I’ve been disappointed by local models in the past. But then I checked Qwen 3.6, and I was in awe. For me it’s the first local model that actually makes sense as a general intelligence.
It comes in two variants, a mixture-of-experts model Qwen 3.6 35B A3B, and a dense Qwen 3.6 27B - slower, but more powerful. The one I recommend!
Let me share my impressions, and show that you can run it too.

It’s hot, literally. When my knees started to melt, I grabbed a phone-attached thermal camera and took a photo.
Qwen 3.6, rightfully, got a lot of coverage on Hacker News. The most common statement about Qwen 3.6 27B is that it punches above its weight - see Will it Mythos?. And I think it is a well-deserved sentiment. It will make your computer hot, but it’s worth it!
Testing the waters
Simon Willison uses “penguins on a bicycle” as a smoke test (see for Qwen 3.6 35B A3B and then Qwen 3.6 27B). I usually go with constrained writing.
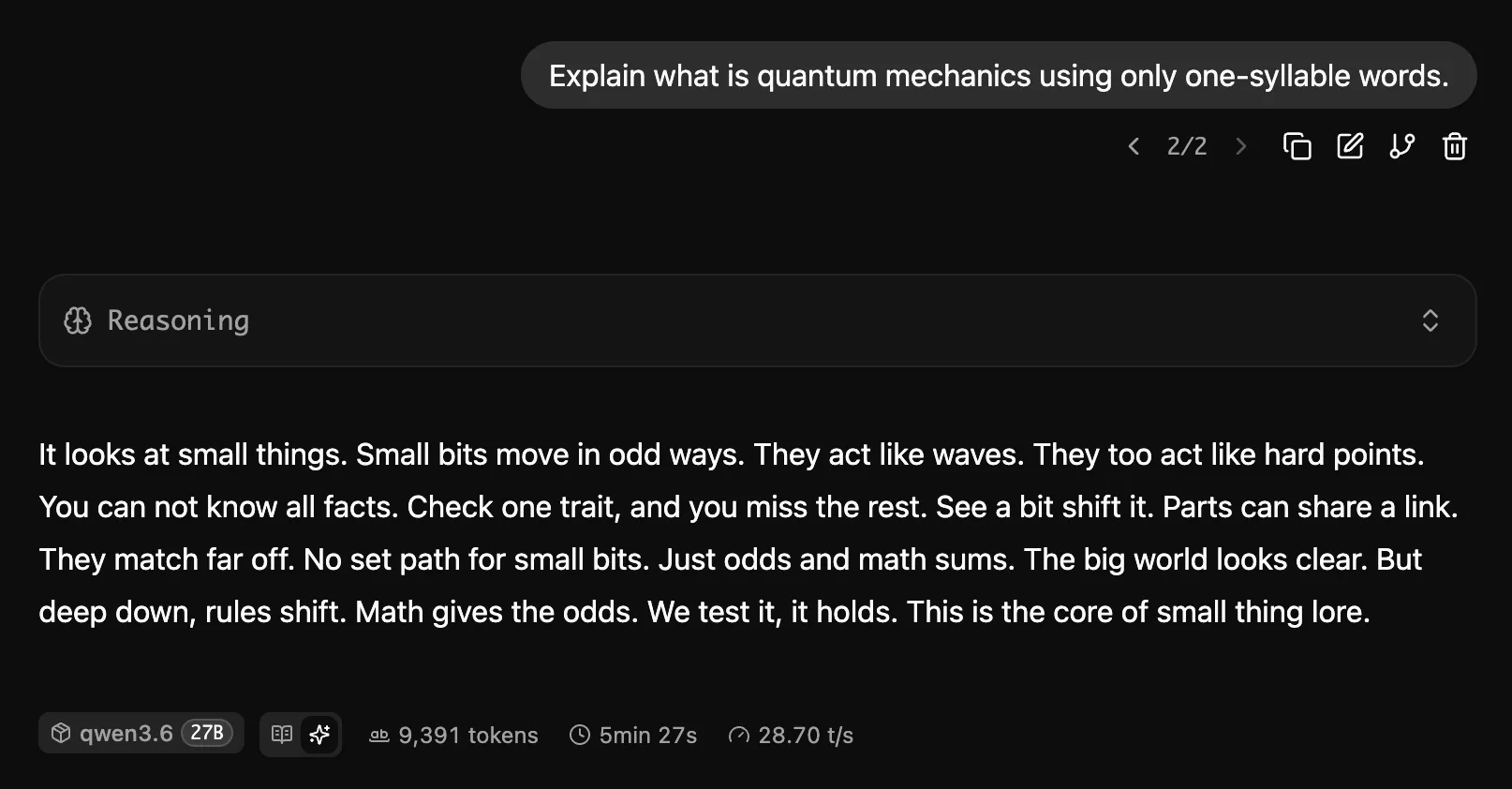
A year ago these kinds of things were state of the art, needing a unique, and insanely expensive GPT-4.5, see vibe translating Quantum Flytrap.
I also asked it to write an 8 line poem about Zouk dance and quantum physics, see the transcript. The thought process made sense, both in terms of deliberation on quantum terms, and rhymes.
Then I asked in OpenCode to create a hexagonal minesweeper using pnpm. It worked:
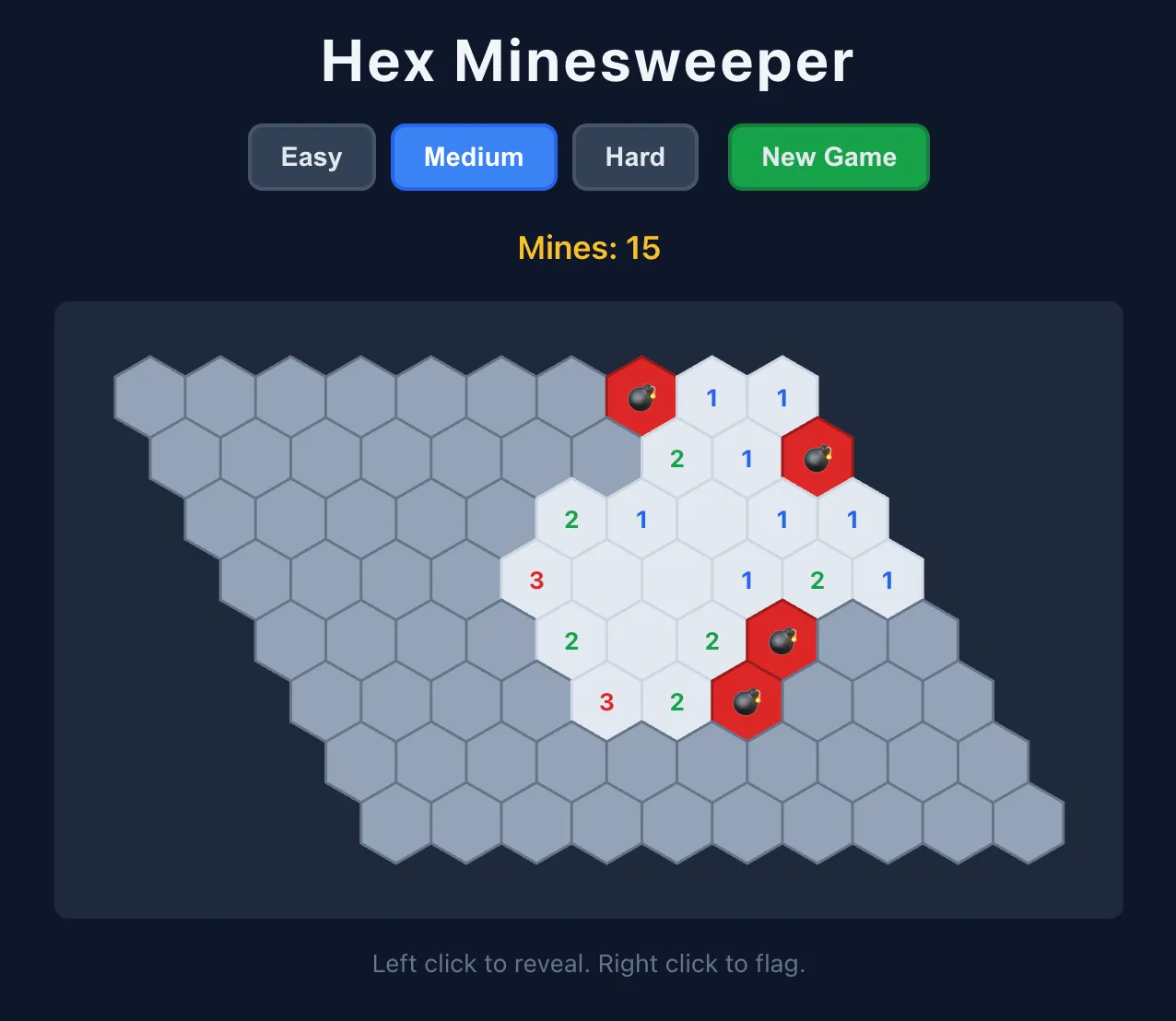
It worked on the first go, from a single prompt, with a proper Node package. The mixture-of-experts Qwen 3.6 35B A3B was faster… but ignored my instruction to create a package, and did it in a single index.html.
Real work
Sure, creative writing about quantum mechanics, or yet another clone of a minesweeper, is rarely a day job. But Qwen 3.6 27B is decent at regular tasks as well.
Prompt by a friend, Maciej Cielecki, at AI Tinkerers Warsaw.
It worked for a few minutes and created this:
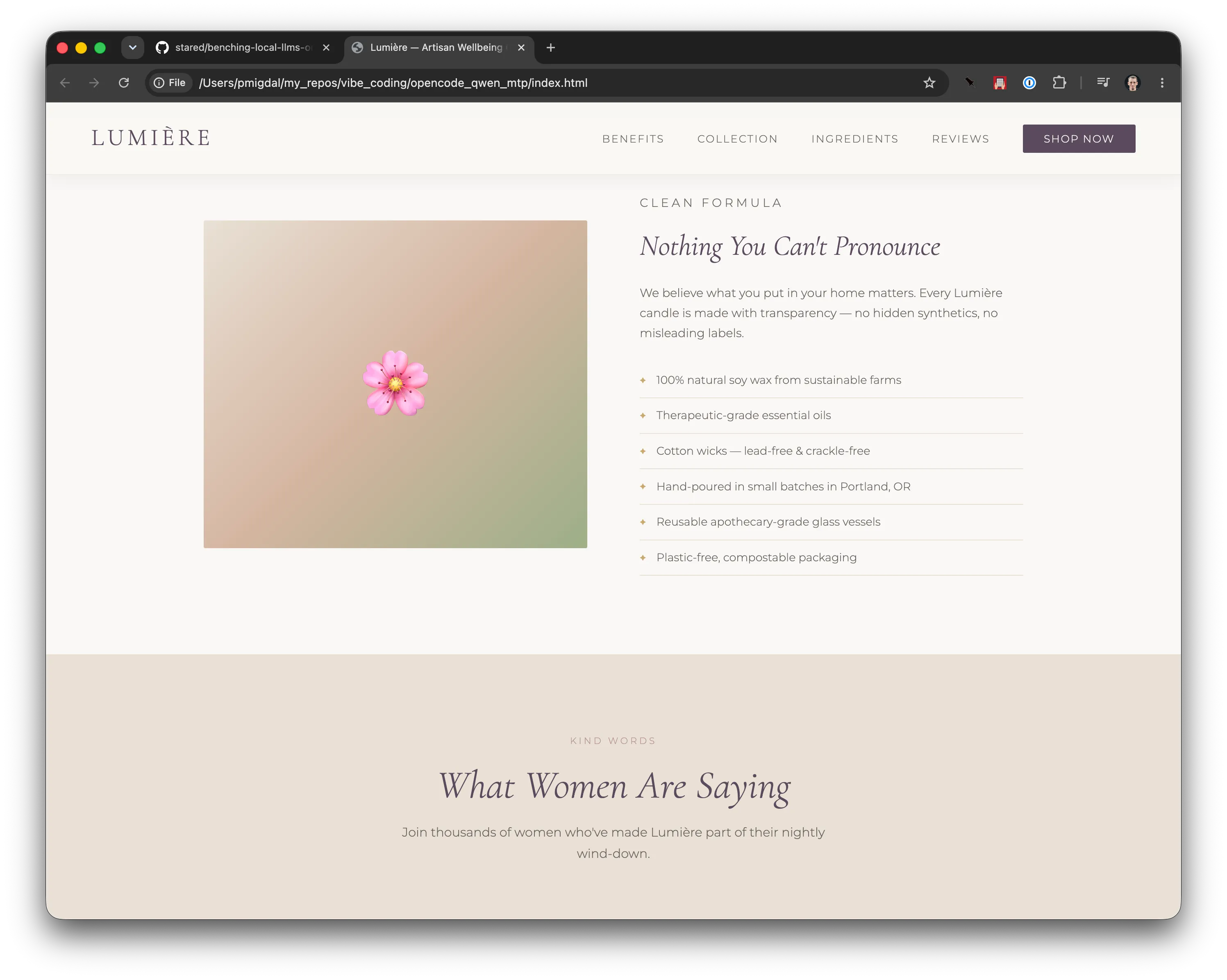
A landing page by Qwen 3.6 27B — view the live page.
By standards of current frontier models, it’s unremarkable. But it is already a practical job. It worked, was reactive, defaults were nice - all from a single, short prompt.
Running Qwen 3.6 locally with llama.cpp
Running local models is easier than ever. A few CLI lines and you’re off.
I recommend llama.cpp - a direct, open source tool that allows running models on various devices. You don’t need Ollama, and frankly - I would recommend against using that on ethical grounds.
First, we go to Hugging Face, to get proper quantization, i.e. a model with reduced size - popular ones are by unsloth or bartowski, among others. Default models usually come with BF16 precision. A common 8-bit quantization saves half the space at almost no cost to quality. Going further down the road, models are smaller (and potentially - faster), but at the cost of quality, see this comparison for 27B and another one for 35B A3B.
We grab unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0, an 8-bit quantization with support for multi-token prediction (MTP).
llama-server -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0 \
--spec-type draft-mtp -ngl 999 -fa on -c 65536 --port 8080
What it does:
-hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0grabs from Hugging Face, on the next runs will reuse that-m ~/models/Qwen3.6-27B-Q8_0.ggufuse instead if you already have itdraft-mtpwe use a fast model to predict subsequent tokens, speeds up things-ngl 999for putting all layers to GPU-fa onflash attention is on-c 65536context size set to 64k tokens (this we can tweak, as Qwen 3.6 27B native context is 256k)--port 8080better to pin port, as it will be used by other configs
If you open http://127.0.0.1:8080, you can directly chat with it.
Precisely the same server can be used for vibe coding. Choice of agent depends both on one’s goal and subjective taste - for an all-around OpenCode, minimalistic Pi, and self-improving Hermes.
For OpenCode, it is as simple as adding to ~/.config/opencode/opencode.jsonc:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"llama": {
"name": "llama.cpp (local)",
"npm": "@ai-sdk/openai-compatible",
"options": {
"baseURL": "http://127.0.0.1:8080/v1",
"apiKey": "local"
},
"models": {
"qwen3.6-27b": { "name": "Qwen3.6-27B Q8 +MTP" }
}
}
},
"model": "llama/qwen3.6-27b"
}
If you just want to chat and are a big fan of Terminal, instead of llama-server use llama-cli:
llama-cli -hf unsloth/Qwen3.6-27B-MTP-GGUF:Q8_0 \
-ngl 999 -fa on -c 65536
Measuring performance
Is it fast enough?
I ran a few tests (source is here) on my Macbook Max M5 128 GB, running it with and without multi-token prediction, and comparing both with the 35B A3B model, and also a quantized DeepSeek V4 Flash version DwarfStar4.
tokens / s
RAM
Qwen3.6-35B-A3B · 8-bit
MLX
85 tok/s 85
37 GB RAM 37 GB
llama.cpp
93 tok/s 93
44 GB RAM 44 GB
llama.cpp + MTP
105 tok/s 105
45 GB RAM 45 GB
Qwen3.6-27B · 8-bit
MLX
17 tok/s 17
28 GB RAM 28 GB
llama.cpp
18 tok/s 18
41 GB RAM 41 GB
llama.cpp + MTP
32 tok/s 32
42 GB RAM 42 GB
DeepSeek-V4-Flash · Q2–Q4
llama.cpp
33 tok/s 33
103 GB RAM 103 GB
30 tokens per second is not bad, well within typical frontier model API range. While mlx-lm is precisely targeted at Apple Silicon devices, and AI agents heavily recommend it, llama.cpp turned out to be faster. It was using 95% of GPU, which means it is efficiently using available resources.
Macbook Max M5 is a beast (at least for a laptop), but on other devices it should also work decently. As you can see, both Qwen 3.6 variants run within 48 GB of Apple Silicon’s shared RAM. A 4-bit quantization are less than 18 GB and should run on 32 GB device. On consumer Nvidia RTX cards, you need to quantize aggressively, but inference runs even faster.
I set this up today on my 5090 at Q6_K quantization and Q4_0 KV, got 50 tokens/s consistently at 123k context, using ~28/32gb vram through LM Studio. - gfosco on the Hacker News
While 35B A3B is 3x faster, I prefer 27B. I’d rather generate a third as much code, but of higher quality.
How do they relate to previous state of the art models?
Manual inspection is great, but benchmarks help with grounding intuitions. Here is the score from Artificial Analysis, comparing it with frontier models:
Gemma 4 31B
29
≈ late 2024
o1 / Claude 3.5 Sonnet
Qwen3.6-35B-A3B
32
≈ early 2025
o3 / Claude 4 Sonnet
Qwen3.6-27B
37
≈ mid 2025
GPT-5 / Claude Sonnet 4.5
DeepSeek-V4-Flash
40
≈ late 2025
GPT-5.2 / Claude Opus 4.5
A few more benchmarks are in these notes, but the spirit is similar. Added here Gemma 4 31B, as a lot of people use this as the default for local coding. But both benchmarks and general sentiment online favour Qwen 3.6 27B by a large margin.
Here there is a caveat - 8-bit quantization of Qwen 3.6 likely does not affect results much, but DwarfStar4 uses much more aggressive ones for DeepSeek V4 Flash, 2-4 bit. For sure it is worse than the full model. My personal impression is that within these quantizations Qwen 3.6 27B is as good as (or maybe slightly better than) DwarfStar4. Though, I won’t be surprised if for longer context projects DS4 has an edge.
What’s next
I think we are entering a fascinating era, when it becomes feasible to run one’s own models.
The change will be propelled further by the state of proprietary frontier models. Claude Fable 5 was taken down. Other frontier models run at a massive subsidy, where paying $100 a month gives us thousands worth in tokens. Let’s use the discount while it lasts!
A locally set model can be fine-tuned to our needs, and cannot be taken away. Businesses can use them for proprietary and sensitive data. We can use them personally for offline projects, or when we don’t feel comfortable sharing our deepest secrets, or medical data, with the US or China.
With the release of frontier-level open-weight GLM 5.2, there is a new era. While Qwen 3.6 was the stepping stone, even frontier GLM 5.2 can be run locally. It won’t run on your Macbook or a single RTX 5090. But still, it is manageable with a company budget.
Moreover, I strongly believe that we will have models smarter than current state of the art, while runnable on local devices, maybe even smartphones. Current models combine both raw intelligence and factual knowledge in the same weights. Future models will likely separate that, offloading a lot of knowledge to tool calling.
Discuss on Hacker News, LinkedIn, or X.