Most teams eventually end up with a seed.ts or seed.sql file. It starts as a convenience. Then it slowly picks up more and more setup work.
You run migrations, load fixtures, wait for some background job to process things, and then hope nothing has drifted since the last time someone touched it.
I still want every new environment to be isolated and fresh. But I don't think "fresh" has to mean building everything from scratch. The question for me was whether you could get that same fresh, isolated environment without recreating all the data every time.
Note: We open-sourced Xata under Apache 2.0. This post explores the workflow that copy-on-write branching unlocks. If you want to see how it works under the hood or run it yourself, the announcement post and technical deep dive cover the internals.
Why we seed
Seeding earned its place. It's portable, repeatable, and fits the "infra from scratch" mindset. For a small app with 20 rows of fixture data, it's genuinely the simplest thing that could work. For tests that need to start from a known state every time, it's still the right tool.
The problems start showing up when:
- Fake data misses real edge cases. A seed might have 2 users. Production might have 200,000, plus nulls in places you didn't expect, foreign keys left behind by an old migration, and plan types your current enum doesn't even have anymore.
- Seed scripts become another thing to maintain. Every migration needs a seed update. Every new feature needs fixture data. The file gets longer and it gets harder to tell what is still needed.
- Loading realistic data gets slow. If you actually try to seed something production-shaped, you're looking at minutes of inserts. Your "quick throwaway environment" isn't so quick anymore.
After a while, the seed and production can drift pretty far apart.

Why branching sounds expensive
When most engineers hear "database branch," the mental model is:
- Take the production database (or a staging copy)
pg_dumpit (might take a while)pg_restoreinto a new instance (might take a while)- Wait
- Pay for double the storage and lost time when the clone was being set up.
That model is correct for how databases traditionally worked. A 500GB database means 500GB of copying, minutes to hours of waiting, and your cloud bill doubling.
So it's reasonable to think branching sounds good in theory but too expensive in practice (both in terms of money and effort), and to keep using seed scripts instead.
That mental model just hasn't caught up with how some newer systems implement branching.
How copy-on-write changes the cost
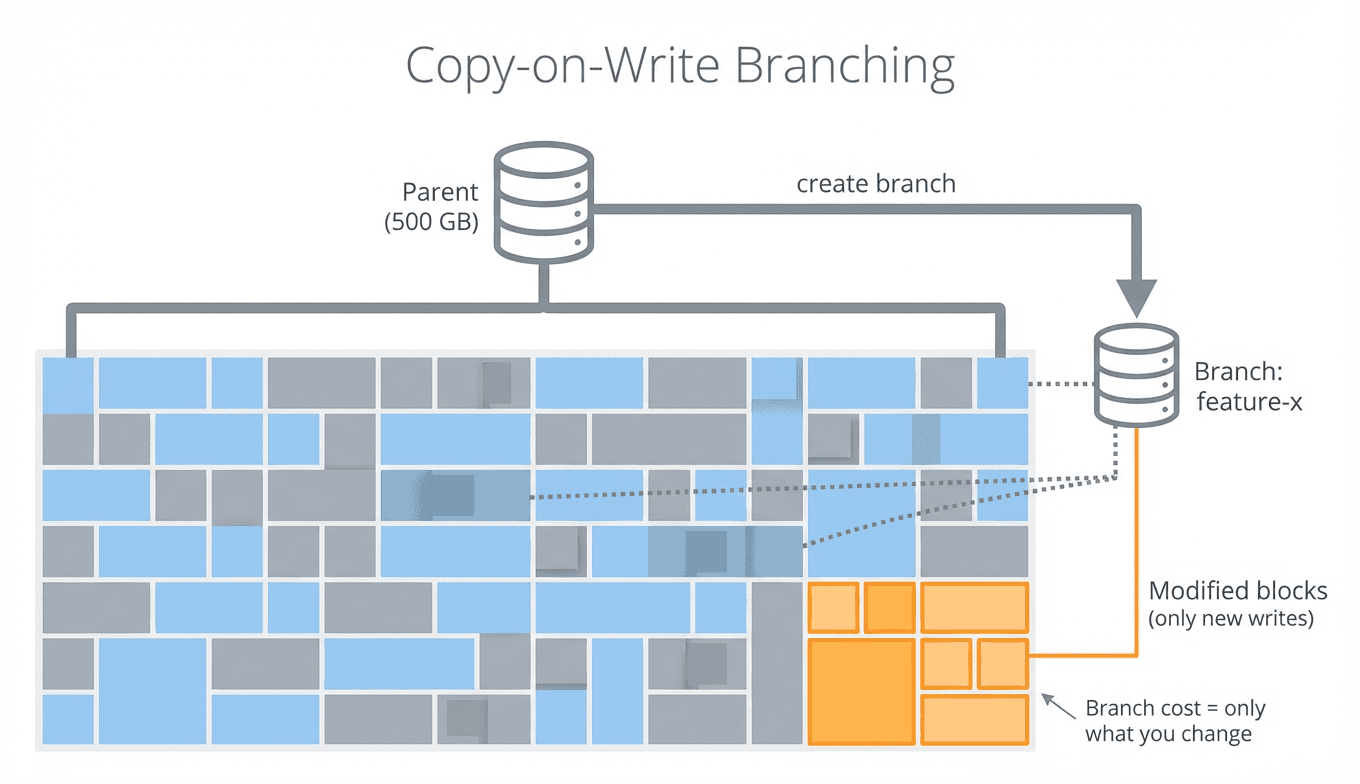
With copy-on-write (CoW), the cost works differently.
The details vary across systems, but the core idea is the same: instead of copying all the data when you create a branch, the new branch shares the parent's storage and only writes new blocks when data is actually changed.
There are different ways to achieve this:
WAL-level CoW — Systems like Neon build a custom storage engine where the write-ahead log (WAL) is the source of truth. A branch is just a pointer: "start from this parent, at this point in time." The child has no data of its own initially — reads that haven't been changed fall through to the parent's storage. Writes go to the child's own layer. Nothing is copied at branch creation time.
Block-level CoW via volume snapshots — Other systems, including Xata, take a different approach. When you create a branch, a snapshot is taken from the parent's storage volume and a new Postgres instance boots from it. The snapshot and the new volume share the same underlying blocks, so branch creation avoids copying the whole database. Only blocks that change after branching need new storage.
In both approaches, the result for the developer is the same:
The cost of a branch doesn't scale with the size of the database — it scales with how much you change after branching. For most dev workflows (run some tests, try a migration, debug a query), you're changing a tiny fraction of the data.
Copy-on-write doesn't remove the cost. It mostly moves it from branch creation time to the point where you start writing data.
In practice, creating a branch takes seconds, not minutes. And the storage cost is tiny until a branch starts changing a lot of data.
One thing to keep in mind: a branch is a snapshot at a point in time. Writes on the parent after branching don't show up in the child. It's a fork, not a live view.
Where this actually matters
The workflow that changed my mind was migration rehearsals.
Imagine you need to add an index to a table with a few million rows. On a seeded database with 200 rows, the migration runs in milliseconds. Obviously. But on a branch with realistic data, it takes 40 seconds and needs CREATE INDEX CONCURRENTLY to avoid locking the table. The branch is isolated, so locking there isn't the issue — the point is that the rehearsal shows the production migration would need CONCURRENTLY.
That's the kind of thing a seed file can't catch. The data shapes are too simple, the volumes are too small, and the edge cases that matter in production just aren't there.
The workflow itself is straightforward — branch from the parent, get a connection string, run your migrations and tests, then delete the branch when you're done:
The branch has all the parent's data without writing a single seed. When you're done, you throw it away.
The same pattern works for preview environments (branch per PR), debugging (branch from staging, poke at it), and safe experimentation (try a destructive UPDATE, throw it away).
I don't want to overstate this. Branching doesn't fix everything but it makes many painful workflows more manageable.
Where seeding still wins
Seeding is still the better fit when you need small, predictable fixtures for unit tests, when you want fully offline workflows, or when your schema is changing so fast that a tiny seed script is just easier to maintain.
Privacy is worth calling out separately. Seed data is fake by definition. Branching production-like data means you either scrub it first or use a system that supports branching with built-in anonymization (some do, including Xata). Either way, it's more work than a seed file.
Conclusion
A lot of our workflows are based on the assumption that a production like clone database is both hard to implement repeatedly and is expensive to maintain. In this post, we saw that with modern database tools like Xata, database branching can be both cheap and easy.
Thank you for reading this post. We look forward to having you try the Xata platform. If you'd like early access, you can get started today.