This post is the culmination of over a year of research into how to properly use AI agents to write high-quality software in security-critical systems.
I will be writing this post primarily from my perspective as a software developer, protocol developer, and maintainer of security-critical software.
Over the past year I dove deep into AI agents. I have explored their limits, what they can and cannot be relied upon to do. I’ve created our own AI review tools that perform just as well as multi-billion dollar AI-review systems. I’ve maintained my own custom fork of an AI coding agent called Crush. And this post is my distillation of what I’ve learned to be the best approach if you want to create high-quality software using AI tools.
There are some people who hate AI. Indeed, many developers should hate AI, because it is an enemy to their own learning of software development. This post is not for them. This post is for the few expert developers whose skills have reached the point where they outclass any and all “frontier AI models” in their area of expertise. It is for these expert developers, who want to use AI as a method of increasing their performance without sacrificing any quality that I write this post.
Problems With Current Approaches
If you’ve used AI agents much, you know that during the course of a session the following can happen:
- You can discover that your initial idea was dumb and a better one exists
- Your agent might go “off the rails” and start doing something you don’t want it to do
I’ve watched videos with hundreds of thousands of views where YouTubers explain how they invented complicated systems of 12 parallel agents managed by an orchestrator, doing a billion things simultaneously. How they no longer have to involve themselves in the coding process. It’s just slop writing and reviewing slop while the YouTuber sits on a beach, goes to the bathroom, or sips coffee for no reason.
It is humanly impossible to build your own understanding of a codebase if you use such a “Vibe” approach. The AI will have gone off the rails multiple times and you will only notice it later when you actually try to use the software. This method may be perfectly OK in situations where you do not care about quality, but if you do care, a different approach is needed.
The problem is that even code written and/or reviewed by Fable 5, will stink:
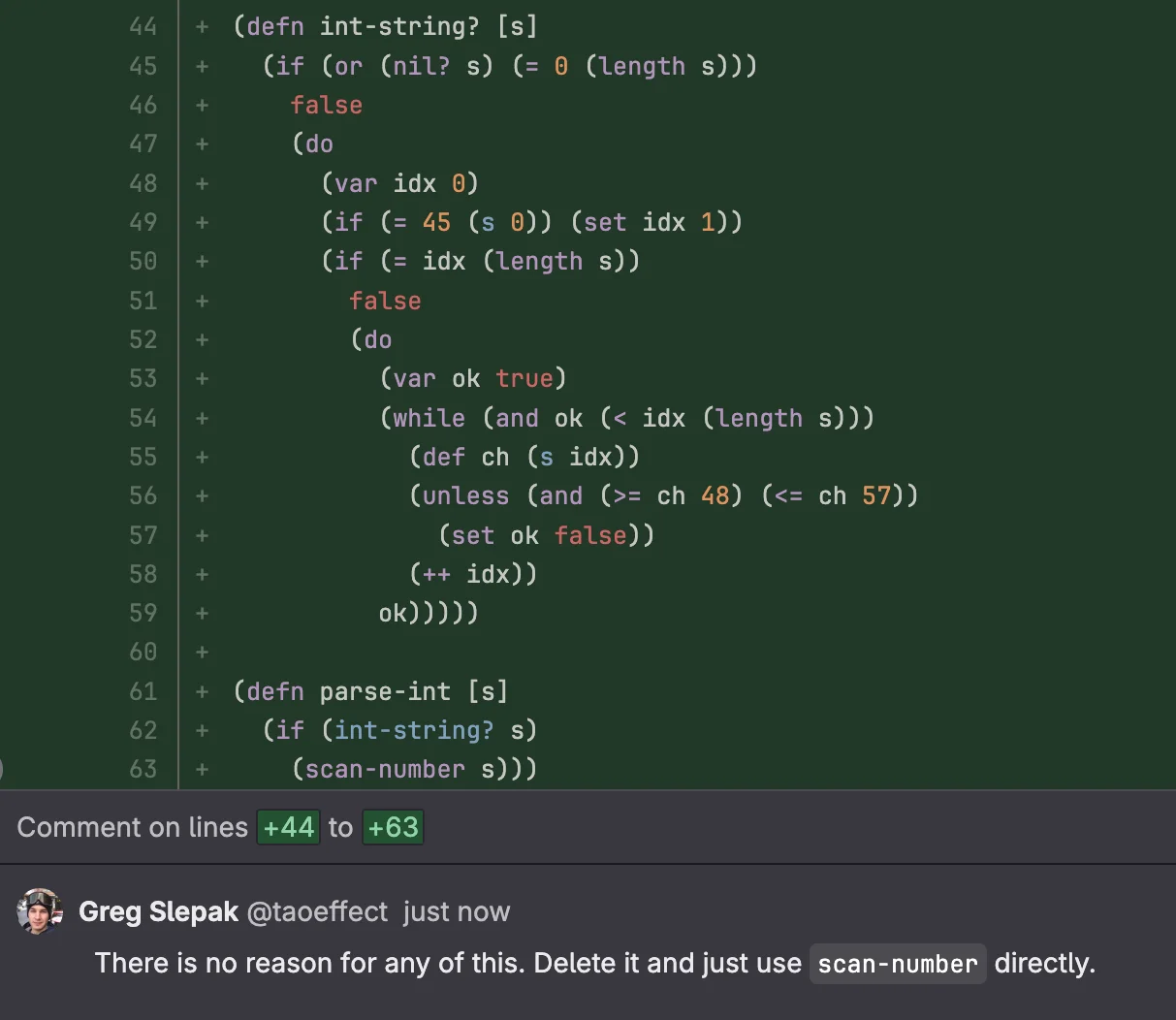
The code works, but it is horribly inefficient and ugly. And this will definitely happen more often if you are working in some kind of a niche area that doesn’t have much training data for the model to fall back on. Contrary to marketing statements made by certain CEOs, these models are not able to think beyond their training data.
AI Code Generation — The “Short Leash” Method
That brings us to the “short leash method” for using AI coding agents.
This method cannot be employed by just anyone. Only professional software developers can use this method. But what’s great about it is that it will lead to Fable-beating results even if you aren’t using a frontier model.
In the Short Leash method:
- You use a planning phase to research the task and formulate a plan, along with something like my tasks skill to track progress and break large tasks into steps (this is one point of commonality with many “vibe engineering” methods; the approach diverges in the following bullet points.)
- You never use “YOLO” mode (aka “dangerously skip permissions”)
- The AI never works “while you play video games”
- You use a coding agent that displays a diff of the changes that are about to be made via the permissions prompt
- You sit there like some crazed person from the 20th century, and actually analyze the changes the AI is proposing to make
- You keep yourself in the loop at all times instead of removing yourself (the trend promoted by YouTubers)
- You use the diffs in the permissions prompts as a way to keep your understanding of the codebase up-to-date and the AI on a “short leash”
- You DENY permissions any time you see that the AI is about to do something you don’t want it to do
- You intervene frequently and as needed to prevent the AI from “going off the rails”
- At all times, the AI is “kept on a short leash”
- Commits are made at the end of every subtask to protect you from the AI screwing up and deleting previously done work (this can happen, I’ve seen Opus do it)
- Finally, we do a review
How to do AI Reviews
A PR reviewed by just a human or just an AI will have more mistakes in it than a PR that’s reviewed by both a human and an AI.
The AI can be treated as a linter. It will quickly catch common mistakes, while the human will catch higher-level issues and directional changes that need to be made.
So when it comes to reviews:
- You should be using AI to review every single PR.
- The AI must have access to sufficient context (the issue, the PR description, the codebase, and the changes).
- You should use the latest and greatest models available to review.
- The PR description must disclose the precise models used (if any) in assisting with the creation of the PR under an “AI Disclosure” heading. This serves multiple purposes:
- It informs the maintainer that AI was used.
- It lets them suggest better models if weak ones were used.
- It signals that you’re a “good guy” developer and aren’t trying to “sneak AI in”.
- Finally, and most importantly, the PR must be reviewed by the PR ‘author’ if it used AI.
That last point is worth expounding upon a bit.
AI-assisted PRs are really PRs from an AI with human assistance. Therefore, the human submitting the PR is expected to understand what they are submitting, and they cannot do that if they haven’t reviewed the code the AI wrote.
So they must treat their own PR as if they’re reviewing someone else’s PR, and review it themselves, line-by-line. Once finished, they can confirm their own approval of the PR, and request attention from the maintainer. This builds and demonstrates their understanding of the codebase.
Fin
And that’s how we use AI at okTurtles. You can read our official AI Usage Policy.
We hope this post has been helpful.
AI Disclosure: this post was entirely written by human fingers connected to a human brain. A final AI-style “spell check” was performed before publishing.
Donating = Loving!
Without our supporters, we can't do what we do.
Please take this moment to support our work.