger than GPT 5.5 on benchmarks. If I were the big labs, I’d be pretty concerned about this. And if I were basically any consumer on the market, I would be doing everything I can to avoid provider lock in by adopting tools that are able to sit on top of all of the major players.
OpenAI unveiled an in house chip for inference.
On Wednesday, OpenAI unveiled its first custom-built inference processor, designed and manufactured in collaboration with Broadcom. Named Jalapeño, the new processor was designed specifically for the unique needs of OpenAI’s inference systems. OpenAI’s own AI models assisted in the development of the chip, the company said.
Jalapeño, like a jalapeño chip. Get it?

Agentics is the study of how to use and reason about agents. If you are an expert in coding agents, or interested in learning more about agents, join our community slack. More articles here. Learn more about how Nori can bring your company into the glorious AI future at norisessions.com.
For the folks who didn’t watch the Knicks win the playoffs, this is a very very unlikely thing to happen
You would not believe how hard it was to work with some of these people. Unless you’ve ever worked in software, in which case you probably are picturing someone in your head right now. To be fair to them, I think their conservatism is totally warranted — the seniority often comes from an ability to reduce complexity, and AI slop cannons are…not that.
No posts